
基于重采样技术在医学不平衡数据分类中的应用研究*
2018-07-16 06:14田翔华阿拉依阿汗张伟文曹明芹
中国卫生统计 2018年2期
闫 慈 田翔华 阿拉依·阿汗 张伟文 曹明芹△
【提 要】 目的 以代谢综合征为例,探讨不平衡数据对分类算法的影响,并运用重采样技术对数据进行平衡化处理,比较神经网络、决策树的分类性能。方法 采用随机过采样、随机欠采样、混合采样和人工合成数据四种重采样技术,比较数据重采样前后及四种数据重采样间使用神经网络、决策树分类的性能,以F-Measure,G-mean和AUC作为模型评价指标。结果 (1)分类算法性能随不平衡数据集不平衡比例的加剧而降低;(2)四种重采样技术中随机过采样后作用于BP神经网络、C4.5决策树分类性能最大。结论 分类性能随数据集中患病率的降低而下降。采用随机过采样提高了算法的分类性能。建议在应用分类算法对医学不平衡数据分类前,采用随机过采样技术以提高分类性能。
不平衡数据分类问题已成为数据挖掘领域内一个重要的研究课题。不平衡数据是指分类数据中某一类(多数类)的数量远大于另一类(少数类)的数量[1],这种不平衡在医疗诊断中颇为常见,如恶性肿瘤。目前流行的分类算法(如决策树、神经网络)都是基于类分布均衡的假设,以高总体准确度为目标[2]。为诊断恶性肿瘤,将99.9%的个体诊断为健康,便可达到99.9%的准确度,但是这种分类算法并无任何实际意义。医学中患者的数量远远小于健康个体,在医疗诊断中病人误诊为健康与健康个体误诊为病人付出的代价是不同的,因此,准确的识别出病人更加重要。那么,如何增加患者的识别率,同时兼顾健康个体的准确度,是亟待解决的分类问题。
目前,解决不平衡数据的分类问题主要包括数据处理及算法设计两方面。前者主要是对数据进行重新采样以达到平衡,然后再应用传统的分类算法对数据集分类[3];后者主要结合不平衡数据的特点,对传统分类算法进行改进,使它更偏向于少数类,以提高不平衡数据集的整体分类性能[4]。
