
基于SAHDE-RVM的铁路短期风速预测研究
2018-05-31 11:49:28杨溪源李彦哲
铁道标准设计 2018年6期
杨溪源,李彦哲
(兰州交通大学自动化与电气工程学院, 兰州 730070)
近年来,我国铁路事业迅猛发展,随着列车运行速度的不断提高,铁路运营安全成为人们关注的热点。铁路运营安全主要包括:列车车体安全、信号与通信系统安全、调度指挥安全等[1-2]。其中,脱轨作为列车车体安全考虑因素之一,容易受大风等自然灾害的影响[3-4]。在大风环境及风口区域的高路堤、丘陵等特殊路段中,由于列车气动性能恶化,导致列车稳定性受到严重影响,大大增加列车脱轨的可能性[5],因此,对铁路风速预测研究,显得尤为重要。
国外,文献[6-7]提出在铁路沿线建立挡风墙、列车外形优化等的方法,一定程度上解决了大风对高速列车运行的影响,但是有一定的局限性;文献[8]根据列车运行沿线历史风速数据以实现外推估计的风速预测研究,该方法简单、实时性好,但预测精度不高;国内,文献[9-11]针对铁路沿线风速短期预测,学者分别利用时间序列分析理论和神经网络等方法进行预测研究,很好的提高了风速预测精度,但存在神经网络初始权值和选择训练数据样本不易确定等缺陷,基于此,支持向量机法等机器学习型算法应运而生,以结构风险最小化为目标的SVM预测模型较神经网络模型具有较高的精度,这在一定程度上克服了神经网络在铁路短期风速预测中的劣势[12],但是SVM模型仍存在核函数选择条件苛刻需遵循Mercer条件,核函数较多且其值的选取对SVM模型的预测精度有着较大的影响。在此,本文根据新型计算机算法相关向量机核函数选择灵活无需遵循Mercer条件,核参数的设置数目少的特点,利用差分进化算法在参数优化方面的优势,采用交叉算子可自适应调整的自适应差分进化算法,并混合了模拟退火算法对最优参数进行二次优化,提出了基于自适应混合差分进化相关向量机(Self-Adaptive Hybrid Differential Evolution-Relevance Vector Machine, SAHDE-RVM)的铁路短期风速预测模型,通过实例对预测模型进行验证,并与现有模型的预测结果进行对比分析。
1 相关向量机原理
相关向量机(Relevance Vector Machine, RVM)是一种基于贝叶斯框架的算法[13]。与传统的SVM相比,RVM具有高稀疏性,仅有核参数的设置,核函数的选择灵活,无需满足Mercer条件等优点,在回归预测方面有着良好的应用价值。
本文使用RVM进行回归预测,建立RVM回归预测模型。给定训练样本的输入集X={x1,x2,x3,…,xn,}与相应的输出集T={t1,t2,t3,…,tn},其中n为样本个数,设ti为目标值且有ti∈R。输出值ti的函数模型可表示为
ti=y(xi,w)+εi
(1)
式中,εi表示高斯白色噪声,且εi服从分布εi~N(0,σ2),则p(ti|xi)=N(ti|y(xi,w),σ2)。RVM模型的输出可表示为非线核函数的组合,核函数无需满足mercer条件。RVM的回归预测模型为
(2)
式中,wi为加权系数;K(x,xi)为核函数;N为样本数量。
对于独立分布的输出集ti的似然估计为
(3)
式中,Φ=(Φ1,Φ2,…,ΦN);Φi=(1,K(xi,x1),…;K(xi,xn))T(i=1,…,N)。
由稀疏贝叶斯原理定义的权值参数为零的高斯先验分布为
(4)
式中,αi为先验高斯分布的超参数;α=(α0,…,αN)T。每个独立的超参数αi控制着权参数wi的先验分布,使相关向量机模型具有稀疏性。
由式(3)、式(4)根据贝叶斯原理计算权值矢量w的后验分布
N(w|μ,∑)
(5)
式中,μ=σ-2∑φTt,∑=(A+σ-2φTφ)-1,A=diag(α0,α1,…,αN)。
由式(5)可知,若要确定权值矢量w需对超参数α、σ2进行确定。用贝叶斯框架计算超参数的似然分布
(6)
式中,C为协方差且C=σ2I+ΦA-1ΦT。
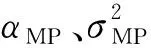
(7)

(8)
式中,uj是第j个后验平均权值;γj=1-αjMjj(γj∈[0,1]);Mjj为权值协方差矩阵Σ的对角线元素。
RVM学习过程中,首先初始化式(7)、式(8)中的两个参数,并通过更新迭代公式不断更新计算两个超参数,当模型中的参数均达到最大训练次数时,更新计算停止,此时得到的α与σ2为最优值。若给定系统一个输入值X*,则输出的概率分布为
N(t)(t*|y*,σ2)
(9)
y*=uTΦ(X*)=uMPΦ(X*)
(10)

