
一种基于深度学习的异常行为识别方法
2018-06-08 07:16杨锐罗兵郝叶林常津津
五邑大学学报(自然科学版) 2018年2期
杨锐,罗兵,郝叶林,常津津
一种基于深度学习的异常行为识别方法
杨锐,罗兵,郝叶林,常津津
(五邑大学 信息工程学院,广东 江门 529020)
异常行为识别与检测在安防领域有广泛的应用前景,但现有的异常行为识别方法时序信息利用率低,准确率和处理速度还难以满足实际需要. 本文采用三维密集连接深度网络结构对采集视频的时序和空间特征进行基于深度学习的建模,对打架、徘徊、抢劫这三类异常行为以及正常行为类进行识别,采用多个可变时序深度的卷积核,并结合深度可分离卷积层重新设计了时序过渡层,更多地利用输入信号中的时序信息. 模拟实验结果表明,本文提出的改进方法准确率达92.5%,进一步提高了模型的准确率和泛化性能.
异常行为;动作识别;深度学习;时序过渡
异常行为识别是行为识别中一个具体化的子类,相对其他种类的行为识别,异常行为的研究显得更具有现实意义,它关乎人们切身利益——安全,异常行为的发生通常标志着异常事件的发生. 自动柜员机(ATM)24小时工作无人值守,为日常生活带来了方便的同时也存在安全隐患,ATM机取款后被抢劫的犯罪事件常有发生. 通过ATM的视频监控自动识别取款室范围内的异常行为显得尤为重要. 当识别出抢劫、打架、徘徊等行为时,系统自动报警并主动暂停现金支付、暂停退卡或锁闭防护室门等后续动作,可以有效预防ATM机前的犯罪行为. 因此,基于视频的异常行为识别是需要研究的关键技术.
深度学习理论在静态图像识别和检测上的优越表现为具有时间序列的视频行为识别研究提供了新的思路,使得行为识别和深度学习理论的紧密结合成为了智能视频分析领域的研究热点[1]. 与此同时,现有行为识别的研究表明,深度学习比传统的机器学习在处理具有复杂动作的视频行为识别中更有效. 本文利用深度学习方法对特定场景下的ATM机前异常行为进行识别,设计了具有密集连接特性的深度网络,挖掘时序线索并结合深度可分离卷积(Depthwise Separable Convolution)[2],充分利用了动作间的时序信息、空间信息进行识别,使异常行为识别性能明显改善.
1 深度学习与异常行为识别
1.1 异常行为的定义
异常行为的定义取决于应用场景,并且会受到一定程度的主观影响,从而导致同一种行为在不同场景下会有不同的定义,例如从暴恐案发生现场逃离的人群,是一种典型的异常行为,而参加马拉松赛跑的人群则是一种正常行为,同样都是人群跑动行为却有着截然不同的定义,因此对异常行为作出明确的定义往往是不太合适的. 但一般而言,异常行为应该具备低频性、可疑性以及非典型性. 结合具体的应用场景来说,对异常行为的定义是可行的,也是非常必要的. 正是由于异常行为定义的不确定性因素的影响,使得同一种算法适用于通用的应用场景变得不切实际. 为了最小化这种不确定性因素的影响,需具体问题具体分析,首先需要确定应用的场景,根据应用场景来分析并定义异常行为类别.
1.2 异常行为的分类
单人异常行为(如徘徊、越界、跌倒等)是只需一个人参与的一类异常行为. 交互行为异常(如抢劫、打架等)通常指双方发生肢体冲突的一类异常行为. 群体异常行为(如因骚乱造成的人群逃离)指由多人形成的一个不可分的、整体上发生的一类异常行为,需综合考虑群体密度与运动特征. 由此可见,针对ATM机所处的场景,适合研究单人异常行为中的徘徊以及交互异常行为中的打架和抢劫这3类异常行为.
1.3 基于深度学习的异常行为识别
深度学习目前已广泛应用于行为识别,但鲜有将深度学习专门用于特定场景异常行为识别的.而现有的大型标准数据集通常都是生活中常见的视频行为数据,也使得基于深度学习的异常行为识别研究难以推广.
卷积神经网络在诸如分类、检测、分割等针对静态图像的计算机视觉任务中表现十分出色,而对于基于视频分析的任务,静态图像中使用的二维卷积并不能很好地捕获视频序列中的运动信息,因此通常需要引入额外的辅助信息,如在二维卷积的基础上增加时间维度扩展为三维卷积,以便同时获得捕获时序和空间运动信息的能力.
在深度学习行为识别中一种常用的方法是使用双流卷积神经网络. Simonyan等[3]提出了一个双路的卷积神经网络,用来分别捕获空间和时序信息,主要特点是使用两种模态的特征,使用RGB以及堆叠的光流帧,其中RGB用来提供外形信息,引入的光流用来捕获行为时序上的运动特征,后续也出现了各种基于双流网络的变体[4-5],极大地提高了动作识别的性能,然而双流网络一般需要事先提取光流,且对于大型数据集来说,这是一个非常耗时的过程,不适宜进行端到端的学习.
为解决双流网络中存在的上述问题,三维卷积神经网络逐渐进入了人们的视野,并在行为识别任务中取得了革命性的突破. Ji等[6]最先提出并应用三维卷积从视频中提取时空特征进行人体动作识别. Tran等[7]提出了C3D(Convolutional 3D)网络,C3D通过增加时间维度可同时对外观和运动信息进行建模,并且在各种视频分析任务上超过了二维卷积神经网络特征,后续C3D的变体[8-10]也充分证明了三维卷积神经网络相比二维卷积神经网络更适合时空特征学习. 另外,在考虑使用基于C3D进行行为识别的实际应用中,Gu[10]提出了具有密集连接特性的深度卷积神经网路3D DenseNet,并对购物行为进行了识别,取得了不错的效果,这得益于该网络具有足够的深度以及最大化了信息的流动. 深度三维卷积神经网络中常用的基于视频的异常行为识别流程如图1所示.

