
基于K-means算法的电能表检定误差分析与研究
2018-07-13 01:40左黎斌何東莹
软件 2018年6期
何 傲,左黎斌,王 昕,何東莹,赵 楠
(1. 云南电网有限责任公司电力科学研究院;云南 昆明 650217;2. 南方电网电能计量重点实验室,云南 昆明 650217;3. 昆明理工大学信息工程与自动化学院,云南 昆明 650000)
0 引言
近年来,随着社会经济的快速发展,电力需求也在不断增长。电能的准确计量是供电企业生产经营管理及电网经济稳定运行的重要环节。电能表是供电企业与用电客户进行电量结算的重要计量器具,电能表的计量准确性直接关系到供电企业和用电客户的经济效益[1]。作为电能表全生命周期质量评价的重要一环[2],目前没有成熟的电能表检定的质量评价策略[3],仅以合格与否来判断同类别电能表检定的质量的依据,无法全面反映电能表检定的质量差距。本文提出一种基于K-means算法的电能表检定误差分析方法,对电能表历史检定数据进行分析与研究,为电能表质量评价、设备选型、状态评价甚至后期的运行维护策略选择提供科学、可靠的依据。
1 聚类算法
1.1 聚类的含义
聚类又称聚类算法、聚类分析、群分析等,它主要是运用统计分析的思想,将样本或指标依据一定的原则,分成不同的聚类簇,从而使得聚类下的簇内间样本或指标具有较大的相似性,簇外的相似性较小。同时,聚类也是解决数据挖掘的方法之一[4]。
聚类分析是由聚类(Cluster)分析是由若干模式(Pattern)组成的,通常,模式是一个度量(Measurement)的向量,或者是多维空间中的一个点。
聚类分析法在人们的生产、生活中应用广泛,例如在商业上,聚类可以帮助商家从数据库中划分出不同的消费群体,依据消费者的消费习惯,针对性的进行销售。在数据挖掘上,聚类可以帮助人们发现数据库中一些深层的信息,并表述其特点,或者在某一个类上做深度分析[5]。
1.2 聚类算法的数学表达式
聚类算法的定义是指根据某一条件或者基准将数据分成多个类,相同类中间的数据有着符合要求的相似度,不同的类中数据有着可解释的差异性。
假定数据集 X,包含一个空间数据 A, xi=(xi1, xi2,…xid),描述为数据集X中的第i个点。第i个数据点的j个属性描述为xij。假定数据集X中包含 N个数据,即 xi( i =1 ,2,… ,N ),那么就可以将数据集X描述为一个N· d阶矩阵。根据聚类的思想,它主要是运用统计分析的思想,将样本或指标依据一定的原则,分成不同的聚类簇,从而使得聚类下的簇内间样本或指标具有较大的相似性,簇外的相似性较小。即设k为数据集分割的次数,则每个聚类集为 Cm(m =1 ,2,… ,k)。则聚类的数学表示如下:
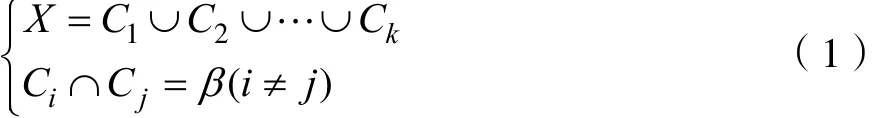
1.3 聚类的要求
聚类方法虽然可以较好的解决分类上的问题,但是如果应用不得当,可能得不到预想的结果[6],因此,聚类方法具有几点要求:
(1)可伸缩性
多数的聚类算法在解决少量的数据是具有较好的聚类性,但面对大规模数据时,可能把控力不强,从而造成聚类上的偏差。
(2)不同属性
聚类算法不单单用来解决数值类型的聚类,还可以应用在二元类型、标称类型或其混合型等。
(3)任意形状
对于每个聚类下的簇来说,它的形状可以是任意的,但是许多人对于相似度的度量方法都是采用欧几里得距离或者曼哈顿距离,而这两种度量方法更多的是解决球状簇的,所以,人们应该提出更多针对性的度量方法用以解决各种形状的簇。
(4)领域最小化
用户在使用聚类算法进行聚类分析的时候,需要自行设定一个阈值,而这个阈值控制着簇内的数目,聚类的结果对于这个阈值的设定十分敏感。通常情况下阈值的大小很难确定,尤其是对于高维的数据集来说。这样使得用户的负担加重了,同样也使得聚类的质量无法得到保障。
(5)处理“噪声”
对于需要进行聚类的数据来说,有些数据是缺失或者错误的,而这些错误或者缺失的数据很有可能造成聚类的错误或者聚类质量的降低。
(6)记录顺序
对于有些具有顺序的数据来说,当以不同的顺序输入到同一个聚类算法中时,可能造成不同的结果,所以,人们应该提出更多针对具有顺序性数据的聚类方法。
(7)高维度
对于海量的数据源来说,可能包含高维度的数据,而很多聚类算法只是擅长处理低维度的数据,最高二到三维,因此,在高维空间中进行聚类是非常具有挑战性的。尤其是这样的数据可能呈现出非常稀疏的分布规律,而且高维度呈现偏斜的情况。
(8)基于约束
对于聚类分析在实际生产、生活中的应用,这就要考虑在各种约束条件下进行。假定任务是要对给定数目下的自动取款机设置安放位置,那么,既要考虑到居民较为密集的活动地点进行聚类,又要考虑到交通问题,如城市中河流的分布情况、公路情况等,还需要考虑客户的需求性等。因此,既要找到特定的约束条件,又要具备聚类的数据分组,这对于实际分析来说是比较困难的。
(9)解释性、可用性
对于聚类的结果,用户往往希望是可解释的、可用的。即聚类需要和特定的语义解释、应用相结合。应用目标如何影响聚类方法的选择也是一个重要研究内容。
(10)样本间的距离与相似度
在对数据进行聚类分析是,首先应找出数据间的相似度,按照数据间相似程度越高,数据越相似的思想进行分类,其公式为:

