
模糊推理在转向柱式电动助力转向系统可靠性计算中的应用
2018-06-28 05:36顾秉章
时代汽车 2018年5期
顾秉章
同济大学 上海市 200092
电动助力转向系统( Electric Power Steering System,简称EPS) 是在机械式转向系统基础上加装伺服控制装置而构成。电动助力转向系统相对于传统转向系统还有轻型小巧、装配迅速、易于调整、维修方便、回正性好、噪声小等优点。基于以上优点,电动助力转向系统正在迅速取代传统液压助力转向系统而得到越来越多的应用,已经成为现代转向系统的发展方向。
相对于国内汽车市场各种新车型迅速的更新换代,如何能够在相应的研发周期内完成必要的验证试验以确保整个转向系统的安全可靠是放在所有人面前的一个问题。本文针对转向柱式电动助力转向系统在研发应用过程中的可靠性验证优化问题作出的一些探索。
1 转向柱式电动助力转向系统组成与基本工作原理
一般来说,转向柱式电动助力转向系统可以分解成以下单元:电控单元、传感系统、驱动电机、减速装置、机械调节机构及中间传动轴。
当驾驶人员转动方向盘时,传感系统当即检测到转向角度信号与转向手力信号并将其通过内部数线路传送到电控单元。电控单元当即对传感系统所采集信号、并结合车速
信号与车况信号进行分析,确定所驱动电机所需要输出助力扭矩的大小与方向,并将该指令通过内部线路传输至驱动电机。驱动电机接收电控单元发出的驱动信号后,立即开始工作,对外输出助力。该助力通过减速装置(通常为蜗轮蜗杆机构)增幅后,通过中间传动轴传递至机械转向机,最后带动横拉杆,实现转向动作。
2 模糊推理的基本概念
“模糊”就是指这些彼此间边界不明确,从属于该概念到不属于该概念之间无明显分界线的情况。对于“模糊”的情况,运用传统属于与不属于概念来区分并不合适,而运用属于程度来代替属于或者不属于。在不必要获得精确数据时,通常运用模糊推理的方法进行分析判断。
模糊推理的过程,一般需要经过以下几个步骤:
(1)将已有信息、输入模糊化;
(2)通过已定义的逻辑规则,对已模糊化的信息、输入进行推理,获得一个模糊的输出;
(3)将获得的模糊输出反模糊化,获得输出。
除了从已知的逻辑事件中计算获得模糊关系外,也可以直接利用相关专家的经验知识或已经明确成熟的规则,得到相应的模糊规则。直接基于模糊规则的推理过程如下:计算规则前提部分的逻辑组合;依次将各规则的前提部分的逻辑组合的隶属度与结论命题的隶属函数做取小运算,得到模糊输出;将所有规则的模糊输出做交取运算,得到模糊推理结果。由于在实际应用中往往需要的是一个精确的输出结果,所以对于模糊推理得到的模糊化的结果进行反模糊化将其转变成一个精确的结果。
3 模糊推理的在系统相似度中的应用
两个不同的转向柱式电动助力转向系统之间的相似程度是一个模糊量,可以利用模糊推理的方法进行判断。前文已将整个系统分解为六个子系统,整个系统的相似度从其组成子系统的相似度进行推算。
子系统间的相似度也是个模糊量,通过表1中的规则可以对其进行判断。对表中未写明的相似度分值,可以也可以通过经验在相应规则间选取一个值。该分值并不需要十分精确,这也是模糊推理的一个优点。
本文中将相似度分为四个模糊子集,分别为“完全相同”、“基本相同”、“基本不同”、“完全不同”,记做TS、PS、PD、TD。本文中,总结以往经验的基础上选择了三角形分布作为子系统相似度的隶属函数,相邻模糊子集相应隶属函数曲线在隶属度值为0.5处相交。

表1 子系统相似度计分规则

类似的,将最得到的系统相似度分为五个模糊子集,分别为“不同”、“低”、“中”、“高”、“相同”,记做D、L、M、H、S。

R2. 如果一个子系统基本相同并且其他的子系统都完全相同,则系统相似度为高。
R3. 如果两个子系统基本相同并且其他的子系统都完全相同,则系统相似度为中。
R4. 如果三个或以上子系统基本相同并且其他的子系统都完全相同,则系统相似度为低。
R5. 如果一个子系统基本不同并且没有子系统完全不同,则系统相似度为低。R6. 如果两个或以上子系统基本不同,则系统相似度为不同。
R7. 如果一个子系统完全不同,则系统相似度为不同。
如将各相应规则所对应的模糊输出分别记为 至 ,则将模糊输出反模糊化即可获得需要的系统相似度。