(11)

2 自适应混合差分进化算法
2.1 差分进化算法
Storn R和Price K于1995年提出了差分进化算法(Differential Evolution,DE),DE是一种使用实数矢量编码的群体智能化的优化算法,其原理类似于遗传算法。DE具有强大的易用性、鲁棒性和全局搜索能力,已有大量的文献证明DE算法的优越性高于遗传算法、蚁群算法等智能算法[14]。DE通过对群体中的个体分别进行变异、交叉、选择等操作获取最优个体,从而得到最优值。但DE算法仍然具有易早熟,较难搜索到全局最优解等缺陷,鉴于此,本文采用一种自适应混合差分进化算法(Self-Adaptive Hybrid Differential Evolution,SAHDE)[15-17],该模型可自适应调整DE的交叉概率算子CR,在算法的初期保持种群的多样性的同时提高其全局搜索能力,并引入了模拟退火算法,该算法具有较强的搜索能力可对获取的最优解进行二次搜索,SAHDE算法可解决DE算法早熟收敛,优化算法的全局所搜能力。差分进化算法的操作步骤如下。
(1)变异操作:DE算法由多种变异操作方法,本文选用如下方法进行变异操作。
xm=xbest+F[(x1-x2)+(x3-x4)]
(12)
随机挑选出4个父代个体,分别记为x1,x2,x3,x4;xbest是父代中的最优个体;xm为变异产生的变异个体;F为变异率(F∈[0,1.2])。
(2)交叉操作:选取两个个体xi和xm进行交叉操作,交叉操作后生成的新个体为xc,具体的操作方法如下式
j=1,2,…,D
(13)
其中,rand()表示[0,1]之间的随机函数,randr(i)∈{1,2,…,D}为随机产生的整数;D为优化变量的维数;CR为交叉率(CR∈(0,1))。
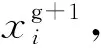
(14)