式中,d——变量间的距离;
c——变量间的相似系数。
因此,需要计算出样本间的距离。常用的计算样本间距离的方法包括以下几种。
(1)马哈拉诺比斯距离(Mahalanobis Distance)
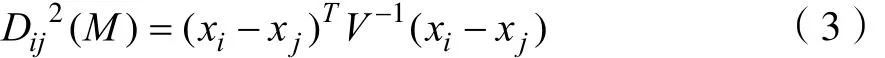
(2)闵可夫斯基距离(Minkowski Distance)

(3)欧几里得距离(Euclidean Distance)
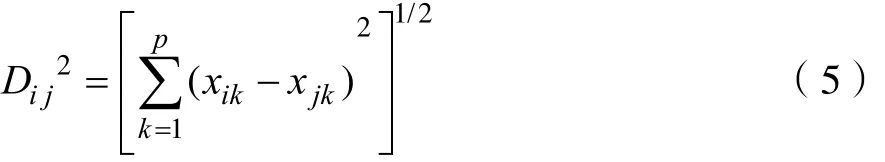
(4)切比雪夫距离(Chebyshev Distance)

(5)城区距离(City-block Distance)
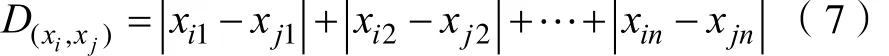
(6)兰氏距离(Canberra Distance)
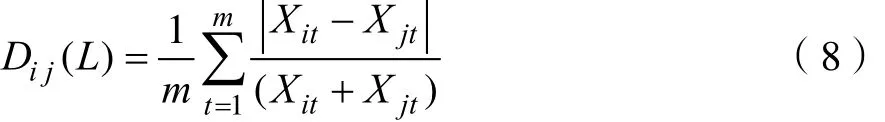
(7)标准化欧几里得距离(Standardized Euclidean Distance)

