
面向月面探测的空间机器人⁃航天员手势交互方法的研究
2018-06-28 11:42刘金国张飞宇郑永春
载人航天 2018年3期
高 庆,刘金国,张飞宇,郑永春
(1.中国科学院沈阳自动化研究所机器人学国家重点实验室,沈阳110016;2.中国科学院大学,北京100049;3.中国科学院国家天文台,北京100012)
1 引言
月面人机联合探测是载人月球探测任务的基础,是制定载人登月任务模式、设计登月飞行器系统方案的前提。对于月面人机联合任务,月面六分之一重力环境、多自由度被控机器人以及人机多空间范围等特点给传统空间人机交互方法带来了很大的挑战[1]。随着计算机和人工智能技术的发展,月面人机交互方式从以机器人为中心逐渐发展到目前以航天员为中心。其中,手势交互是新型交互方式中的一种主要技术路线,其自然、直观、且不受环境限制等优点非常适合空间人机交互任务[2⁃3]。手势识别是手势人机交互中的核心技术,很多学者都对其进行了深入的研究。针对面向月面探测的人机交互任务,按航天员与月面探测机器人的空间位置可分为航天员在空间舱内、空间机器人在月面的遥操作和航天员、空间机器人同在月面的近距离交互控制两种。对于前者,航天员可用裸手进行交互;对于后者,航天员需要穿戴航天服手套进行交互。因此,该部分的复杂性也使面向月面探测人机交互的手势识别具有更大的难点和挑战。
手势识别技术中,基于视觉的手势识别方法目前还处在发展阶段,随着kinect等深度传感器的出现,融合深度和彩色图像信息的视觉手势识别成为目前主流的研究方向。应用深度图像可以很好地解决传统红绿蓝(Red,Green,Blue,RGB)图像受到背景和光照影响的问题,能有效提高手势的识别率[4]。在识别算法方面,传统的视觉手势识别算法包括动态时间规整法(Dynamic Time Warping,DTW)、人工神经网络法和隐马尔科夫模型法等,都存在一些问题。随着深度学习在图像识别领域的发展和成功,越来越多的学者开始将深度学习方法应用于视觉手势识别的研究中,并取得了一定的研究成果[5⁃8]。
