
基于包簇框架平衡蚁群算法的资源分配策略
2018-07-13 01:40杨苏影陈世平
软件 2018年6期
杨苏影,陈世平
(上海理工大学,光电信息与计算机工程学院,上海 200093)
0 引言
云计算是当前科技领域最热的研究,是一种商业服务模式和计算模型。随着用户需求的扩大,云计算规模的增长,数据中心所消耗的电能也随之剧增。根据国际数据信息公司的研究,全球共有超过300万个数据中心,每小时的总耗电量已经超过3000万千瓦。而数据中心每年产生的能耗更是成倍的增长。因此,数据中心能耗问题是当前甚至以后云计算领域的重要课题。
目前,针对数据中心的能耗问题,许多研究者对能耗优化的策略进行了讨论。文献[1]针对资源虚拟化环境中的混合型负载调度问题,提出了一种基于能耗比例模型的虚拟机调度算法。文献[2]利用约束满足问题对异构云数据中心的能耗优化资源调度问题建模,在此基础上提出了能耗优化的资源分配算法。文献[3]公开了一种云计算能耗关键的三维度虚拟资源调度方法,从CPU、内存以及网络带宽三个维度充分考虑了如何有效地降低数据中心的能耗。文献[4]则通过建立系统模型,针对任务集的物理资源分配问题,提出一种节能调度算法。
以上研究方案对降低数据中心能耗都有一定的改善,但都是基于传统数据中心资源分配方式的,存在许多局限性。传统的数据中心以虚拟机为中心,资源直接在个体的虚拟机与个体的物理机之间进行映射,非常复杂的物理机之间进行映射,非常复杂。在这种情况下考虑降低数据中心能耗也更为困难,分散的资源难以集中,工作量成倍增长,能耗降低的效果也受到限制。因此,针对当下的能耗问题,本文将在一种全新的资源管理框架即包簇框架下进行研究,提出一个种基于包簇框架的资源分配策略。包簇框架可以大大简化映射的复杂性,更易于实现资源的集中管理,有利于提高资源利用率,同时,采用包簇框架下的平衡蚁群算法来进行资源分配,尽可能将包集中分配在簇上,达到降低数据中心能耗的目的。最后通过仿真实验,验证了该算法的有效性,并通过对比实验验证了该算法的先进性。
1 包簇框架
1.1 包簇介绍
