
结合用户行为和物品标签的协同过滤推荐算法
2018-07-05 04:31李龙生李妍妍上海理工大学光电信息与计算机工程学院上海00093郑州航空工业管理学院电子通信工程学院河南郑州450003
计算机应用与软件 2018年6期
李龙生 艾 均 苏 湛 李妍妍(上海理工大学光电信息与计算机工程学院 上海 00093)(郑州航空工业管理学院电子通信工程学院 河南 郑州 450003)
0 引 言
随着科技的进步和计算机的快速发展,人类已经进入大数据的时代,面对如此庞大的信息,人们很难获得自己想要的信息或者是感兴趣的信息,特别是我们经常接触到的信息,比如电影、新闻、商品、音乐等。在这样的背景下,推荐系统的出现很好地解决了这些问题。最开始的推荐系统推荐不准确,随着广大研究学者对推荐算法的不断探索研究,推荐系统得到快速成长。发展到如今,推荐系统不仅可以帮助用户获取到自己感兴趣的信息,还可以帮助商家快速地把信息投放到感兴趣的人群中。目前推荐系统常用的有以下几类:1) 基于协同过滤的推荐[1-2];2) 基于内容的推荐;3) 混合推荐[3-5]。协同过滤推荐技术是目前推荐算法中最受欢迎也是应用最为广泛的推荐技术。协同过滤算法的主要思想是,根据用户之间相似的兴趣以及爱好,分成不同的用户群组,对于某个特定用户的推荐可以根据其所属的用户群组中的其他用户的偏好习性来对其进行推荐。由于数据稀疏[6],冷启动[7],以及评分的不准确性对现有的推荐系统都会存在或多或少的影响。针对上述出现的问题,许多推荐系统研究学者提出了一系列改进方案。文献[8]建议用一种降维的方法来缓解数据稀疏性;文献[9]指出用评分预测填充的方法可以有效地降低评分矩阵的稀疏性;文献[10]指出利用用户,物品和标签之间的多重关系为目标用户推荐感兴趣的物品,从而来提高推荐算法的准确度;文献[11]指出把奇异值分解(SVD)的方法应用到个性化标签推荐系统可以很好地提高推荐准确度。