本文针对航天员⁃空间机器人交互手势交互的需求,设计一种手势人机交互框架。并针对8种静态的空间人机交互手势,设计一种双通道并联网络结构。将RGB图像的分类结果与对应深度图像的分类结果融合,得到最后的预测结果。
2 空间机器人⁃航天员手势交互框架
空间机器人选择由中国科学院沈阳自动化研究所研制的第二代航天员助手机器人(AAR⁃2)[9⁃10],它可以作为航天员的助手辅助或者代替航天员在月球表面恶劣环境中完成任务。该机器人具有6个自由度,可利用自身的位姿传感器和涵道风扇推进系统在微重力环境中自由飞行或悬停;且具有一定的环境感知能力和手势识别能力,航天员可通过手势操控该机器人完成一些特定的任务。图1所示为航天员在月球表面通过手势操控航天员助手机器人。
为航天员与空间机器人的手势交互,需要设计一套空间人机交互手势语义库。为了实现手势库的通用性,从如图2所示的American Sign Language(ASL)手势[11]中选取8种(图2方框中)作为空间人机交互手势,其对应的手势语义如表1所示。
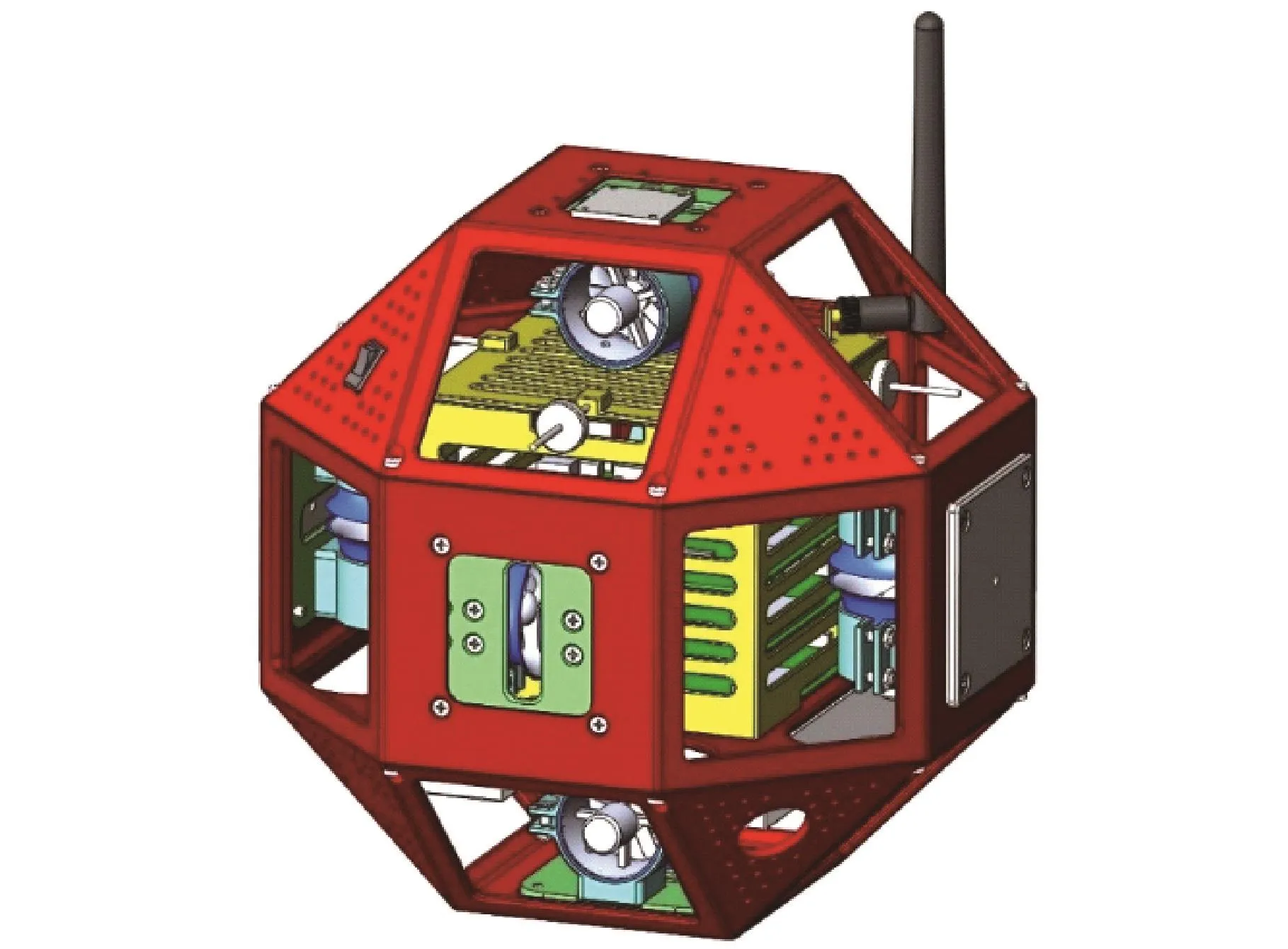
图1 AAR⁃2 机器人 3D 模型[9]Fig.1 3D solid model of AAR⁃2[9]
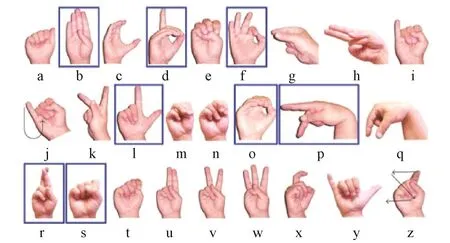
图2 空间人机交互手势[11]Fig.2 Space human⁃robot interaction hand ges⁃tures[11]

