
基于LeaderRank和节点相似性的多标签传播重叠社团挖掘算法①
2018-06-14 08:49饶仁杰
计算机系统应用 2018年6期
王 林,饶仁杰
(西安理工大学 自动化与信息工程学院,西安 710048)
近年来,随着科技的快速发展,对复杂网络的研究不断深入,社团结构作为复杂网络中的重要属性也逐渐得到人们的重视.所谓社团结构就是:同一社团内节点之间连接紧密,而不同社团内节点之间连接稀疏[1,2].社团挖掘是为了探索和发现复杂网络的社团结构,有助于分析网络的结构和功能,从而发现网络中隐含的内在规律,因此社团挖掘具有重要的理论意义和广泛的应用前景.
随着研究的不断深入,许多社团挖掘算法被广大研究者相继提出,如基于节点分裂的GN算法[3],基于模块度优化的FN算法[4]和BGLL算法[5],基于标签传播的LPA算法[6]等.其中,LPA算法因为其简单、高效等优势,得到了人们的普遍关注.但是该算法仅仅只能用于非重叠网络中,并且该算法存在稳定性差和随机性高的缺陷.然而在真实网络中社团通常是相互重叠的,如图1所示,网络中的阴影节点同属于两个社团,那么这两个社团就是重叠的,阴影节点即为重叠节点.为了能够挖掘重叠社团结构,Steve在LPA算法的基础上进行延伸,提出了多标签传播COPRA算法[7],该算法允许每个节点携带v个标签,其继承了LPA算法的优势,但用于未知网络时无法预估网络中节点所属的社团个数,假设节点所属社团个数分布不均时,就很难找到一个合适的参数v,使得算法难以准确的得到社团结构,且COPRA算法同时也继承了LPA算法的随机性缺陷,使得划分的结果非常不稳定.Xie等人基于标签传播的思想提出SLPA算法[8],算法通过记录每一个节点在刷新迭代过程中的历史标签序列,利用概率阈值删除出现频率小的标签最终得到社团结构,但该算法仍需要一个合适的概率阈值参数,并且采用的随机策略将导致结果存在随机性.
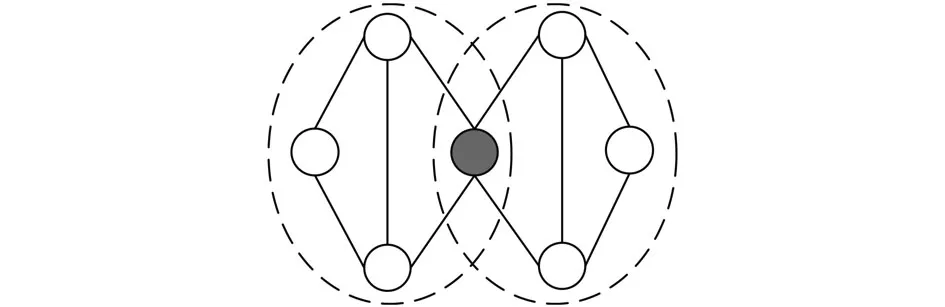
图1 重叠社团的网络结构
为了改善现有的基于多标签传播算法的因采用随机策略导致结果不稳定,以及需要输入额外的参数问题,本文提出一种基于LeaderRank和节点相似性的多标签传播算法,该算法引入LeaderRank算法[9]来衡量网络中节点重要性,根据重要性大小确定节点的更新序列,并重新设计了标签的更新策略,使得到的划分结果更加稳定,且该算法无需输入额外的参数.实验表明本文算法较现有的多标签传播算法相比能够较准确的得到重叠社团结构.
1 基于LeaderRank和节点相似性的多标签传播重叠社团挖掘算法
本文利用LeaderRank算法对网络中的节点的更新顺序进行排序,并结合节点的相似性重新设计了标签的更新策略提出了基于LeaderRank和节点相似性的多标签传播重叠社团挖掘算法.
1.1 LeaderRank排序算法
由于先更新的节点影响传播的较远,很多重要性较小的节点在传播时会反过来影响一些重要性较大的节点,这样就造成了标签的逆向传播.虽然算法在后续的迭代过程中可以修正结果,但耗费了大量的时间和更新操作.因此,本文利用LeaderRank排序算法对节点的更新顺序进行排序减少算法不必要的更新和标签逆流现象.
