
一种支持数据去冗和扩容的多媒体文件云存储系统实现
2018-05-28 03:46:01吕江花汪溁鹤吴继芳马世龙
计算机研究与发展 2018年5期
汪 帅 吕江花 汪溁鹤 吴继芳 马世龙
1(中国空间技术研究院 北京 100086) 2(北京航空航天大学计算机学院 北京 100191) (buaashuai@buaa.edu.cn)
互联网的高速发展产生了海量数据,导致海量数据的传输和存储场景日益增多,在这种背景下数据存储技术得到了快速发展[1-3].过去10多年在多个应用领域产生的多媒体文件数量增长非常迅速,多媒体文件在互联网信息中占有很大比重,所以海量多媒体文件存储技术是一个重要研究课题[4-5],分布式文件系统成为了当今的研究热点.目前,在分布式文件系统中存储海量多媒体文件时,还普遍存在着存储性能不高、存储空间利用率低、性能瓶颈及单点故障等问题,因此,如何解决海量多媒体文件在存储和传输过程中存在的诸多实际问题,是当前计算机存储技术研究领域非常重要的工作[6].
随着云计算技术的广泛应用,越来越多的应用程序为用户提供图片、视频、音频等多媒体文件的存储和查询服务,这类型文件通常具有存储周期长、转载复制频繁、文件内容不宜分割等特点[7],运用分布式存储虽然可以提高多媒体文件的访问效率,避免网络传输瓶颈对多媒体文件造成的访问延迟和磁盘存储空间瓶颈对多媒体文件存储造成的吞吐性能下降.但是,很多应用程序向用户提供的多媒体文件上传入口会使云存储平台积累大量重复的多媒体文件,这样既给应用程序开发商增加了存储成本,也降低了多媒体文件的访问效率[8].因此,为了满足这类应用程序对多媒体文件存储和管理的需求,对多媒体文件进行分布式存储、删除重复的多媒体文件、保护用户隐私、支持对存储目录动态逻辑扩容,对于提高系统性能、降低存储成本、提升用户体验具有重要意义.
本文提出一种分布式存储目录动态建模方案,用来描述整个数据中心的存储目录逻辑结构,应用程序基于此模型可以方便地管理用户上传的多媒体文件,简化存储文件和获取文件的过程.基于此建模方案实现的多媒体文件云存储系统,支持对指定存储目录中的多媒体文件进行数据去冗,并且该系统可以在运行过程中对存储目录进行动态逻辑扩容.应用程序可以自定义存储目录树的逻辑结构,应用程序通过该云存储系统保存文件时,不必担心某个存储目录的磁盘占用空间已达到存储上限的问题,该云存储系统解决了数据冗余度高的应用程序在低存储成本条件下对多媒体文件进行分布式存储的问题.
1 相关工作
云计算的发展使越来越多的信息被数据化,大量数据密集型的应用程序每天产生的体积较小的多媒体文件呈几何级增长[9].Facebook这类大型社交软件每周产生的图片数据高达60TB[10],淘宝网的图片存储量已经达到2PB[11],如何对海量多媒体小文件进行有效的存储与管理,减轻应用程序的负担,已是存储领域必须要面对的一个重要课题.
Ross等人[12]提出的PVFS(parallel virtual file system)是一个高性能、可扩展的分布式并行文件系统,PVFS将文件分散到多个存储结点的多块磁盘上,实现了对文件的条带化存储,消除了单个存储结点引发的瓶颈问题,但是它缺乏必要的容错机制并且配置不够灵活,适用于对文本文件进行并行访问和分析.Lustre文件系统[13]是基于对象存储的大规模分布式文件系统,它把数据划分成条带存储在多个对象存储服务器(object storage server, OSS)上,当某个OSS发生故障时仍能保证存储在该服务器上的数据不丢失.它是基于Linux内核级的分布式文件系统,多数用于高性能计算中.Lustre文件系统不支持数据去冗,同时数据的条带化导致它在小文件存取时表现较差,每次读取小文件都需要从多个存储服务器结点上获取文件的每个数据块,然后把这些数据块拼接成一个完整的小文件返回给应用程序.