除了利用距离来度量样本数据间的相似度,还可以利用夹角余弦和相关系数来确定。
(1)夹角余弦
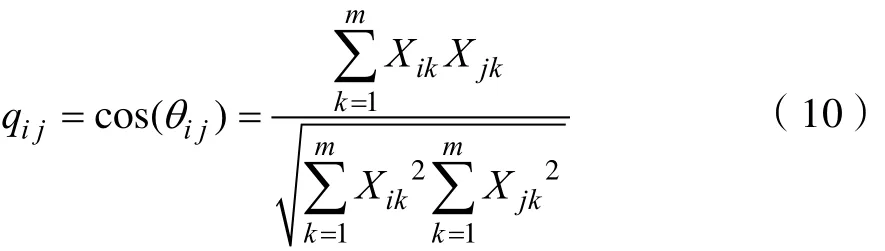
(2)相关系数
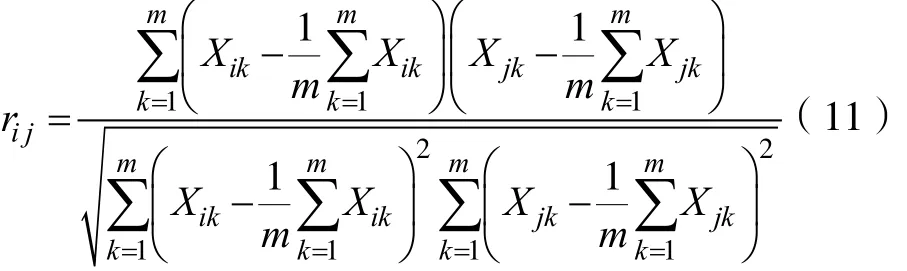
总结上述公式,如果利用距离公式进行相似度考量,则距离越小,相似度越高,如果利用相似系数进行相似度考量,则结果越大,相似度越高。
1.4 聚类的常用方法
聚类算法是一类将未知标签的数据对象集进行分组的无监督学习方法,其主要目的是实现同一组的数据对象间的相似性较高,而不同类的数据对象间的相似性较低。在探索性数据分析和数据挖掘中,聚类算法经常用来发掘隐藏在数据中的部分或全部模式。因此,近几年来聚类算法得到了广泛的关注。常用的聚类算法分为七类,分别是划分聚类法(Partition)、层次聚类法(Hierarchical)、密度聚类法(Density)、图论聚类法(Graph)、网格聚类法(Grid)、模型聚类法(Model)以及混合聚类法(Hybrid)。
(1)划分聚类法(Partition)
划分聚类法的思想是首先对数据进行相似性分组,然后将划分好的数据依次放入到每组中,每一组即代表一个类,同时满足每个类中至少含有一个数据;每个数据仅属于一个类。然后,通过一个数据对象定位技术循环调整数据对象所处的划分,即反复迭代的过程。最终得到较好的分类效果。基于划分聚类的常用方法有K-means算法、PAM算法、CLARA算法、CLARANS算法、K-modes算法以及FCM算法等[7]。
基于划分聚类的K-means算法的基本思想是根据预先设定好的参数K作为分组,然后从数据样本中随机选取K个数据作为各组的中心数据,随后依据相似度将其他数据进行分类。将分类好的数据依据每类中的中心平均值再次聚类,经过反复迭代得到最优解[8]。
K-means算法的计算公式如下:

式中x——某个样本;
ct——聚类中心样本;
E——数据的平方差之和。
modes算法与K-means算法的唯一不同之处在于K-means算法选取的是中心平均值作为再次聚类的中心,而K-modes算法选用距离中心点距离最近的样本代表该类。
(2)层次聚类法(Hierarchical)
层次聚类法的基本思想是采用距离作为样本数据间相似程度的衡量标准,自底向上的凝聚,或者自顶向下的分裂来达到最终的聚类效果。同时,在聚类的过程中,无法取消已经完成的聚类,从而可以有效避免因生成类的数目问题而造成的误差,但也正因如此,一旦聚类中发生错误,整个聚类都将错误。基于层次聚类的常用方法有:Birch算法、CHAMELEON算法、CURE算法以及 MSCMO算法等[9]。
(3)凝聚层次聚类法
基于层次聚类的凝聚法的基本思想是首先将集合中的每个样本数据分别看做一个类,然后根据样本数据间的距离作为相似程度进行聚类,得到的新类再次迭代,直到满足条件为止。
凝聚算法的计算公式如下:
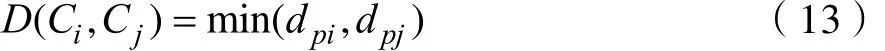
式中Ci——集合中第i个类;
Cj——集合中第j个类;
D(Ci,Cj)——集合中第i个类与集合中第 j个类的距离;
dpi,dpj——样本i与样本j之间的距离。
(4)分裂层次聚类法
基于层次聚类的分裂法的基本思想恰恰与凝聚法相反,即首先将所有样本数据都放到一个类里边,然后对整个类进行迭代分裂,直到分裂为不同的类,满足满足条件为止。
(5)密度聚类法(Density)
密度聚类法的基本思想是针对非球状数据集,将样本数据看成是空间的,从而将数据密集的归为一类。对密度聚类法的评价一般采用类内方差法,基于密度聚类的常用方法有:DBSCAN算法、OPTICS算法、DENCLUE算法,SNN算法以及Fast Clustering算法。
(6)图论聚类法(Graph)
图论聚类法的基本思想是先将样本数据集看成是一张图,然后在一定的条件下,将图分为若干个子图,即分为若干个类,从而将样本数据进行聚类划分。基于图论聚类的常用方法有:AUTOCLUST算法、MST算法以及2-MSTClus算法等。
(7)网格聚类法(Grid)
网格聚类法的基本思想是首先将数据样本集进行空间量化,从而形成有限数目的、具有多分辨率的网格,然后在每个网格中进行聚类。网格聚类法因为不受时间复杂度和数据大小的影响,所以运行速度较快,但不适合高维数据的聚类。基于网格聚类的常用方法有:STING算法、STING+算法、CLIQUE算法以及Wave Cluster算法等。
(8)模型聚类法(Model)
模型聚类法的基本思想是假设数据符合潜在分布规律的基础上,它首先为每个聚类簇假设一个用于参考的模型,然后将数据集中的数据样本与参考模型作比较,找到最佳逼近拟合即为分类结果。基于模型聚类的常用方法有:EM 算法以及 SOM算法。
(9)统计学法
Fisher提出的COBWEB方法的基本思想是采用启发估算度量模式将样本数据的最高效用值划分到各类中。Genai提出的 CLASST方法是建立在COBWED方法的基础上,主要针对处理连续性数据增量的问题。而Cheseman等人提出的AutoClass方法主要建立在贝叶斯的统计分析上,从而实现分类个数的估计,也是生活中较为常用的。
(10)神经网络法
神经网络法的基本原理是采用样本间数据距离的相似程度分析,并以此为依据将每个类描述为不对应的对象实例。由于神经网络法是模拟人的大脑进行实际处理,因此处理过程较为复杂,所以神经网络不适用于大量的样本数据的聚类分析与处理。
(11)混合聚类法(Hybrid)
混合聚类法的基本思想是将多种聚类方法结合的思想,由于每种聚类都存在一定的确定,而将多种聚类方法相结合可以有效规避不足,吸收优点。基于模型聚类的常用方法有:NN-Density算法、CSM算法等。
1.5 聚类的指标评定
聚类有效性的评价标准有两种:一是外部标准,通过测量聚类结果和参考标准的一致性来评价聚类结果的优良;另一种是内部指标,用于评价同一聚类算法在不同聚类数条件下聚类结果的优良程度,通常用来确定数据集的最佳聚类数[6]。
对于内部指标,通常分为三种类型:基于数据集模糊划分的指标;基于数据集样本几何结构的指标;基于数据集统计信息的指标。基于数据集样本几何结构的指标根据数据集本身和聚类结果的统计特征对聚类结果进行评估,并根据聚类结果的优劣选取最佳聚类数,这些指标有 Calinski-Harabasz(CH)指标,Davies-Bouldin(DB)指标Weighted inter-intra(Wint)指标,Krzanowski-Lai(KL)指标,Hartigan(Har)指标,In-Group Proportion(IGP)指标等。
本文主要使用较为常用的外部指标和内部指标中的Calinski-Harabasz(CH)指标、Davies-Bouldin(DB)指标。
对于聚类分析所产生的聚类程度的结果好坏,一般由以下几种方式进行评定。
(1)假定分类中,集合 G中的类与类所设定的范围为 T,则类与类之间任意两个元素间的聚类dij均满足:

(2)假定分类中,集合G中的类与类所设定的范围为T,G中包含n个元素,则每个i元素均满足:

(3)假定T和H都为给定的正数,且HT≻,集合G中的n个元素间的平均距离均满足:
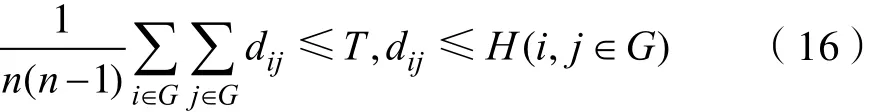
(4)假设类中 G有 n个样本,n个样本中的Xi的维度为 m,则每个数据 Xi可以从以下几个方面来描述G类。
1)平均值

2)样本的离差矩阵
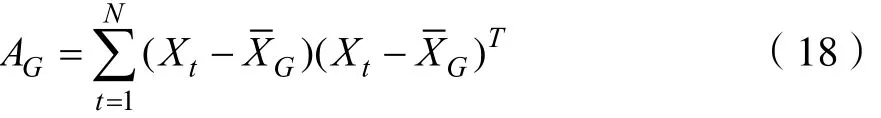
将其简化整理得到:

3)类的直径

或将其表示为:

4)CH指标
CH指标通过类内离差矩阵描述紧密度,类间离差矩阵描述分离度,指标定义为 :

式中n——聚类的数目;
k——当前的类;
trB(k)——类间离差矩阵的迹;
trW(k)——类内离差矩阵的迹。
从表达式中可以得出 CH越大代表着类自身越紧密,类与类之间越分散,即更优的聚类结果。
5)DB指标
DB指标通过描述样本的类内散度与各聚类中心的间距,定义为:

式中K——聚类的数目;
Cij——类与类之间的距离;
Wi——类Ci中的所有样本到其聚类中心的平均距离;
Wj——类 Ci中的所有样本到类 Cj中心的平均距离。
从表达式中可以看出,DB越小表示类与类之间的相似度越低,从而对应越佳的聚类结果。最佳聚类数的确定过程一般是这样的:给定 K的范围[Kmin,Kmax],对数据集使用不同的聚类数K运行同一聚类算法,得到一系列聚类结果,对每个结果计算其有效性指标的值,最后比较各个指标值,对应最佳指标值的聚类数即为最佳聚类数。
2 聚类算法确定
针对电能表检定数据的特点,选择基于划分聚类的K-means算法。
基于划分聚类的K-means算法的基本思想是根据预先设定好的参数K作为分组,然后从数据样本中随机选取K个数据作为各组的中心数据,随后依据相似度将其他数据进行分类。将分类好的数据依据每类中的中心平均值再次聚类,经过反复迭代得到最优解。
K-means聚类算法是用隶属度确定每个数据点属于某个聚类的程度的一种聚类算法。把n个向量xi(i=1,2,…,n)分为 c个模糊组,并求每组的聚类中心,使得非相似性指标的价值函数达到最小。每个给定数据点用值在0,1间的隶属度用来确定其属于各个组的程度[10]。与引入模糊划分相适应,隶属矩阵 U允许有取值在 0,1间的元素。不过,加上归一化规定,一个数据集的隶属度的和总等于1:

那么,K-means的价值函数(或目标函数)的一般化形式:
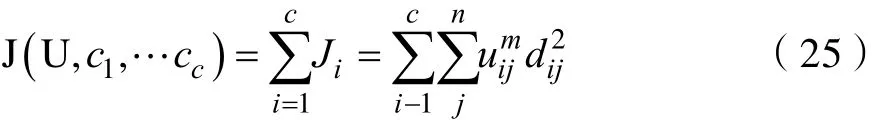
这里iju介于0,1间;ci为模糊组I的聚类中心,dij=||ci-xj||为第I个聚类中心与第j个数据点间的欧几里德距离;且是一个加权指数。
构造如下新的目标函数,可求得使(25)式达到最小值的必要条件:
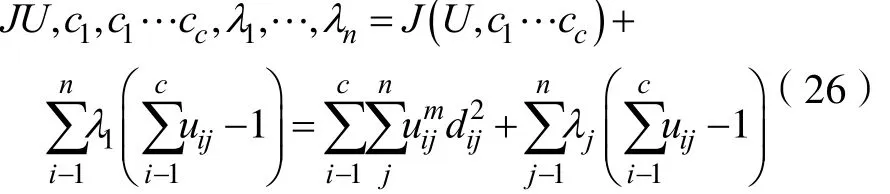
这里ij,j=1到n,是(24)式的n个约束式的拉格朗日乘子。对所有输入参量求导,使式(25)达到最小的必要条件为:

和
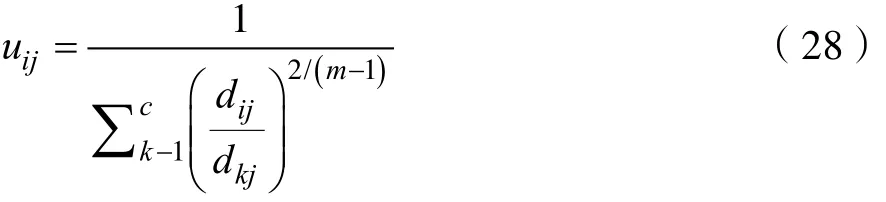
由上述两个必要条件,模糊C均值聚类算法是一个简单的迭代过程。在批处理方式运行时,K-means用下列步骤确定聚类中心ci和隶属矩阵U:
步骤1:用值在0,1间的随机数初始化隶属矩阵U,使其满足式(24)中的约束条件
步骤 2:用式(25)计算c个聚类中心 ci,i=1,…,c。
步骤 3:根据式(25)计算价值函数。如果它小于某个确定的阀值,或它相对上次价值函数值的改变量小于某个阀值,则算法停止。
步骤4:用式(26)计算新的U矩阵。返回步骤2。
上述算法也可以先初始化聚类中心,然后再执行迭代过程。由于不能确保K-means收敛于一个最优解。算法的性能依赖于初始聚类中心。因此,我们要么用另外的快速算法确定初始聚类中心,要么每次用不同的初始聚类中心启动该算法,多次运行K-means。
3 数据预处理
检定数据中存在粗大误差会直接影响电能表的检定结论。粗大误差是指明显超出规定条件预期的误差,也称疏忽误差或粗差,其会明显歪曲测量结果,故也称异常值(坏值)。导致粗大误差产生的原因主要有:测量仪器不符合测量要求,本身存在缺陷;由于不可抗力或不可预估的瞬时性事件导致的计量器具测量偏差等等。在对测量数据进行分析时,由于测量误差客观存在无法消除且具有分散性,很难直观判别测量数据是否存在粗大误差,因此需要运用一定的判别准则对粗大误差进行剔除,以得出较为准确的结论,保障数据分析结果的可信度[11]。
3.1 粗大误差的判别准则
可疑数据是一组测量数据中,明显偏离其他次数测量值的测量数据,需要进行粗大误差判别。测量数据含有粗大误差情况极少发生,但为保证数据分析结论的准确性,一方面需要对数据进行判别并剔除其中的粗大误差,另一方面也需要采用较为妥当的准则进行判别,避免由于粗大误差误判对分析结果造成影响,因此在进行测量数据分析之前,需要进行预处理。数据的预处理是利用冗余测量数据来减少数据的随机误差的影响,实现粗大误差识别,常用于统计实验中识别严重错误的数据。
对选出来的特征进行数据预处理,主要有抽样、空值处理、聚类处理几个步骤,数据预处理的环节见图1。
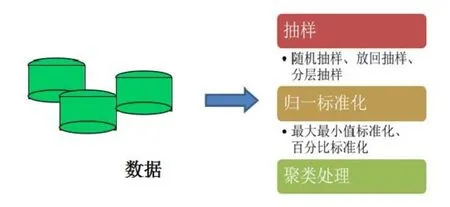
图1 数据预流程示意图Fig.1 Data preprocess diagram.
3.2 抽样
对所有数据进行训练,会受到内存和运行时间的限制,因此对数据进行抽样是必经步骤。抽样方式的选择影响最后的模型输出。抽样方式主要有随机抽样、系统抽样、整群抽样、分层抽样四种[12]。
(1)随机抽样是用得最多的一种抽样方法,用随机抽签的方式或随机数字的方式确定抽样结果。随机抽样原理简单,但不适合数据分布层次明显的数据集。
(2)系统抽样是指按固定的间隔距离进行抽样,系统抽样可操作性强,但易受到参数发展趋势持续递增或递减的影响。
(3)整群抽样是指在抽样前将被抽样群体分成几个类,抽样结果直接选择某个子类。
(4)分层抽样顾名思义,在数据集分层基础上,按比例对每层数据进行抽取,形成一定大小数据集。一般在抽样前需要对数据进行摸底,浏览数据分布情况,如果数据时序性质比较强则选择线性随机抽样,保证参数的时序性。如果数据呈现出类别或层次规律,则选择分层抽样法,确保每种类别的数据都在抽样数据集中。如果无法了解数据集的分布情况,数据随机性强,可以考虑系统抽样。如果抽样只为了提高数据处理效率,则选择系统抽样。本实验采用的抽样方式为线性随机抽样,因为目标预测量为带着时序性质的温度指标,在建模预测过程中,要尽量保持其时序性。
3.3 空值处理