算法通过在原网络中加入一个背景节点(ground node),将其与网络中的所有节点相连,得到一个有N+1个节点的强连接网络.
首先,给除背景节点以外的所有节点分配1单位的LR值,然后将这1单位的LR值分配给其邻居节点,不断重复这一过程,直到达到稳定状态,即公式所示:
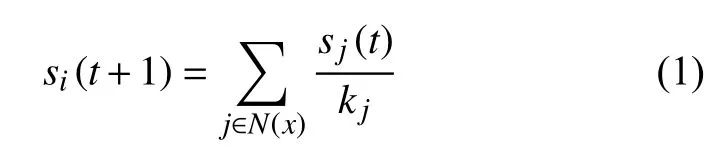
其中,N(x)表示节点x的邻居节点集合,kj表示节点j的度,sj(t)表示第t次迭代节点j的LR值.
达到稳定状态[9]后,此时再将背景节点的LR值分配给其他所有节点,因此,最终的LR值定义为:
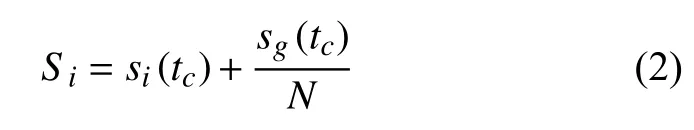
其中,tc表 示收敛次数,sg(tc)表示稳定状态下节点g的LR值.
在计算出所有节点LR值之后,将LR值进行降序排序,LR值越大说明节点的重要性越大,从而得到了节点的更新顺序.
1.2 标签更新策略
在COPRA算法中,更新节点的标签时算法简单地认为每个节点与其邻居节点之间的关系是相等的,显然这与现实生活中的情况不符合.比如a有b,c,d,e四个邻居节点,但如果邻居节点b与节点a的关系更加亲密,那么节点a更加容易接收来自节点b的标签.因此,本文重新设计了标签的更新策略进行标签更新.首先给出如下定义:
定义1.节点间的相似性:
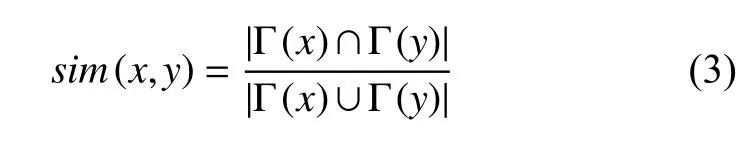
其中表示节点x的邻居节点.
定义2.领导标签:节点的标签集合中具有最大从属系数的标签.
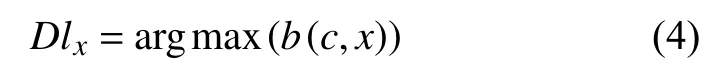
结合定义1与定义2给出了新的标签更新策略,如下式所示:
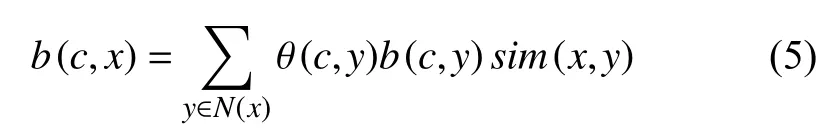
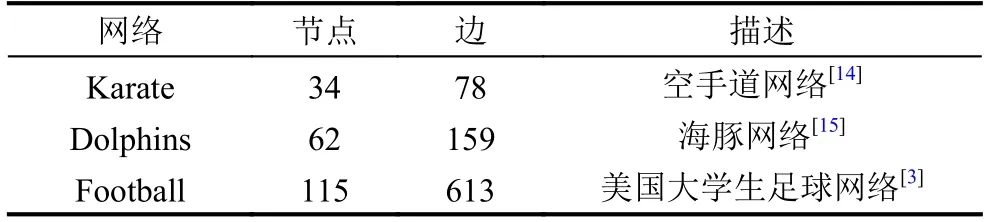
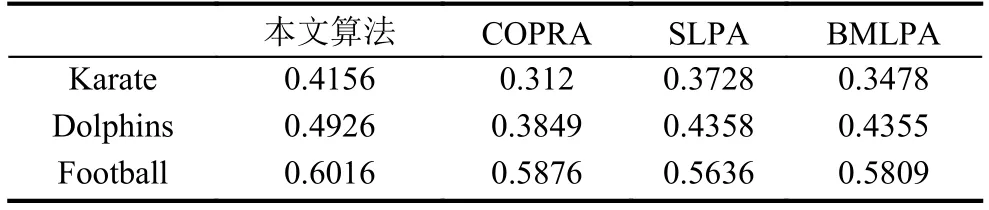
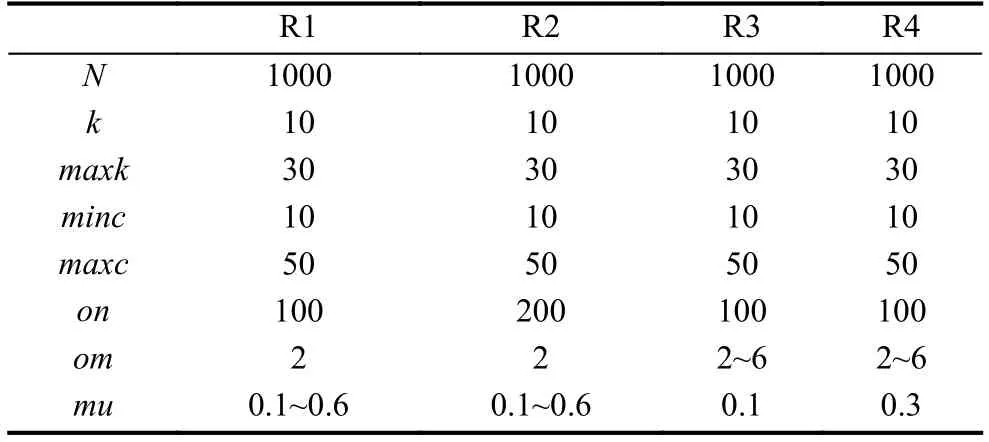
根据以上定义,标签的更新策略描述如下:首先给每个节点分配一个唯一的标签,并且标签的从属系数为1.然后为了对标签进行更新,利用公式(3)计算出节点与其所有邻居节点的相似性,当更新节点x时,节点x只接收来自其邻居节点中从属系数最大的领导标签,随后将节点x从邻居节点接收到的最大从属系数乘以对应邻居节点的相似性,得到节点x更新后的标签集合Lx,设定阈值其中b表示节点x的标签集合Lx中所有标签的从属系数,n表示节点x的标签数量,当b 初始时,标签数量等于节点数量,随着标签更新过程而减少,最后达到最小值,即为最终的社团数量.定义i t为第t次迭代的标签数量(社团数量),如果当时,算法停止,可能导致输出结果不准确,虽然此时标签数量不变,但是每个社团内的节点数量可能在几次迭代后发生变化.因此,终止条件不仅要满足还要注意每个社团内节点数量的变化情况.第t次迭代时,社团c的节点数量可以表示如下: 拥有标签c的节点数量会在迭代过程中发生变化,本文观测拥有标签c的最小节点数的变化,当时, 否则只要满足算法停止. 本文算法的主要过程可以分为3个阶段:初始化、确定节点更新顺序和标签传播.