Google文件系统(Google file system, GFS)[14]是一个支持数据密集型应用的、高度容错且具有高吞吐量的分布式文件系统,GFS支持多个客户端并行的对同一个文件进行内容追加操作,同时它能够保证每个客户端在在给同一个文件内容进行追加操作时的原子性,GFS会把文件切分成相同大小的数据块存储在不同的数据结点.对于多媒体文件来说,如果把它的内容切分成不同的数据块分布式存储,那么在访问这些多媒体文件内容时,就需要从多个数据结点把数据块全部取到然后返回给应用程序,这样会额外消耗很多资源,而且GFS不支持通过HTTP协议访问多媒体文件.基于GFS的设计思想,Konstantin等人[15]实现了开源的HDFS(Hadoop distributed file system),HDFS也不支持通过HTTP协议访问多媒体文件,HDFS的命名空间结点把系统中所有的元数据都放置在内存中,如果系统中存在海量的体积比较小的多媒体文件,会降低整个存储系统的存储效率和存储能力.
淘宝文件系统(Taobao file system, TFS)[16]是一个构建在普通的Linux机器集群上的、对外提供高可靠和高并发访问的分布式文件系统.TFS为阿里巴巴提供海量小文件存储,满足了阿里巴巴对小文件存储的需求,被广泛地应用在阿里巴巴各项应用中.TFS采用扁平化的数据组织结构,一方面它把多个小文件压缩在一个数据块中进行存储,另一方面它把文件名映射到文件的物理地址,简化了文件的访问流程,一定程度上为TFS提供了良好的读写性能.当TFS客户端需要读取文件内容时,它将文件名转换为文件块号和文件号,然后在命名空间结点上取得文件块号所对应的数据结点信息,之后客户端通过数据结点获取数据块内容,然后根据文件号找到文件的具体内容.TFS不支持数据去冗,它把图片编号作为元数据存储在外部数据库中,TFS对数据库比较依赖而且要求数据库具有很高的性能,每次获取图片信息时都要进行读取数据库操作,然后去确定图片的存储位置.
表1直观地显示了上述4个文件系统之间的差异和不足:

Table 1 Different Feature of File Systems表1 文件系统对比
① Large: File size greater than 10 MB.
② Small: File size less than 10 MB.
在具备扩展性的高性能文件系统研究方面,OceanStore[17]和Farsite[18]可以提供TB级别的高可靠文件存储,同时支持几千个客户端并发访问文件内容,但是它们由于命名空间结点的瓶颈,不能支持客户端高并发访问小文件.Ceph[19]是一个扩展性较强的高性能分布式文件系统,Ceph文件系统为异构的并且拥有不可靠对象存储设备的动态集群设计了伪随机数据分发函数,通过替换分配表来最大化分离数据和元数据管理之间的耦合关系,但是它在安全性和POSIX调用[20]方面还有待进一步完善.Chung等人[21]提出的分布式文件系统虽然可以降低存储成本并且拥有不错的性能,但它在扩展性方面表现较差.Hao等人[22]提出的链接分布式文件系统支持对文件进行多版本管理,但扩展性和实用性较差.Xiong等人[23]、Cao等人[24]和Chao等人[25]在实用性方面各自研究了分布式存储策略,但他们的研究方向偏向于文件副本策略.在小文件管理方面,Dong等人[26-27]、Chandrasekar等人[28]和Chatuporn等人[29]在HDFS的基础上优化了小文件的存储策略,一定程度上提高了HDFS在小文件存储和访问方面的性能,但他们对多媒体文件去冗方面研究较少.
在多媒体文件数据去冗领域,根据去冗粒度的不同,去冗方式可以分为字节级的去冗、数据块级的去冗和文件级的去冗,不同的去冗方式各有利弊.1)对于字节级去冗,一般在字节层面查找和删除重复的数据,通常使用差异压缩策略生成差异部分内容,它的优点是去冗率很高,缺点是去冗的速度比较慢,不适合对数据实时去冗.2)数据块级的去冗方式将文件按一定的策略划分成多个数据块,把数据块视为去冗的基本单位,它的优势是计算速度较快,去重效率也较高,但对数据变化比较敏感.3)文件级的去冗方式把整个文件当作检测和去冗的基本单位,首先计算整个文件的指纹,然后根据文件指纹在存储系统中查找是否存在具有相同指纹信息的文件,这种去冗方式的去冗速度非常快,缺点是即使2个文件中存在很多相同数据,也无法删除文件内的重复数据[30].
