
基于语义标注的数据资源库元数据质量自动评估方法研究
2018-07-05 02:42郭晓明马良荔孙煜飞海军工程大学计算机工程系湖北武汉430033
计算机应用与软件 2018年6期
郭晓明 马良荔 苏 凯 孙煜飞(海军工程大学计算机工程系 湖北 武汉 430033)
0 引 言
元数据因其可以描述海量原始数据信息,起到简化问题的作用,是各领域信息资源常用的组织方式。在语义网中,存在大量的面向应用的各种数据库,蕴涵着数量巨大的重复和语义异构元数据信息[1],那么提高元数据质量成为数据集成应考虑的重点,如何使元数据描述信息更加全面、高效可用,基于本体的语义标注方法给元数据质量自动评估提供了思路。本体的类、子类对应与元数据的元素、子元素,本体也可以按照元数据的方式进行描述。同样,元数据也可作为本体的描述对象,对关系型数据库元数据进行基于本体的语义标注,通过元数据与本体之间的自动映射转换为具有统一标识的语义数据[2],将生成语义元数据存放数据库中。可用于标注的元数据为可用元数据,标记后生成的语义元数据更能表达数据库表的语义信息,从而提高数据资源库元数据的质量。因此,本文在基于元数据信息组织的基础上,研究关系型数据库元数据质量自动评估方法,提出了基于相似度计算的数据库元数据语义标注算法进行元数据自动语义标注。通过对数据库关系表元数据和本体类之间的相似度计算来实现数据库元数据的自动语义标注。经标注后生成的语义元数据单独存放,作为数据库中关系表的语义标签。
1 相关工作
对关系型数据库自动语义标注的研究随着本体研究展开,现有的方法多是研究关系型数据库模式和本体模式之间的模式转换[3-4],常用方法及已有的转换工具如下:
(1) 关系数据库模式转换成本体模型 FDR2# Kit[5]工具是关系数据库模式和本体间映射早期研究的代表,许多后续工作继承了它的基本思想。主要工作是先自动地将关系数据库模式转换为本体的形式表达,然后手工构建两者之间的简单对应。浙江大学开发的一套针对中医药领域的集成系统DartGrid[6]是其具体应用。文献[7]提出了基于本体和Karma建模的快速集成方法,通过Karma建模构建语义模型,发布成统一RDF数据和R2RML模型。文献[8]采用模式映射的方法从装备数据库中生成初始局部本体,通过本体映射对领域本体进行规范化处理。