由于系统与系统之间是否相似很难直接从个体事件中得出规律,并且有相应专家在以往的工程开发中积累了很多经验,所以决定采用直接将专家经验改写为模糊关系规则的方式定义规则库。结合资深专家的意见与工程实践中的经验,总结了以下规则。
R1. 如果所有子系统都完全相同,则系统相似度为相同。
4 模糊推理的在系统可靠性中的应用
在实际工程中,常见的研发模式是进行原型平台开发后,基于该平台进行应用开发。在原型平台开发阶段将进行大量的试验并积累大量的试验数据与经验。但在传统的验证过程中,这些积累的数据与经验并没有能对应用项目的可靠性做出任何贡献。以下就将运用模糊推理的方法将平台研发阶段的数据借用至应用开发型产品中。
以某一应用型产品为例,首先对其进行分析,识别其中的非沿用件,并对对于这些非沿用件一一进行工程变更分析,并估计该变更对可靠度产生的影响并记录于表2中。
之后根据式1至4,将相应的输入模糊化后得到模糊推理所需要的模糊输入,并将各子系统相对模糊子集的隶属度记录于下表3中。
在得到模糊输入后,将根据所有规则依次进行判断,并结合式5至式9得到各个规则所对应的模糊输出。在得到所有规则的模糊输出后,通过式10就可以得到最后需要的模糊输出。

将式12代入式11进行反模糊化就可以最终得到应用型产品与原平台产品的相似度为0.375。
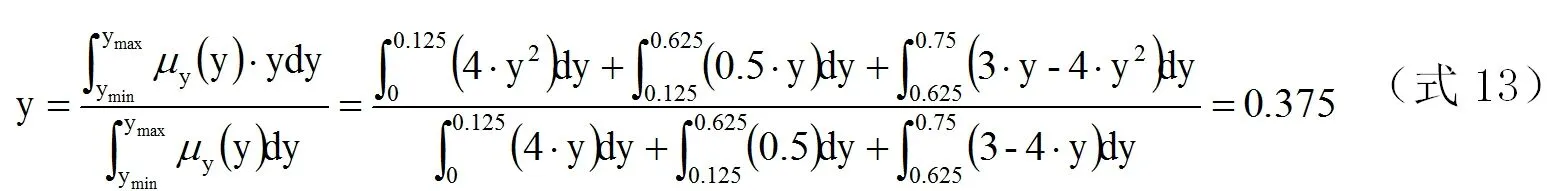
转向柱式电动助力转向系统的失效概率密度满足威布尔分布。

基于同一原型平台产品开发的应用型产品的失效概率密度服从于同一威布尔分布。那么通过对于威布尔分布的推导,可以得到式16。

我们容易理解,如果系统A与系统B完全相同,则如果系统A通过试验并满足设计要求,那么系统B也应通过试验并满足试验要求。系统A与系统B之间相似程度越高,在系统A通过试验并满足设计要求的情况下,系统B也应通过试验并满足试验要求的可能性也相应越高。将通过模糊推理得到的系统相关度引入式16可以得到式17。