本文以代谢综合征为切入点,通过计算机模拟不同比例的不平衡数据集,探讨不同患病率疾病分类性能间的差异,并对原代谢综合征不平衡数据集从数据处理角度进行重采样处理,以神经网络、决策树两种分类算法为例,比较两种分类算法智能甄别体检中代谢综合征患者的性能。
资料与方法
1.数据来源
本研究共收集新疆某体检中心2014-2016年63861份体检数据,其中男性32403例,女性31458例,年龄3~93(43.06±13.47)岁,代谢综合征患者占4.34%,不平衡比例达22。共14个变量,其中13个生理、生化指标,1个分类指标。代谢综合征的诊断严格参照中华医学会糖尿病分会的标准[5]。数据集变量特征见表1。
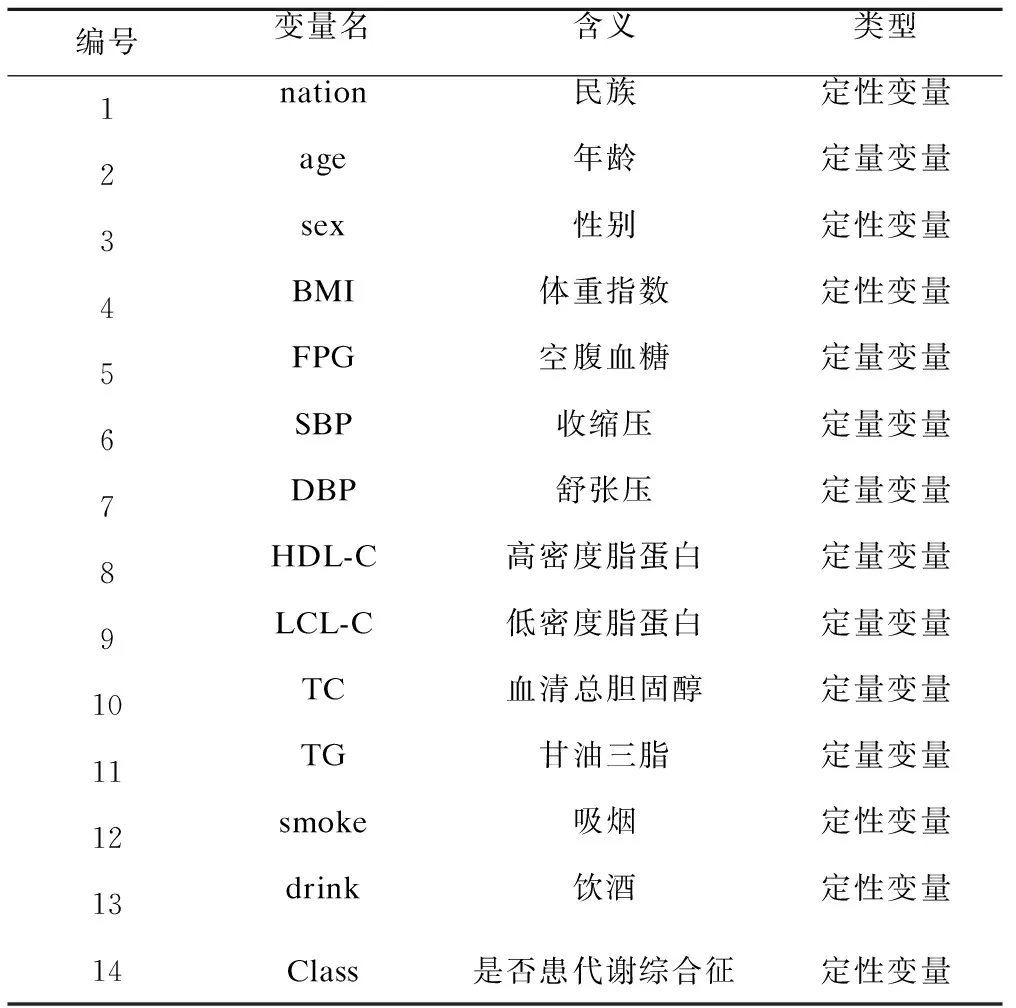
表1 数据集变量特征
2.重采样技术
从数据处理角度解决类别不平衡问题中最重要的方法就是重采样技术,其主要思想是通过合理地增加或者减少一些样本达到平衡数据分布的目的,从而降低数据不平衡对分类算法带来的不良影响[6]。过采样、欠采样和混合采样是目前较为成熟的重采样技术。过采样通过对少数类样本进行复制或人工合成一些新的样本产生数据集的超集使数据集样本量达到平衡,分为随机过采样和人工合成数据,欠采样则以一定的策略选取多数类样本中的一个子集达到同样的目的[7]。混合采样则融合过采样和欠采样两种技术。
3.分类算法
(1)BP神经网络BP神经网络(back propagation neural network)是一种按误差逆向传播算法的多层前馈网络,其学习规则使用最速下降法,通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小[8]。其网络拓扑结构包括输入层、隐含层和输出层[9],见图1。
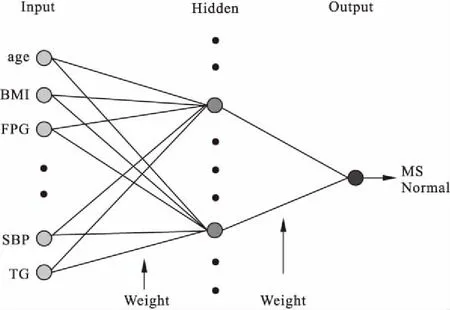
图1 BP神经网络模型结构
本研究以所有生理、生化指标作输入层,以是否患代谢综合征为输出层,设置单个隐含层。隐含层神经元个数的选择直接关系到神经网络的规模和精度。目前,隐含层神经元个数的选取尚无理论指导。公式(1)可用于选择最佳隐含层神经元时的参考公式[10]:
(1)
