
基于机器学习的图书智能采编模式的构建
2018-06-06 00:48:48
中华医学图书情报杂志 2018年12期
图书馆编目业务外包是指图书馆将编目业务以合同的形式委托给书商或专业机构处理的方式[1]。徐州医科大学图书馆(以下简称“我馆”)2017年开始将编目业务全部外包给书商,通过编目外包缩短了新进图书的上架时间,降低了图书馆的运营成本,提高了图书馆的咨询和学科服务水平[2-3]。但由于外包编目人员知识水平欠缺、流动性大,导致编目质量低下,需要我馆的编目人员进行审核,加大了数据校验的难度,难以提高工作效率[4-5]。编目数据的著录、分类、标引等工作外包的模式也一直存在争议。如董剑平曾指出图书著录、分类、标引是关系到图书馆实现知识组织功能和社会文献流整序功能的核心工作,外包不利于图书馆的读者服务和的可持续发展[6]。
鉴于图书馆编目外包模式中存在书商编目人员不够专业、不甚了解各个图书馆编目细则和流动性大等问题,难以保证外包的编目质量著录、分类和标引由本馆编目人员完成的部分外包模式虽然保证了编目质量,但效率低,外包效果不够明显,使编目外包陷入了两难的境地。因此,以汇文系统为例,在现有图书管理系统和编目部分外包的基础上,结合机器学习技术实现自动批量智能采访、批量智能套录、智能分类和智能生成索书号的功能,提高采访和编目效率,最后由本馆的编目人员进行编目数据审核和图书实物验收。严把编目质量关的编目外包智能采编新模式,对图书馆编目外包模式和流程进行了创新研究,对图书馆编目外包业务的深入开展具有一定的借鉴意义,有利于图书馆的可持续发展。
1 基于机器学习技术的图书馆智能采编解决方案
1.1 机器学习在中文书目自动分类中的应用
机器学习(Machine Learning)技术是指采用计算机模拟人类的学习行为,通过学习训练从已知样本中寻找规律,并利用规则对未知数据进行预测,目前已广泛应用于图书自动分类。机器学习技术能够根据中文图书的题名、关键词和摘要等内容特征自动给出中图法分类号,常用的方法有朴素贝叶斯法、K近邻、支持向量机以及人工神经网络等[7-8]。