表1 空间人机交互手势语义对照表Table 1 Space human⁃robot interaction gesture seman⁃tic comparison table
3 深度学习模型
手势具有颜色、形状、空间深度等多种信息,利用多种信息融合的方式可以实现更好的手势识别效果[12⁃13]。 因此,本文针对手势的静态识别问题,从信息融合的角度出发,提出一种图3所示的并联卷积神经网络结构。RGB⁃CNN通道用来处理手势的RGB图像,以手的颜色特征为主要信息对手势进行识别;Depth⁃CNN通道用来处理手势的深度图像,以手的深度特征为主要信息对手势进行识别;最后将两个通道的输出结果进行融合,实现手势语义的最终预测。RGB通道主要对手势的颜色信息及细节特征进行提取,深度通道可以弥补RGB图像受光照及背景影响的问题,并能提取手势的深度信息,将两个通道的预测结果进行融合,可以更充分地利用手势的信息,因此理论上能提高手势的识别率。

图3 并联卷积神经网络结构图Fig.3 The structure of the parallel CNNs
3.1 网络结构
本文提出方法的网络结构如图4所示。该网络借鉴了 Ciresan的并联结构思想[14],将 RGB⁃CNN子网络和Depth⁃CNN子网络以并联的方式运行,先分别对手势的RGB图像和对应的深度图像进行预测,再将预测结果进行融合,得到最终的预测结果。下面分别对两个子网络和预测结果融合方式进行说明。
3.1.1 RGB⁃CNN 子网络
RGB⁃CNN子网络结构如图4所示,该网络共有7层,前4层为卷积层,后两层为全连接层,最后一层为分类层。具体来说,输入为3通道的尺寸为100×100的RGB图像,经过一个具有9个5×5卷积核的卷积层、一个ReLU层和一个核为2×2的最大池化层,转化为9个尺寸为48×48的特征图;再经过一个具有18个5×5卷积核的卷积层,一个ReLU层和一个核为2×2最大池化层,转化为18个22×22的特征图;再经过一个具有36个5×5卷积核的卷积层,一个ReLU层和一个核为2×2的最大池化层,转化为36个尺寸为9×9的特征图;再经过一个具有72个卷积核的卷积层和一个ReLU层,转化为72个尺寸为5×5的特征图;再经过一个具有144个神经元的全连接层和一个具有72个神经元的全连接层,最后采用softmax方法进行分类,得到具有针对8种语义手势的预测概率。

图4 并联CNN网络结构Fig.4 The structure of the parallel CNNs
整个子网络中,除了softmax层,其余每层都含有一个Rectified Linear Unit(ReLU)层,其激活函数表示为式(1)[7]:

其中,z为输出神经元的值。分类层采用softmax[2]方法,其表达式为式(2):

其中,x为手势的观察量,C为手势实际语义的神经元,W为网络的权值参数,zq为神经元q的输出。
3.1.2 Depth⁃CNN 子网络
Depth⁃CNN子网络与RGB⁃CNN子网络结构类似,最后得到具有8种语义手势的预测结果。
3.1.3 结果融合方法
RGB⁃CNN子网络中,网络参数为WRGB,手势的观察量为x,则对于手势语义C的预测概率为P(C|x, WRGB)。 Depth⁃CNN 子网络中,网络参数为WD,手势的观察量为x,则对于手势语义C的预测概率为 P(C|x, WD)。 根据文献[15]中提出的融合方法,对两个子网络的预测概率进行融合,得到最终的手势分类器针对8种语义手势的预测概率为式(3):

3.2 训练
训练的过程中,将数据分成几批(batches)进行训练,可以提高训练的效率。令每批数据的数量(batch_size)为 N,此时的 loss函数为为式(4):
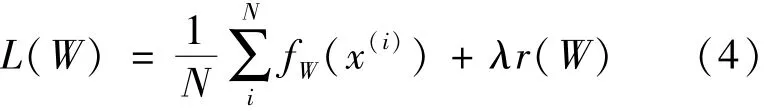
其中,fW(x(i))计算的是数据 x(i)上的 loss,先将每个单独的样本x的loss求出来,然后求和,最后求均值。 r(W)是权重衰减相(weight_de⁃cay),为了减弱过拟合现象。有了loss函数后,就可以迭代地求解loss和梯度来优化这个问题。在神经网络中,用forward pass来求解loss,用back⁃ward pass来求解梯度。
本文的梯度求解方法采用了随机梯度下降法(Stochastic Gradient Descent,SGD),SGD 在通过负梯度L(W)和上一次的权重更新值Vt的线性组合来更新 W,迭代公式如式(5) ~ (6)所示[16]:

其中,α是负梯度的学习率(base_lr),μ是上一次梯度值的权重(momentum),用来加权之前梯度方向对现在梯度下降方向的影响。这两个参数需要通过tuning来得到最好的结果,一般是根据经验设定的。t表示当前的迭代次数。学习率的调节方法选择step均匀分布策略,该方法能使网络前期快速地收敛,后期减小震荡,趋于稳定。其计算公式如式(7)所示:

其中,α0表示初始学习率,γ为调节参数,一般设置为0.1,s表示调节学习率的迭代长度,即当当前迭代次数t达到s的整数倍时,进行学习率的调节。
4 验证试验
4.1 手势数据库
依据上述设计的并联卷积神经网络手势识别方法,在ASL数据集上对8种空间人机交互手势进行识别,ASL数据集如图5所示,其中粗方框中为选择的空间人机交互手势数据集。每个手势包含5000个样本图片,其中2500张 RGB图片,2500张深度图片,分别由5个人在不同的背景和不同光照之下完成。则实际的手势图片样本经过镜像处理可得到共80 000张图片,选取其中的60 000张作为训练样本,剩余20 000张作为测试样本。图片经过尺寸变换、数据范围变化和均值操作等预处理后,输入到网络。