N表示隐含层神经元个数,P表示输入神经元个数,Q表示输出层神经元个数。经过试验,得最佳隐含层神经元个数为8。
(2)C4.5决策树决策树从一个无次序、无规则的实例集中归纳出一组采用树形结构表示的分类规则。本研究采用C4.5决策树算法。该算法将定量变量采用离散化的取值空间策略,进行优化二分,并采用信息增益率进行分类性能评估。离散化方法为:①寻找连续型变量的最小值和最大值,分别赋值为min和max;②设置区间[min,max]中N个等分段点Ai,其中,i=1,2,……,N;③分别计算[min,Ai]和[Ai+1,max](i=1,2,……,N)作为区间值时的Gain值,并进行比较;④选取Gain值最大的AK作为该连续型变量的断点,将变量值设置为[min,Ak]和[Ak+1,max]两个区间[11]。决策树的剪枝策略从根节点开始递归对决策树各节点进行检查,若该节点的某一子树所含集合的全局支持度小于最小全局支持度阈值,则直接剪掉该子树;若该节点存在叶节点作为子树,并且该节点所含集合对某一叶节点的类支持度大于最大类支持度阈值,则剪掉此节点直接指向该叶节点的其他子树[12]。
4.评价标准
不平衡数据更加关注对少数类样本的识别,所以仅仅依靠准确率作为评价标准并无适用性。为了更有意义地衡量不平衡数据的分类,需要构建混淆矩阵来确定相应的评价标准[13]。二分类问题中,混淆矩阵记录了每一类中正确和错误识别样本的结果,如表2所示。

表2 二分类数据的混淆矩阵
不平衡数据分类性能的评价指标如下:
(1)F值(F-Measure)
(2)
在不平衡数据评价中,F-Measure是一个综合性的评价标准,其公式如(2)所示,其中查全率(recall)表示被正确分类的样本占总样本的比例。查准率(precision)表示分类阳性在真正阳性中所占的比例。当查全率和查准率都比较大时,F-Measure才会相应的增大,故F-Measure可以正确的评价分类器对于每一类的分类性能。
(2)几何均数(G-mean)
(3)