图1 基于视频的异常行为识别流程
Huang等[11]提出了一种具有密集连接特性的深度卷集神经网络DenseNet. 在该网络所有的层中,两两之间都存在连接,也就是说,网络每一层的输入都是由前面所有层输出特征图的并集组成,而该层所学习的特征图也会作为后面所有层的输入. DenseNet可以有效解决梯度消失问题,强化特征传播,支持特征重用以及大幅度减少参数数量. 鉴于C3D以及密集连接特性的诸多优点,本文同样也采用了类似具有密集连接特性的C3D网络进行异常行为识别.
2 深层网络模型的改进
2.1 异常行为识别现有技术的不足
在人体行为识别中,人体是非刚性的目标主体,其行为出现的形式具有非常大的灵活性,这使得识别和检测异常行为变得非常具有挑战性,因此如何有效提取可判别的行为特征是一个研究难点. 与行为的外形特征相比,由于时序上的运动特征往往不能很好地建模,容易造成部分关键时序运动信息发生丢失. 在以往的时序结构中,大多在整个网络结构中使用一种固定时序深度的三维卷积进行特征提取,这种方式不利于融合多时间跨度的时序信息,从而导致时序信息得不到充分利用,进而阻碍了行为识别准确率的进一步提升. 为了弥补这种不足,使用可变时序深度三维卷积并结深度可分离卷积融合多时间跨度的时序信息,使用密集连接的特性最大化网络的信息流动,使得时空信息被充分利用以提高行为识别准确率.
2.2 基于3D DenseNet的改进
为了有效地完成行为识别任务,需增加DenseNet的时间维度以扩展到三维的情形从而构成3D DenseNet. 为此,我们根据C3D网络结合DenseNet实现了3D DenseNet的相关算法,并将包含固定时序卷积核深度的时序过渡层扩展为包含多个可变时序深度的卷积核过渡层,使其能够对时序信息进一步提炼并建模. 在3D DenseNet基础上通过增加深度可分离卷积的可变时序深度三维卷积进行了进一步的改进,使得改进后的网络能更加充分利用动作间的时序信息进行建模.
与DenseNet中定义类似,3D DenseNet中两个相邻的三维密集块之间的层称为时序过渡层,并通过三维卷积和池化来改变特征图的大小. 时序过渡层由4个串联的可变时序深度的三维卷积层组成,后面接一个1×1×1的三维卷积层和一个2×2×2的平均池化层. 由于层之间的特征图存在大小差异,导致池化图层执行下采样操作时会与执行式(5)中特征图的串联操作冲突,故需将网络划分为多个密集连接的密集块,并在它们之间添加过渡层. 如图2所示,三维时序卷积以端到端的方式进行学习.