(2) 利用中间模型转换 关系数据库到一个中间模型的映射和本体到另一个中间模型映射,通过两中间模型之间的映射,实现两模式之间的转换[9]。以Web-PDDL 语言描述的中间模型为媒介的OntoGrate系统[10];以树状结构模型为中间转换模型的MAPONTO映射工具[11]。文献[12]提出基于中间模型的映射算法,通过模型解析转换、映射规则设计、映射策略选择、映射关系表达等最终获得二者的映射关系。
(3) 本体模式与数据库模式语义映射 建立数据库模式和本体模式之间的语义映射,生成语义元数据作为语义映射的模板,以文件的形式存放在模板库中,实现数据库数据实例到本体实例的自动转换。文献[13]提出一种对Web数据库查询结果进行语义标注的方法。文献[14]提出了构建能够描述语义映射信息的语义元数据;文献[15]提出利用领域本体对关系型数据库的元数据进行语义标注的方法实现两模式之间的转换。文献[16]提出一种面向领域本体非分类关系的语义相关度计算方法。该方法在数据属性和对象属性两个方面分别计算语义相关度的方法。
上述方法多是以手工建立数据库模式和本体模式之间的对应关系,不适用现在自动本体标注的需要。文献[14-16]虽提到了自动标注,但仅仅是数据库表名与字段名所呈现的语义信息与本体概念之间的直接转换,是对表示描述数据表的元数据进行了语义标注,对描述表之间复杂关系的元数据没有提及。
2 数据库元数据语义标注框架
数据库元数据语义标注通用的语义标注流程如图1所示。针对各种规模的关系数据库经预处理后进行元数据自动提取算法得到元数据,利用本体库中通用的知识概念对元数据进行语义发现和标注,使得标注后的元数据含有丰富的语义信息,能够为语义集成系统提供数据库的相关语义信息。数据库语义标注的方法研究多数是采用数据库模式和本体模式的语义映射实现的,本文提出了新的语义标注方案,将在第3节中详细介绍。
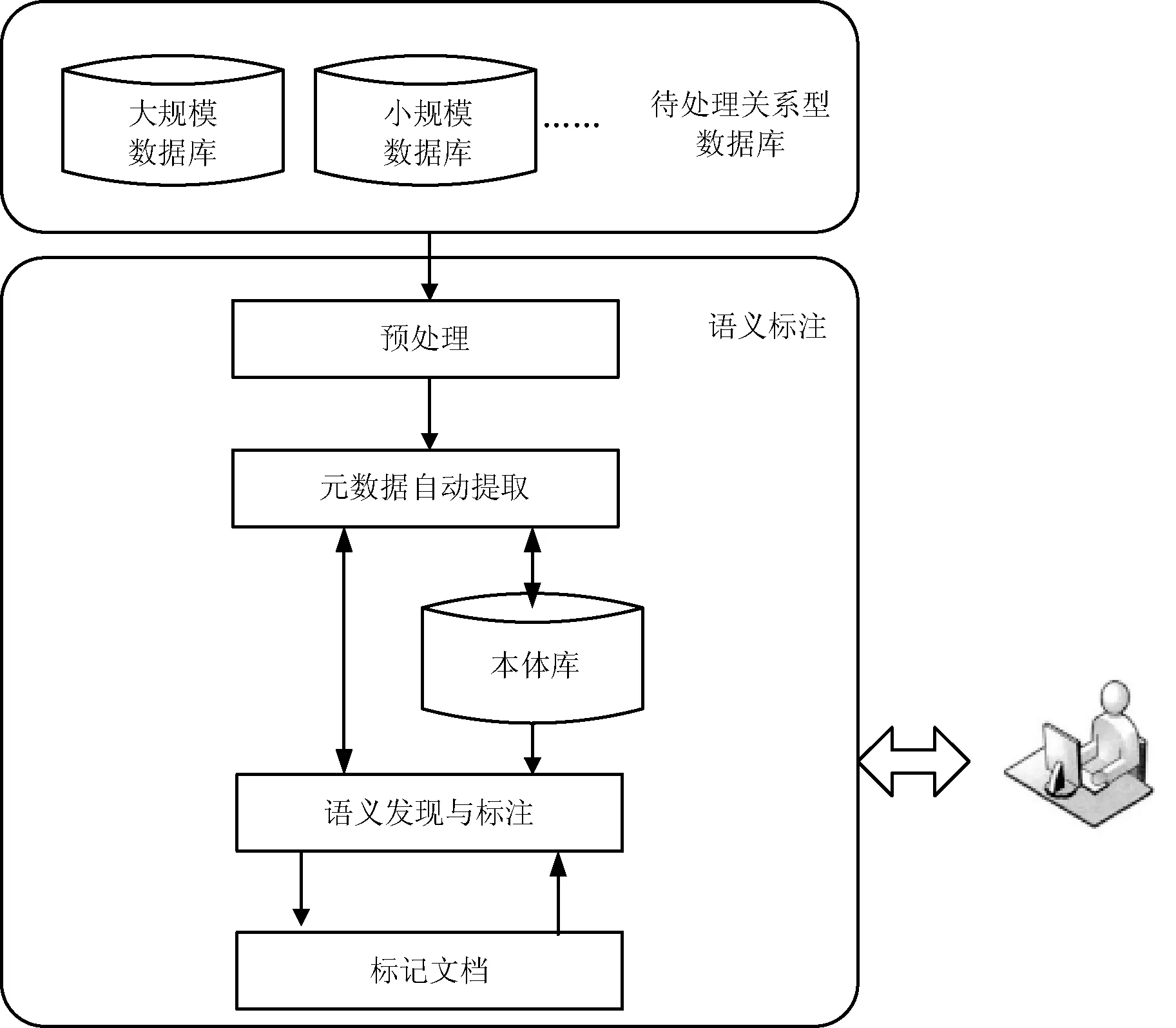
图1 数据库元数据语义标注通用流程
3 数据库元数据自动语义标注算法
关系数据库原语和OWL DL本体的逻辑基础都是一阶逻辑,建立关系数据库模式和本体间的映射在理论上是可行的。多数的映射方法是发现关系数据库模式中表、列和本体中的类、属性之间一对一简单映射。本文提出的方法通过引入关系数据库模式和本体间结构特征来体现它们对应的语义信息,基于简单映射查找多对多的复杂映射,从而实现本体对数据库表的语义标注。