由公式(3)所示,只有当灵敏度和特异度都比较高的时候,G-mean才会相对较高[14]。因此,G-mean综合考虑了少数类样本的准确率和多数类样本的准确率,体现了分类算法在多数样本和少数样本上的整体分类性能。
(3)ROC曲线下面积(area under receiver operating characteristic,AUC)
ROC曲线分别以TPrate和FPrate为横纵坐标,曲线越靠近左上角表示分类器性能越好。在很多情况下直接比较不同模型的ROC曲线并不方便,因此使用ROC曲线的量化指标,即AUC的值作为分类算法的评价指标更为普遍[15]。
本研究以AUC为最重要的评价标准,描述指标的取值范围均为[0,1],取值越大表示对不平衡数据集的分类性能越好。此外,为提高分类算法的可靠性,采用十折交叉验证。
结 果
1.不平衡数据集模拟
利用原代谢综合征不平衡数据集,根据不同疾病的患病率,计算机模拟不同比例的不平衡数据集。BP神经网络分类不同比例的代谢综合征数据集,结果见表3。随着数据集不平衡比例的加剧,即患病率逐渐降低,BP神经网络的F-Measure不断增大,但G-mean和AUC不断降低。综合考虑F-Measure、G-mean和AUC,认为BP神经网络的分类性能随数据集不平衡比例的加剧而降低,C4.5决策树也得出同样结论。
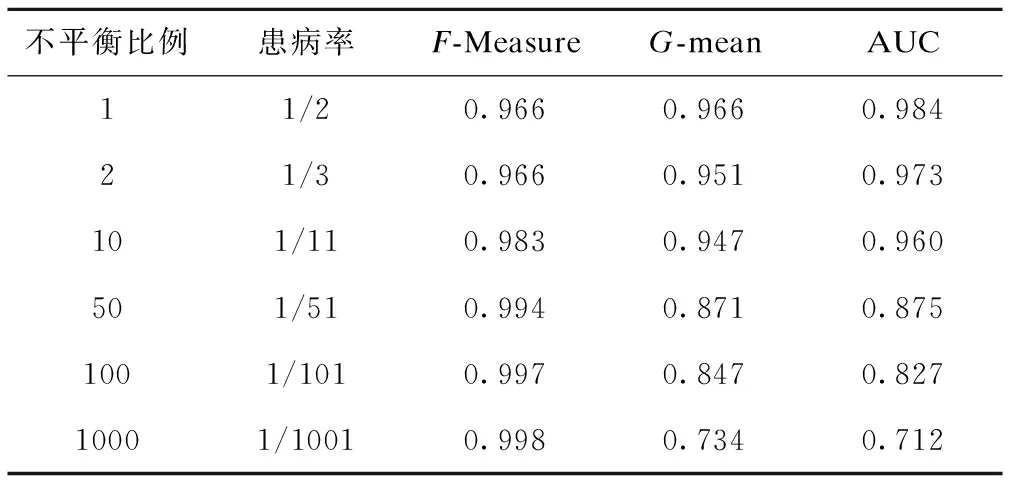
表3 BP神经网络分类不同不平衡比例数据集的结果
2.BP神经网络分类结果
BP神经网络分类四种重采样后的数据集结果见表4。相较于原不平衡数据集,四种重采样后的数据集经BP神经网络分类后F-Measure均降低,表明平衡数据后降低了算法的分类性能;G-mean均有提升,随机过采样G-mean最大;除人工合成数据外,采用随机过采样、随机欠采样和混合采样的AUC均有提升,随机过采样AUC最大。综合考虑F-Measure、G-mean和AUC,随机过采样+BP神经网络的分类性能最佳。
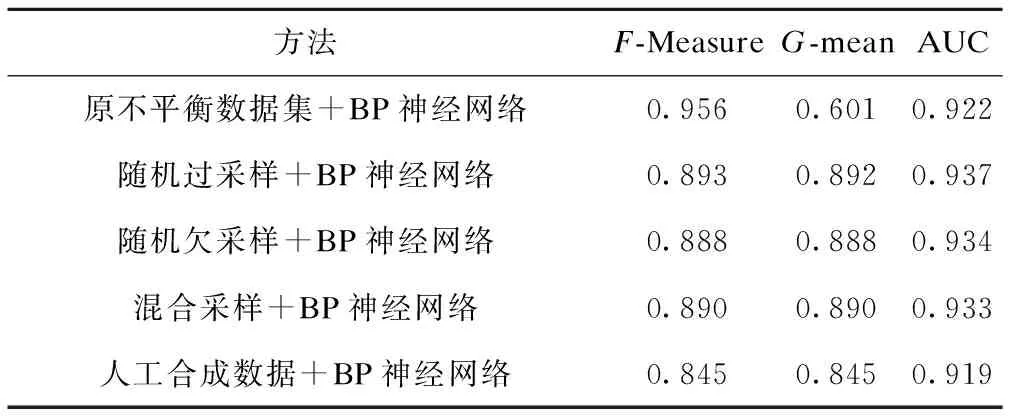
表4 BP神经网络分类结果
3.C4.5决策树分类结果