数据清洗一般是对数据为空的值进行清洗。空值一般包括两种情况:第一种是数值的不完整,另外一种则是数值为空。数值不完整是指值实际存在,但数据不完整,或者说没有存入所属字段。数据清洗所处理的是缺失值。处理方法有:可以从本数据源或其它数据源利用相关性推导出某些缺失值;可以用数据源的最小值、中间值、平均值、最大值或推测值;最后也可以通过手动输入一个在接受范围内的人工经验值等。
3.4 聚类处理
聚类指依据相似度把相似度高的数据放在一个类,使得类内差异小,类间差异大,常见的聚类方法有 Partitioning algorithms,Hierarchy algorithms层次算法,Density-based基于密度,Grid-based基于网格,Model-based基于模型。聚类除了进行简单的类别划分,将聚类进行数据预处理的原理就是匹配实际的应用场景,聚类能使相关性比较大的数据聚集在一类。本文基于聚类算法在异常值检测中的应用,结合电能表检定数据的特性,将K-means聚类算法运用在电能表检定数据的处理上,得出电能表检定误差的几种模式。
4 实验处理
4.1 聚类质量评估
K-means聚类算法的K值大小和初始值的设定需要借助一定的评价标准。DBI(Davies-Bouldin 指数)是一种评估度量聚类算法有效性的指标。这个DBI就是计算类内距离之和与类外距离之比,来优化k值的选择,避免K-means算法中由于只计算目标函数J而导致局部最优的情况。k取值太大,每组的分类值太少,特征不明显。K取值小,影响聚类效果。对比K值从2到8的取值,DBI指数发现其在K=4的情况下DBI指数最小,因此本实验用的K值为4,如图2所示。
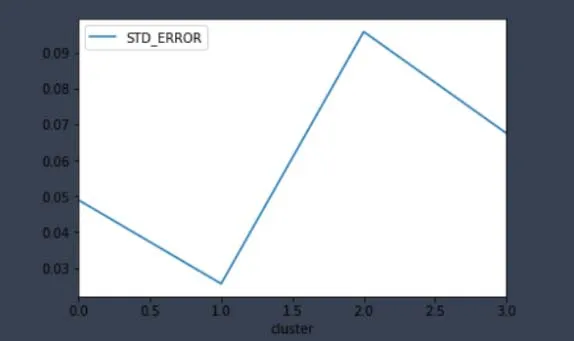
图2 DBI指数图Fig.2 DBI index diagram
4.2 数据描述
所使用的数据为来自于云南省地市供电局2017年4月的部分检定数据。
不可预估的瞬时性事件导致的数据采集不成功,使原始智能电表数据产生脏数据,为保证结果的准确性,首先对原始记录数据进行了简单的预处理,剔除了空值数据记录。
选取4月份检定数据3000条,剔除空值数据后剩余2910条检定记录。检定部分数据如下表1所示。表中数据为电能表在功率因数cos为0.5L和1.0时不同负载电流下的误差。
将K-means聚类算法运用在电能表检定数据的处理上,得到电能表检定误差的几种模式,见图3。
对应的聚类中心图,见图4。
不同生产厂家电能表检定误差处理后的散点图,见图5。
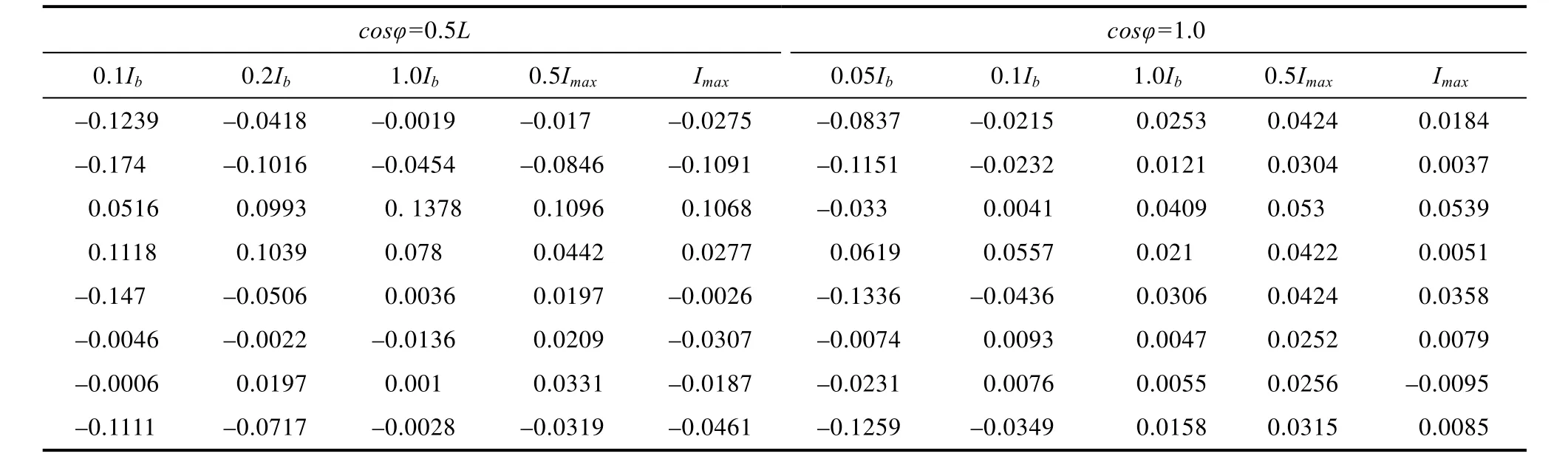
表1 部分电能表检定数据Tab.1 verification data of some electric energy meter
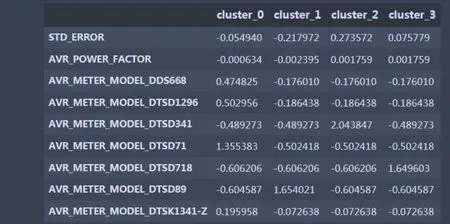
图3 电能表检定误差的几种模式Fig.3 Several modes of verification error of electric energy meter
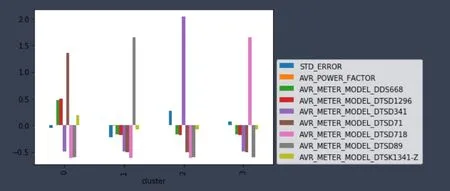
图4 聚类中心图Fig.4 Cluster center diagram
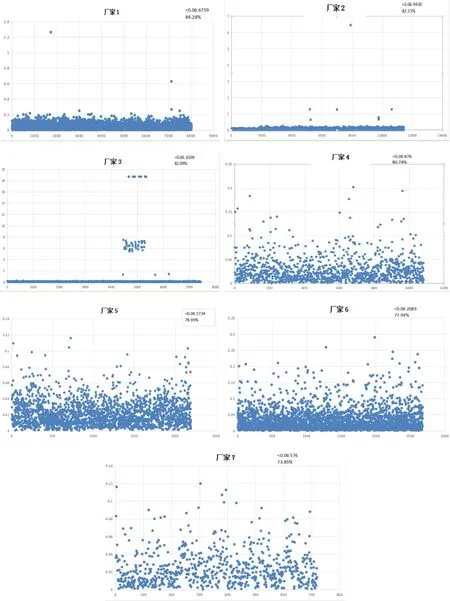
图5 不同生产厂家电能表检定误差处理后的散点图Fig.5 Scatter plot of verification error of electric energy meters of different manufacturers