主流的开源分布式文件系统大多针对大文件读写而专门设计,企业级的多媒体文件管理系统因商业利益无法公开.本文重点研究数据冗余度高的应用程序如何对多媒体文件进行分布式存储的问题,与主流的分布式文件系统相比,本文实现的MFCSS(multimedia file cloud storage system)系统能够运行在Windows或Linux下,不依赖数据库,支持对多媒体文件进行数据去冗,支持对存储目录进行运行时动态逻辑扩容.
2 分布式存储目录建模方法及MFCSS系统
数据中心是一整套复杂的设施,它不仅包括计算机系统和其它与之配套的设备,还包含冗余的数据通信连接、环境控制设备、监控设备以及各种安全装置[31].一个数据中心通常会包含多台存储服务器,存储服务器自身会存在一些受保护的应用程序数据文件和存储目录,为了隔离不同应用程序的存储区域,防止应用程序上传的文件对存储服务器自身的重要文件造成破坏,存储服务器需要指定一些存储目录供应用程序存储文件.
图1描述了一个数据中心的分布式存储目录结构图,它由多棵存储目录树构成,不同的应用程序在保存用户文件时通常具有不同的存储目录树逻辑结构,存储目录树中结点的层次关系取决于应用程序,本节将给出分布式存储目录建模方案中各结点的详细定义.

Fig. 1 Distributed directory tree structure图1 分布式存储目录结构图
定义1. 存储目录结点(directory node,DN).用来描述存储服务器上的存储目录信息,它定义为(id,naming,storePath,(parent,ChildNodes)),其中:
1)id表示DN的编号,编号具有唯一性.
2)naming表示DN的命名规则.它定义为三元组(nameType,staticName,dynamicName),其中:
①nameType∈{static,dynamic}表示DN的命名方式,static表示DN采用静态命名方式,dynamic表示DN采用动态命名方式.
②staticName表示DN采用静态命名方式时候的文件名是staticName,例如:staticName=“Z1”,则该目录的文件名为“Z1”.
③dynamicName表示DN采用动态命名方式时,将应用程序运行时传递的dynamicName所对应的参数的值作为DN的文件名,例如:dynamic-Name=“userId”,且应用程序运行时传递的参数userId=“U10”,则该目录的文件名为“U10”.
3)storePath表示DN的初始设置结点的磁盘存储路径,初始设置结点AN(ancestor node)的定义参见下文.
4) (parent,ChildNodes)表示DN的直连结点的属性信息,其中:
①parent表示DN的直接父结点.
②ChildNodes={node1,node2…,nodem}(m≥0)表示DN直接子结点的集合,其中nodei(0≤i≤m)可以是DN,也可以是文件结点(file node,FN),FN的定义参见下文.
根据定义1,下面行文中定义静态目录结点SDN(static directory node),它是DN的特殊实例,其名称staticName在系统未运行时指定,为了防止同一个存储目录中出现2个具有相同文件名的存储目录,不同编号的SDN具有不同的目录名称;定义动态目录结点DDN(dynamic directory node),它也是DN的特殊实例,其编号在系统未运行时指定,但其名称取决于系统运行过程中应用程序传递的dynamicName所对应的参数的值,一个DDN在系统运行过程中会产生多个具有不同文件名的DN,这些DN具有相同的父目录;定义初始设置结点AN,它也是DN的特殊实例,它代表存储服务器结点在应用程序运行之初提供的用来存放文件的存储目录,AN必须是实际存在的存储目录,其中AN.parent是存储服务器结点,AN.storePath是该初始设置结点在磁盘上的绝对路径.
例1. 在图1所示的分布式存储目录结构图中,“图书”和“场景”分别是“电子书存储服务器”和“场景存储服务器”的初始设置结点,每个存储服务器可以具有多个初始设置结点,但是每个存储目录结点只能隶属于唯一的初始设置结点.