然而现有的推荐算法忽视了用户对物品评分的盲目性,随意性,小众偏见性以及恶意评分的特征,存在评分不准确的问题,并且在推荐时,存在推荐商品的多样性较差的缺点,而且基于用户-物品评分的协同过滤算法存在准确度不高,效率低等问题。评分对于平时不太关注该物品信息的用户来说,起到了很好的导向作用,但是从另一方面可以说是左右了物品的生死。当物品口碑能够影响观众选择时,更趋向利益的市场可能会出现有水分的评分。比如说国产电影上映时,某些电影为了使口碑更好,则会涌出大量趋向利益性的评分,这些评分不属于客观因素的评分,基于这样的评分不仅不能给用户提供合适的参考而且还有可能推荐错误的物品。在Web2.0中,标签是一项重要的信息资源,它首先由社会大众用户使用标签对物品进行规范的统一化标注并能得到普遍用户的认可,然后把标注后的标签进行归类整理,比如说电影中的标签标注后可分类为:恐怖、科幻、动作等。这样便形成了一种全新的信息分类方式即为以标签为基础的信息分类方式。为了更好地解决用户-物品评分信息的所带来的不必要的影响,一些推荐系统的研究学者结合以上标签信息提出了一种基于标签[12-13]的方法。但是该标签方式是对标签进行单纯权重评分计算,没有考虑到电影标签分布的无规律性以及拥有多标签的特性,由于不同用户对标签的喜好程度不同,因此标签权重评分的权重值的设置问题一直是个难题。针对上面出现的难题,本文提出了一种结合用户行为和物品标签的协同过滤推荐算法。该算法是对传统基于标签做推荐的一种扩展,我们不去设置权重值,而是通过用户自身行为(观影记录)算出用户-物品标签的选择概率,综合考虑多标签而去推荐。同时,该方法较以往的传统协同过滤方法还能更好地降低带有客观因素的评分对推荐准确度的影响。