数据库表的元数据包括:表(对象实体E)、字段(属性)、数据类型、表约束、主键、外键等。但这些元数据无法完成对表和字段的语义描述,利用本体对其进行语义标注,生成能够表达关系表结构和内容语义信息的语义元数据。一般而言,数据表可以映射到本体类;关系表的字段可以映射到本体属性;如果属性是外键类型属性,可以映射到本体中的一个对象属性,而非外键型属性可以映射到本体中的数据类型属性或对象属性。数据库模式与本体模式之间的简单映射如图2所示。
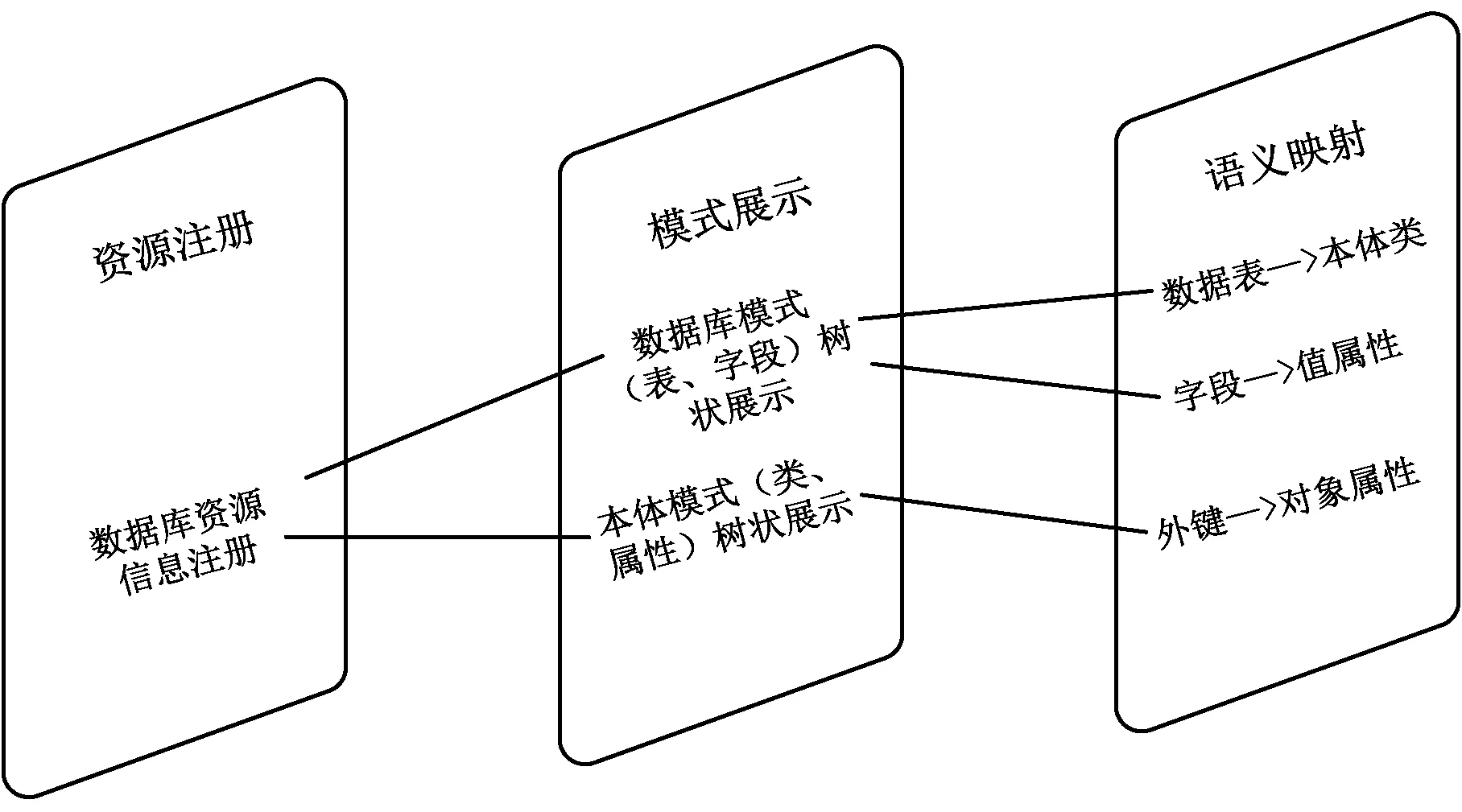
图2 数据库模式与本体模式转换流程
本节提出了基于相似度计算的语义标注算法DMSAAS(Database Metadata Semantic Annotation Algorithm based on Similarity),不但考虑表元数据和本体类之间的概念相似性,也考虑表关联关系与类关联关系之间结构的相似性,通过该算法找到更为准确的相关本体类。关系表和表的字段元数据蕴含着部分领域概念、概念之间的关系及属性,与本体中的类和属性存在对应关系,要对这些元数据进行语义标注,就是建立元数据与领域本体概念的语义映射,图3为关系数据库和本体的示例。
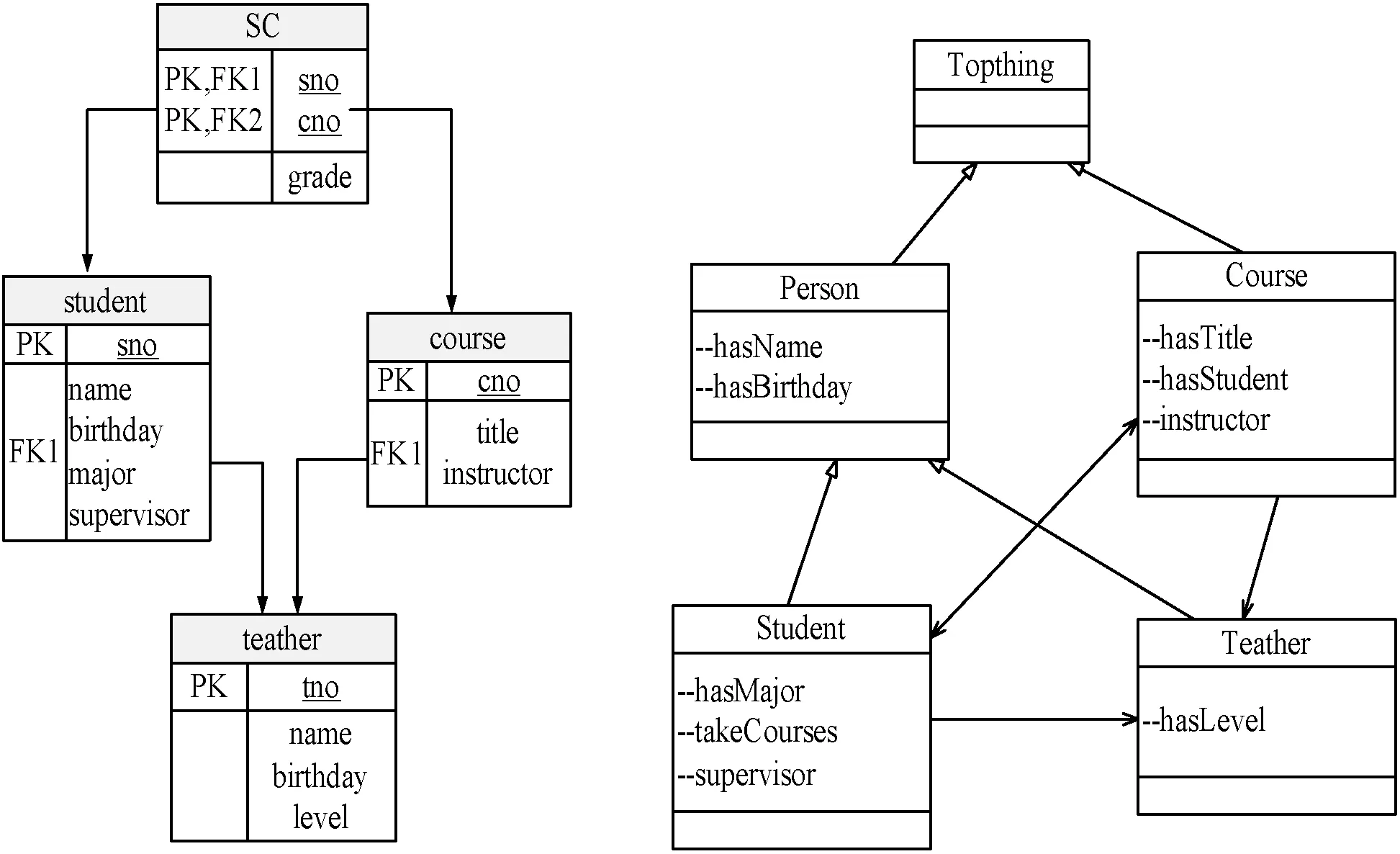
图3 关系数据库和本体的示例
语义标注的过程事实上就是计算元数据语义信息与本体的相似度。在本文中,关系表和类、外键列和属性名都是考虑名称的相似度,名称的相似度计算通用方法是使用基于字符串的相似度计算方法。
(1) 基于字符串的相似度计算:
基于字符串相似度计算的思想是:两个元素名称的字符串越相似,则这两个名称越相似。最常用、最传统的是基于编辑距离ED(Edit Distance)[15]的计算方法。
编辑距离算法是把一个字符串S={s1,s2,…,sn}转换成另一个字符串U={u1,u2,…,un}所需要的最少操作数目,包括对字符的插入、剔除、替换操作。编辑距离的语义相似度的计算方法为:
(1)