定义2. 存储服务器结点(server node,SN).用来描述数据中心内存储服务器的属性信息、访问信息和它所提供的初始设置结点信息,它定义为(id,property,access,AncestorNodes,url),其中:
1)id表示SN的编号,编号具有唯一性.
2)property定义为(ip,ftpPort,serverPort),表示SN的属性.
①ip表示SN的IP地址.
②ftpPort表示通过FTP协议访问SN的端口号.
③serverPort表示SN提供的外部TCP协议访问端口号.
3)access定义为(userName,password),表示SN的访问信息.
①userName表示访问SN的用户名.
②password表示访问SN的密码.
4)AncestorNodes={AN1,AN2…,ANn}(n≥1)表示SN提供的可以存储文件的初始设置结点集合.
5)url表示通过HTTP协议访问SN的地址.
定义3. 文件结点.FN用来描述文件的相关信息,它定义为(id,fileName,fileType,property),其中:
1)id表示FN的编号.
2)fileName表示文件名.
3)fileType表示文件类型.
4)property定义为(fingerprint,directory-NodeId),它表示文件的属性.其中:
①fingerprint表示文件的指纹信息,它在系统中可以是MD5,也可以是SHA-1等摘要算法.
②directoryNodeId表示FN的父存储目录结点的编号.
根据上文中对一些结点的定义,下面将给出存储目录子树、存储目录树和分布式存储目录的相关定义.
定义4. 存储目录子树(SubTree).用于描述某一个存储目录结点及其嵌套子结点之间的关系,以存储目录结点node为根结点的存储目录子树SubTree(node)定义为:
1) 如果node是文件结点,则SubTree(node)=node.
2) 如果node是存储目录结点,并且该存储目录结点没有直接子结点,即node.ChildNodes=∅,则SubTree(node)=node.
3) 如果node是存储目录结点,并且该存储目录结点具有直接子结点,假设:node.ChildNodes={node1,node2,…,nodem}(m≥1),则SubTree(node)是由以node为根结点的m棵子树{SubTree(node1),SubTree(node2),…,SubTree(nodem)}按从左到右顺序构成的树.
4) 用SubTree(node).id表示存储目录子树的编号,且SubTree(node).id=node.id.
定义5. 存储目录树(DirectoryTree).用于描述某一个存储服务器结点(SN)及其嵌套子结点之间的关系,设SN.AncestorNodes={AN1,AN2,…,ANn}(n≥1),则存储目录树DirectoryTree(SN)是由以SN为根结点和n棵存储目录子树SubTree(AN1),SubTree(AN2),…,SubTree(ANn)按从左到右顺序构成的树,用DirectoryTree.id表示存储目录树DirectoryTree的编号,且DirectoryTree.id=SN.id.
定义6. 数据中心.可以看作一个分布式存储目录(DistributeTrees),它由若干棵存储目录树构成,即DistributeTrees={DirectoryTree(SN1),DirectoryTree(SN2),…,DirectoryTree(SNk)}(k≥1).
通过以上定义,整个数据中心可以被建模形成一棵分布式存储目录,分布式存储目录中的存储目录结点都是逻辑结点,应用程序可以通过该建模方案定义每个逻辑结点之间的关系以及逻辑结点的相关属性,系统会在运行过程中根据应用程序传递的参数,把每个逻辑结点实例化为相应的物理存储结点,应用程序在保存文件时只需要指定逻辑结点的编号,系统会把文件保存到逻辑结点对应的物理存储结点中.
在分布式存储目录模型的基础上实现的多媒体文件云存储系统(MFCSS)解决了数据中心内多媒体文件的数据去冗问题,它可以给应用程序提供便捷的管理分布式存储目录的接口,简化应用程序管理分布式存储环境中多媒体文件的过程.整个系统的架构如图2所示,MFCSS系统向应用程序提供多媒体文件云存储服务,它由存储接口管理子系统(storage interface management subsystem, SIMSS)、集群管理子系统(cluster management sub-system, CMSS)和存储管理子系统(storage manage-ment subsystem, SMSS)构成,每个应用程序各集成一个存储接口管理子系统,存储接口管理子系统以JAR文件格式包的形式集成在应用程序中.
