
面向医疗的垂直搜索引擎的研究与开发
2018-07-05 02:09姚奕伸张旖旎陈恩泽陈晓星
科技与创新 2018年13期
姚奕伸,张旖旎,周 婷,陈恩泽,陈晓星
(华北电力大学 控制与计算机工程学院,北京 102206)
随着互联网技术的快速发展和医疗水平的不断提高,越来越多的用户选择上网搜索获取医疗信息。中国互联网络信息中心于2017年发布的《中国互联网络发展状况统计报告》显示,截至2016-12,中国网民规模达7.31亿,相当于欧洲人口总量,互联网普及率达53.2%,其中,手机网民规模达6.95亿,占比达95.1%,增速连续3年超10%[1].医疗信息检索就是众多网络行为中重要的一部分。
在实际应用中,用户常选用通用搜索引擎,比如百度、Google检索医疗信息。的确,这类综合性搜索引擎资源范围广,用户可以在搜索框中输出关键词检索出几乎任何类型、任何主题的信息,但是,正是由于其信息资源的广阔性,出现了死链接繁多、广告层出不穷、相关度精准度低等问题,给用户带来了烦恼,且在一定程度上误导用户[2]。轰动一时的魏则西事件更是揭露了混淆用户视听的百度竞价排名机制,引起了大量网民的口诛笔伐。针对这些问题,垂直搜索引擎应运而生。垂直搜索引擎[3]是针对某一个行业的专业搜索引擎,是搜索引擎的细分和延伸,是对网页库中的某类专门信息进行一次整合,定向分字段抽取出需要的数据进行处理后再以某种形式返回给用户。垂直搜索引擎的召回率和准确率远高于综合性搜索引擎,因为它的特定信息来源于特定的网站,在一定程度上保证了它的准确率。
相比于通用搜索引擎,“医家搜索”专门针对医疗行业的特定信息,致力于实现高召回率和高准确率的医疗信息搜索,同时保证少之又少甚至零的广告。通过搜集大量医院网址,借助于开源搜索引擎Nutch,搭建出小型服务器,为用户提供了一定的医院信息服务,同时也实现了移动端的服务。
1 垂直搜索引擎工作原理
搜索引擎为用户查找网上的资源,它的爬虫会按照设定好的策略爬行,并采集信息,经过处理后将结果返回给用户。通用搜索引擎由网页爬虫、页面分析、索引和检索4个基本模块构成。
1.1 网络爬虫
爬虫(crawler),是用来在网络上进行信息抽取的程序。它从起始网站出发,按照一定的策略,遍历网站并且抓取各类型的网页内容。由于互联网上的信息非常庞大,爬虫不可能抽取到所有的信息,因此,需要按照一定的策略进行爬取。常见的网络采集策略有深度优先采集、IP扫描采集和广度优先采集3种策略[4]。
1.2 页面分析
为了便于建立索引,通用搜索引擎常在抓取完数据后进行一定的预处理,一般包括页面语法分析、词汇分割、词汇过滤等。垂直搜索引擎还需要进行更深的数据挖掘和信息类型的判断等操作,从而提高搜索的精准度。
1.3 索引
搜索引擎普遍使用的技术是倒排索引。所谓“倒排索引”,是相对于正向索引来说的,正向索引用来存储每个文档对应的单词列表,而倒排索引则是根据单词来索引文档编号,每个单词后边的文档编号列表叫做投递列表。索引可使检索对网页的定位更加精确,减少计算时间,提高搜索引擎效率。
1.4 检索
检索模块为用户提供了一个方便检索的接口,在用户搜索相应的关键词后,搜索引擎对检索到的结果进行排序后呈现给用户。排序主要依据搜索词的相关度和权值,此外,还需考虑网页的重要性和链接程度。