图5 ASL手势数据库Fig.5 ASL hand gesture database
4.2 试验平台
物理试验采用FT⁃200小型气浮平台模拟月面六分之一重力环境,在大理石平台上进行试验验证,如图6所示。

图6 物理实验平台Fig.6 Physical experiment platform
试验的硬件设备选择 Intel Core i5⁃6400 CPU,NVIDIA GeForce GTX 1060 6 GB GDDR5,16 GB内存。试验在Ubuntu 14.04 64bit OS系统环境下的Caffe开发环境进行。
4.3 试验结果及分析
按照上述网络结构,分别采用RGB⁃CNN网络、Depth⁃CNN网络和两个子网络并联的RGBD⁃CNN网络在ASL数据集上对上述8种空间人机交互手势进行静态手势识别试验,可获得关于三种网络的训练误差、测试误差和测试准确率的数据,如图7~图9所示。

图7 训练误差对比图Fig.7 The comparison of training errors

图8 测试误差对比图Fig.8 The comparison of test errors

图9 测试准确率对比图Fig.9 The comparison of test accuracies
图7 为三种网络的训练误差对比图,从图中可以看出,三种网络的训练误差最终都趋于0。图8为三种网络的测试误差对比图,RGB⁃CNN网络的测试误差趋于 0.356,Depth⁃CNN 网络的测试误差趋于1.071,RGBD⁃CNN网络的测试误差趋于0.331。三种网络的测试准确率如图9和表2所示,RGB⁃CNN网络的测试准确率趋于90.3%,Depth⁃CNN 网络的准确率趋于 81.4%,RGBD⁃CNN网络的测试准确率趋于93.3%。因此可知,本文所设计的并联卷积神经网络结构相较于传统的RGB卷积神经网络和深度卷积神经网络,在静态手势识别任务的准确率上具有一定的优势。

表2 网络测试准确率对比Table 2 The comparison of test accuracies
除此之外,本文还将提出的并联卷积神经网络方法的试验结果与 Pugeault[17]和 K.Otiniano[18]提出方法的试验结果进行了对比,如表3所示。

表3 网络测试准确率对比Table 3 The comparison of test accuracies
三种方法均采用ASL数据集,且均使用了RGB图像和深度图像融合的方法。从表3可以看出,本文所提出的并联卷积神经网络方法实验的准确率要高于Pugeault和K.Otiniano等学者提出方法的准确率。因此本文提出的方法对于静态手势识别准确率的提高有很好的效果。
在月面探测的人机交互过程包括舱内裸手操作和舱外佩戴航天服手套的操作,而上述试验的ASL数据库只有裸手图片。为了进一步实现手势识别方法对于月面探测过程中人机交互的应用,本文自制了一套小型空间人机交互手势数据库,该数据库由6名不同的工作人员佩戴航天员手套录制而成,分别对每位工作人员采集本文中8种不同的手势,共1000张手势图像。则该数据库共6000张带有航天服手套的手势图像,如图10所示。将其中3000张增加到训练数据中,另外3000张增加到测试数据中,采用本文提出的并联RGBD⁃CNN网络进行重新测试,测试准确率为92.8%,对一幅图片的平均识别时间是26.3 ms,满足实时性。可证明本文提出的静态手势识别方法对于月面探测的空间人机交互应用的可行性。