运用四种重采样技术后,C4.5决策树分类体检中的代谢综合征患者结果见表5。相较于原不平衡数据集,随机过采样和混合采样的F-Measure增大,表明这两种数据平衡化方法提高了数据集的分类性能;G-mean与AUC均有提升,且随机过采样技术的G-mean和AUC均最大,人工合成数据均最小,表明采用四种数据平衡化方法均提高了分类性能,其中随机过采样技术分类性能最高,采用人工合成数据分类性能最小。综合考虑上述三个指标,认为随机过采样+C4.5决策树的分类性能最佳。
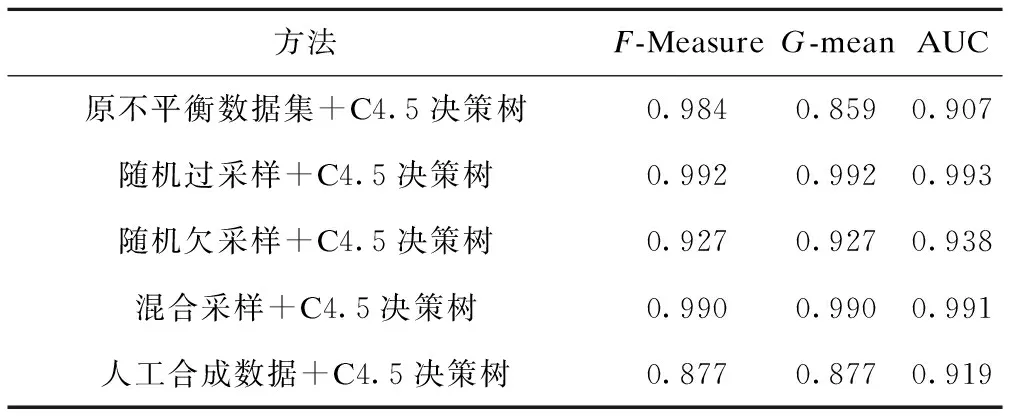
表5 C4.5决策树分类结果
重采样技术平衡数据集前后决策树产生的树状图大致相同,见图2~3。从决策树可看出,代谢综合征的影响因素主要是:空腹血糖、高密度脂蛋白、BMI、舒张压和年龄。但随机过采样平衡数据集后,产生的决策树更接近诊断标准。此外,决策树分类规则提示,如果体检者FPG≤6.1,HDL-C≤0.99,BMI≤24.94,age≤61,那么不患代谢综合征等。
讨 论
通过计算机模拟二分类中不同比例的数据集,即模拟不同疾病的患病率,结果证实,随着数据集不平衡比例的加剧,BP神经网络、C4.5决策树的分类性能逐渐降低,即分类算法的性能随患病率的降低而降低。这与相关报道[11]一致。
本研究中BP神经网络、C4.5决策树分类体检中的代谢综合征患者,分类性能均大于0.9,均取得了较好的分类性能,这可能与样本量的大小有关,该样本由63861份14个变量的体检数据组成。此外,从决策树节点看,与目前大规模流行病学调查得出的代谢综合征发病高危因素一致[16],这表明决策树产生的树状结构具有实际意义,与医学认识水平相同。且从决策树的根节点到叶节点对应着一条合理的规则,并可根据规则对体检人群进行代谢综合征风险评估。

图2 原始不平衡数据集决策树产生的树状图
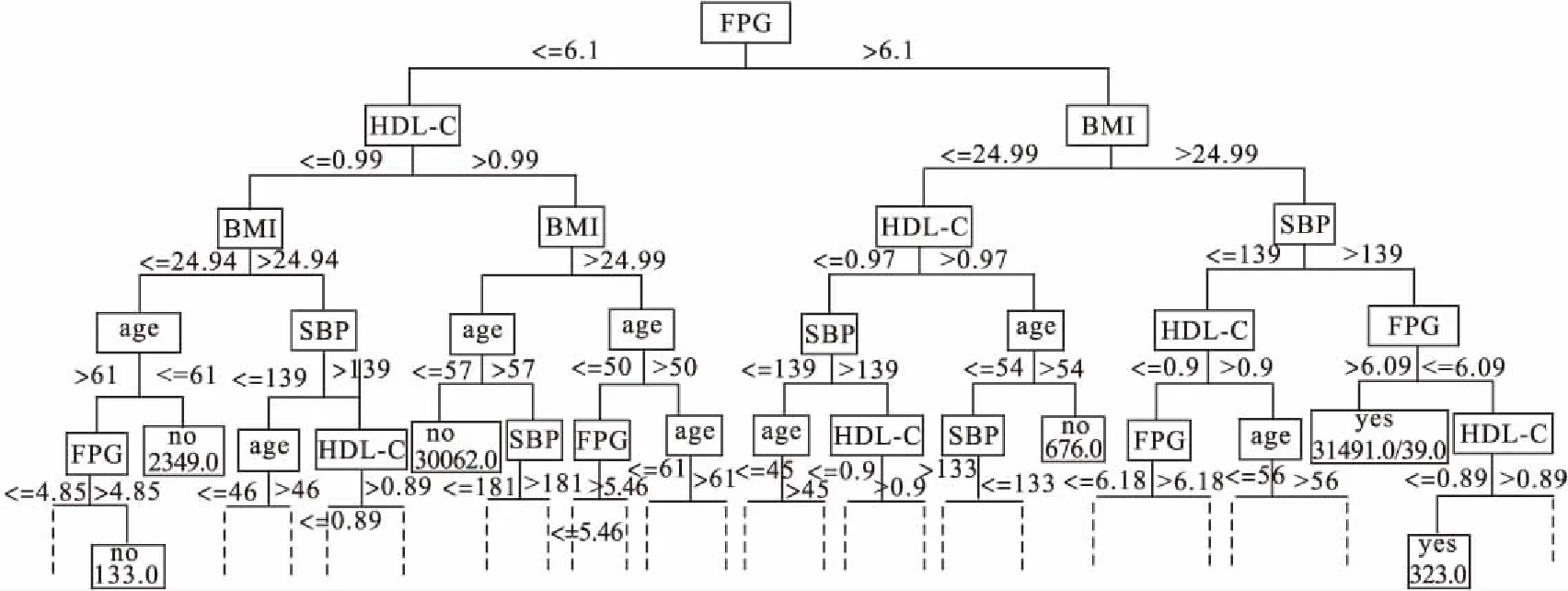
图3 随机过采样平衡数据集后决策树产生的树状图