2 垂直搜索引擎的特点
与通用搜索引擎抓取海量信息不同,垂直搜索引擎主要用于特定主体的抓取。垂直搜索引擎比通用搜索引擎的结果更加精准,它的爬虫具有过滤功能,可实现对特定网页的抓取,无关网页的过滤。
2.1 垂直搜索引擎
垂直搜索引擎与通用搜索引擎的结构基本相同,唯一的差别就是前者的爬虫在抓取信息时会进行一定的判别。这样,就保证了爬虫在工作时不会受到不相关信息的干扰,为返回准确的结果打下基础。
2.2 垂直搜索引擎与通用搜索引擎的区别
垂直搜索引擎与通用搜索引擎原理大致相同,但垂直搜索引擎也有自己比较明显的特征,两者的区别主要体现在以下几个方面:①爬行策略。通用搜索引擎要实现的是更多的信息,所以,它倾向于全网的爬取;而垂直搜索引擎则只需爬取具有特定主题的网页,爬取专业领域的深采集。②服务对象。通用搜索引擎面向全体网络用户,其数据覆盖面比较广,但其相对于某一特定领域的专业性比较差;垂直搜索引擎服务于专业人士或某一专业领域的检索,因此,更加注重抓取的行业相关度和深度。③信息处理。通用搜索引擎注重网页元数据的处理和结构化信息的提取,在网页排序方面通常采用PageRank算法;垂直搜索引擎还要在信息处理中加入主题判别功能,在排序方面比较多样化。
3 面向医疗的垂直搜索引擎
面向医疗网站的搜索引擎的主要目标是实现对某地区各大医院网站、各科室的精准搜索,同时,还实现了对广告的隔离,为用户提供简洁直观的搜索结果。因此,面向医疗的垂直搜索引擎应当至少包括以下几个功能:①对特定医院网站的数据采集,信息抽取;②对分类后的数据生成倒排文件和数据管理;③简单易操作的界面和直观的返回结果。
根据以上功能需求,本文提出了一种基于Nutch的面向医疗网站的垂直搜索引擎,其工作流程如图1所示。
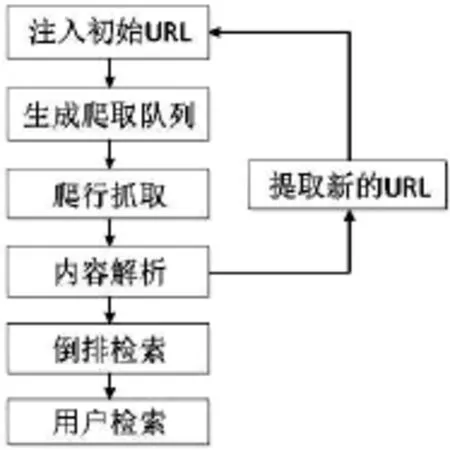
图1 垂直搜索引擎工作流程图
基于Nutch的面向医疗的搜索引擎的搭建步骤如下。
3.1 工作环境的安装和变量的设置
Nutch是Java开发的开源项目,需要在JDK、Linux下工作,本搜索引擎使用JDK1.7,cygwin(Linux虚拟器),Nutch1.2来搭建[5]。如果需搭建分布式环境,则还需要Hadoop[6]。另外,在环境变量中分别为JDK、Nutch和Tomcat配置环境变量。
3.2 为Nutch和Tomcat分别设置工作条件
在nutch-1.2confNutch-site.xml中为Nutch设置工作信息,这些信息会附加在发给服务器的信息中,遵循HTTP协议。在之间添加以下内容:格式如下:

同样,在TomcatconfNutch-site.xml下为Tomcat配置相关信息,其信息与Nutch对应目录下一致。
3.3 加入相关网站