式中:s表示源字符串,u表示目标字符串,ED(s,u)表示s与u间的编辑距离,maxlength(s,u)表示s,u之间的最大长度。
最长公共子序列LCS(longest commom substring) 计算方法,是寻找两个字符串s与u间最长的公共子串,用LCS(s,u)表示,通过式(1)计算它们的相似度,长度越长相似度越高:
(2)
最终,经归一化处理后,名称相似度的计算方法是对SimED(s,u)和SimLCS(s,u)加权平均得到如下式:
Simname(s,u)=SimED(s,u)×ω1+SimLCS(s,u)×ω2
(3)
式中:ω1和ω2是可调节参数,ω1+ω2=1,ω1和ω2的取值可根据具体实验需求人工进行调整,文献[15]中总结出一般情况下,取ω1=0.6,ω2=0.4。
(2) 计算表和本体类的结构相似度:
当关系数据库的表和本体的类相似时,表的列和本体类的属性应该是相似的,同它们各自“关联”的表和类之间的相似性,如图3所示。数据库中表与表之间的关联是通过外键来表达,对于本体而言,类与类之间的关联是通过属性和关系来表达,因此计算表和本体类的结构相似度就显得十分重要。
关系表t和本体类oc的结构相似度计算如下所示:
simstr(t,oc)=simprop(t,oc)×ω1+simrel(t,oc)×ω2
(4)
式中:ω1+ω2=1,一般情况下,取ω1=0.6,ω2=0.4。
simprop(t,oc)表示表t和本体类oc各自属性之间的相似度,设表t的属性集合为A={a1,a2,…,an},本体类oc的属性集合为B={b1,b2,…,bm},计算公式为:
(5)
式中,a和b都是都表示属性,simname(a,b)表示两属性之间的相似度,主要采取名称相似度计算方法,其计算公式取式(3)。
simrel(t,oc)表示与表t和类oc相“关联”的表和类之间的相似度,Trel表示与表t有关联关系的表的集合,OCrel表示与本体类oc通过属性建立联系的实体类的集合。计算公式为:
(6)
式中:trel是与t连接的邻接表,可用表名代表;OCrel表示与本体类oc通过属性建立联系的实体类,也用类名表示。simname(trel,ocrel)表示邻接表和关联本体类之间的相似度,也采用名称相似度计算方法,其计算公式取式(3)。