通过递归的方式来定义抽象的,多层次的包和簇。其中,包可以看做是一组参与资源共享的虚拟机,若干这样的包可以被抽象成为级别更高的包,最终,这些虚拟机和包就构成了具有明显层次的结构。在实际的云计算应用中,包的层次架构形式将由具体的用户需求来确定,比如一个企业内部可以根据公司分布以及部门划分来确定该企业的包的架构,如图1就为某一企业的包拓扑结构。
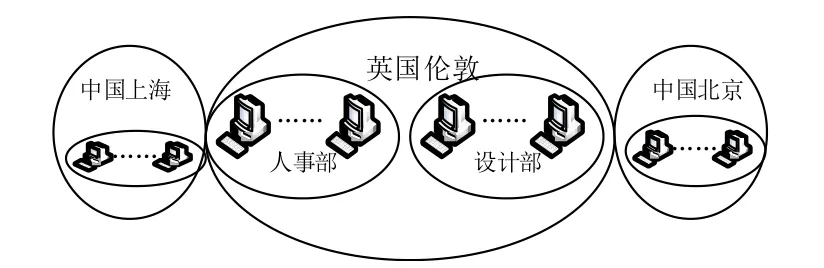
图1 某企业的包拓扑结构Fig.1 The packet topology of one enterprise
与之相对应的簇也是相似的,我们将“簇”定义为数据中心拓扑结构中位置相近的服务器或者更低级别的簇的集合[5]。数据中心资源也可以组成由服务器、簇、簇中簇构成的多级别的层次架构。如图2是以肥胖树形式存在的传统数据中心的服务器拓扑结构;如图3则为采用簇层次结构的简化后的簇拓扑结构,也可以进一步化简,这样一个问题规模巨大的分配问题,就被简化为多个小问题。
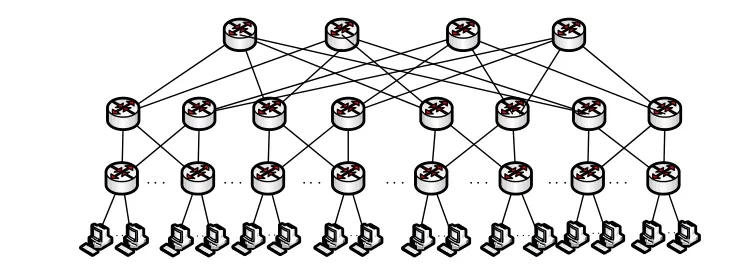
图2 传统数据中心的服务器拓扑结构Fig.2 The server topology of a traditional data center
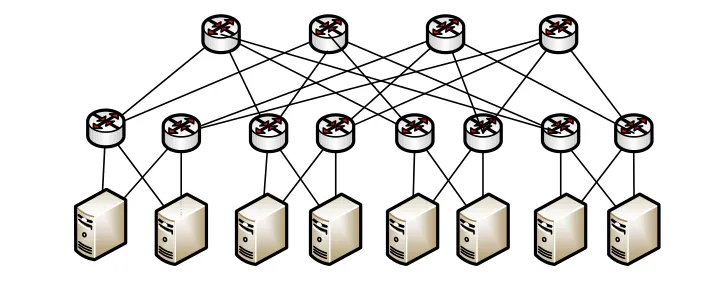
图3 简化的簇拓扑结构Fig.3 Simplified cluster topology
1.2 包簇框架下的资源映射问题
在包含数以千万计机器的数据中心中,采用传统的分配方式进行资源分配具有极高的计算复杂性。而与传统的方式相比,包簇框架下的资源映射问题就简单的多。包簇采用“树”的描述方式,层次划分清晰。可将大量离散的机器的映射转化为递归的层次映射。包簇框架的采用就将虚拟机与服务器之间的映射问题转换成了另一种更小型的包和簇之间的映射问题。通过上述方法,就对指数级复杂读的问题进行了分解,得到了一系列的小问题,最后,将这些小问题各个击破。
2 基于包簇框架的能耗模型
2.1 包簇模型
设簇层次结构中任意一个簇为ρ,该簇具有N个子簇p,则1≤p≤N。并设已分配给ρ的包由M个子包v组成,则1≤v≤M。这样问题就转化为了如何最优地将这M个子包分配给ρ中的N个子簇。
