
对抗深度强化学习为自动驾驶汽车保驾护航
2018-06-11 09:32AidinFerdowsiUrsulaChallitaWalidSaadNarayanMandayam
机器人产业 2018年3期
□文/ Aidin Ferdowsi、 Ursula Challita、Walid Saad、Narayan B. Mandayam
对于自动驾驶汽车(AV)而言,要想在未来的智能交通系统中以真正自主的方式运行,它必须能够处理通过大量传感器和通信链路所收集的数据。这对于减少车辆碰撞的可能性和改善道路上的车流量至关重要。然而,这种对通信和数据处理的依赖性使得AV很容易受到网络物理攻击。最近,美国弗吉尼亚理工大学电气与计算机工程系的Aidin Ferdowsi和Walid Saad教授、瑞典爱立信研究院的Ursula Challita教授,以及美国罗格斯大学的Narayan B. Mandayam教授,针对自动驾驶汽车系统中的“安全性”问题,提出了一种新型对抗深度强化学习(RL)框架,以解决自动驾驶汽车的安全性问题。
可以这样说,为了能够在未来的智能城市中有效地运行,自动驾驶汽车(AV)必须依靠车内传感器,如摄像头和雷达,以及车辆间的通信。这种对于传感器和通信链路的依赖使得AV暴露于攻击者的网络物理(CP)攻击之下,他们试图通过操纵它们的数据来控制AV。因此,为了确保安全和最佳的AV动力学控制,AV中的数据处理功能必须针对这种CP攻击具有强大的鲁棒性。为此,本文分析了在存在CP攻击情况下监视AV动力学的状态估计过程,并提出了一种新的对抗深度强化学习(RL)算法,以最大化AV动力学控制针对CP攻击的鲁棒性。我们在博弈论框架中对攻击者的行为和AV对CP攻击的反应进行了研究。在制定的游戏中,攻击者试图向AV传感器读数中注入错误数据,以操纵车辆间的最佳安全间距,并潜在地增加AV事故的风险或减少道路上的车流量。与此同时,AV作为一名防守者,试图将间距的偏差最小化,以确保具有针对攻击者行为的鲁棒性。由于AV没有关于攻击者行为的信息,并且由于数据值操作的无限可能性,因此玩家以往交互的结果被输入到长短期记忆网络(LSTM)块中。每个玩家的LSTM块学习由其自身行为产生预期间距偏差,并将它们馈送给其RL算法。然后,攻击者的RL算法选择能够最大化间距偏差的动作,而AV的RL算法试图找到最小化这种偏差的最佳动作。模拟结果表明,我们所提出的对抗深度RL算法可以提高AV动力学控制的鲁棒性,因为它可以最小化AV间的间距偏差。

图1:文中所提出的对抗深度强化学习算法的体系结构