综上,根据数据库元数据和本体类的对应关系,应综合考虑两因素:第一,考虑表对应类,首先计算表名与本体类概念名称相似度;第二,考虑到与表的结构有关系的元素是属性(字段)和相关联的表,计算表与本体类的结构相似度。对数据库表元数据的语义标注,即寻求能描述表元数据语义信息的领域本体的类(概念),可能是一类也可能是多类。
结合上面讨论,表与本体类的语义相似度应取式(3)和式(4)两者的加权平均值:
Sim(g,o)=Simname(g,o)×ω1+Simstruc(g,o)×ω2
(7)
式中:g表示表(表名或字段名),o表示本体实体,ω1和ω2表示权重,ω1+ω2=1根据实验或经验得出ω1=0.3,ω2=0.7。
利用上述的公式,对数据库表进行自动语义标注的DMSAAS算法流程如下:
算法DMSAAS
输入:数据库表元数据,领域本体库
输出:用于标注的本体类
Step1抽取描述关系表的元数据:表名,属性名。
Step2计算出与本体库中所有本体类的相似度,代入计算式(3)。
Step3通过计算表的属性集合与类的属性集合,表的邻接表集合和类的相关类集合的相似度计算,通过式(4)得到表和本体类的结构相似度。
Step4通过计算式(7),得到表的元数据与本体类的语义相似度算法,取最大值。
Step5如果最大值大于设定阈值,那么对应的本体类知识作为该项元数据的语义标注信息,标注成功。
Step6如果最大值小于等于设定阈值,表示没有与之匹配的本体,标注失败;创建新的本体加入本体库,重新计算。
Step7输出用于标注的本体类。
Step8算法结束。
4 实验验证
4.1 实验设计
为验证本文提出的数据库语义标注算法的有效性,本小节在公共数据集上进行实验。数据是MapOnto[17]项目测试集合中的用例,该测试集合中共有14组数据集,我们从中挑选4组作为测试数据集[18]:
用例1:3SDB中关系数据库模式3sdb1.sql.schema为基因表达分析生物样本数据库V1,本体文件3sdb1.owl为样本数据库V1的概念模型。
用例2:DBLP 中的关系数据库模式dblp1.sql.schema来自于 DBLP 计算机科学参考文献数据库,本体Bibliographic-Data.owl来自斯坦福大学 Ontolingua 服务器中有关参考文献的本体。
