
一种基于PE病毒转图和CNN的病毒识别方法
2018-07-13 01:40吕臻,张宇
软件 2018年6期
吕 臻,张 宇
(1. 浙江省嘉兴市公安局科技信息通信处,浙江 嘉兴 314001;2. 贵州省遵义市公安局科技信息通信处,贵州 遵义 563000)
0 引言
随着矛与盾的升级,病毒检测和病毒变形的对抗越来越激烈。检测方式由最初的md5匹配,到简单的特征检测,再到具有启发能力的机器学习检测。然而病毒的变形方式也越来越多样化,从修改 md5到切片免杀再到多态变形[2]。
如何有效的识别病毒并把病毒家族化,对于未知样本的聚类,家族识别是我们需要面对的挑战。
1 病毒转图的基本思路
一个二进制病毒可以转化为一个灰度图[3],转换为灰度图之后,我们就把病毒识别的问题转换为了图片识别分类问题。深度学习中的CNN正好是解决图片分类问题的好方法[4]。传统的特征提取检测引擎,特征提取的代价很高,往往无法高效的检测新增样本和样本的变种[5]。传统的机器学习的方法,也同样存在特征提取的问题,特征的好坏往往是主导检测效果的主要原因[6]。
CNN神经网络却很好的解决了上述问题,特征自动提取,所以特征的通用性和鲁棒性更好。
在这个过程中,我们依然有一些困难。比如:训练样本种类样本数量差距较大、计算量较大,需要更多的训练样本。
2 相关工作
在之前的研究中很多人已经开始了二进制文件转图的工作[3],一般是通过整体文件转化为图片,然后根据家族进行分类。 我们这里的方法,是取了文件256个字节的入口点代码作为图片像素。依然可以有效的区分病毒家族。我们举例几种多态变形家族的例子:

图1 parite家族病毒不同变种的入口点灰色图Fig.1 Grey diagram of entry points for different variants of parite family virus

图2 wannacry病毒家族不同变种的入口点灰色图Fig.2 Grey diagram of entry points for different variants of wannacry virus family

图3 Virut感染型病毒家族不同变种的入口点灰色图Fig.3 Grey diagram of entry points for different variants of Virut infectious virus family
通过上面的例子可以看出,二进制转出的图,可以肉眼识别出家族关系和不同家族之前的区别。为了发现更多更深层次的特征关联,我们后面使用CNN进行特征提取。
3 CNN的应用中的挑战
应用 CNN去识别分类病毒图像的过程中有几个困难的地方,一个是样本数量不均衡[7,8],一个是需要有监督训练 。
本文提出:
a.采取新的损失函数,来解决样本数量不均衡的问题。
b.聚类---打标签---分类的思路 来解决监督训练样本数量不够的问题。
(1)样本数量不均衡:
在我们的训练样本中有着样本不均衡的情况,比如,virut、sality病毒的数量就很多每一类都5w+的数量,而 btc.xmr 类型病毒数量就会少很多,只有大概80多个。在多分类问题中,各种类样本数量比例应该在 1:1 左右会有比较好的效果,这时样本数量是均衡的。但是在我们的实际情况看,样本很难是均衡的。训练出的结果也不会很好,所以我们修改了sofmax函数,来解决这个问题。
加权softmax函数:
Softmax回归模型,该模型是logistic回归模型在多分类问题上的推广,在多分类问题中,类标签y可以取两个以上的值。
在 softmax回归中,我们解决的是多分类问题(相对于 logistic回归解决的二分类问题),类标y可以取k个不同的值(而不是2个)。因此,对于训练集(注意此处的类别下标从1开始,而不是0)。例如,在MNIST数字识别任务中,我们有k个不同的类别。
Softmax代价函数与 logistic 代价函数在形式上非常类似,只是在 Softmax损失函数中对类标记的k个可能值进行了累加。注意在 Softmax回归中将x分类为类别 j的概率为:

由于传统的 softmax会平均对待每一类,那么对于样本数量比较少的类型就会有不好的效果,我们对于每个类别的概率前面进行加权计算。
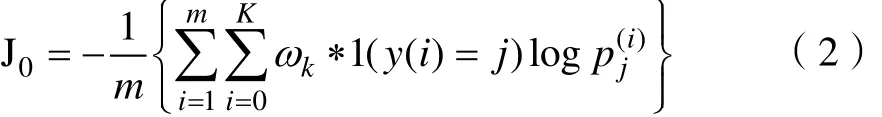
权重ωk的计算方式如下:

这里的maxS是训练集合中,样本数量最大集合的样本数量。kS是第K个类别的样本数量,β是用来控制权重的一个系数,这个系数我们通过遍历法来选择一个较为好用的,我们的经验值是25.
(2)监督训练样本不够
我们通过 Kmeans算法,在收集到的海量样本中,同样采用图片作为特征进行聚类,聚类后人工审核打标签,然后将打过标签的样本类型加入训练。
流程图如下:
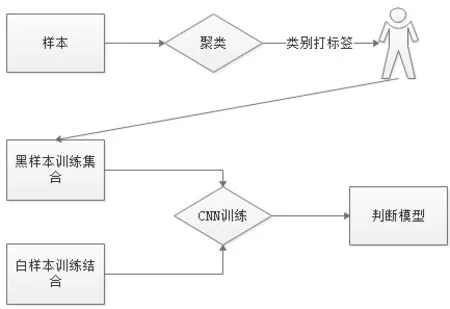
图4 训练流程图Fig.4 Training flow chart
4 CNN设计于应用
这个部分我们讨论应用 VGG网络来进行我们的病毒图片分类。
(1)网络结构
VGGNet[9]是牛津大学计算机视觉组(Visual Geometry Group)和Google DeepMind 公司的研究员一起研发的的深度卷积神经网络,在 ILSVRC 2014上取得了第二名的成绩,将 Top-5错误率降到7.3%。
好学校要把学生的全面发展和个性发展结合起来,才能使学生发现自己的长处并培养自己的长处,最后使自己成为一个人格健全、积极上进和快乐幸福的人。好教育就是让学生做最好的自己。我们最近也在做一些事情来配套跟进。
GGNet 探索了卷积神经网络的深度与其性能之间的关系,通过反复堆叠3′3的小型卷积核和2′2的最大池化层,VGGNet成功地构筑了16~19层深的卷积神经网络。VGGNet相比之前state- of-the-art的网络结构,错误率大幅下降,并取得了ILSVRC 2014比赛分类项目的第2名和定位项目的第1名。
同时 VGGNet 的拓展性很强,迁移到其他图片数据上的泛化性非常好。VGGNet 的结构非常简洁,整个网络都使用了同样大小的卷积核尺寸(3′3)和最大池化尺寸(2′2)。
深度学习中最大的问题是过拟合[10],所以我们每层网络中加入dropout,来避免过拟合。每层网络中的单元被随机丢弃。我们增加两个Droput层来防止过拟合。(VGG19并不包含dropout层)。结构如下:
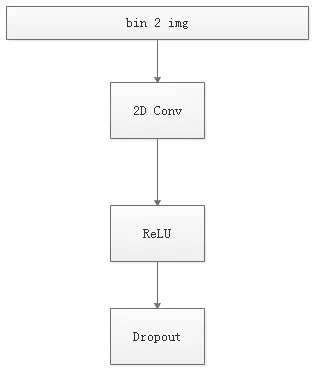
图5 CNN网络结构图Fig.5 CNN network structure diagram
(2)加入加权softmax函数
为了解决之前说的训练样本不平衡问题,我们把修改的加权 softmax函数作为网络的最后一层。下图中的NET1、NET2均为上面这个CONV+droput的结构。
网络总体结构如下:
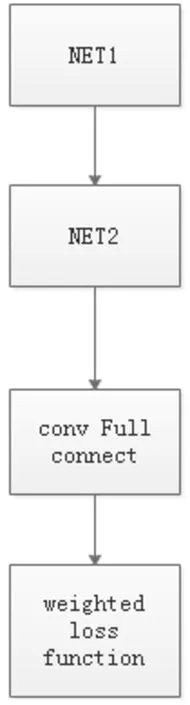
图6 判别网络总体结构图Fig.6 General structure diagram of discriminant network