图2 三维时序卷积



表1 整体结构设计
2.3 模型结构改进分析

普通卷积操作为

深度可分离卷积在式(6)的基础上,考虑区域和通道的方式变为先考虑区域再考虑通道的方式,实现了区域和通道分离. 深度可分离卷积的计算过程是在执行逐点卷积(Pointwise Convolution)前先执行深度卷积(Depthwise Convolution):
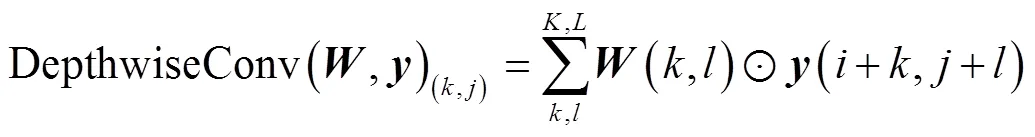
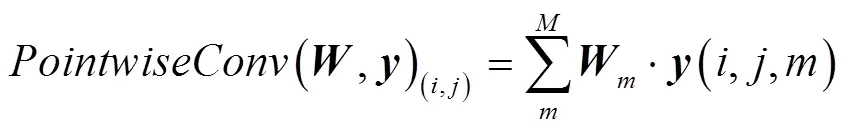
从而构成

3 实验及结果分析


表2 实验数据集的组成结构

图3 实验数据集中的部分训练样本
为了证明本算法的有效性,本实验实现了3D DenseNet的相关算法,并在其基础上按照上述的改进细节在自建的ATM前异常行为模拟数据集上实施了本次对比实验. 表3和表4分别为使比对算法和本算法在相同验证集中的统计结果.

表3 比对算法在验证集中的统计结果

表4 本算法在验证集中的统计结果
将表3和表4的统计结果汇总为表5所示.

表5 算法比对结果
从表5中可以看出,对打架行为的识别的准确率最高,抢劫行为的识别准确率最低,徘徊和取款行为居中并且识别准确率相近. 这可以解释为打架行为动作幅度大,具有的运动特征比较明显,而抢劫行为与打架行为有着较高的相似度,甚至可以看作是打架行为的特例,导致抢劫行为识别较为困难. 同样,徘徊行为和取款行为也存在一定的共性,但徘徊行为相对于取款行为来说空间位置变化比较大,使得徘徊行为和取款行为可以较为容易区分并准确识别. 对表5中的行为类别准确率进行平均得到了表6中的平均准确率,并在表6中对模型参数量进行了比较.

表6 平均准确率和模型参数量
从表6中的实验结果可以看出,本文算法与改进前的算法在准确率上有了进一步的提升,同时模型参数量仅有小幅度的增加. 这说明了本算法在参数效率和准确率之间得到了较好的平衡.

图4 测试集中测试结果部分视频截图
从图4结果来看,能较为准确地识别出对应的行为,由此证明了本实验改进算法的有效性.
为验证模型的泛化能力,从网络上下载了几个与训练类别相关的视频片段,并对其进行测试.