实际上,用户需求以及空闲的资源都是实时变化的。若时间可以被划分成若干离散的时间段,则对每一个子包v而言,在时间t对资源i的需求总量表示为 Rv,i[t]。资源分配将通过矩阵变量x表示:x : = ( xv,p[t])。每个 xv,p[t]实际上是二进制0-1变量:当且仅当在时间t时包v被分配给簇p,则 xv,p[t] = 1,否则 xv,p[t] = 0。对每一个子簇p而言,在时间t时资源i的可用总量记为 Ap,i[t]。
在进行资源分配时,需要考虑到任意一个簇p的资源用量不能超过资源总量。所以有了以下约束条件,见公式1:
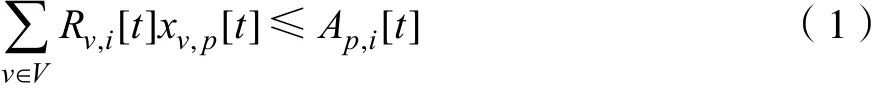
2.2 基于包簇的能耗模型
服务器能耗中,CPU占据了绝大多数的部分,文献[6-7]验证了 CPU使用率与能耗呈近似线性关系,所以本文利用CPU使用率来建立近似的能耗模型,见公式2。
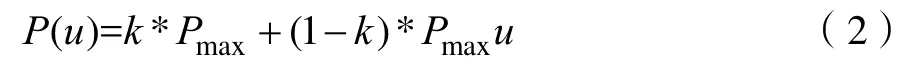
其中,k表示在服务器没有负载时的功耗占服务器满负载时的功率比例,u代表CPU利用率,maxP代表CPU在使用率为100%时的功率。即公式2是单个服务器在CPU利用率u下的功率。
而服务器消耗的总能量一般用服务器的功率和时间之积表示,则公式3即为单个服务器消耗的能量。

而在包簇框架中,不仅需要考虑单个虚拟机消耗的能量,还需要考虑到簇消耗的能量,而簇是由簇与服务器所组成的,因此在包簇框架下单个簇的消耗的能量如公式4。
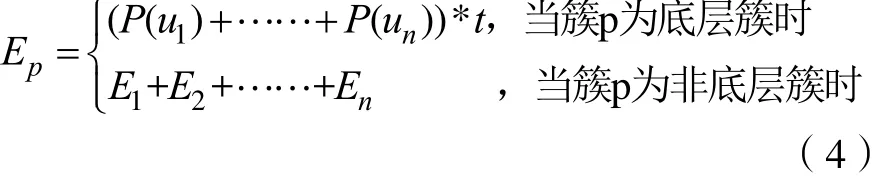
其中n为簇p的子簇数量。当簇p为底层簇时,只需计算其下服务器消耗的总和即可;而当p为上层簇时,计算该簇的能耗就需要计算该簇所有子簇的能耗之和。同样,其子簇能耗也能够通过公式4计算出来,从而计算出每个簇的能耗大小。进一步地,可以计算出在包簇框架下的数据中心的总能耗,见公式5:

由于CPU利用率在不同的时间点有所不同,可以使用积分表示某个时间段内的数据中心的能耗,见公式6和公式7。