5 实验结果
我们会比较SVM、LR、和CNN网络检测病毒图片的能力和 CNN 使用普通的 softmax 和 加权softmax在检测能力上的比对。并描绘在实际应用中,通过CNN检测linux样本引擎的roc曲线。
SVM:使用 libsvm,参数 g和 c通过 easy.py计算
CNN:tensorflow + keras
操作系统:windows 7
数据:
实验中的数据集包含了10个病毒类别,不同类型病毒之间的样本数量是高度不平衡的。每一种类型的名字和样本数量在下表中列出。我们把数据分为3块,60%的样本作为训练集合,20%的样本作为验证集合,最后20%的样本作为测试集合。
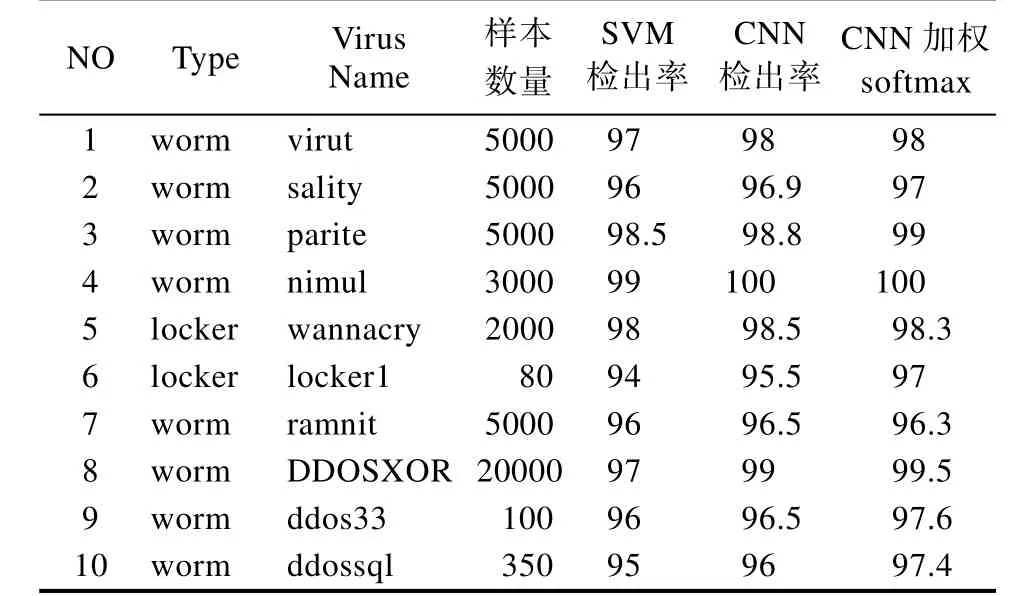
表1 测试集结果Tab.1 Test set results
我们发现 CNN算法比SVM算法在病毒图识别中有着更高的精度,CNN加权算法相比CNN算法,在样本比例不平衡的情况下,对于小样本集合有着一定的优化作用。
不足之处,在二进制转换图片的过程中,发现仅仅使用入口函数的256个字节还是很多病毒分不开,今后会对此做出改进。
CNN引擎检测 linux平台恶意文件的 ROC曲线图,如图7所示。
6 结论
我们通过二进制转图,在通过 CNN和加权的softmax,可以有效的检测病毒样本,也获得不错的精度。可以通过CNN自动提取代码特征,解决了二进制病毒识别中特征提取困难的问题。
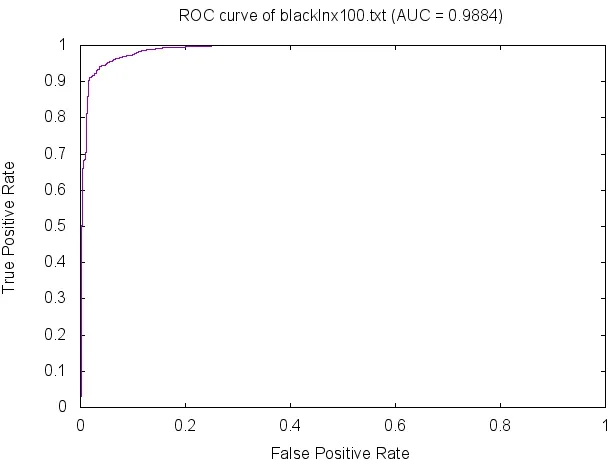
图7 ROC曲线图Fig.7 ROC curve graph
今后的工作中,我们会对于自动提取的特征进行人工分析,看是否存在可以解释的特征。
本次试验中,虽然对于家族检测效果较好,但是对于加壳文件没有进行测试,通常加壳是躲避杀软查杀的主要方式。今后的工作中,我们会对加壳文件进行测试。
对于样本不平衡问题,加权 softmax方法有着较好的效果,但还需进一步探究不同情况下β对于加权softmax的影响。
猜你喜欢
科技创新与应用(2020年6期)2020-02-29
小哥白尼(军事科学)(2019年9期)2019-12-21
电影(2019年3期)2019-04-04
电子制作(2018年19期)2018-11-14
阅读(低年级)(2018年11期)2018-05-14
自动化学报(2017年11期)2017-04-04
北京理工大学学报(2016年6期)2016-11-22
电视技术(2016年9期)2016-10-17
系统工程与电子技术(2016年7期)2016-08-21
噪声与振动控制(2015年4期)2015-01-01