1 结合用户行为和物品标签的协同过滤推荐算法
1.1 相关定义
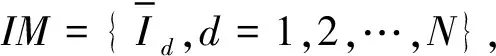
(1)
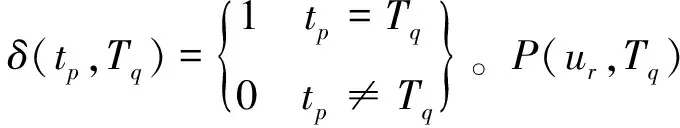
(2)
定义2(用户对物品的选择性概率评分值)ur为用户,Ii为对象(电影),δ(tp,Tq)与定义1中定义相同,P(ur,Tq)为用户ur对标签Tq的选择性概率值,由定义1中计算可得。用户对某个物品的选择性概率评分值如下式所示:
(3)
定义3(用户相似度)由定义2中公式得知中间值即用户对物品的选择性概率评分值,然后通过该值来计算用户间的相似度,目前相似度的计算方 法[14-15]有很多种,本文采用基于用户的皮尔逊相似度计算公式来计算用户相似度:
(4)
定义4(用户对物品的选择性概率预测评分值)由用户对物品的选择性概率评分值和用户相似度计算用户对物品的选择性概率预测评分值:
(5)
式中:m为用户i的最近邻个数,这与协同过滤算法相似,都是利用与用户最相似的邻居的概率评分值预测用户对物品的概率评分。
1.2 算法基本思想
根据以上描述,本文并不依赖用户-物品原始评分,采用结合用户行为和物品标签的推荐算法。
输入:<用户(user),物品(item),用户行为(rating)>
输出:目标用户的Top-N物品推荐
步骤1用户行为(rating)即用户以往记录。根据用户行为文件分离出以往该用户所有有关物品并组成物品集合IM,再结合物品(item)文件找出对应物品标签信息并组成标签集合TG,由标签集合TG利用式(2)计算该用户下所有标签概率P(ur,Tq)。
步骤2步骤1已经计算出该用户下某个标签的概率P(ur,Tq),然后再结合用户行为利用式(3)计算出用户-物品选择性概率评分值R(ur,Ii)。