首先初始化每个节点,给每个节点分配一个独特的标签,并且该标签的从属系数为1.然后为了减少算法的迭代次数并避免标签的逆流现象,利用LeaderRank算法对每个节点进行排序,确定标签的更新顺序.再根据本文提出的标签更新策略进行标签更新,直到达到标签传播的终止条件结束迭代过程.最后将具有相同标签的节点归为一个社团,如果节点有多个标签那么该节点为重叠节点. 算法具体描述如下: 1) 计算网络中所有节点的LR值,并按降序排序.2) 计算网络中所有节点之间的相似性,得到相似性矩阵.3) 初始化,给每个节点的标签初始化为.4) 节点x接收每个邻居节点的领导标签以及对应的从属系数.5) 利用公式(5)更新节点x的标签从属系数.6) 设定阈值,删除小于阈值的标签,最后对剩余标签的从属系数进行标准化.7) 重复4)-6)步骤,直到达到迭代条件,算法停止.8) 输出社团,具有多个标签的节点则为重叠节点. 设网络中包括n个节点,k为节点的平均度,m为边的数量,L为节点平均包含的标签个数. 利用LeaderRank算法对网络中的节点进行排序需要其中l为LeaderRank算法收敛时的迭代次数.初始化标签需要 O(n),计算相似性矩阵需要 O(m),更新标签时每次迭代需要 O(Lmlog(Lm/n)),假设共需要迭代T次,所以整个标签更新过程需要O (TLmlog(Lm/n)),故算法的总复杂度为 O(ml+m+n+TLmlog(Lm/n)),由于L通常非常小,且T远小于m,所以最终的算法复杂度为 为了测试本文提出的算法的性能,将算法应用于真实网络和人工网络数据集进行验证分析,并与COPRA算法[7]、SLPA算法[8]、BMLPA算法[10]进行对比分析,以验证算法的有效性. 为了评价算法性能,本文利用标准互信息和扩展模块度EQ来衡量重叠社团结构的划分结果. 1) 扩展模块度(EQ) 模块度Q[11]是评价社团质量的主要评价指标,然而它只能用于评价非重叠社团质量,并不能够准确评价重叠社团质量.因此,本文引入扩展模块度EQ[12]作为重叠社团质量的评价指标.EQ的取值范围是0到1之间,值越大说明重叠结构越好. 其中,m表示网络中边的个数表示节点i属于社团的数量,di表示节点i的度表示如果节点i和节点j在同一个社团则值为1,否则为0. 2) 标准互信息(NMI) 由于人工网络的社团结构是已知的,因此采用标准互信息NMI(Normalized Mutual Information)[13]作为社团挖掘的评价指标.NMI的取值范围是0到1之间,算法划分的社团结构越准确,NMI值越大;否则NMI值越小. 其中,x和y分别表示真实的社团结构和实验产生的社团结构. 为了验证本文算法在真实网络数据集上的有效性,将其应用于3种真实网络数据集上,表1列出了用于测试的3种真实网络数据集. 表1 真实网络数据集 由于COPRA算法和SLPA算法具有随机性,每个数据集均采取运行20次的方式获取COPRA算法和SLPA算法的平均实验结果.而本文算法以及BMLPA算法由于算法的稳定性只需本别对数据集进行一次实验.实验中COPRA算法的参数v设为2,SLPA算法的概率阈值设为0.2,BMLPA的标签过滤阈值设为0.75. 