用例3:AMALGAM中关系数据库模式amalgam1.sql.schema为混合出版物关系数据库,本体文件amalgam1.owl为混合出版物概念模型。
用例4:University 的关系数据库模式utcs.sql.schema来自多伦多大学计算机系的学生与工作人员学术部门数据库,本体univ-cs.owl来自于DAML本体库中有关学术部门的本体。
相关统计数据如表1所示。

表1 MapOnto测试数据集统计数据
实验目的:检测本文提出的语义标注算法DMSAAS的有效性。
实验参照:对测试数据集人工标注的结果。
评测参数:通常是用精确度(precision)、召回率(recall)、F值度量(F-measure)来评价算法。
(8)
式中tp、fp、fn的含义如下:tp是发现正确的标注;fp为发现的错误标注;fn为未发现的正确标注。精确度表示经算法标注准确表占实际所有被标注表的比例。召回率表示经算法标注准确表与应该被正确标注表的比例。其中,实际被标注的表是经本文算法标注的结果,应该被正确标注的表是人工标注的结果。
4.2 实验结果及分析
检测本文提出的语义标注算法DMSAAS在公共数据集上的语义标注的结果,测试的标准映射结果由人工标注给出,结果如表2所示。
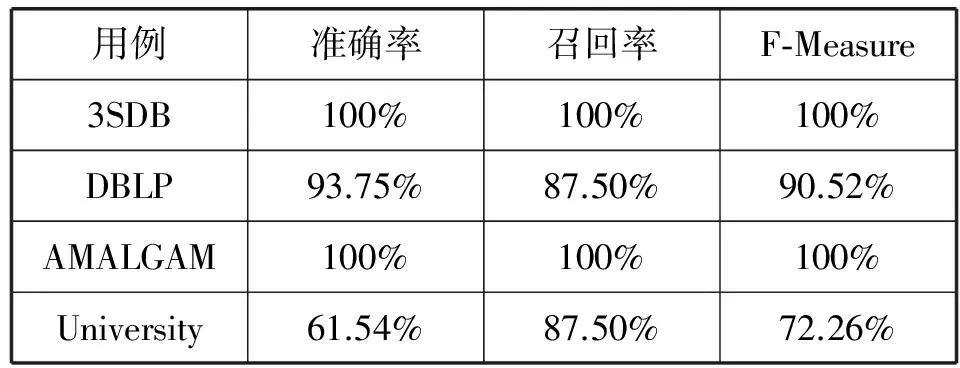
表2 实验结果
由表2中结果可以看出,本文算法在数据集3DSB和AMALGAM取得了较好的效果,准确率和查全率均达到100%。这是由于在这两个数据集中数据库中表的表名与本体中映射概念的概念名完全相同,且数据库中表的非外键属性名与本体中数值属性相似度较高。如数据库模式3sdb1.sql.schema中数据表Family_History中的ID属性与本体文件3sdb1.owl中的histID,数据库中的外键属性与本体中的对象属性在这两组实例中存在此类情况,尤其在AMALGAM用例中数据库具备7组外键表对应两张数据表之间的关系;在数据库模式文件amalgam1.sql.schema中外键表MiscPublished用于表述表Misc与表Author间的关系,在本体文件amalgam1中同样存在对象属性miscPublished用于表述概念Misc与概念Author间的关系,由于在这两组用例的名称及结构构造较为类似,使得本文的方法得分较高,取得较好的映射效果。