杨晓花提出使用多父差分进化策略挖掘上一代更多的额外信息,提高朴素贝叶斯的分类精度,以便获取全局最优的解决方案[9];杨敏提出构建基于词频和TFIDF(Term Frequency-inverse Document Frequency)混合特征的向量矩阵,再利用支持向量机(SVM)算法对图书进行自动分类效果更好[10];郭利敏提出构建基于题名、关键词的多层次卷积神经网络模型,使之能够根据文献的题名和关键词自动给出中图分类号,以此提高图书分类的准确性[11]。
1.2 图书自动分类器的构造方法
基于机器学习的图书分类器的构造主要包括预处理、特征提取和机器学习3个关键环节[12-14]。
本文预处理首先提取MARC数据中的题名、主题、摘要和索书号等信息并转化为Excel格式,再采用Python的pandas库的DataFrame对象进行数据清洗,采用jieba分词对题名、摘要(或主题等)进行分词处理,得到文本所包含的词条信息,将非结构化的文本信息转换为结构化的词条信息。
本文使用词频加TFIDF混合特征提取方法,将词条信息描述为向量空间模型。图书的书名对揭示图书内容和主题的作用更加重要,所以将书名用于词频特征提取能更明显地区分图书的类别。摘要是图书内容的简介和主旨介绍,能够提取更多的特征,使机器学习的效果更好,分类更准确。但由于其内容较多,重复的、与书目主题关联性不大的内容易产生噪音,把“了”“的”“本书”等无意义的词剔除后,提取词频特征和TFIDF特征进行修正,并为每个特征分配不同权重。对于候选特征需要将其转换为SVM机器学习所需要的特征向量矩阵,其中每行代表一个书目,每列代表测试数据中抽取出的一个特征,矩阵中的每个元素代表特征的值。如公式1所示,Bi代表书目i的特征向量, Cij代表书目i中第J个特征的值。
Bi=[Ci1,Ci2,Ci3,......Cij]
(公式1)
式中,Cin= H1×FTin + H2×FAin + H3×TFIDF(n,i)