2.2 交叉算子的自适应调整
(15)
CR0为交叉算子CR的初值,CR的值根据上式自适应调整,初始值CR0较小,而后其取值逐步增大,此时算法具备一个优秀搜索算法所具备的能力,与传统DE相比具有更好的性能。
2.3 模拟退火算法的引入
DE种群的多样性会导致其早熟收敛。为了进一步提高算法的搜索效率,本文使用模拟退火算法对SAHDE产生的当前最优个体进行二次搜索。在SAHDE当中,选定当前最优个体为初始个体,既y0=xbest初始温度选定为T0,产生新个体的方式如下所示
yr+1,j=yr,j+ηε(xjmax-xjmin)
j=1,2,…,D
(16)
式中,r为模拟退火算法的迭代次数;yr为r次迭代后产生的新个体;η为控制扰动幅度;ε为服从均值或正态分布的随机变量;xjmax、xjmin分别为第j维优化变量的取值范围。
SAHDE产生的最优个体再经过模拟退火算法二次搜索后,适应度变化为ΔF,ΔF=f(yr+1)-f(yr)。若ΔF<0则接受新个体并用新个体替换原来的最优个体;若e(-ΔF/T)>rand(),此时也接受新产生的个体,并用其替换种群中的一个非最优个体;否则拒绝。若选择了接受新的个体,按Tr+1=aTr(0 为了加快样本的训练速度并提高模型的预测精度,本文使用均值化的方法对风速实测样本数据进行预处理 (17) 核函数是RVM技术的核心,核函数的使用有效地解决了数据空间、特征空间、类别空间之间的非线性变换。传统的RVM选取的单一核函数具有其自身的局限性,本文采用混合核函数,将不同的核函数进行组合,取长补短,发挥各自的优势,组合后的核函数具有优秀的性能。 通过参考文献[18]对不同核函数性能的对比研究,本文选用高斯核函数与二项式核函数组合得到的组合核函数作为RVM模型的核函数。组合后的核函数如下 K(xi,xj)=λG(xi,xj)+(1-λ)P(xi,xj) (18) 通过对样本数据集的训练,自适应获取模型的最优参数α、σ2。 RVM模型核参数的选取对模型回归预测的结果起关键作用,为减小人为参数设置不当而引起的较大预测偏差,本文SAHDE的适应度函数以文献[19]的留一交叉验证法得到,进而RVM模型的参数可自适应获取。基于此,提出SAHDE-RVM模型,RVM参数可自适应获取最优值,从而减小了人为参数设置不当而产生的预测误差。具体步骤如下。 (1)为选取RVM的最优参数,首先以差分进化算法的个体维数等于需要确定的RVM参数的个数进行实数编码。 (2)对SAHDE参数初始化,种群规模设置为100且采用实数编码,变异率F=0.35,初始交叉率CR0=0.4,最大进化代数gmax=1 800;以群体特征信心确定模拟退火算法的初温,模拟退火算法的迭代次数为100,即第100次迭代后最优个体保持不变则停止操作。 (3)用适应度函数来评价种群中的个体,判断其是否达到最优,以此选取此步骤所确定的最优个体。 (4)上一步骤得到最优个体之后,采用模拟退火算法对已确定的最优个体进行二次搜索。 (5)根据公式(15)计算当代交叉率CR后更新SA参数。 (6)判断是否满足终止条件,既达到最大进化数量,若满足条件,此时确定了RVM的最优参数,以此参数建立RVM回归预测模型;若未达到终止条件,返回步骤(3)继续执行直至满足条件为止。 模型预测流程如图1所示。 图1 SAHDE-RVM模型预测流程 合理的误差分析能对所使用的方法进行恰当的评判。本文选取均方根误差RMSE和平均相对误差MAPE作为模型误差的评价指标,其表达式如下 (19) (20) 本文采用我国海南东环铁路及青藏铁路某监控点2012年11月2日至2012年11月29日之间的实测风速数据,设置原始数据的采样间隔均为15 min,经数据预处理后分别得到各1 300组数据,利用前1000组数据作为训练样本,后300组数据进行测试。将相同的数据样本分别利用本文所提出的SAHDE-RVM模型、最小二乘支持向量机(Least Squares-Support Vector Machine, LS-SVM)模型和传统DE参数寻优的RVM模型进行预测,并对比分析。其中,LS-SVM模型采用文献[20]所提出的EEMD-LSSVM模型,首先对实测的风速序列进行总体经验模态分解,由风速的不同趋势将风速序列分解为各个子序列,对每个子序列分别建立LSSVM模型,最终叠加各个子序列的预测结果,其参数优化方法采用自适应扰动粒子群算法进行优化,选取其最优值。RVM模型的参数采用传统的DE进行参数寻优。SAHDE-RVM的参数采用本文所提出的自适应混合差分进化算法(SAHDE)寻优得到其最优值。海南东环铁路记为A段,提前15 min及30 min短期风速预测结果如图2所示;青藏铁路记为B段提前15 min及30 min短期风速预测结果如图3所示。 图2 A段铁路短期风速预测 图3 B段铁路短期风速预测 由图2、图3可知,在风速预测模型中,数据相同的情况下,SAHDE-RVM模型、LS-SVM模型和传统的RVM模型对风速进行预测都具有一定的精度,A段不同方法在测试集上提前15、30 min预测的结果如表1所示。 表1 A段铁路不同方法的预测性能 B段不同方法在测试集上提前15、30 min预测的结果如表2所示。 表2 B段不同方法的预测性能 由表1、表2可以看出,一方面本文所提出的SAHDE-RVM模型预测结果与真实数据较为接近,A段、B段铁路提前15 min均方根误差RMSE仅有1.218 6%和1.318 2%,同时两段铁路的平均相对误差MAPE均高于铁路现场精度15%的要求;另一方面在给定样本条件下,SAHDE-RVM模型预测结果的平均相对误差MAPE较LS-SVM模型明显减小,且小于传统DE参数寻优的RVM回归预测模型,同样地,SAHDE-RVM模型的均方根误差eRMSE值小于LS-SVM、RVM。由此可见,本文所提出的使用SAHDE进行RVM参数寻优的SAHDE-RVM预测模型有一定的正确性,且较传统模型精度有了较大提升,具有较高的回归预测精度。 (1)针对铁路沿线短期风速预测,本文提出采用一种基于自适应混合差分进化相关向量机模型对铁路沿线短期风速进行预测,以国内两段铁路沿线实测风速数据为依据,将本文方法预测结果与实际风速数据对比分析得出,SAHDE-RVM模型的预测结果与实际数据之间具有良好的相似性,从而验证了本文所构建SAHDE-RVM风速预测模型的准确性。 (2)以同一实测风速数据为样本,分别采用SAHDE-RVM、LS-SVM、DE-RVM进行预测,对比得出:SAHDE-RVM模型既克服了传统神经网络预测法泛化能力差训练时间长且易陷入局部最小值的缺点,又解决了支持向量机核函数选取不灵活,需要遵循Mercer条件的缺陷,降低了传统方法由于核函数参数设置不当而引起的模型精度误差,具有较高的精度,有良好的工程应用价值。 [1] Grnbak J, Madsen T K, Schwefel H P. Safe wireless communication solution for Driver Machine Interface for train control systems[J]. 3rd International Conference on Systems, 2008:208-213. [2] Blakstad H C, Hovden Jan, Rosness R. Reverse invention: An inductive bottom-up strategy for safety rule development A case study of safety rule modifications in the Norwegian railway system[J]. Safety Science, 2010,48(3):382-394. [3] 田红旗.中国列车空气动力学研究进展[J].交通运输工程学报,2006,6(1):1-9. [4] Liu Hui, Tian Hongqi, Li Yanfei. Short-term forecasting optimization algorithms for wind speed along Qinghai-Tibet Railway based on different intelligent modeling theories[J]. Journal of Central South University of Technology(English Edition), 2009,16(4):690-696. [5] 刘辉.铁路沿线风信号智能预测算法研究[D].长沙:中南大学,2011:1-12. [6] Chu C R, Chang C Y, Huang C J, et al. Windbreak Protection for Road Vehicles Against Crosswind[J]. Journal of Wind Engineering and Industrial Aerodynamic, 2013,116(5):61-69. [7] Simonovic A, Svorcan J, Stupar S. Aerodynamic Characteristics of High Speed Train under Turbulent Cross Wind: A Numerical Investigation Using Unsteady-RANS Method[J]. FME Transactions, 2014,42(1):10-18. [8] Hppmann U, Koenig S, Tielkes T, et al. A short-term strong wind prediction model for railway application: design and verification[J]. Journal of Wind Engineering and Industrial Aerodynamics, 2002,90(10):1127-1134. [9] 潘迪夫,刘辉,李燕飞,等.青藏铁路格拉段沿线风速短时预测方法[J].中国铁道科学,2009,29(5):129-133. [10] 刘辉,潘迪夫,李燕飞.基于列车运行安全的青藏铁路大风预测优化模型与算法[J].武汉理工大学学报(交通科学与工程版),2008,32(6):986-989. [11] 刘辉,田红旗,等基于小波分析法与神经网络法的非平稳风速号短期预测优化算法[J].中南大学学报(自然科学版),2011,42(9):2704-2711. [12] 刘苏苏,孙立民.支持向量机与RBF神经网络回归性能比较研究[J].计算机工程与设计,2011,32(12):4202-4205. [13] 马开良.基于相关向量机的复合模型在风速预测中的研究及应用[D].兰州:兰州大学,2014:10-14. [14] Price K, Storn R, Lampinen J. Differential evolution: A practical approach to global optimization[M]. Berlin Heidelberg:Springer, 2005:1-29. [15] 胡玉纯.自适应差分进化算法在PMSM电机控制器中的应用[D].郑州:郑州大学,2014,23-38. [16] 沈佳杰,江红,王肃.基于自适应缩放比例因子的差分进化算法[J].计算机工程与设计,2014,35(1):261-266. [17] 燕飞,秦世引.一种基于模拟退火的支持向量机超参数优化算法[J].航天控制,2008,26(5):7-11. [18] 楼俊钢,蒋云良,申情,等.软件可靠性预测中不同核函数的预测能力评估[J].计算机学报,2013,36(6):1303-1311. [19] 刘学艺,李平,郜传厚.极限学习机的快速留一交叉验证算法[J].上海交通大学学报,2011,45(8):1140-1146. [20] 王贺,胡志坚,张翌晖,等.基于聚类经验模态分解和最小二乘支持向量机的短期风速组合预测[J].电工技术学报,2014,29(4):237-245.3 自适应混合差分进化相关向量机模型的构造
3.1 样本数据的预处理

3.2 RVM模型核函数的选取
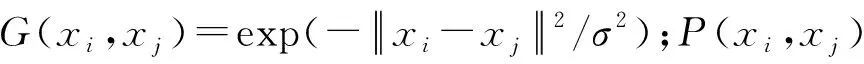
3.3 自适应混合差分进化相关向量机模型流程

3.4 模型精度评价指标


4 算例分析




5 结论
猜你喜欢
新世纪智能(数学备考)(2021年5期)2021-07-28 06:19:46
电机与控制应用(2021年12期)2021-02-28 07:55:52
海洋通报(2020年5期)2021-01-14 09:26:54
测控技术(2018年3期)2018-11-25 09:45:08
西南交通大学学报(2016年4期)2016-06-15 20:29:37
电测与仪表(2016年17期)2016-04-11 12:38:44
电源技术(2015年5期)2015-08-22 11:18:24
信息安全研究(2015年3期)2015-02-28 20:17:57
电网与清洁能源(2015年3期)2015-02-28 16:03:31
城市轨道交通研究(2015年3期)2015-02-27 11:01:36
