
改进的Adaboost方法及其在水电站设备故障检测中的应用
2018-06-22 06:34:04张华飞衣传宝孙成勋徐华雷
水力发电 2018年3期
陈 涛,张华飞,衣传宝,孙成勋,高 阳,徐华雷
(1.国网吉林省电力有限公司电力科学研究院,吉林长春130021; 2.国网新源控股有限公司,北京100761)
水电站作为一种可持续能源,在发达国家中占有很高的地位。近年由于水电站的不断发展,水电站的安全问题也随之暴露出来。国内外现今对水电站设备故障的检测,其研究内容较为单一,比如只针对水轮机机组和发电机组等设备进行故障诊断,而且故障信息的判断主要以振动信号为主[1- 4]。因为设备的振动信号中含有许多不稳定因素,影响了分析结果的准确性。所以信号提取需要借助谐波小波分析等方法进行信号除噪,这是一个复杂且繁琐的过程。
现今国内水电站对设备故障的检测主要采用人工巡检,水电站内部环境复杂,运行人员进行一次完整的巡检大约需要2个小时。因为需要检查的设备过多,种类繁杂,涉及的区域很广,所以会导致巡检的效率很低,很多地方会被疏忽而没有仔细检查或者漏检。一旦某些设备出现问题,故障会很难被及时发现或者排除,最终会威胁到工作人员的安全。
1 方案设计
水电站噪声由水电站设备运作时产生,当设备发生故障时,其产生的噪声强度也会发生变化[5],因此水电站设备是否正常运作与其产生的噪声强度有着紧密的关系。针对噪声信号,设计方案步骤如下:
1.1 利用噪声传感器收集信息
通过熟悉运行人员的巡检路线,将水电站分为多个重要区域,并在不同区域中的主要设备旁安装噪声传感器,传感器会把监测到的噪声信号(即噪声数据)传送到服务器的数据库中,并储存起来[6,7]。通常情况下,水电站设备主要通过人为检测,而面对运行人员检测时间过长,检测效率过低等问题,利用噪声信息代替运行人员在整个巡检中捕捉到的设备信息,这样不仅节省人力与时间,而且信息的正确性也得到保证。
1.2 分类器模型的创建
水电站的设备种类繁杂,会导致收集的数据量巨大,不能逐个判别。利用改进的Adaboost方法创建分类器模型,对不同工况下的噪声样本进行分类处理,最后只将分类结果错误的样本提取出来,进行故障判别,从而大大减少了工作量。