所以最终目标函数如下:
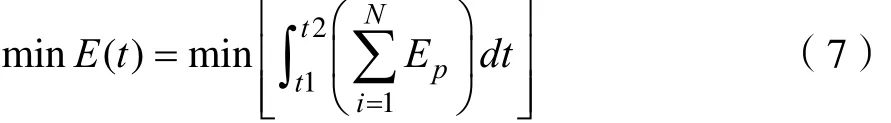
3 基于包簇框架的资源分配问题
3.1 资源分配问题与蚁群算法
资源分配问题可以类比为装箱问题[8-10],将每个簇p看作是箱子,包v看作是物品。本文将采用装箱问题的解决思路来处理该资源分配问题。
蚁群算法[11-12]的特点是分布计算、信息正反馈以及启发式搜索[13],所以该算法成为了装箱问题的经典解决算法。基于以上特征,与其它算法相比,在解决装箱问题时能更有效地收敛到最优解,因此本文将选取蚁群算法处理该资源分配问题。该算法的基本原理为:蚁群在寻找食物时会在其经过的路径上释放信息素,蚂蚁会被吸引着往信息素浓度较高的路径行走,并且会在路上留下信息素。这样就形成一种正反馈的机制,使蚁群总能在一段时间后找到最短路径。
3.2 改进的蚁群算法
3.2.1平衡蚁群算法
蚁群算法也存在一些问题,如蚁群迷失和早熟问题,本文将针对这两个问题对蚁群算法进行改进,称为平衡蚁群算法。
1)为使蚂蚁能够在算法的初始阶段更快的收敛到最优解,我们将在初始时为路径上的信息素设置初始值。
2)为信息素浓度设置最高与最低阈值,使每条路径上的信息素浓度相对平衡,这样的设定可以给予不同的路径更多地成为最优解的机会,从而避免早熟和迷失问题。
因此,将改进后的蚁群算法称为平衡蚁群算法。
3.2.2包簇框架下的平衡蚁群算法
蚁群算法需要执行多次从而得到最优解。在包簇框架下,由于包簇并不是单一的一组节点,而是具有层次的树形结构体,蚁群算法需要考虑到整个簇层次结构的每一层。因此,在此说明基于包簇框架下蚁群寻找“食物”的规则。
3、保证国家能源安全。传统的矿物质能源是当今社会发展和进步的发动机,目前全球总能耗的75%来自煤炭、石油、天然气等。但是,矿物能源是有限的。预计2020年能源消费量将达到30亿吨标准煤以上,到2050年可能要达到50亿吨标准煤以上。因此,开发利用生物质能已成为解决我国能源问题的战略选择。
(1)包簇框架下的每一层都有其对应的解,而每一层的解又取决于上一层包簇的解;
(2)不同层次的包簇不能够产生映射关系;