智能交通系统(ITS)将包括自动驾驶汽车(AV)、路边智能传感器(RSS)、车辆通信,甚至是无人机。为了在未来的ITS中能够以真正自主的方式运行,AV必须能够处理通过大量传感器和通信链路所收集的大量ITS数据。这些数据的可靠性对于减少车辆碰撞的可能性和改善道路上的车流量至关重要。然而,这种对通信和数据处理的依赖性使得AV很容易受到网络物理攻击。特别是,攻击者可能会在AV数据处理阶段进行插入,通过注入错误数据来降低测量的可靠性,并最终导致事故或危及ITS中的交通流量。这样的流量中断还可以波及到其他相互依赖的关键基础设施,例如为ITS提供服务的电网或蜂窝通信系统。
最近,科学家们已经提出了一些解决车辆内部安全问题的安全性解决方案。P.Kleberger、T. Olovsson和E. Jonsson在他们所著的《联网汽车车载网络的安全问题》中,确定了车辆控制器的关键漏洞所在,并提出了许多入侵检测算法用以保护该控制器。此外,在《对联网汽车的实际无线攻击和车辆内部的安全协议》中,作者指出,AVs当前安全协议中的远程无线攻击可能会中断其控制器区域网络。他们分析了AVs车辆内部网络对局外无线攻击的脆弱性。同时,《插入式车辆的安全性问题》的作者解决了插电式电动汽车的安全性挑战,同时考虑了它们对电力系统的影响。此外,在《关于嵌入式汽车网络安全威胁和保护机制的调查》中介绍了嵌入式汽车网络安全威胁和保护机制的调查。
此外,科学家们还研究了车辆通信安全挑战和解决方案,分析了当前车辆通信体系架构的安全漏洞。另外,科学家们发现,通过使用短期认证方案和合作车辆计算架构,可以减轻由信标加密引起的计算开销。
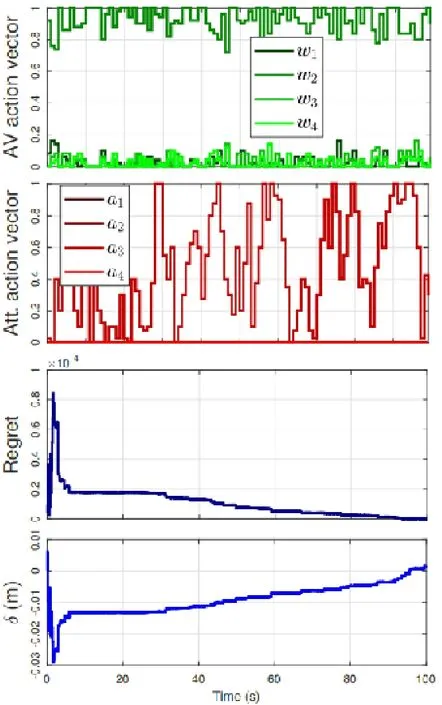
图2:在攻击者只攻击信标信息的情况下,AV和攻击者的行为、regret以及我们提出的算法的偏差。
然而,在设计安全解决方案时,以往的一些研究成果中的体系构架和解决方案没有兼顾AV 的网络层与物理层之间的相互依赖性。此外,现有的研究没有对攻击者的行为和目标进行合理的建模。在这种情况下,攻击者的行为和目标的这种网络物理依赖性将有助于提供更好的安全解决方案。另外,在一些以往的研究成果中,现有技术没有提供能够增强AV动力学控制应对攻击的鲁棒性的解决方案。然而,设计一个最佳且安全的ITS需要对车辆间传感器和车辆间通信的攻击具有鲁棒性。而且,现有的ITS安全性研究往往假设攻击者的行为处于稳定状态,然而在许多真实情况下,攻击者可能会自适应地改变其策略以增强攻击对ITS的影响。
因此,本文提出了一种新型对抗式深度强化学习(RL)框架,旨在提供具有鲁棒性的AV控制。特别要强调的是,我们提出了一种车辆跟随模型(car following model),在该模型中,我们将关注的重点放在紧跟在另一个AV后的一个AV的控制上。这样的模型是恰当的,因为它会捕捉AV的动力学控制,同时记录AV的传感器读数和信标。我们考虑通过车内传感器(例如摄像头、雷达、RSS、车内信标)收集领先AV的四个信息源。我们认为攻击者可以向这些信息中心注入不良数据,并试图增加事故风险或减少车流量。