步骤3由用户-物品选择性概率评分值R(ur,Ii)通过使用基于用户的皮尔逊相似度计算公式计算用户间相似度S(i,j)。
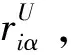
本文所提算法流程图如图1所示。
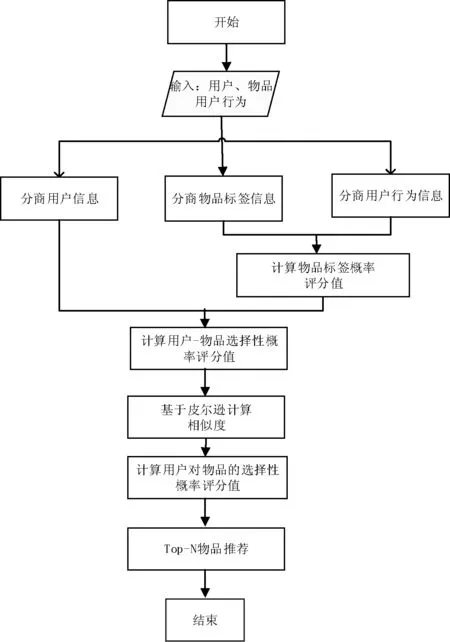
图1 算法流程图
2 实验结果及分析
2.1 实验数据
MovieLens数据集和Netflix数据集是推荐系统研究学者们常用来做电影推荐系统研究的数据集。由于此次实验需要使用电影标签,则我们选取带有电影标签的MovieLens数据集。为了使实验结果拥有更高的准确性,以及排除偶然因素造成的不必要影响,本文将MovieLens数据集中用户-物品评分数据打乱并随机分成两部分来做对比,一部分为训练数据集,另一部分为测试数据集,其中训练数据集占比为80%,测试数据集占比为20%。为检验本文提出的结合用户行为和物品标签的协同过滤推荐算法(UBT-CF)的有效性,本文用传统的基于皮尔逊协同过滤推荐算法[16](CF)作为对比。CF是利用皮尔逊相似度计算公式计算基于用户-物品评分数据的用户间相似度,是目前最为流行的个性化推荐系统算法之一,本文选择CF作为对比。在实验数据对比结果中,本文选取最近邻居个数从5逐步增加到50,其中步长为5。
2.2 评价指标与结果及分析
传统的基于用户的协同过滤算法是根据用户-物品评分矩阵(用户-物品评分范围值为1~5)通过计算任意两个用户之间的评分相似性,由相似性再计算用户-物品的评分预测矩阵(用户-物品预测评分范围值为0~5之间)然后再对目标用户进行Top-N推荐。在整个推荐系统流程中,用户-物品评分是用来计算用户间相似性,只是中间的计算数据,最终结果是评分预测矩阵。