(公式2)
式中,TFIDF(n,i)= TF(n,i) × IDF(n)
(公式3)
公式2中,H1表示特征词出现在书名中的权重,FTin表示特征词n在i书名中出现的频率;H2代表特征词出现在书目摘要中的权重,FAin表示特征词在i书目摘要中出现的频率;H3表示特征词在摘要中的TFIDF值的权重,TFIDF(n,i)表示特征词n在i书目摘要中的TFIDF值。H1+H2+H3=1。
公式3中,TFIDF特征用两个项的乘积表示。TF(n,i)项表示特征n在书目i摘要中出现的频度,该值越大说明特征n在书目i的相关性越强和该特征n对书目i越重要;IDF(n)项表示逆文档频度,可以表示为IDF(n)-log10(N/DF(n)),其中N表示训练书目总数,DF(n)表示特征 n 在所有训练书目摘要中出现的总次数。可见在所有书目中,特征n出现的频度越大,说明该特征n对书目的区分能力越弱。在书目分类时,特征的TFIDF 值越高,表明该特征的区分能力越强。经过测试发现,H1取值0.7、H2取值0.2、H3取值0.1时能达到最佳的分类效果。支持向量机算法具有泛化能力强、计算复杂度样本空间维数关联小的特点,所以本文使用支持向量机算法进行机器学习构建中文图书多级分类器。先构建大类分类器(支持22个图书大类),然后再构建每个大类的子分类器。在应用中,第一步先用大类分类器进行大类预测,大类分好后再用其子分类器进行子类预测,可根据具体大类的相关情况进行多级分类器设计,以达到更好的分类效果。
1.3 基于机器学习的图书智能采编模式
本文在现有图书管理系统和图书物理加工外包的基础上,提出利用机器学习实现图书自动分类,增加批量采访、著录、分类和标引的功能进行智能采访和编目,最后由本馆的编目人员进行数据审核和实物验收的图书编目外包方案。对现有的图书编目外包进行流程再造,构建图书智能采编新模式,使图书编目更加自动化和智能化,既能提高工作效率,又能发挥本馆编目人员的专业优势,保障编目质量。智能采编模式流程如图1所示。