1.3 利用分类器进行故障判别

(1)当P≤20%时,说明噪声异常值是由测量误差产生,无需进行设备检查,设备运行正常;
激励是给学生最好的动力,老师在课堂教育时营造情境氛围,用激励的语言去指导学生,从而让学生产生对体育学习的兴趣。激励教学就是要做到理性和感性相结合,学生在一种轻松的环境下学习,有严有松,既能锻炼身体,又能培养自身的服从命令听指挥的意识。在学生碰到一些状况时,老师千万不要用一些嘲笑不友好的态度对待学生,要晓之以理,动之以情,帮助学生解决状况,尊重学生,让学生在激励的语言下取得更大的进步。
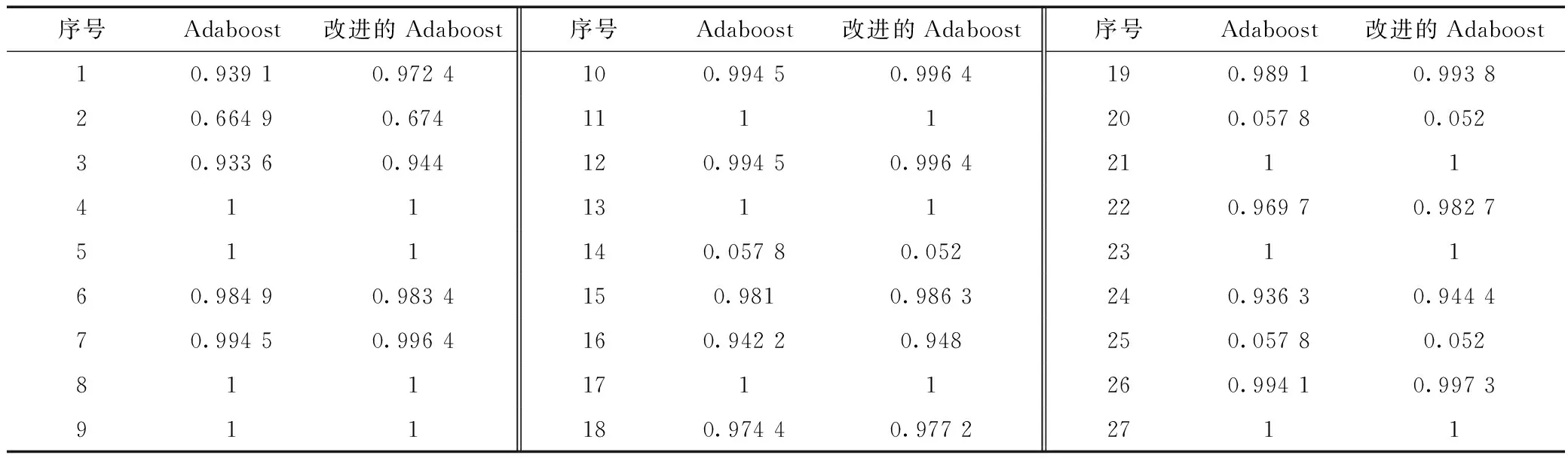
(2)当20% (3)当P>50%时,设备很大可能性出现故障,发出故障信号,通过i,j确定故障位置,及时检修。 (4)完善分类器模型 将分类结果正确的噪声样本添加到数据库中,利用更新后的数据训练一个新的分类器模型,通过数据的添加与更新,不断完善分类器模型,从而提高模型的精确度。 Adaboost是一种常用的分类算法,其中心思想是通过训练,将弱分类器组合成强分类器,弱分类器的学习方法有很多,如神经网络,SVM,CART等[8,9]。 在水电站故障检测方案中,分类器模型是检测方案的核心步骤,所以要求分类器的精确度很高,这样才能保证检测的准确性。本文对Adaboost方法进行了改进,用该方法得到的分类器模型具有很高的正确率,使其在检测中发挥更大的作用。 本文利用熵权法[13-15],通过熵权对Adaboost方法的弱分类器系数进行修正,从而得到更加精准的弱分类器权重,提高强分类器的正确率,进而提高水电站的故障检测效率。改进步骤共分5步。 2.2.1 确定原始指标水平矩阵 2.2.2 计算弱分类器的信息熵 第L个指标的信息熵为 2.2.3 计算弱分类器的熵权 2.2.4 修正弱分类器系数 2.2.5 构建强分类器 表2 改进的Adaboost方法和普通Adaboost方法正确率对比 为了证明方案的可行性,我们对湖南某水电站噪声进行了实地测量,收集到了样本数据。通过对该水电站运作流程的了解,本文将运行人员主要巡检的作业场所分为四个区域,分别为:发电机层、母线层、主变洞和水轮机层。在水电站运行正常时,在发电、备用两种工况下分别对四个区域,不同地点所产生的噪声值进行检测,得到近500个数据样。 将样本集分为两部分,其中测试样本64个,其余为训练样本。利用改进的Adaboost算法对训练样本进行训练,其中弱分类器的学习方法采用分类回归树[16,17],最大迭代次数为100次。最终获得的强分类器需对测试样本进行分类,改进的Adaboost算法的正确率达到89.1%,错误率上限为8.46×e-71<1.87×e-20,说明分类器符合错误率标准。 利用改进的Adaboost方法与BP神经网络[18,19]和简单贝叶斯算法[20,21]等学习方法进行结果对比,结果如表1所示。 表1 不同学习方法的对比结果表 对比结果表明改进的Adaboost方法的错误率最小,相比其它算法具有很大的优势。改进的Adaboost方法和普通Adaboost方法对27个测试样本分类结果正确率的比较如表2所示。 在两种算法的结果中,正确率大于0.5,代表样本被正确分类,而正确率小于0.5,则样本被错误分类。表2结果显示,在分类正确的样本中,改进的Adaboost方法比普通Adaboost方法的正确率有明显提高,进而加强验证了其为正常样本,而对分类错误的样本,正确率明显降低,加强验证了其为异常样本。对比结果表明改进的Adaboost方法比普通Adaboost方法精确度更优,平均正确率提高了0.3%,提高了对水电站故障检测的正确率。 提取误差样本与各区域的噪声分布进行比对,分类错误的噪声样本及异常位置如表3所示。 误差样本与不同区域噪声强度分布区间数据进行对比,很快就可以发现噪声异常位置。根据表3结果显示,有4个测量位置的个别噪声值存在异常,其中水轮机层1号机有2个噪声值存在异常、主变洞2号室1个、水轮机层2号机3个和水轮机层4号机2个。在测试样本中每个测量位置均测得16个数据,根据式(2),故障发生概率P分别为12.5%、6.25%、18.75%、12.5%,P均小于20%,说明噪声异常值是由测量误差所产生的,所有检测设备运行正常,检测结果符合实际情况。此方案可代替人工巡检,进而更快的得到检测结果,发现故障位置。 表3 分类错误的噪声样本及异常位置表 水电站环境安全是近年来研究的一个热点话题,本文利用噪声来检测设备故障,应用改进的Adaboost方法提高检测的正确率。当水电站设备发生故障时,此方案可缩小设备故障区域,进而更快的发现和排除问题,从而提高了工作人员的安全保障,减少经济损失。同时,此套方案也存在着某些问题,如噪声的相互干扰和对测量误差的解决方法等,这也是今后的研究重点。 [1] 卢娜. 基于多小波的水电机组振动特征提取及故障诊断方法的研究[D]. 武汉: 武汉大学, 2014. [2] 梁兴. 耦合故障对水电机组转子动力特性的影响分析[J]. 水电能源科学, 2014, 32(11): 155-157. [3] 肖剑. 水电机组状态评估及智能诊断方法研究[D]. 长沙: 华中科技大学, 2014. [4] DAI Feng, LI Biao, XU Nuwen, et al. Microseismic early warning of surrounding rock mass deformation in the underground powerhouse of the Houziyan Hydropower Station, China[J]. Tunnelling and Underground Space Technology, 2017, 62: 64- 74. [5] 管争荣. 减速机振动和噪声分析与谱诊断方法的研究[D]. 西安: 西安建筑科技大学, 2008. [6] 焦新泉, 李功, 侯卓, 等. 基于电容式噪声传感器的信号调理电路设计[J]. 