本文提出的结合用户行为和物品标签的协同过滤推荐算法,是根据用户行为计算出标签概率,其标签概率范围值本文设定在(0~5)之间,然后利用标签概率计算相似性,最终得出概率预测评分矩阵(概率预测评分矩阵范围值为0~5)并对目标用户进行推荐。本文所涉及方法与所对比的传统基于用户的协同过滤方法很相似,不同点在于计算用户间相似度值是采用中间计算后的值即标签概率,对比的方法即传统的基于用户的协同过滤方法,采用的是用户-物品评分。两者的取值范围相同,以及两者的最终结果都是评分预测矩阵,并且两者采用统一的评价指标。
目前在推荐系统的研究领域中,推荐算法是否得到较好的提高,有几个常用的评价指标。这类评价指标的思路大都很相似,就是计算预测评分与真实评分的差异。其中最为经典也是最为常用的方法就是平均绝对误差[17-19]MAE(Mean Absolute Error),MAE公式为:
(6)
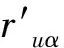
(7)
实验结果如图2、图3所示。
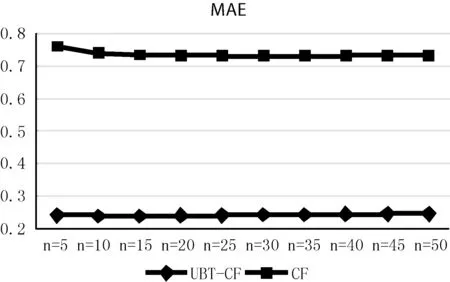
图2 传统CF与UBT-CF,MAE值对比图
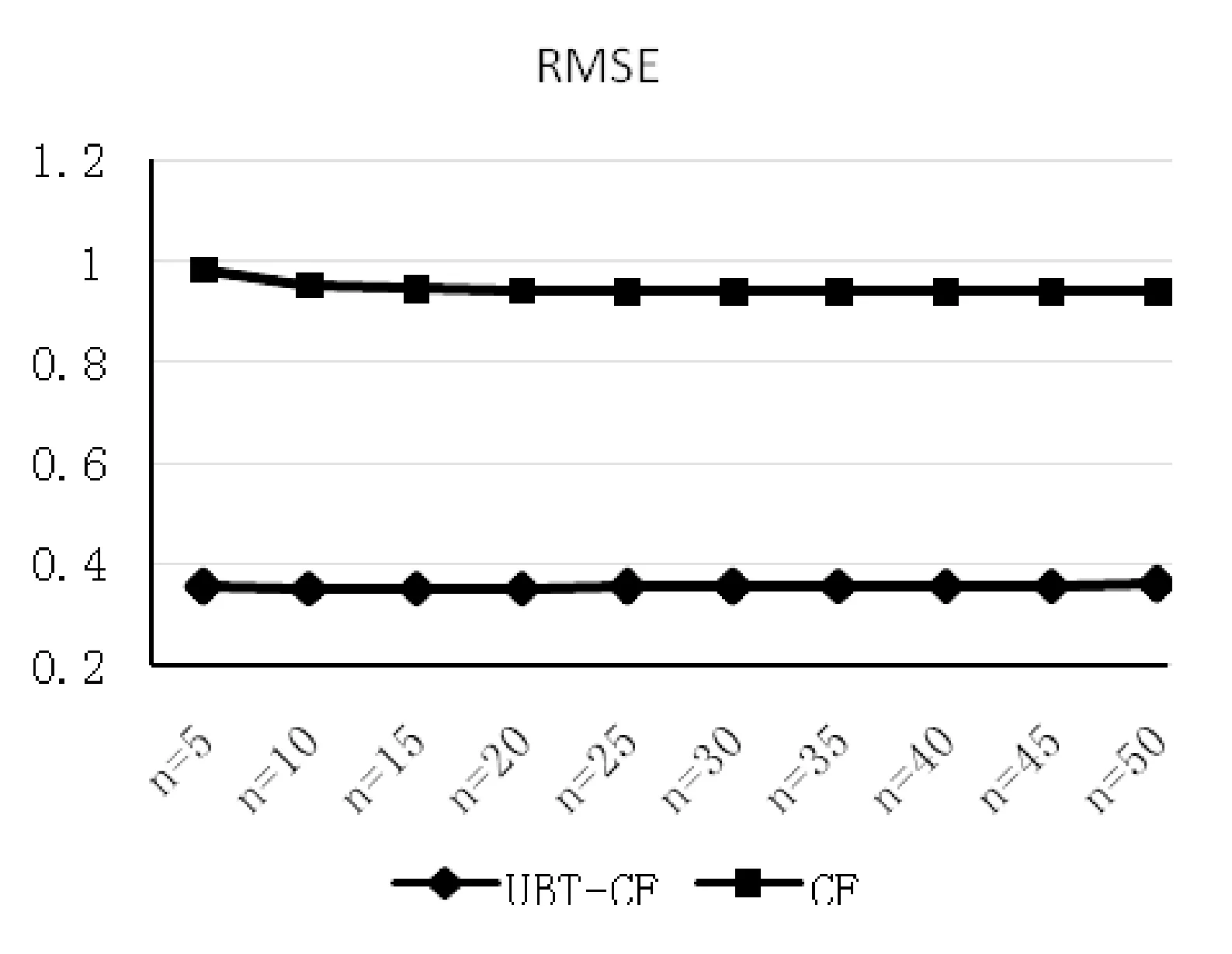
图3 传统CF与UBT-CF,RMSE值对比图
由图可以看出,本文提出的UBT-CF在MAE和RMSE评价指标上明显优于传统CF。由于MAE更擅长于低分值,为了进一步分析UBT-CF比CF优的原因,本文给出UBT-CF标签概率预测评分分布区间以及CF原始用户-物品预测评分分布区间。如图4所示。
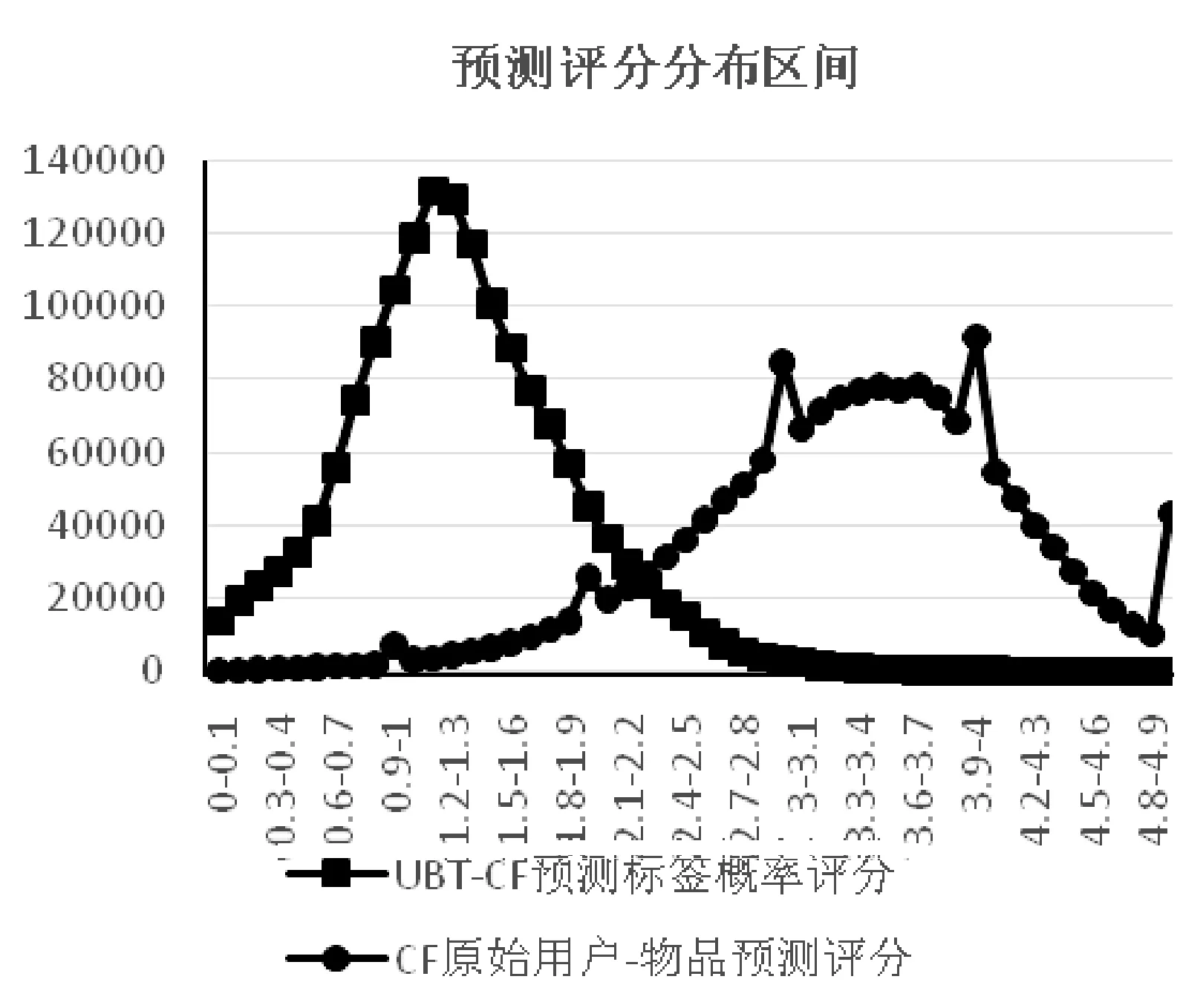
图4 UBT-CF与CF预测评分分布区间