从表2中可以得出,本文算法在选取的3个真实网络数据集上得出的社团结构重叠模块度较其他算法相比均有所提高,因此本文算法可以有效提高重叠社团挖掘的重叠模块度,得到的社团结构质量更高. 为了生成LFR人工网络,使用LFR基准程序[16]生成了如表3所示的4种类型的人工网络.其中N是网络的节点数,k是节点的平均度数,maxk是节点的最大度数,maxc是一个社团的最大节点数,minc是一个社团的最小节点数,on是重叠节点的个数,om是重叠节点属于的社团个数,mu是节点与社团外部连接的边数与该节点度数的比值,取值范围是0到1之间,值越大说明网络的社团结构越不明显,所以mu取值从0.1到0.6. 表2 真实网络数据集上的EQ值比较 表3 人工网络的参数设置 实验中,针对R1和R2网络,COPRA算法的参数v取值2,针对R3和R4网络,COPRA算法的参数v取值2~6.在4种网络中SLPA算法的概率阈值r均取值0.2,BMLPA算法的标签过滤阈值设为0.75. 图2为本文算法与COPRA算法、SLPA算法以及BMLPA算法在4种类型人工网络上的NMI值对比图.可以看出,本文算法仅在R2网络的mu=0.4时未取得最优值,这是因为本文算法运用在该网络中产生了过多的重叠节点,因此影响了社团的质量,其他网络所得的NMI值都大于对比算法.因此,在人工网络中,本文算法能够挖掘出高质量的重叠社团结构. 本文针对现有的多标签传播算法在挖掘重叠社团时,稳定性较差以及需要输入额外参数的问题,提出了一种稳定的且无需任何参数的多标签传播算法.该算法利用LeaderRank算法衡量节点重要性确定更新顺序,在进行标签更新时,节点只接收来自邻居节点的领导标签,并且考虑了节点与邻居节点之间相似性不同的特点,使得更新过程更加稳定.通过在真实网络和人工网络上进行实验,结果表明本文算法较现有的基于多标签传播的重叠社团挖掘算法得到的社团质量更高. 图2 算法在4种网络的NMI比较 1 Fortunato S.Community detection in graphs.Physics Reports,2010,486(3-5):75-174.[doi:10.1016/j.physrep.2009.11.002] 2 罗明伟,姚宏亮,李俊照,等.一种基于节点相异度的社团层次划分算法.计算机工程,2014,40(1):275-279. 3 Girvan M,Newman MEJ.Community structure in social and biological networks.Proceedings of the National Academy of Sciences of the United States of America,2002,99(12):7821-7826.[doi:10.1073/pnas.122653799] 4 Newman MEJ.Fast algorithm for detecting community structure in networks.Physical Review E,Statistical,Nonlinear,and Soft Matter Physics,2004,69(6):066133.