分别采用随机过采样、随机欠采样、混合采样和人工合成数据平衡原代谢综合征不平衡数据集后,C4.5决策树的分类性能(G-mean、AUC)较平衡数据集前均有明显提高。而BP神经网络中,除人工合成数据外,采用随机过采样、随机欠采样和混合采样的分类性能(G-mean、AUC)均提高。上述4种数据平衡化方法相比较,随机过采样技术更有助于提高分类算法的性能。平衡数据集后,两种分类算法相比较,C4.5决策树分类性能更优。因此,综合考虑表4、表5,认为随机过采样+C4.5决策树可显著提高体检数据代谢综合征分类性能。
此外,研究发现采用四种重采样技术的F-Measure大多小于原始数据集,这是因为,虽然采用数据平衡化方法可以增加正确分类的患者数量(即TP增大,FN减小),但是,同时也增加了误分类的健康个体的数量(即TN减小,FP增大)。也就是说,重采样虽然可以提高患者的查全率,但是当两类样本数量相差较大时,误分类的健康个体的数量有时会比正确分类的患者的数量还要大,故根据公式(2),数据平衡化方法中F-Measure值不会得到很大的提高,甚至降低[17]。
综上所述,数据集不平衡比例越高,患病率越低,数据挖掘技术分类该疾病的性能越差。通过随机过采样、随机欠采样、混合采样和人工合成数据四种方法改善数据集的不平衡性,证实数据集整体的分类性能将得到提升,且采用随机过采样后的分类性能最优。因此,在采用分类算法对医学不平衡数据进行分类前,可采用随机过采样技术对不平衡数据进行平衡化处理,从而提高分类算法的分类性能。
猜你喜欢
中国临床医学影像杂志(2022年5期)2022-07-26
现代电力(2022年2期)2022-05-23
中医眼耳鼻喉杂志(2021年2期)2021-07-21
儿童故事画报(2020年12期)2020-06-23
电子制作(2019年19期)2019-11-23
电子制作(2019年24期)2019-02-23
猪业科学(2018年8期)2018-09-28
电子制作(2018年16期)2018-09-26
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
智能系统学报(2015年4期)2015-12-27