由对比图可以得知,UBT-CF算出的预测概率评分个数超过98%分布在0.1~2.7之间,而传统CF算出的预测评分个数超过98%分布在2~5之间。经分析UBT-CF与CF预测评分分布区间图,本文得出由于本文数据集用的是标签概率评分,当与基于用户-物品评分的推荐系统进行比较时,由于MAE,RMSE没有考虑到数据分布区间不同的原因,对于偏低分的数据,会出现明显的优势。
为了更好地验证本文提出的方法以及使实验数据具有更好的说服性,本文还需要更为公平准确的评价标准,即标准平均绝对误差[20]NMAE(Normalized Mean Absolute Error)以及标准均方根误差[20]NRMSE(Normalized Root Mean Square Error),NMAE公式如下:
(8)
NRMSE公式如下:
(9)
式中:rmax为测试集中用户对物品的选择性概率评分最大值,rmin为测试集中用户对物品的选择性概率评分最小值。为了让数据更加缓和,NMAE,NRMSE均在数据区间上做了归一化处理,从而可以进行更好的比较。实验结果如图5所示。
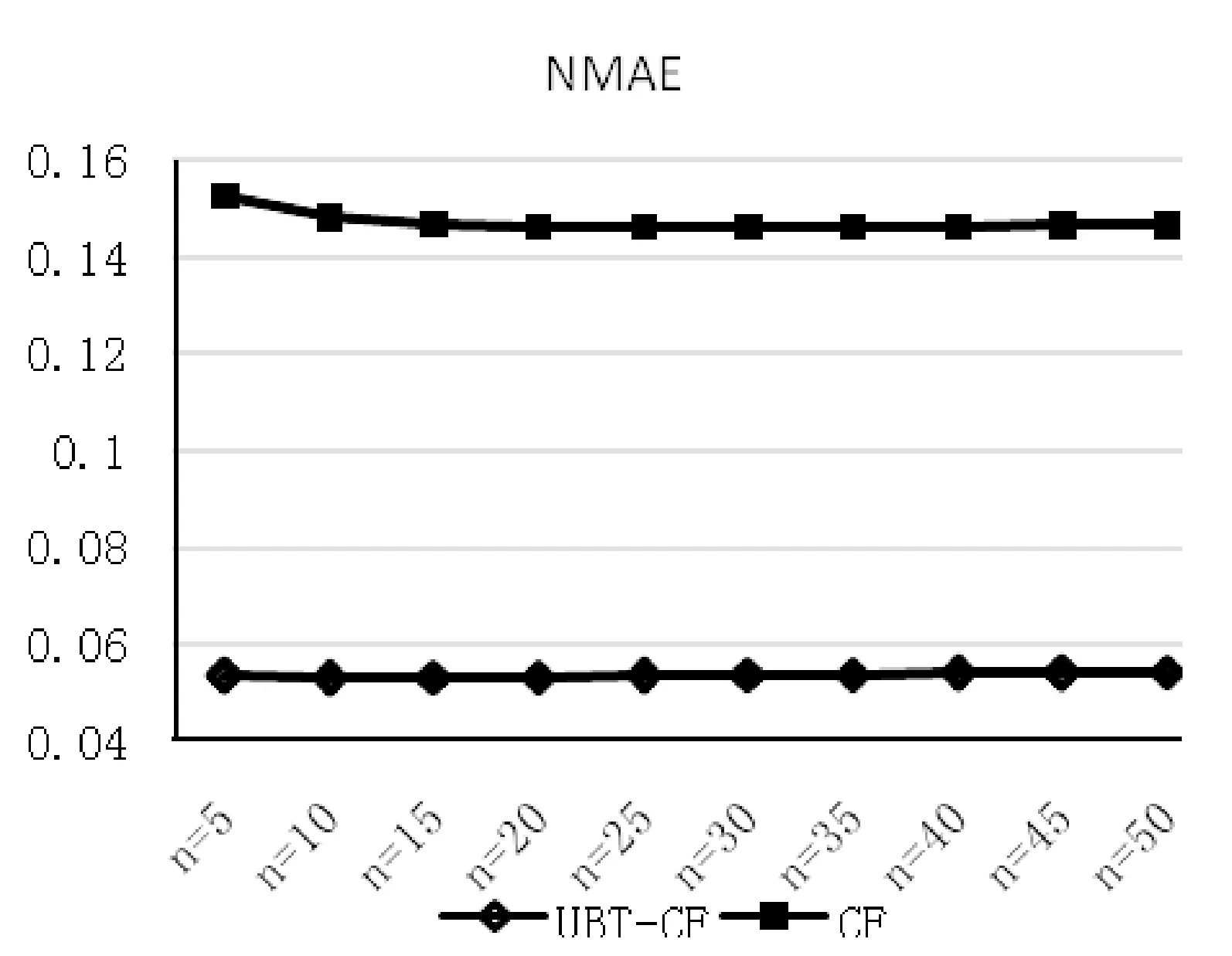
图5 传统CF与UBT-CF,NMAE值对比图
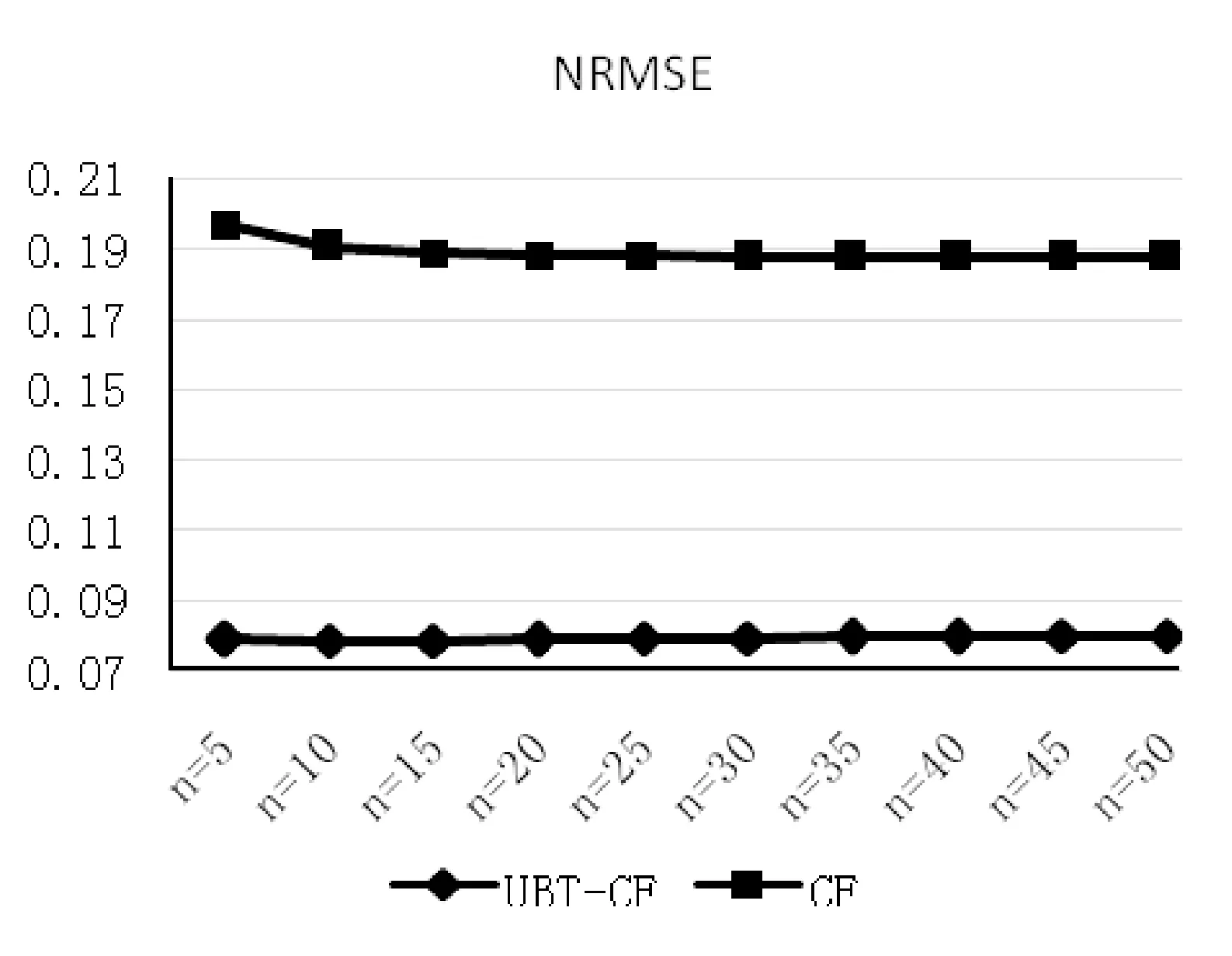
图6 传统CF与UBT-CF,NRMSE值对比图
由以上评价指标对比得知,与传统CF方法相比,无论是推荐系统中常用的的评价指标MAE,RMSE还是归一化后对两者更为公平的NMAE,NRMSE,本文所提出的UBT-CF方法都具有较小的评价指标值。因此,将用户行为和物品标签相结合,能有效提高推荐系统的质量,并且不受客观因素用户-物品评分的影响。
3 结 语