火力与指挥控制, 2016, 41(10): 159- 162. [7] XIAO Kejiang, WANG Rui, FU Tun, et al. Divide-and-conquer architecture based collaborative sensing for target monitoring in wireless sensor networks[J]. Information Fusion, 2017, 36: 162- 171. [8] 曹莹, 苗起广, 刘家辰, 等. AdaBoost算法研究进展与展望[J]. 自动化学报, 2013, 39(6): 745- 758. [9] SUN Jie, FUJITA Hamido, CEN Peng, et al. Dynamic financial distress prediction with concept drift based on time weighting combined with Adaboost support vector machine ensemble[J]. Knowledge-Based Systems, 2016, 120: 1- 11. [10] 李闯, 丁晓青, 吴佑寿. 一种改进的AdaBoost算法-AD AdaBoost[N]. 计算机学报, 2007, 30(1): 103- 109. [11] 徐海龙, 别晓峰, 冯卉, 等. 一种基于QBC的SVM主动学习算法[J]. 系统工程与电子技, 2015, 37(12): 2865- 2871. [12] LEE W, JUN C H, LEE J S. Instance categorization by support vector machines to adjust weights in AdaBoost for imbalanced data classification[J]. Information Sciences, 2017, 381: 92- 103. [13] 邱陆旸, 张丽萍, 陆芳春, 等. 基于熵权法的林下土壤抗腐蚀性评价及影响因素分析[J].水土保持学报, 2016, 30(4): 74- 79. [14] DUAN Y, MU Hailin, LI Nan, et al. Research on comprehensive evaluation of low carbon economy development level based on AHP-Entropy method: a case study of Dalian[J]. Energy Procedia, 2016, 104: 468- 474. [15] HAFEZALKOTOB A, HAFEZALKOTOB A. Extended MULTIMOORA method based on Shannon entropy weight for materials selection[J]. Journal of Industrial Engineering International, 2016, 12(1): 1- 13. [16] D’AMBROSIO A, ARIA M, IORIO C, et al. Regression trees for multivalued numerical response variables[J]. Expert Systems with Applications, 2017, 69: 21- 28. [17] ZHAO Yannan, LI Yuan, ZHANG Lifen, et al. Groundwater level prediction of landslide based on classification and regression tree[J]. Geodesy and Geodynamics, 2016, 7(5): 348- 355. [18] 袁铸, 申一歌. 农业机器人轨迹优化自动控制研究-基于BP神经网络与计算力矩[J]. 农业化研究, 2017, (6): 34- 37. [19] YE Sun. RMB Exchange rate forecast approach based on BP neural network[J]. Physics Procedia, 2012, 33: 287- 293. [20] 王建新, 王柏人, 曲鸣, 等. 基于朴素贝叶斯分类器的硬件木马检测方法[J]. 计算机应用研究, 2017, 34(10): 1- 10. [21] SHEN Shiwen, HAN S X, PETOUSIS P, et al. A Bayesian model for estimating multi-state disease progression[J]. Computers in Biology and Medicine, 2017, 81: 111- 120.2 Adaboost算法介绍和改进
2.1 样本集初始权重的重新分配

2.2 利用熵权法优化弱分类器系数





3 方案实施
3.1 数据收集
3.2 利用改进的Adaboost方法创建分类器模型
3.3 方法对比

3.4 结果评价与分析

4 结 论
猜你喜欢
西北水电(2022年1期)2022-04-16 05:20:06
金桥(2021年8期)2021-08-23 01:06:54
中华养生保健(2020年7期)2020-11-16 01:14:26
电子测试(2018年1期)2018-04-18 11:52:35
水利技术监督(2016年6期)2017-01-15 14:01:41
家教世界·创新阅读(2016年11期)2016-12-27 18:49:15
天津护理(2016年3期)2016-12-01 05:40:01
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
故事会(2016年15期)2016-08-23 13:48:41