表2 不同评价标准下电能表检定的质量Tab.2 Quality of electric energy meter verification under different evaluation criteria
4.3 聚类数据分析
从图3、图4、图5可以看出,大部分电能表满足仿真结果,从聚类结果可以看到电能表检定的质量大致可分为4类。
第一类,厂家1、厂家2和厂家3生产的电能表误差比较小。
第二类,厂家 4在选取的标准下的百分比为80%左右。
第三类,这些电能表在选取的标准下的百分比为80%以下,为厂家5、厂家6、厂家7。
第四类,由于该厂家电能表数据样本数少于50只,无法全面反映其质量,不具备评价意义。
再次对第一档的三家生产商电能表检定质量进行对比,分别取评价标准为0~0.02、0~0.03和0~0.04三档,得到表2数据。
从表中数据可以看出,厂家 1生产的电能表在 3个评价标准下的检定质量都优于其他两个厂商。
4 结论
针对供电企业对电能表检定的质量评价的需求,结合历史电能表检定数据的特点,本文提出运用基于划分聚类的K-means算法对电能表历史检定误差进行分析与研究。该方法可以分析、评价电能表检定的质量,为电能表全生命周期质量评价、设备选型等提供科学、可靠的依据。
猜你喜欢
数学小灵通(1-2年级)(2021年11期)2021-12-02
小学生导刊(2018年34期)2018-12-18
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
电子设计工程(2015年6期)2015-02-27
电测与仪表(2014年16期)2014-04-22
电测与仪表(2014年6期)2014-04-04
延河(下半月)(2014年3期)2014-02-28
华东师范大学学报(自然科学版)(2014年6期)2014-02-27