图10 空间人机交互手势数据集Fig.10 Hand gestures database of space human⁃ro⁃bot interaction
5 结论
1)本文设计了一种并联卷积神经网络结构,将RGB子网络和深度子网络并联,将各自的预测结果进行融合,得到最终的手势语义预测结果。
2)设计了含有八种手势的空间人机交互手势集,并自制了数据库。
3)试验结果显示,设计的并联网络能够提高手势的语义识别率。
4)本文方法能够保证月面探测联合任务更加顺利的进行。
[ 1 ] Fong T,Nourbakhsh I.Interaction challenges in human⁃robot space exploration [J].Interactions, 2005, 12(2): 42⁃45.
[ 2 ] Liu Jinguo, Luo Yifan, Ju Zhaojie.An interactive astronaut⁃robot system with gesture control[J].Computational Intelli⁃gence and Neuroscience, 2016,2016:314⁃325.
[3] Wolf M T,Assad C,Stoica A.Decoding static and dynamic arm and hand gestures from the JPL BioSleeve [C]//Pro⁃ceedings of the IEEE Aerospace Conference, MT, USA,2013:1302⁃1310.
[4] Yamashita T,Watasue T.Hand posture recognition based on bottom⁃up structured deep CNN with curriculum learning[C] //2014 IEEE International Conference on Image Process⁃ing (ICIP),Paris, France, 2014:853⁃857.
[5] Pisharady P K,Saerbeck M.Recent methods and databases in vision⁃based hand gesture recognition: a review [J].Com⁃put.Vis.Image Underst, 2015, 141: 152⁃165.
[ 6 ] Hasan H, Abdul⁃Kareem S.Human⁃computer interaction u⁃sing vision⁃based hand gesture recognition systems: a survey[J].Neural Comput.Appl.,2014, 25(2): 251⁃261.
[ 7 ] Molchanov P, Mello SD, Kim K,et al.Hand gesture recog⁃nition with 3D convolutional neural networks[C]//Proceed⁃ings of the IEEE Computer Vision and PatternRecognition,Boston, USA,2015:384⁃391.
[ 8 ] Nagi J, Ducatelle F, Caro G D, et al.Max⁃pooling convolu⁃tional neural networks for vision⁃based hand gesture recogni⁃tion [C] //Proceedings of the 2011 IEEE International Con⁃ference on Signal and Image Processing Applications (ICSI⁃PA),Kuala Lumpur, Malaysia,2011:342⁃347.
[ 9 ] Gao Qing, Liu Jinguo, Tian Tongtong, et al.Free⁃flying dy⁃namics and control of an astronaut assistant robot based on fuzzy sliding mode algorithm [J].Acta Astronautica, 2017,138:467⁃474.
[10] Liu Jinguo, Gao Qing, Liu Zhiwei,et al.Attitude control for astronaut assisted robot in the space station [J].International Journal of Control, Automation and Systems (IJCAS),2016,14(4):1082⁃1095.
[11] Gattupalli S, Ghaderi A, Athitsos V.Evaluation of deep learning based pose estimation for sign language recognition[C] //9th ACM International Conference on PErvasive Tech⁃nologies Related to Assistive Environments,Greece2016:12⁃19.
[12] Ju Zhaojie, Gao Dongxu, Cao Jiangtao,et al.A novel approach to extract hand gesture feature in depth images [J].Multimedia Tools and Applications,2015, 75(19):11929⁃11943.
[13] Ju Zhaojie, Wang Yuehui, Zeng Wei,etal.A modified EM algorithm for hand gesture segmentation in RGB⁃D data[C]//IEEE World Congress on Computational Intelligence,Beijing, China, 2014: 1736⁃1742.
[14] Ciresan D, Meier U, Schmidhuber J.Multi⁃column deep neu⁃ral networks for image classification[C]//Proceedings of the CVPR,Providence, USA, 2012:3642⁃3649.
[15] Lin H I, Hsu M H, Chen WK.Human hand gesture recogni⁃tion using a convolution neural network [C] //2014 IEEE In⁃ternational Conference on Automation Science and Engineer⁃ing (CASE), Taipei, Taiwan,2014: 1038⁃1043.
[16] Le Cun Y,Bengio Y,Hinton G.Deep learning[J].Nature,2015, 521:436⁃444.
[17] Pugeault N, Bowden R.Spelling it out: real⁃time ASL finger spelling recognition [C] //Proceedings of the IEEE Interna⁃tional Conference on Computer Vision Workshops(ICCV Workshops),Barcelona, Spain,2011:1114⁃1119.
[18] Odriguez K O,Chavez G C.Finger spelling recognition from RGB⁃D information using kernel descriptor [C] //Proceed⁃ings of the26th SIB⁃GRAPI⁃Conferenceon Graphics, Patterns and Images (SIBGRAPI),Arequipa, Peru, 2013:1⁃7.
猜你喜欢
北京航空航天大学学报(2022年7期)2022-08-06
军事文摘(2022年8期)2022-05-25
作文大王·低年级(2022年4期)2022-04-23
软件(2020年3期)2020-04-20
军事文摘(2020年24期)2020-02-06
红领巾·萌芽(2019年9期)2019-10-09
军事文摘(2019年18期)2019-09-25
电子制作(2019年23期)2019-02-23
小学阅读指南·低年级版(2017年6期)2017-06-12
数学大世界·小学低年级辅导版(2010年9期)2010-09-08