对于DBLP用例,数据库中表的名称不能完全与本体中概念的名称对应,如数据库文件的editor表,在人工标注情况下与本体中的Person对应。由于本文的名称相似度算法仅基于字符串的相似度,未考虑语义的相似度,因此无法得到一部分映射,同时由于部分映射未发现,导致在结构相似度计算时,与该种表存在外键关系的表与本体中的概念映射可能发生一定的错误,使得对该用例的映射结果较用例1和用例3的结果有一定程度下降。
对于University用例,在该用例的本体中存在多个概念名称中存在相同的词汇,如AdministrativeStaff、ClericalStaff与SystemsStaff等,且这些概念的属性信息相似度较高,使得数据库中相应的表,如technicalStaff计算名称和结构相似度的得分超过阈值,从而被错误的判断为映射,使得本文方法在该用例中得分较低,仅为61.54%。同时由于数据库与本体间存在部分名称相似度不高的表名和本体,使得系统的召回率未取得用例1及用例3中的效果,召回率值为87.50%。
本文算法的优势在于:综合表和类概念的名称相似度与表和本体类关系结构相似度,取其加权平均值。名称的相似度计算是求解字符串编辑距离法和最长公共子序列法的加权平均值,结构相似度计算是利用结构相似度特征计算其值,无需迭代。该方法目的使标注更加快速,结果更加准确。但本文的算法在计算名称相似度时并未考虑词汇的语义信息,使得名称相似度计算还未达到理想的效果,需要在下一步中进行改进。
5 结 语
本文在基于元数据信息组织的基础上,研究关系型数据库元数据质量自动评估方法,提出了基于结构相似度的数据库元数据语义标注算法进行元数据自动语义标注。该算法综合考虑关系表与本体类名称的相似度计算以及结构相似度计算。其中结构相似度细分为表所含列和类所含属性之间的相似度,以及同它们各自连接的表和类之间的相似度。经综合计算后相似度值大于阈值的本体类用于语义标注。因必须同时满足名称和结构的相似度的本体概念和属性才能用于语义标注,标注准确性较高。另外该算法无需迭代计算,标注效率高。
[1] 谢诚.基于自适应本体的异构数据语义集成框架研究[D].上海:上海交通大学,2012.