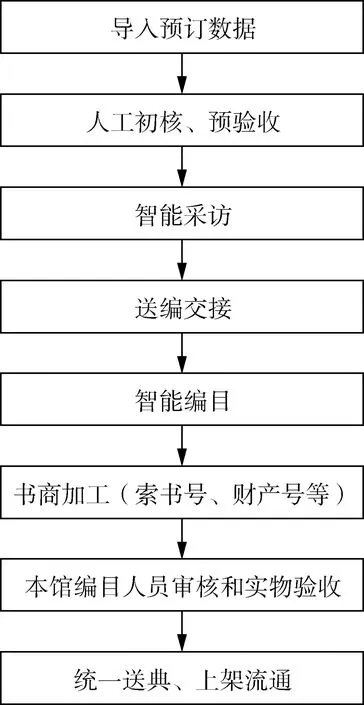
图1 图书馆智能采编模式总体流程
2 智能采访
书商先把ISBN、条码号(图书馆分配)、题名、责任者、出版社、版本、丛书项、金额、摘要、主题等书目信息整理成Excel表格,和新进图书及清单按一定的顺序一起提供给图书馆采访人员,由他们对图书进行人工初核、预验收。确定合格后,采访人员将Excel表格的数据在图书管理系统中批量进行智能采访[15]。以汇文系统为例,原汇文系统中需要采访人员一一扫描ISBN号、条码号进行关联、核对书目信息是否在预订数据之中、输入金额等。智能采访模块将批量导入书商提供的书目数据,并与对应的预订数据进行智能匹配,匹配条件为ISBN、题名、价格、册数等(系统可配置)。全匹配成功进入准入库单,匹配不成功时数据不一致进入待复核清单,预订数据中没有的进入未预订清单,书商数据中没有的进入未配清单。待复核清单需要采访人员与书商共同确认,修改书商数据后进行人工复核,进入准入库单,有问题的退回书商。未预订清单需要图书馆与书商协商哪些书目可以订购,采访员复核后新增数据进入准入库单,其他退回书商。未配清单需要书商注明理由,如遗漏、缺货或是分批供应等。所有问题都处理完后,将准入库单进行入库,并在系统中与条码进行绑定,生成财产号,写入MARC数据[16]。可提前配置好财产号的产生规则,如是否与条码号一致、编码规则和自增规则等。入库后打印入库单,进行批量送编。整个智能采访的流程如图2所示。
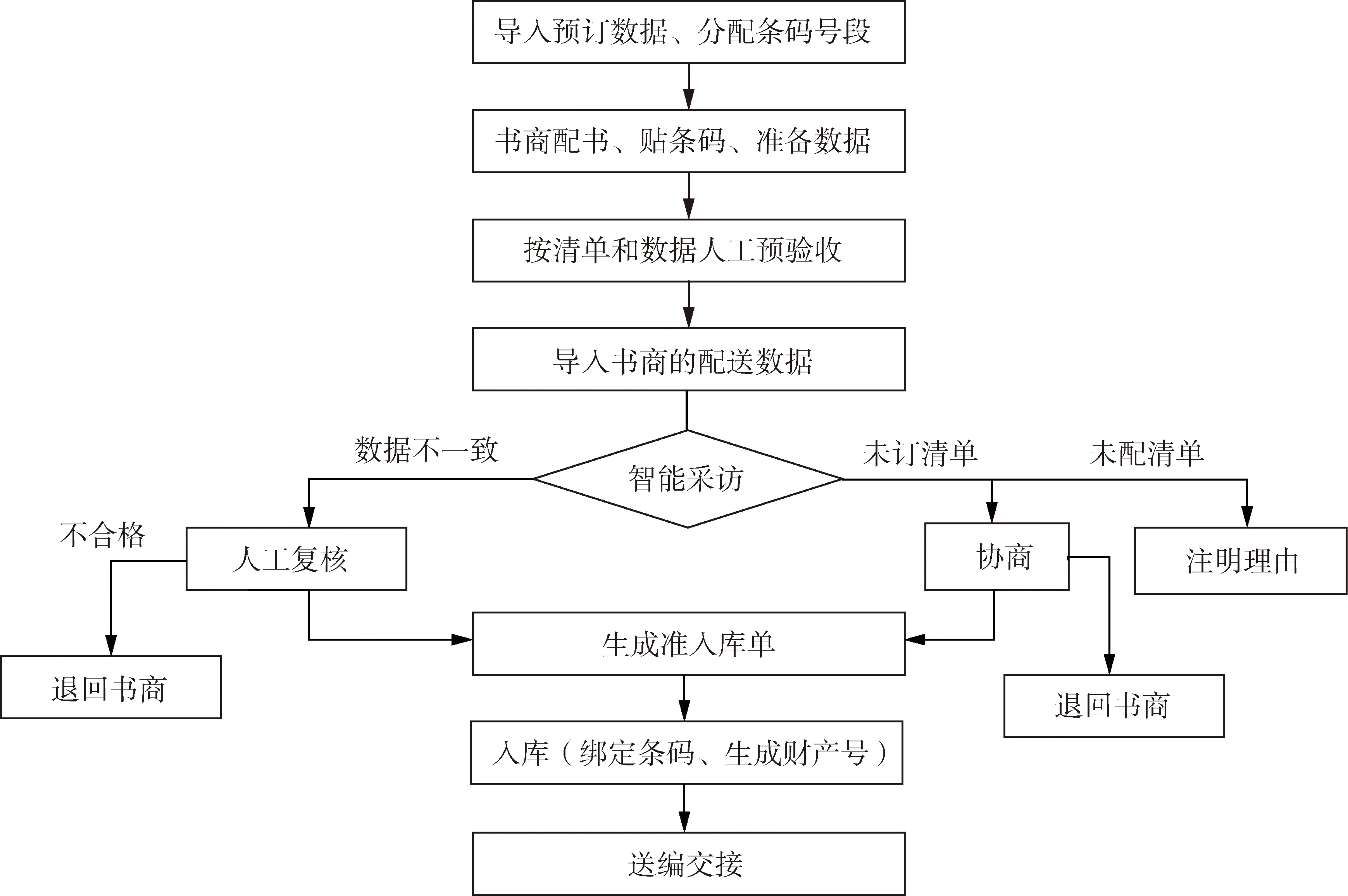
图2 图书馆图书智能采访流程
3 智能编目
智能编目可以按送编批次批量套录、智能分类和种次号分配,因此可以极大地提高编目效率。具体流程图如图3所示。这部分模块需要对现有图书管理系统进行升级改造。套录以使用较广泛的中国高等教育文献保障文献系统(CALIS)为例。
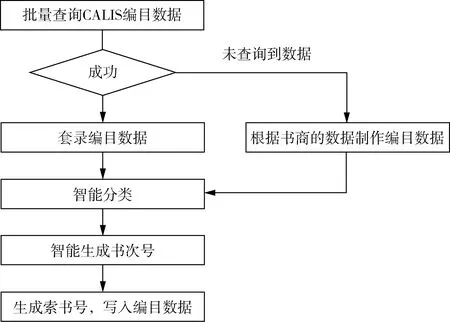
图3 图书馆图书智能编目流程