(3)同一层次的包簇只有在父包和父簇存在映射关系的前提下,属于该父包的一组包才能够分配到属于该父簇的一组簇上去。
(4)默认最顶层的簇与最顶层的包存在映射关系,因为最顶层的包簇是1对1的关系;
(5)除顶层外的余下每一层,在满足2,3映射条件的前提下,都将递归的通过蚁群算法得到每一层的最优解;
(6)蚁群算法在寻找最优的映射关系时,必须保证该簇有足够的资源满足该包的需求。
3.3 包簇框架下平衡蚁群算法的资源分配策略
3.3.1适宜度函数
蚂蚁在觅食过程中,信息素对于获得最优解有着至关重要的作用。而装箱问题的解可以通过适宜度函数的大小来评判好坏,信息素的变化量与适宜度函数成正比,即适宜度函数越大,说明该解的效果越好。
在 3.2节中我们建立了能耗模型,本文目标是为了降低系统能耗,采用能耗的倒数来定义适宜度函数,如下:

设蚁群中蚂蚁的数量为m,在簇上随机放置每只蚂蚁的初始位置。每个蚂蚁k需要根据概率转移函数从allowedk集合中搜索下一个包v,概率转移见公式9:
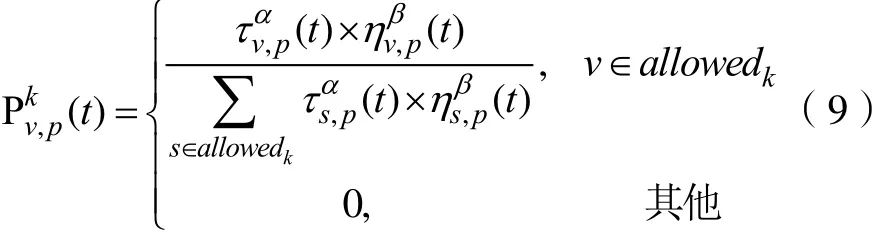
式中, a llowedk即为蚂蚁k可允许选择的包集合,每一次迭代过程中,该集合都会减少,直至allowedk为空,本次迭代结束;ηv,p为启发信息函数,α为信息素启发因子,β为能见度启发因子,这两个参数反映了蚂蚁在选择包的过程中积累的信息素和启发信息对蚂蚁选择路径的重要程度; τv,p(t)为在t时间包v和簇p路径上的信息素。
在初始时刻,各个信息素的强度均相等,为信息素设置一个初始值τv,p( 0)= C (C为常数)。信息素会因为蚂蚁的选择而增加,也会随着时间而挥发;当蚂蚁完成对包的搜索过程或者是完成一次迭代后,要对信息素进行更新操作,更新规则见公式10和公式11。

其中,信息素挥发系数设为ρ,包v和簇p路径上的信息素增量可以表示为 Δ τv,p(t)。f为信息素增量函数,即适宜度函数,见公式 8。而为避免蚁群早熟问题,将为信息素设定上下限,将信息素τv,p设定在一个区间 [τmin, τmax]中,τmin为信息素τv,p的下限,τmax为上限。另外,设包集合为Setv,簇集合为 S etp,簇p在t时间时,其上i资源的剩余资源容量为 R estp,i[t]。a l lowedk,p为蚂蚁k在其当前所在簇p上可允许选择的包集;当蚂蚁完成一次选择时,需要更新 Rv,i[t],见公式13。