相比之下,AV的目标是保持对攻击者的数据注入攻击(data injection attacks)具有鲁棒性的同时,最大限度地控制其速度。为了分析AV和攻击者之间的交互,我们提出了一个博弈问题,并分析了它的纳什均衡(NE)。然而,我们注意到,由于存在连续的攻击者和AV动作集以及连续的AV速度和间隔,使得在NE处获得AV和攻击者动作具有挑战性。为了解决这一问题,我们提出了两个基于长短期记忆网络(long-short term memory)(LSTM)块的深度神经网络(DNN),针对AV和攻击者,提取过去AV动态的总结,并将这些总结反馈给每个玩家的RL算法。一方面,AV的RL算法试图通过结合传感器读数来从领先的AV速度中学习最佳估计。另一方面,攻击者的RL算法试图欺骗AV,并偏离车辆间的最佳安全距离。模拟结果表明,所提出的深度RL算法收敛于混合策略的纳什均衡点,可以显著提高AV针对数据注入攻击的鲁棒性。结果还表明,AV可以利用所提出的深度RL算法来有效学习传感器融合规则,最大限度地减小速度估计误差,从而减小了与最优安全间距的偏差。
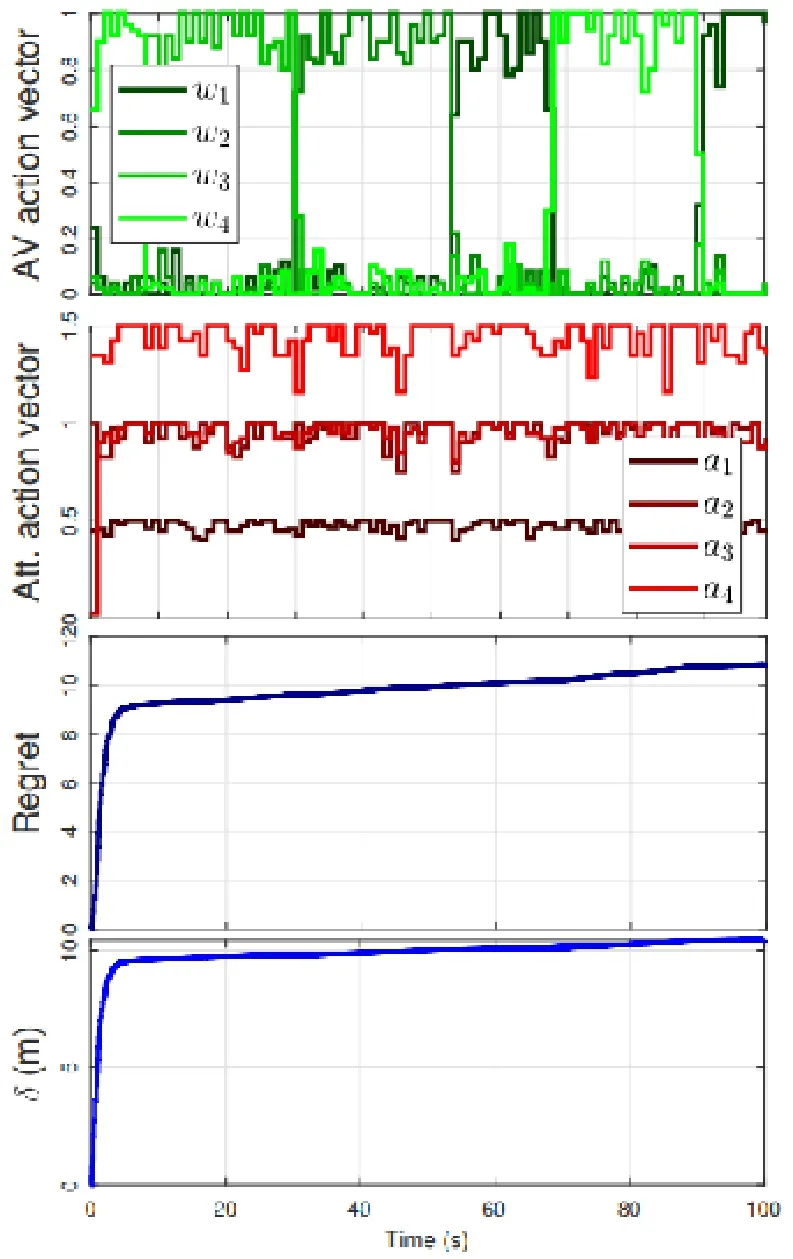
图3:在攻击者攻击所有传感器的情况下,AV和攻击者的行为、regret和偏差。
本文提出的新型深度RL方法,该方法能够在传感器读数受到数据注入攻击的情况下,实现对AV的具有鲁棒性的动力学控制(robust dynamics control)。为了分析攻击者攻击AV数据的动机,同时了解AV对这类攻击的反应,我们提出了攻击者与AV之间的博弈问题。我们已经表明,在纳什均衡(the mixed strategies at Nash equilibrium)中推导出混合策略,从分析角度而言是具有挑战性的。因此,我们使用我们提出的深度RL算法学习AV在每个时间步长中的最优传感器融合。在所提出的深度RL算法中,我们使用了LSTM块,它可以提取AV和攻击者动作及偏差值之间的时间特征与依懒性,并将其反馈给强化学习算法。模拟结果表明,利用所提出的深度RL算法,AV可以缓解数据注入攻击对传感器数据的影响,从而保持对这些攻击的鲁棒性。

猜你喜欢
现代电子技术(2022年11期)2022-06-14
商界评论(2022年1期)2022-04-13
科技研究·理论版(2021年22期)2021-04-18
学生天地(2020年6期)2020-08-25
数学大王·趣味逻辑(2019年10期)2019-11-06
爱你·心灵读本(2018年6期)2018-09-10
爱你(2018年16期)2018-06-21
草原(2018年2期)2018-03-02
电脑知识与技术(2016年28期)2016-12-21
汽车科技(2016年5期)2016-11-14