3.1 编目智能套录
系统支持根据ISBN从CALIS批量套录MARC数据。汇文系统只支持单个书目从CALIS套录MARC数据,需要增加批量套录的功能[17]。套录成功后将关键字段(题名、责任者、版本、出版社等)与书商提供的数据进行智能比对,一致则数据等级标记为一级,不一致标记为二级。若通过CALIS找不到,则根据书商提供的数据进行编目数据加工,数据等级标记为三级,以便编目人员在核对编目数据时分类差别化处理,提高编目数据质量和工作效率。
3.2 编目智能分类
图书馆要根据本校的类别、本馆的性质、任务和读者阅读需求,制定《中图法》本馆使用本,规定各类图书的分类详简级次,复分、仿分的使用规则,参见类目的使用规则,组配号的使用规则和并列关系的使用规则等[18]。参见类目:如某种疾病的食养、食疗入相关各类,同时可以参见TS972.161。如《糖尿病健康食疗图典》,我校医学院校分为R587.1,其他学校分为TS972.161。组配分类:如H319.4读物,以提高阅读能力为目的的各科简易读物、对照读物、注释读物,如愿细分,可用组配编号法。如我馆的《亚马孙恐怖之旅》为H319.4:I,《胃肠病学》为H319.4:R,我馆规定组配后面的分类不需要再细分,只到大类即可。并列关系:如《解剖学与组织胚胎学》,人体胚胎学为R321,人体解剖学为R322。有这种并列类目的时候,可以选择上位类R32为分类号,也可以根据本馆的规定,分到下位类。另外,各个大类在分类中,具体分到几级类目,也可以根据自身情况进行规定,然后根据每个图书馆的具体规则进行智能分类校正。根据图书MARC数据的题名(200字段)、摘要(330字段),各个主题字段(600、601、602、604、605、606、607、610等)利用机器学习技术掌握各馆的分类细则并对新进书目进行智能分类,不需对每一个细则在系统里进行人工设置。