[doi:10.1103/PhysRevE.69.066133] 5 Blondel VD,Guillaume JL,Lambiotte R,et al.Fast unfolding of community hierarchies in large networks.Journal of Statistical Mechanics:Theory and Experiment,2008.[doi:10.1088/1742-5468/2008/10/P10008] 6 Raghavan UN,Albert R,Kumara S.Near linear time algorithm to detect community structures in large-scale networks.Physical Review E,Statistical,Nonlinear,and Soft Matter Physics,2007,76(3):036106.[doi:10.1103/Phys RevE.76.036106] 7 Gregory S.Finding overlapping communities in networks by label propagation.New Journal of Physics,2010,12(10):103018.[doi:10.1088/1367-2630/12/10/103018] 8 Xie J,Szymanski BK,Liu X.SLPA:Uncovering overlapping communities in social networks via a speaker-listener interaction dynamic process.Proceedings of the IEEE 11th International Conference on Data Mining Workshops.Vancouver,Canada.2011.344-349. 9 Lü LY,Zhang YC,Yeung CH,et al.Leaders in social networks,the Delicious case.PLoS One,2011,6(6):e21202.[doi:10.1371/journal.pone.0021202] 10 Wu ZH,Lin YF,Gregory S,et al.Balanced multi-label propagation for overlapping community detection in social networks.Journal of Computer Science and Technology,2012,27(3):468-479.[doi:10.1007/s11390-012-1236-x] 11 Newman MEJ,Girvan M.Finding and evaluating community structure in networks.Physical Review E,Statistical,Nonlinear,and Soft Matter Physics,2004,69(2):026113.