本文首先论述了用户评分的利弊,然后提出了一种结合用户行为和物品标签的协同过滤推荐算法,通过计算物品标签的概率,利用本文定义公式计算得到物品-标签概率评分值、用户-标签概率评分值、用户相似度以及用户-物品选择性概率预测评分值,然后生成对应选择性概率评分值矩阵,最后通过Top-N向目标用户进行个性化推荐。通过使用Movielens数据集对本文提出的算法进行对比验证,与传统基于物品标签的评分权重算法相比,本文算法可以更好地利用多标签并且不用考虑权重值的设置问题,从而避免了由于权重值设置不当而造成的推荐结果的不稳定。本文算法是基于结合用户行为和物品标签的,并且每当新电影的出现都会伴随已经匹配正确的分类标签,因此本文提出的结合用户行为和物品标签的协同过滤推荐算法可以很好地解决物品冷启动问题。实验结果证明,本文用传统的基于皮尔逊协同过滤推荐算法(CF)作为对比,提出的UBT-CF在MAE和RMSE以及更为公平的做了归一化处理的NMAE和NRMSE评价指标上明显优于传统CF,能有效提高推荐系统的质量。本文采取的相似度计算公式是基于皮尔逊的,下一步工作将着重利用不同相似度计算方法来更好地提高推荐算法的质量。
参 考 文 献
[1] Linden G,Smith B,York J.Amazon.com Recommendations:Item-to-Item Collaborative Filtering[J].IEEE Internet Computing,2003,7(1):76- 80.
[2] Huang Z,Zeng D,Chen H.A Comparison of Collaborative-Filtering Recommendation Algorithms for E-commerce[J].IEEE Intelligent Systems,2007,22(5):68- 78.