我馆有100多万册图书和30多万MARC数据。按22个大类下载我馆的MARC数据中,I类有5万多条,R类有8万多条,只下载了30%的数据,其余的大类全部下载共计199 060条。首先进行MARC数据转换,提取题名、摘要、主题、索书号、作者、出版社等相关图书信息。经分析发现有多个分类号的图书在其各个大类下载的数据之中均有重复,同一本书在系统内有多个MARC数据有重复。然后进行数据清洗,利用索书号分配MARC数据的大类,这样有多个分类号的MARC数据(6 654条)大的分类号与我馆的实际应用一致,保证通过学习构造的分类器符合我馆的分类细节。再根据题名和摘要去重,保留有效数据,清洗后书目数据为192 574条,最后选取语料集。
为了提高图书分类器的分类精度,分类MARC数据小于2 000条的大类不再参与本文研究,其他大类每类取35%的数据(30%的训练语料,5%的测试语料),训练语料不满2 000条的按2 000选取,测试语料不满400条的按400选取。按上述规则从14个大类18万多书目数据中随机选取57 270条书目数据为训语料集,随机选取9 871条书目数据为测试语料集(表1)。
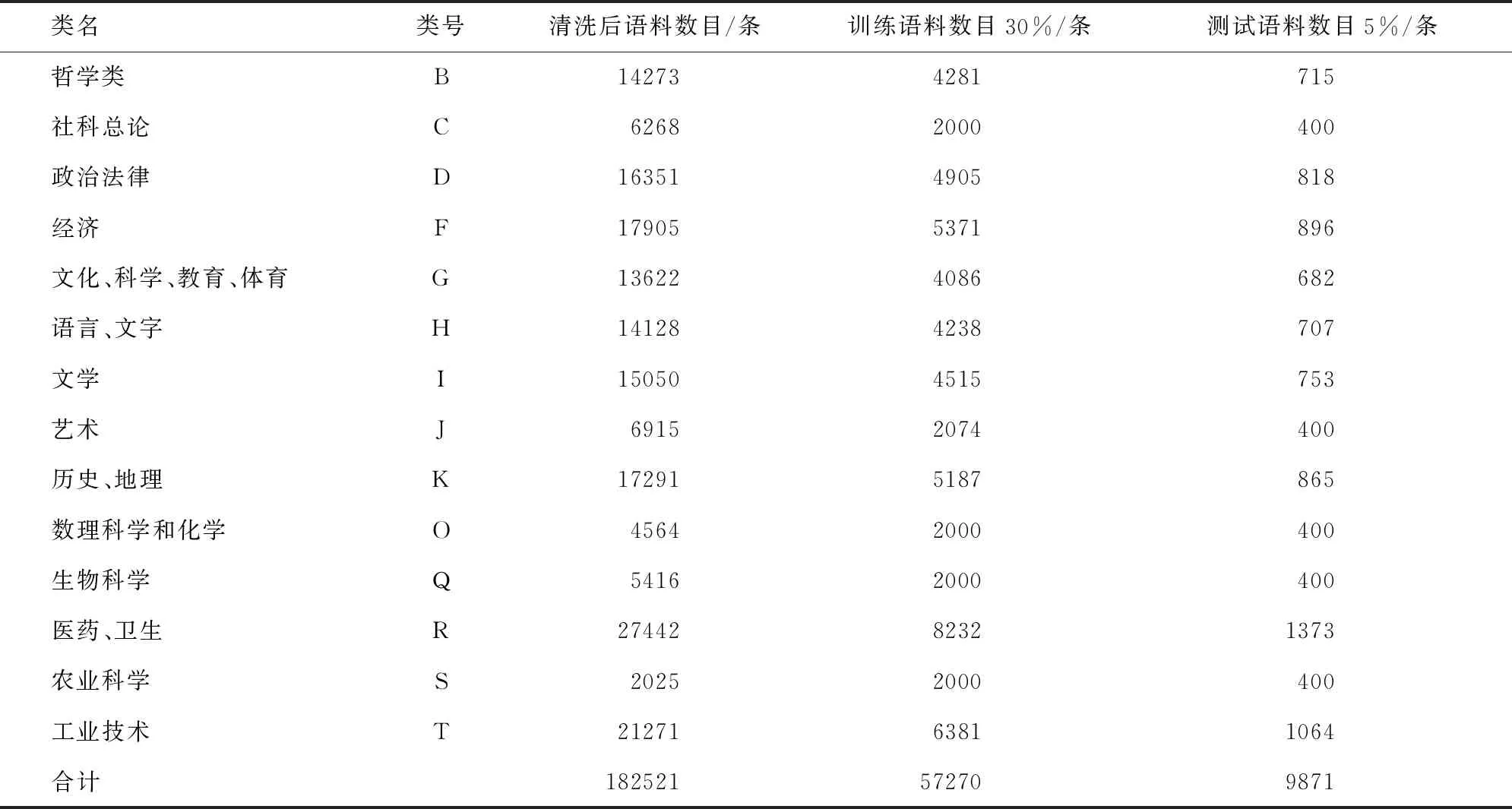
表1 智能分类语料集构成明细
分类器设计为2级分类,先按14个大类进行智能分类,分配完大类后再进行大类的子类智能分类,这样可以逐步缩小语料范围,提高分类精度和速度。以题名、摘要和各个主题字段为输入,分类号为类目标签,进行TFIDF特征提取,利用SVM算法进行监督学习,构建各级分类器。由于测试语料包括分类号,智能分类号与此分类号相同或互为上位类就算分类正确。如《软件工程》测试语料的原分类号为TP311.5,智能分类为TP311.5或TP311都算正确。实验表明一级大类分类器的测试正确率大概在94%~97%之间,二级分类器的测试正确率大概在88%~92%之间,综合正确率达到85%以上,符合日常工作的需求(表2)。
图书分类器为套录的MARC数据分配中图分类号,一、二级套录数据标记为校正中图分类号,与套录MARC数据中的中图分类号进行比对,不一致的标记供编目人员审核数据时进行处理;三级MARC数据直接采用此中图分类号。