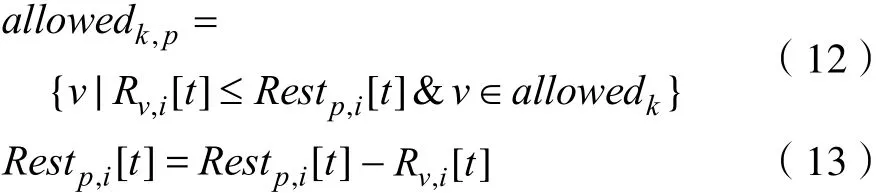
并设iterator为当前累计迭代次数,cycle为循环次数,则算法结束条件为iteratorcycle>。
3.3.3算法步骤
某一层中一次包簇映射过程如下,其中包集合与簇集合的关系需满足4.3.2中的规则3。
(1)初始化 S etv及每个包对应的 Rv,i[t], S etp及每个簇对应的 Rp,i[t];将包集合里的所有包加入allowedk中;
(2)设置蚂蚁数量m,信息素启发因子α,能见度启发因子β,信息素挥发系数ρ;
(3) 将每只蚂蚁随机放置在簇上,作为初始位置,蚂蚁准备出发寻找食物即包;
(4)如果 a llowedk为空,则转步骤 6;如果allowedk不为空,则根据公式10构建 a llowedk,并转到下一步;
(5)若 a llowedk,p为空,将蚂蚁转移到下一个簇上;若 a llowedk,p不为空,蚂蚁根据概率转移函数在allowedk,p中选取包v放置进当前簇p中,更新p的剩余容量,同时更新 a llowedk,将包v在 a llowedk中删除;转到步骤4;
(6) 完成本次迭代,判断是否满足结束条件,若不满足,则初始化信息素,转1继续下一次迭代。
在包簇框架下,需要进行多次递归这一过程。由于每一层次划分清晰,在每一层次中可以并行的实施包簇框架下的蚁群算法,这样,在每一次迭代中只需要执行K-1次即可,其中K为包簇的层数。
4 仿真实验
4.1 仿真环境
为了验证本文算法在包簇框架下对于能耗问题的有效性,在Cloudsim[14]上进行仿真实验。Cloudsim提供了一个通用的、可扩展的仿真框架,使新兴的云计算基础设施和应用服务无缝建模、仿真和实验。以下为仿真实验相关环境。