[2] 何向武.大数据中RDF语义数据存储优化探讨[J].计算机应用与软件,2015,32(4):38- 41,55.
[3] 刘海池.关系数据库模式到本体映射的研究[D].长沙:国防科学技术大学,2011.
[4] 刘歆.领域数据集成及服务关键技术研究[D].北京:北京科技大学,2016.
[5] Korotkiy M, Top J L. From relational data to RDFS models[C]//Web Engineering—4th International Conference, ICWE 2004, Munich, Germany, July 26- 30, 2004, Proceedings. DBLP, 2004:430- 434.
[6] 陈华均.DartGrid支持中医药信息化的语义网络平台实现[M].浙江大学出版社,2011.
[7] 于小洋,云红艳,贺英,等.利用语义技术实现Web Service数据的快速集成[J].青岛大学学报(自然科学版),2017,12(1):79- 84.
[8] 李亢,李新明,刘东.面向数据语义集成的装备领域本体构建研究[J].系统仿真学报,2015,22(5):1071- 1080.
[9] Pinkel C, Binnig C, Kharlamov E, et al. IncMap: pay as you go matching of relational schemata to OWL ontologies[C]//International Conference on Ontology Matching. CEUR-WS.org, 2014:37- 48.
[10] Dou D, Lependu P, Kim S, et al. Integrating Databases into the Semantic Web through an Ontology-Based Framework[C]//International Conference on Data Engineering Workshops. IEEE Computer Society, 2006:54.
[11] An Y, Borgida A, Mylopoulos J. Inferring Complex Semantic Mappings Between Relational Tables and Ontologies from Simple Correspondences[C]//On the Move to Meaningful Internet Systems 2005: CoopIS, DOA, and ODBASE, OTM Confederated International Conferences, CoopIS, DOA, and ODBASE 2005, Agia Napa, Cyprus, October 31-November 4, 2005, Proceedings. DBLP, 2005:1152- 1169.
[12] 贾贺,艾中良,刘忠麟.基于中间模型的异构数据资源语义映射方法[J].计算机工程与应用,2013,19(3):133- 138.
[13] 袁柳,李战怀,陈世亮.基于本体的DeepWeb数据标注[J] .软件学报,2008,19(2):237- 245.
[14] 黎建辉,余怀化,阎保平.基于元数据的关系数据库语义集成方法[J].计算机工程,2008,34(6):54- 56.
[15] 董国卿,童维勤.数据库元数据的自动语义标注[J].计算机科学,2012,39(11A):159- 162.
[16] 王红,樊红杰,孙康.面向领域本体非分类关系的语义相关度计算方法[J].计算机应用与软件,2016,33(11):16- 20,32.
[17] http://www.cs.toronto.edu/semanticweb/maponto/.
[18] http://www.cs.toronto.edu/~yuana/research/maponto/schemaMapping/.
猜你喜欢
科学与信息化(2021年15期)2021-12-30
科学与信息化(2021年12期)2021-12-27
哈哈画报(2021年10期)2021-02-28
小型微型计算机系统(2019年6期)2019-06-06
软件导刊(2016年11期)2016-12-22
青春岁月(2016年21期)2016-12-20
科技资讯(2015年8期)2015-07-02
图书与情报(2013年1期)2013-11-16
卷宗(2013年6期)2013-10-21