其中x为系统相关度,m为原型产品完成试验样件数,t0为应用型产品计划试验时间,ti为原型产品试验时间。
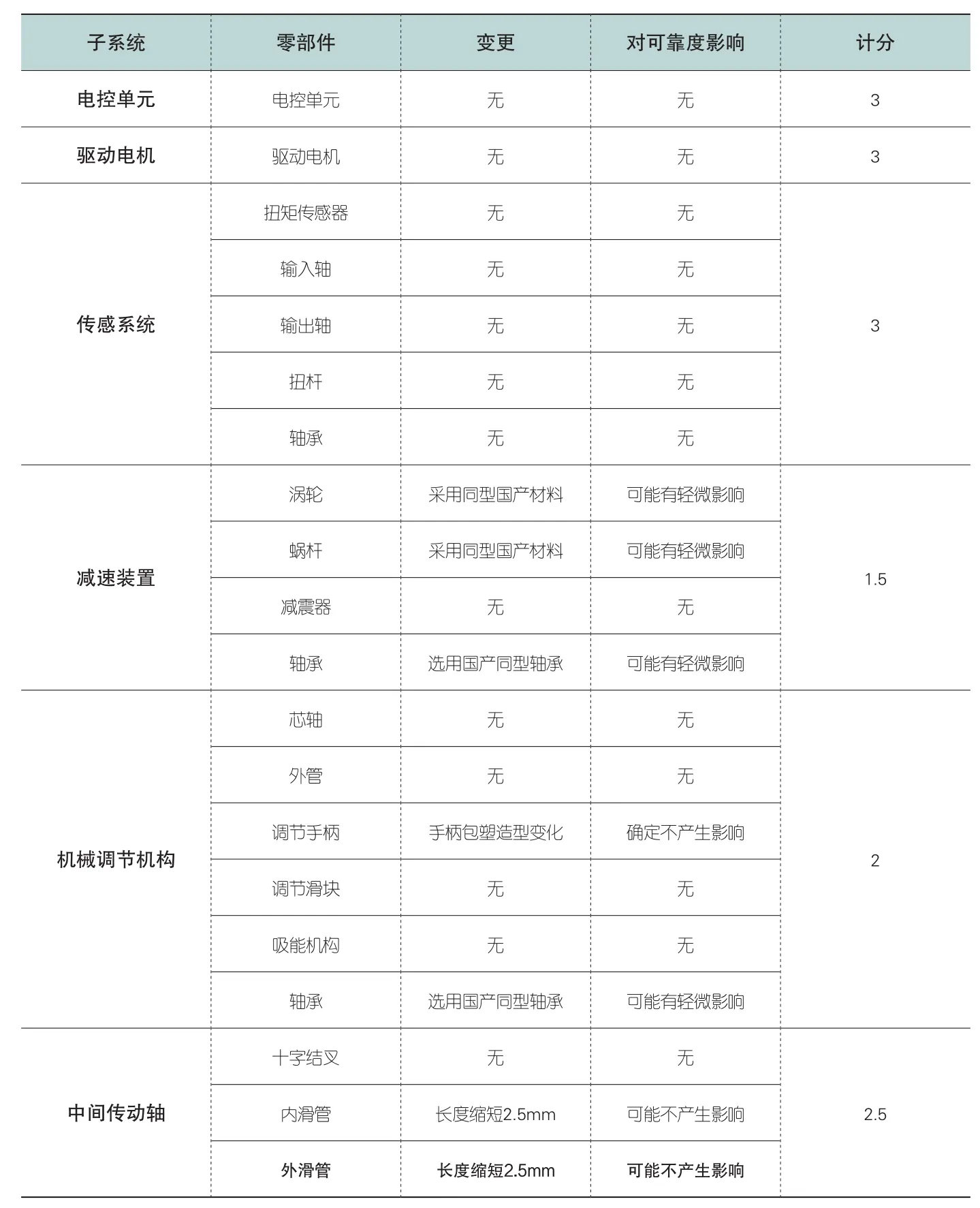
表2 子系统相似度计分表

表3 子系统模糊子集隶属度表
上例中的原型平台产品在开发过程中共对12个样品进行4个寿命当量耐久试验并且并得到相应威布尔形状参数为 =2.2。应用型产品的计划试验时间为3个寿命当量,那么将所有数据代入式17可以计算得到原型平台产品对应用型产品在研发过程中的贡献量,即可以认为应用型产品已经完成8.474个样件的耐久试验并未发生任何失效。

5 结语
通过以上论述,采用模糊推理的方法将原型平台产品在开发过程中的试验数据合理借用到应用型产品开发中,大大提高实际产品验证工作的效率,达到降低试验成本、缩短产品研发周期的目的。并且随着基于同一原型平台产品的应用型产品数量增多,新的应用型产品可以借用更多的同类产品的试验数据,可以进一步降低试验成本、缩短产品研发周期。
猜你喜欢
厦门大学学报(自然科学版)(2022年4期)2022-07-15
小资CHIC!ELEGANCE(2021年45期)2021-01-11
现代装饰(2020年7期)2020-07-27
英美文学研究论丛(2018年2期)2018-08-27
智富时代(2018年6期)2018-08-06
智富时代(2018年6期)2018-08-06
小天使·二年级语数英综合(2017年12期)2017-12-05
中国集体经济(2017年1期)2017-01-04
商(2016年28期)2016-10-27
剑南文学(2016年14期)2016-08-22