[3] 刘兆兴,张宁,李季明.基于协同过滤和网络结构的个性化推荐算法[J].复杂系统和复杂性科学,2011,8(2):29- 33.
[4] 赵超超.基于用户和基于项目结合的个性化推荐算法[J].内蒙古农业大学学报(社会科学版),2007,6(9):139- 142.
[5] Bogers T,Van B A.Recommending scientific articles using citeulike[C]//Proceedings of the 2008 ACM conference on Recommender systems,2008:287- 290.
[6] Hu Y,Peng Q,Hu X,et al.Time Aware and Data Sparsity Tolerant Web Service Recommendation Based on Improved Collaborative Filtering[J].IEEE Transactions on Services Computing,2015,8(5):782- 794.
[7] Wei J,He J,Chen K,et al.Collaborative Filtering and Deep Learning Based Recommendation System For Cold Start Items[J].Expert Systems with Applications,2016,69:29- 39.
[8] Sarwar B M,Karypis G,Konstan J A,et al.Application of dimensionality reduction in recommender system-a case study[R].Minneapolis:Minnesota University Minneapolis Department of Computer Science,2000.
[9] 王嵩,鲍长春,李晓明.参数音频编码回顾[J].信号处理,2011,27(4):575- 586.
[10] Liang H Z,Xu Y,Li Y F,et al.Connecting users and items with weighted tags for personalized item recommendations[C]//Ht’10,Proceedings of the 21st ACM Conference on Hypertext and Hypermedia,Toronto,Ontario,Canada,June.DBLP,2010:51- 60.
[11] 肖海力.Sc Grid冗余系统部署[R].北京:中科院计算机网络信息中心超级计算中心,2010.
[12] Zhang Z K,Zhou T,Zhang Y C.Tag-Aware Recommender Systems:A State-of-the-Art Survey[J].Journal of Computer Science & Technology,2011,26(5):767- 777.
[13] Tso-Sutter K H L,Marinho L B,Schmidt-Thieme L.Tag-aware recommender systems by fusion of collaborative filtering algorithms[C]//Proceedings of the 2008 ACM Symposium on Applied Computing.Fortaleza,Brazil,2008:1995- 1999.
[14] Lee T Q,Park Y,Park Y T.A time-based approach to effective recommender systems using implicit feedback[J].Expert Systems with Applications,2008,34(4):3055- 3062.
[15] Chen Yenliang,Cheng Lichen.A novel collaborative filtering approach for recommending ranked items[J].Expert Systems with Applications,2008,34(4):2396- 2405.
[16] Zhao Z D,Shang M S.User-Based Collaborative-Filtering Recommendation Algorithms on Hadoop[C]//International Conference on Knowledge Discovery and Data Mining.IEEE,2010:478- 481.
[17] Shardanand U,Maes P.Social information filtering:algorithms for automating “word of mouth”[C]//ACM Chi’95 Conference on Human Factors in Computing Systems,Volume 1 of Papers:Using the Information of Others.1995:210- 217.
[18] Breese J S,Heckerman D,Kadie C.Empirical analysis of predictive algorithms for collaborative filtering[J].Uncertainty in Artificial Intelligence,1998,98(7):43- 52.
[19] Herlocker J L,Konstan J A,Borchers A,et al.An algorithmic framework for performing collaborative filtering[C]//SIGIR’99: Proceedings of the,International ACM SIGIR Conference on Research and Development in Information Retrieval,August 15- 19,1999,Berkeley,Ca,Usa.DBLP,1999:230- 237.
[20] Balabanovic M,Shoham Y.Fab:content-based,collaborative recommendation[J].Communications of the Acm,1997,40(3):66- 72.
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31
新世纪智能(数学备考)(2021年4期)2021-08-06
新世纪智能(数学备考)(2021年4期)2021-08-06
中学生数理化·高三版(2021年3期)2021-05-14
中学生数理化·高三版(2021年3期)2021-05-14
疯狂英语·初中天地(2021年11期)2021-02-16
第一财经(2019年8期)2019-08-26
少年漫画(艺术创想)(2019年2期)2019-06-06
作文·初中版(2017年6期)2017-06-16
安徽医科大学学报(2015年9期)2015-12-16