3.3 索书号智能生成
索书号是由分类号加书次号组成。书次号即同类图书的区分号码,用来确定相同分类号图书的排架次序。图书编目时书次号的形成方式主要有分类种次号、四角著者号和汉语著者号3种,其中分类种次号最常用[19]。分类种次号是用流水号区分相同分类号的不同图书,即图书编目时,当第一次录入某个分类号时,对应的种次号为1,再录入时依次递增。系统支持批量多层次检索,智能分配种次号(支持多卷书、再版书等情况的复杂逻辑处理),生成索书号。我馆种次号分配规则如图4所示。
种次号生成的判断条件包括ISBN、题名、责任者、出版社、分类号、分辑题名或分卷题名、丛编、出版发行附注、责任者附注和版本附注等,生成规则包括与原书数据合并、再版书处理、多卷书处理和顺序生成种次号等。
智能图书编目系统支持批量用ISBN、题名及从编项进行检索,根据规则智能生成种次号,并支持各馆根据其自己的编目细则进行个性化设置,该系统符合各馆建设的标准和规范。最后分类号加种次号生成索书号,由本馆的编目人员进行数据审核和实物验收。
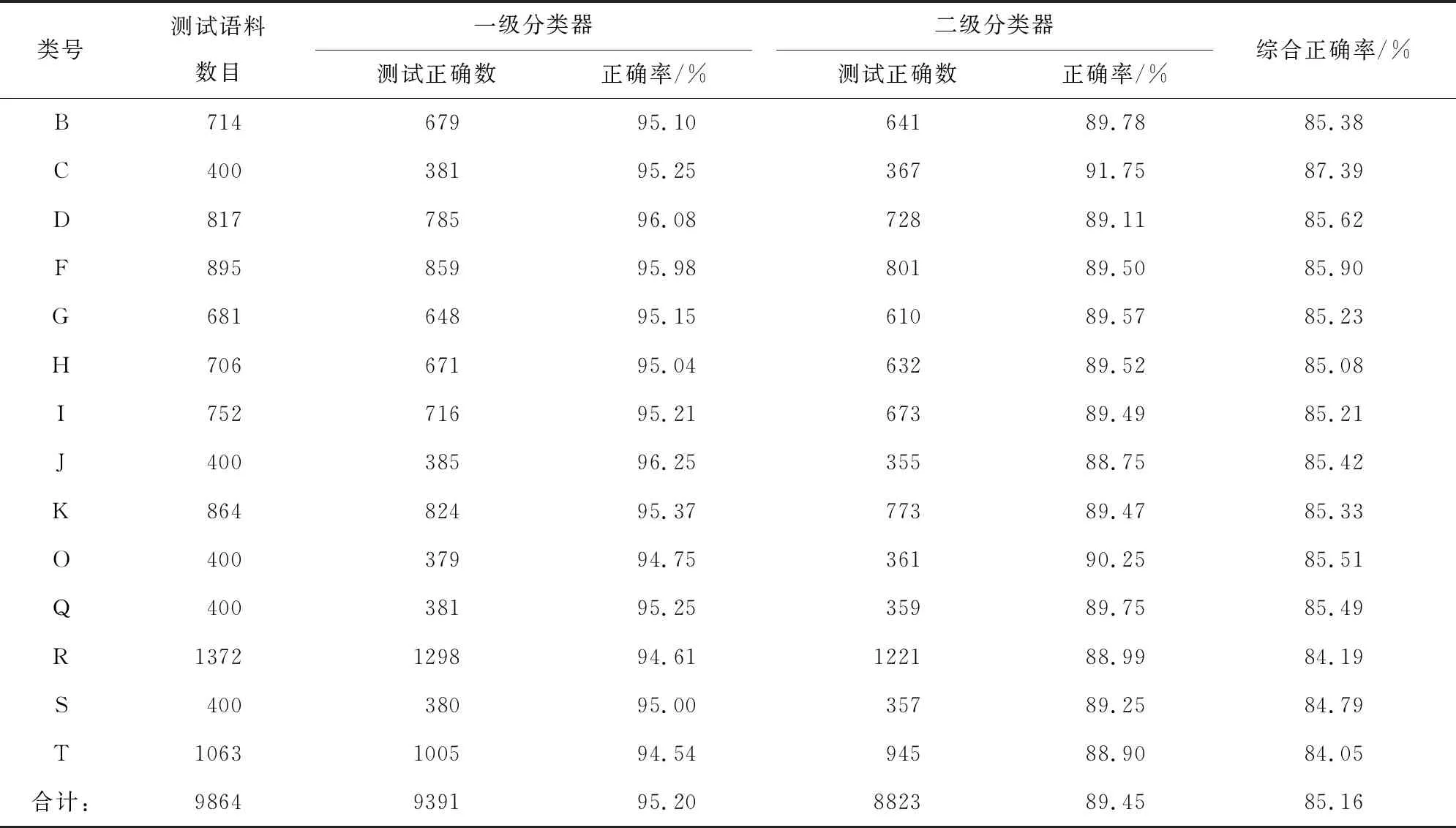
表2 基于混合特征的SVM分类器语料测试实验结果
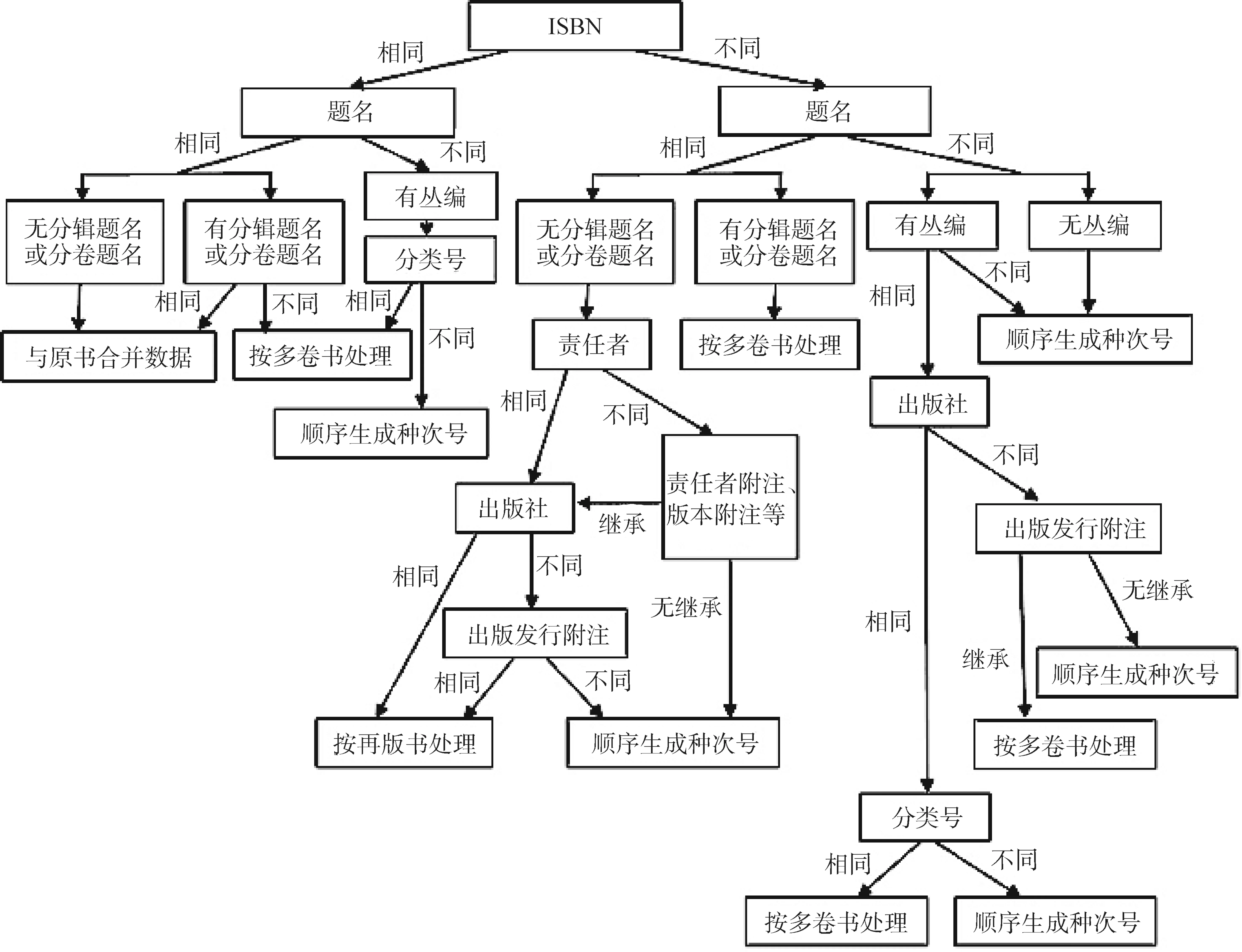
图4 我馆种次号生成规则
4 数据审核和实物验收
系统支持批量智能数据审核。编目外包必须对书商提供的数据和系统进行批量采访和对编目生成的数据进行审核,才能在提高效率的同时保障编目的质量,所以编目人员要对编目数据进行分类差别化审核处理。对一级编目数据或分类校正一致的编目数据实行5%的随机抽查,对二级编目数据或分类校正不一致的一级编目数据实行50%的随机重点审核,对三级编目数据实行全面审核(3种类型的抽查比例可根据本馆的具体运营情况进行调整)。审核人员首先对图书MARC数据的内容、详尽程度和是否符合文献著录标准与规范等进行校对,可与图书的实物、清单进行核查,然后重点审核分类号和种次号是否按照本馆的编目细则进行选取、是否符合规定标准等,不合格的由审核人员进行手工处理。