[doi:10.1103/PhysRevE.69.026113] 12 Shen HW,Cheng XQ,Guo JF.Quantifying and identifying the overlapping community structure in networks.Journal of Statistical Mechanics:Theory &Experiment,2009,(7):07042. 13 Lancichinetti A,Fortunato S,Kertész J.Detecting the overlapping and hierarchical community structure in complex networks.New Journal of Physics,2009,11(3):033015.[doi:10.1088/1367-2630/11/3/033015] 14 Zachary WW.An information flow model for conflict and fission in small groups.Journal of Anthropological Research,1977,33(4):452-473.[doi:10.1086/jar.33.4.3629752] 15 Lusseau D,Schneider K,Boisseau OJ,et al.The bottlenose dolphin community of Doubtful Sound features a large proportion of long-lasting associations.Behavioral Ecology and Sociobiology,2003,54(4):396-405.[doi:10.1007/s002 65-003-0651-y] 16 Lancichinetti A,Fortunato S,Radicchi F.Benchmark graphs for testing community detection algorithms.Physical Review E,Covering Statistical,Nonlinear,Biological,and Soft Matter Physics,2008,78(4):046110.1.3 终止条件
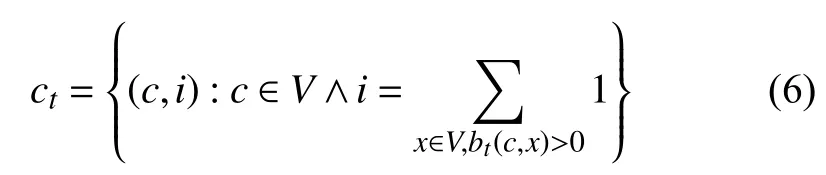

1.4 算法描述

1.5 复杂度分析
2 实验分析
2.1 评价指标
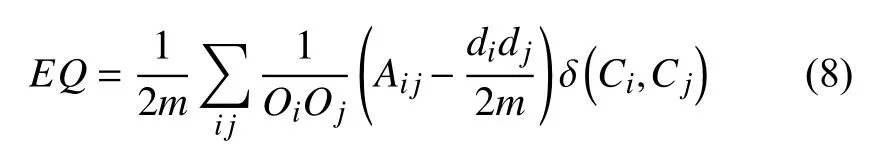
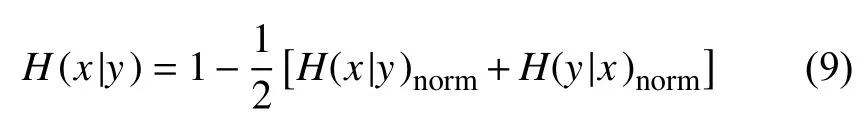
2.2 真实网络实验
2.3 人工网络实验
3 结论与展望
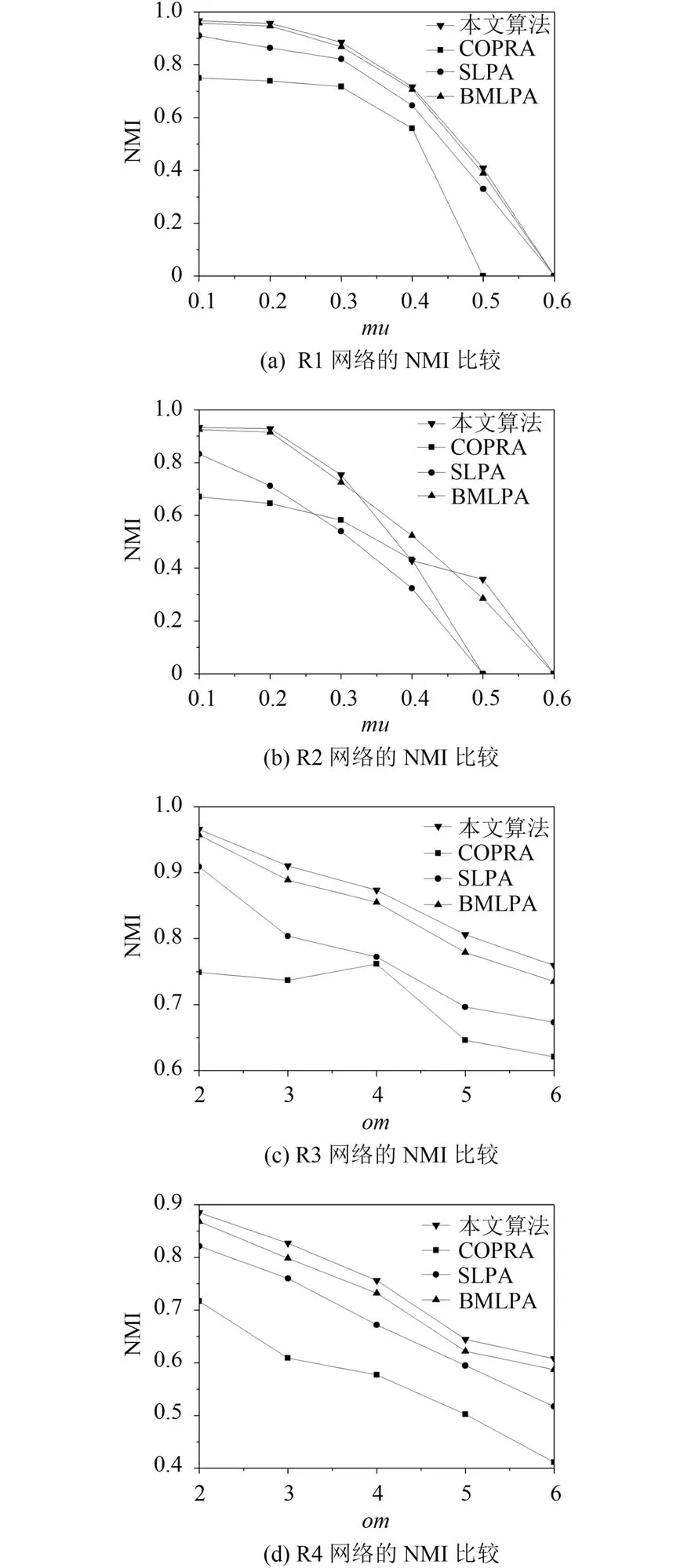
猜你喜欢
建材发展导向(2021年19期)2021-12-06
计算机仿真(2021年6期)2021-11-17
临床骨科杂志(2020年1期)2020-12-12
河北画报(2020年8期)2020-10-27
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
Coco薇(2015年11期)2015-11-09