本搜索引擎面向医疗,因此,爬虫要抓取的应是医疗方面的相关网站。利用一段简单的Java小程序找到行业网站,经过实际操作观察后,编写特定规则的Java程序,获取包含所需网址链接的网页链接。同时,编写Java代码获取网页源码。编写所需网址类型的正则表达式,采用首尾截取方式截取相关字段,以准备好的正则表达式匹配之,最终获得我们所需的网址链接。将获得的链接整理好放于文档中,用Nutch爬取,所得结果存储于Nutch中的用户自行命名创建的文档中。采用这种方式,我们直接获得所需的一手资料,获得属于自己的数据库,能极大程度地剔除广告带来的影响。这样,就可以得到大量与医疗相关的网站。我们将其放在Nutch根目录下自己新建的一个文本文档中,命名为seed.txt。
3.4 对相关URL进行爬取
在Cygwin下进行相应的命令操作:①利用cd命令进入到Nutch的根目录下。②利用bin/nutch crawl seed.txt-dir crawl-depth 1-topN 1000-threads 5命令进行抓取,seed.txt是存放目标抓取网站的文本文档;dir后跟爬取到的数据所存放的文件夹;depth为爬取的深度,此处设置为1;topN为爬取的广度,此处设置为1 000;threads为爬虫设置线程数,此处设置为5.至此,本文的垂直搜索引擎已搭建完成,借助于Sunny垂Ngrok,我们将本地服务器的端口与申请的域名绑定在一起,实现移动端的搜索。
4 试验测试及性能分析
召回率[7],是衡量某一检索系统从文献集合中检出相关文献成功度的一项指标,即检出的相关文献与全部相关文献的百分比。普遍表示为:召回率=(检索出的相关信息量/系统中的相关信息总量)×100%.
在召回率的实验中,大量文献表明,通用搜索引擎的召回率远低于垂直搜索引擎。由于百度、搜狗、Yahoo等通用搜索引擎基于其数据库信息保密的需要,我们无法精确地具体得知这些通用搜索引擎系统中的相关信息总量,但是,可以通过大量查询得知中国人民解放军医院北京地区总共有13家,在百度、搜狗、Yahoo这3个搜索引擎中,对于这13家医院,笔者一一检索均能进入其网站或者掌握该医院数据库的网站,然而当检索的关键词为北京军队医院官网时,检索的相关信息量就很少了。同样的,医家搜索库里放了11个解放军医院的官网,检索出来的网站为6,由此可以进一步推断,医家搜索的查全率高于通用搜索引擎。检索结果对比如表1所示。
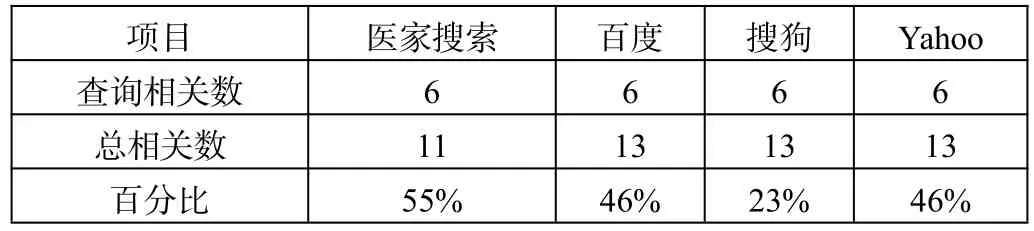
表1 检索结果查全率对比图
在医家搜索中输入“北京军队医院官网”,检索结果如图2所示。

图2 “北京军队医院官网”检索结果图
研究表明,用户希望检索结果能随相关度降序排列[8]。因此,前几页的搜索结果往往是用户最为关注的。搜索引擎用户通常只浏览前2页的检索结果,而且前3个检索结果最为重要,其次是接下来的7个检索结果,而后是再接着的10个检索结果[9]。
在搜索框内输入关键词“心血管”,检索结果如图3所示。

图3 关键词“心血管”检索结果图
所以,实验选取“心血管”“消化”2个医疗领域的关键词进行检索,统计前2页的检索结果中与医疗主题相关结果的个数,计算检准率,并与主流通用搜索引擎进行比较,得出结果如表2所示。
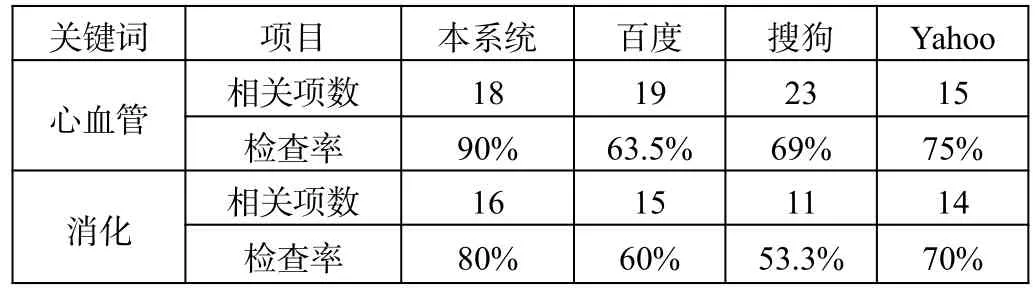
表2 检查结果相关性及排序质量分析
分析表2中的数据可知,本搜索引擎相对于通用搜索引擎,检准率平均高出30%.虽然通用搜索引擎检索信息量大,但多为重复信息或不相关信息,对于用户而言都是无用的。实验表明,在检索医疗信息方面,本搜索引擎比通用搜索引擎更为准确。