审核完成后打印审核验收单和书标,交给书商进行统一加工,包括盖馆藏章、加印财产号、贴书标和贴磁条或RFID标签等[20]。加工完成后交给编目部门,对财产号、条码、书标是否清晰、端正,磁条的磁性等进行实物验收。系统支持对书商编目业务外包质量进行评价,为下次图书采购招标提供依据[21-22]。图书经过编目、实物验收后,统一送典藏、上架,就可以正常流通了。
5 结语
本文介绍了我馆编目外包以来的运行情况,指出了编目质量难以保障的相关问题,分析了机器学习技术在图书智能分类的应用情况,提出了基于图书的题名、摘要的词频与TFIDF的混合特征构建向量空间模型,利用支持向量机算法实现图书的智能分类,最终构建图书批量采访、套录、智能分类、智能生成种次号和本馆编目人员统一审核的采编模式。经过测试发现图书智能分类综合正确率达到85%以上,符合日常工作的需求,但发现TFIDF特征在分析交叉学科图书分类时效果相对较差。下一步将继续研究基于混合特征的多种机器学习算法分级组合应用,各种算法取长补短,争取达到最佳的图书分类效果,真正解决编目外包质量问题,提高工作效率。
猜你喜欢
都市人(2022年3期)2022-04-27 00:44:57
天一阁文丛(2020年0期)2020-11-05 08:28:36
戏曲研究(2017年3期)2018-01-23 02:51:01
华中学术(2017年1期)2018-01-03 07:25:13
小学阅读指南·高年级版(2017年3期)2017-03-23 12:54:37
山东青年(2016年1期)2016-02-28 14:25:20
河南科技(2014年22期)2014-02-27 14:18:37
中国民间疗法(2012年1期)2012-07-27 09:31:30
全国新书目(2009年8期)2009-05-22 11:31:16
全国新书目(2009年1期)2009-04-13 06:58:24