考虑到真实应用中,企业一般根据分部与部门划分为三层,因此本实验假设包簇架构为三层,并分别设计二级包40个,三级包500个,二级簇80个,三级簇 700个,设每个二级簇下的子簇数量[5,100]间随机选取,以提高实验的可靠性。
4.2 算法调参
本文提出的资源分配算法基于蚁群算法,其参数的选取对于整个算法的性能有一定的影响。因此为提升本文算法的有效性与准确性,首先对包簇框架下平衡蚁群算法的几个关键参数进行调试,包括信息素浓度启发因子α与信息素挥发系数ρ,这两个参数都与信息素相关,对于依靠信息素得到最优解的蚁群算法来说至关重要。
在分析某个特定参数时,固定其它参数的取值,从而观察分析出被调整参数取值变化对于目标函数结果的影响,进而确定最优参数值。本文以能耗为目标,即以公式7值最优为目标进行考察。设置蚁群算法其他的参数值:5β=,15m=,10C=,cycle=20。并设α初始值为1,ρ初始值为0.1。经过多次实验,结果如图4和图5。
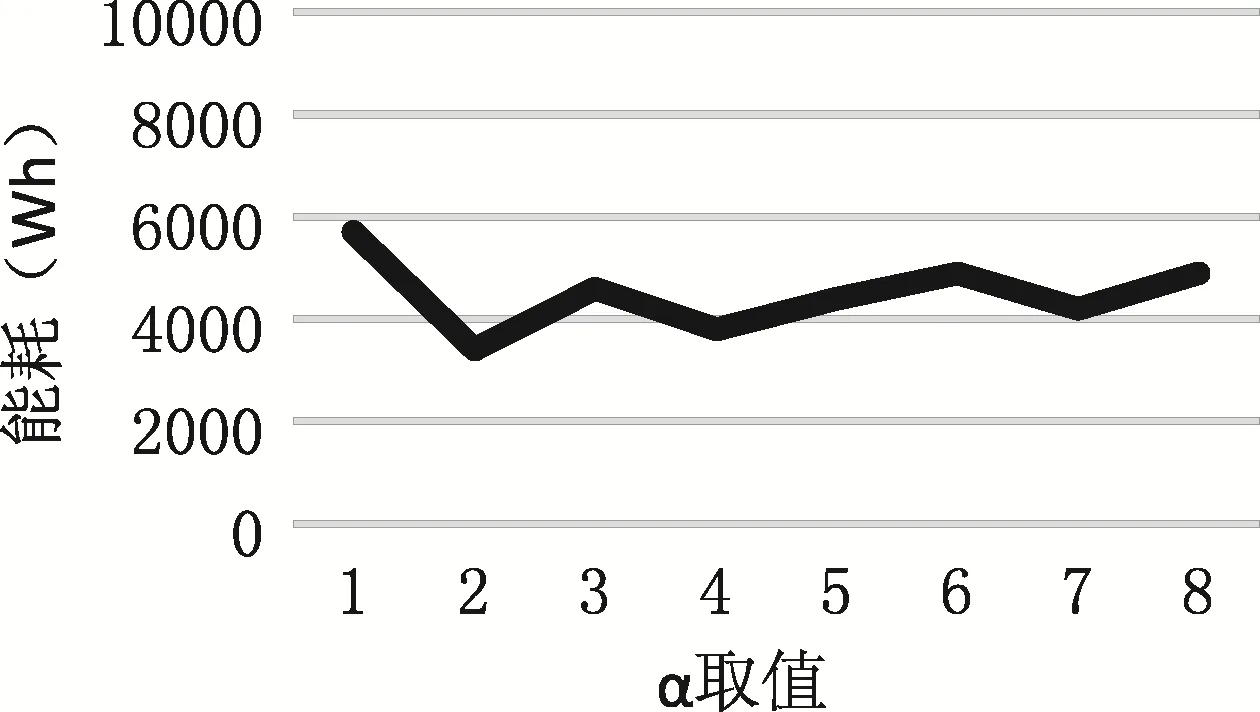
图4 α取值对能耗的影响Fig.4 The effect on energy consumption of α
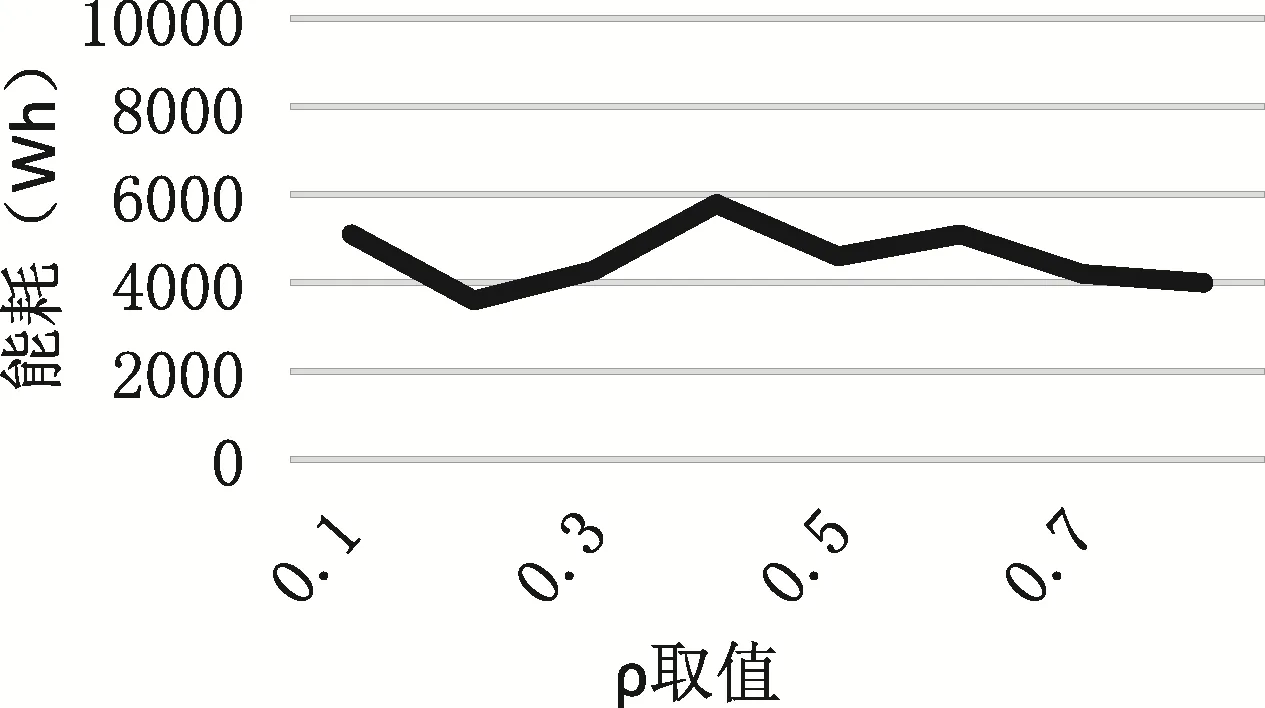
图5 ρ取值对能耗的影响Fig.5 The effect on energy consumption of ρ
由图4可以看出,α=1时能耗并未达到最低值。通过观察看出随着α值的增大,能耗也逐渐降低,在α=2时达到最低值,随后能耗曲线又开始升高。因此信息素浓度启发因子α的最优值为 2。同样通过图5可以看出ρ得最优值为0.3。所以最终蚁群算法参数取值如表1。
4.3 不同算法的实验结果对比与分析
为更清晰地描述实验结果,本文选取文献[5]中的基于包簇框架的遗传算法(IMOPC),以及文献[15]中在传统数据中心下的遗传算法(IGA)作为本文算法的对比实验。在蚁群算法循环20次后得到实验结果如图6和图7所示。

表1 参数设置Tab.1 Parameter Settings
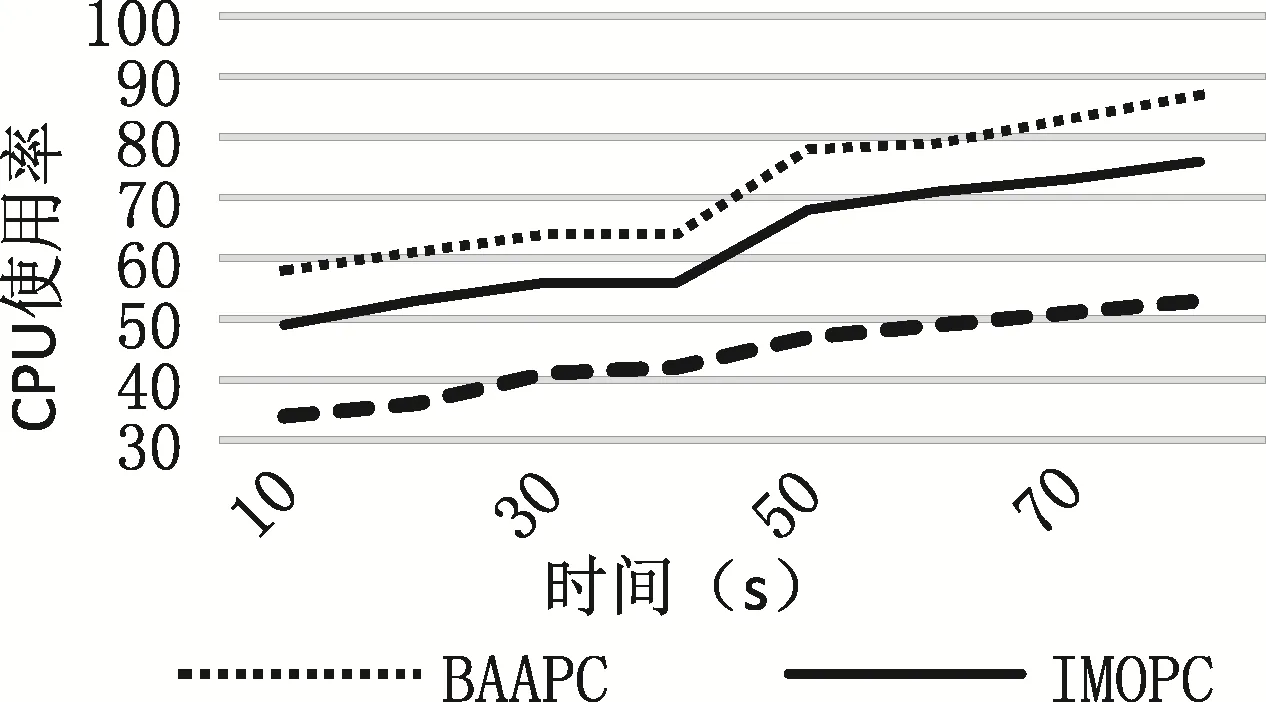