图5 实际测试结果部分视频截图
从图5结果来看,本算法可以较好地识别实际场景中的对应行为,具有较好的模型泛化性能.
4 总结
将深度学习应用于ATM视频的异常行为识别,改进深度网络结构模型,在基于3D DenseNet引入具有可变时序深度的卷积核过渡层并结合深度可分离卷积层,提高了模型对时序信息的利用率,进一步提高了模型的准确率和泛化性能. 由于对送入到时序过渡层中的特征实施了适当的降维操作,使得参数效率和准确率获得较为理想的折中效果. 由于实验条件和资源有限,获取的样本数量还不够大,在后续的工作中将结合实际ATM视频,研究增加样本数量后如何提高识别的准确性.
[1] 朱煜,赵江坤,王逸宁,等. 基于深度学习的人体行为识别算法综述[J]. 自动化学报,2016, 42(6): 848-857.
[2] CHOLLET F. Xception: deep learning with depthwise separable convolutions [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, Hawaii: IEEE,2017: 1251-1258.
[3] SIMONYAN K, ZISSERMAN A. Two-stream convolutional networks for action recognition in videos [C]// International Conference on Neural Information Processing Systems, Montreal: MIT Press,2014:568-576.
[4]FEICHTENHOFER C, PINZ A, WILDES R P. Spatiotemporal multiplier networks for video action recognition [C]// IEEE Conference on Computer Vision and Pattern Recognition, Hawaii: IEEE, 2017: 7445-7454.
[5] FEICHTENHOFER C, PINZ A, WILDES R. Spatiotemporal residual networks for video action recognition [C]//Proceedings of the 30th International Conference on Neural Information Processing Systems. New York: Curran Associates Inc, 2016: 3476-3484.
[6] JI Shuiwang, XU W, YANG Ming, et al. 3D Convolutional Neural Networks for Human Action Recognition [J]. IEEE Transaction Pattern Analysis and Machine Intelligence, 2013, 35(1): 221-231.
[7] TRAN D, BOURDEV L, FERGUS R, et al. Learning Spatiotemporal Features with 3D Convolutional Networks [C]//2015 IEEE International Conference on Computer Vision (ICCV), Boston:IEEE, 2015: 4489-4497.
[8] HARA K, KATAOKA H, SATOH Y. Learning spatio-temporal features with 3D residual networks for action recognition [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Hawaii: IEEE, 2017: 3154-3160.
[9] SHOU Zheng, CHAN J, ZAREIAN A, et al. CDC: convolutional-de-convolutional networks for precise temporal action localization in untrimmed videos[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, Hawaii: IEEE, 2017: 1417-1426.
[10] GU Dongfeng. 3D densely connected convolutional network for the recognition of human shopping actions [D]. Ottawa: University of Ottawa, 2017.
[11] HUANG Gao, LIU Zhuang, VAN der M L, et al. Densely connected convolutional networks[C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Hawaii: IEEE, 2017: 2261-2269.
[12] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]//Advances in Neural Information Processing Systems, California: NIPS, 2017: 6000-6010.
[责任编辑:韦 韬]
A Method for Abnormal Behavior Recognition Based on Deep Learning
YANGRui, LUOBing, HAOYe-lin, CHANGJin-jin
(School of Information Engineering, Wuyi University, Jiangmen 529020, China)
Abnormal behavior recognition and detection have extensive application prospects in the field of security; however, the existing abnormal behavior recognition methods are low in the utilization rate of temporal information, and the accuracy and speed of processing cannot meet the actual needs. In this paper, the 3-D densely connected deep network architecture is employed to perform modeling of the temporal and spatial features of the video acquisition based on deep learning, and to recognize normal behavior and the three types of abnormal behavior: fighting, loitering, and robbery. Multiple convolution kernels with variable temporal depth combined with depthwise separable convolutional layers can be adopted to redesign the time series transition layer so as to make more use of temporal information from the input signals. Simulation results show that the accuracy of the proposed method reaches 92.5%, which further improves the accuracy and generalization performance of the model.
abnormal behavior; action recognition; deep learning; temporal transition
TP216.1
A
1006-7302(2018)02-0023-08
2018-03-09
杨锐(1992—),男,湖北孝感人,在读硕士生,主要研究方向为数字图像处理及应用;罗兵,教授,博士,硕士生导师,通信作者,主要研究方向为机器视觉、智能信息处理、数家图像处理及应用.
猜你喜欢
小猕猴智力画刊(2022年3期)2022-03-28
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
铁道建筑技术(2020年11期)2020-05-22
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
中国交通信息化(2018年5期)2018-08-21
北京航空航天大学学报(2018年1期)2018-04-20