5 总结
本文基于Nutch,为用户提供了医疗方面的信息检索服务,相比于百度、雅虎等搜索引擎,它具有更高的召回率和检准率,且广告等冗余信息大大减少。与此同时,本文的搭建方法具有普适性,他人可以据此搭建其他领域的垂直搜索引擎。
但我们尚有不足:①信息的捕获过于烦琐,需要人工操作,并不适应当今社会信息的爆炸增长;②中文分词的功能不够强大,搜索的精准度有待进一步提高;③检索的结果未能细化到某一科室,对用户来讲检索效率比较低。
在大数据时代的背景下,关于垂直搜索引擎技术的探讨一直在继续,相信我们的不足会被有效解决。
[1]CNNIC发布第39次《中国互联网络发展状况统计报告》[J].中国信息安全,2017(02):24.
[2]施俭,王恒山,肖仰华,等.面向主题的垂直搜索引擎系统的研究与实现[J].微电子学与计算机,2011(7):1-4,8.
[3]百度百科“垂直搜索”词条[EB/OL].[2017-11-23].https://baike.baidu.com/item.
[4]袁恩阁.基于Nutch的医疗搜索引擎的研究与开发[D].乌鲁木齐:新疆大学,2014.
[5]胡涛,路红英.基于Nutch的搜索引擎的研究[J].计算机时代,2007(1):57-59.
[6]程苗,陈华平.基于Hadoop的Web日志挖掘[J].计算机工程,2011(11):37-39.
[7]准确率(Accuracy),精确率(Precision),召回率(Recall)和 F1-Measure[EB/OL].[2017-12-01].https://rc.mbd.baidu.com/gk77wmo.
[8]Cortes C,Mohri M,Rastogi A.An Alternative RankingProblem for Search Engines[C]//International Conference on Experimental Algorithms.Springer-Verlag,2007:1-22.
[9]Leighton,H.V.,&Srivastava,J.First 20 Precision Among World Wide Web Search Services(Search Engines)[J].Journal ofAmerican Society for Information Science,1999(10 ):870-881.
猜你喜欢
房地产导刊(2022年10期)2022-10-18
计算机与网络(2022年2期)2022-03-17
现代信息科技(2021年21期)2021-05-07
成都信息工程大学学报(2021年6期)2021-02-12
疯狂英语·新阅版(2020年11期)2020-12-21
智能计算机与应用(2018年5期)2018-10-20
魅力中国(2018年5期)2018-07-30
电脑知识与技术·经验技巧(2018年1期)2018-05-30
中学科技(2016年7期)2017-05-16
科学导报·学术论坛(2013年5期)2013-06-26