图6 CPU使用率随时间变化曲线图Fig.6 The graph of CPU utilization over time
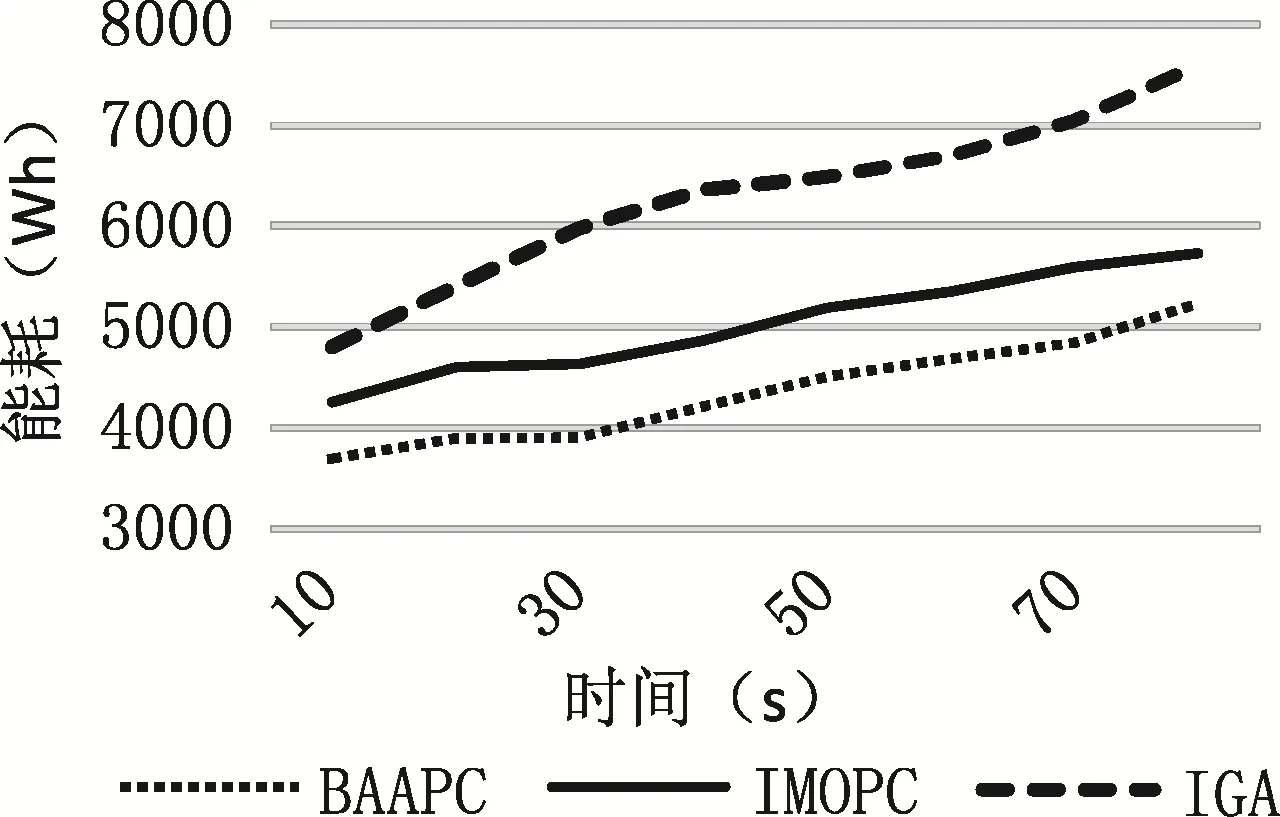
图7 能耗随时间变化曲线图Fig.7 Energy consumption curve over time
图6为三种算法下CPU利用率随时间变化的对比图。可以明显看出,基于包簇框架的 BAAPC与IMOPC算法的CPU利用率远超于IGA算法,说明包簇框架能有效实现资源共享,提高利用率。而同为包簇框架的BAAPC与IMOPC相比,BAAPC在CPU利用率上则更有优势,说明本文的BAAPC更能减少簇的使用个数,集中资源,提高资源的利用率。
图 7为三种算法下数据中心的能耗大小对比图。首先可以看出能耗与CPU利用率是呈正比的,随着时间的变化两者都在逐渐增加。其次可以看出CPU利用率最高的BAAPC算法在能耗方面的表现也是最好的,说明本文BAAPC能有效提高利用率,减少簇的个数,从而有效降低能耗,达到绿色节能的目的。
5 总结
本文就当前数据中心能耗严峻问题提出了一种全新的资源管理框——架包簇框架的资源分配方案。首先针对能耗问题建立了基于包簇框架的能耗模型,然后对于该资源分配问题进行分析,选取蚁群算法作为本文算法,并评估了蚁群算法的优劣性,针对性地对蚁群算法进行了改进,得到包簇框架下的平衡蚁群算法,然后基于该算法实现了包资源分配问题。最后通过实验证明,该算法能有效提高资源利用率,对于降低数据中心能耗具有有效性。
猜你喜欢
机械研究与应用(2022年4期)2022-09-15
英语文摘(2020年10期)2020-11-26
测控技术(2018年7期)2018-12-09
电子测试(2018年11期)2018-06-26
少儿科学周刊·儿童版(2017年5期)2017-06-29
计算机应用(2016年10期)2017-05-12
学苑创造·A版(2017年3期)2017-04-27
中国交通信息化(2015年3期)2015-06-05
学苑创造·A版(2014年6期)2014-08-04
计算机工程(2014年6期)2014-02-28