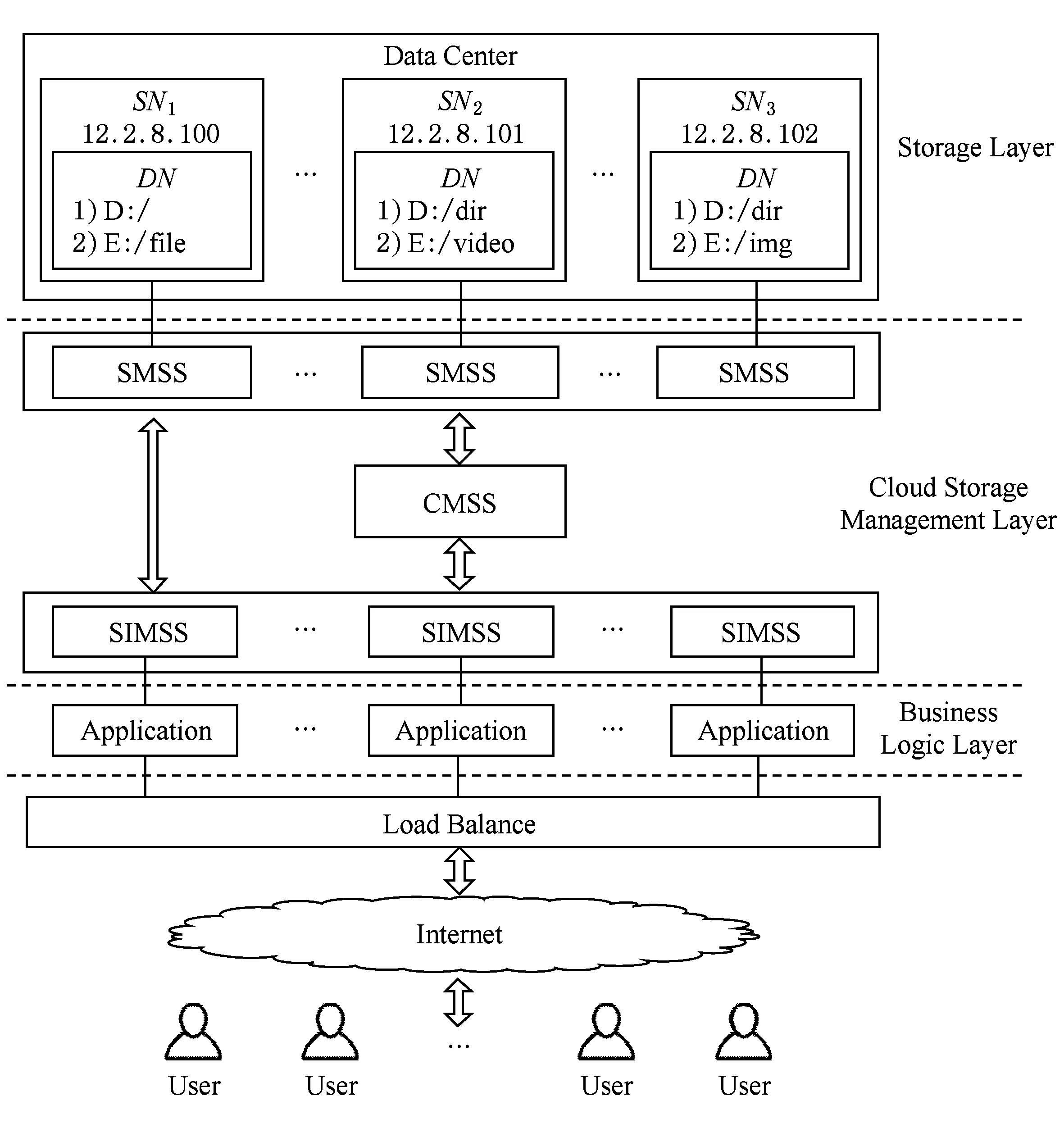
Fig. 2 System architecture of MFCSS图2 多媒体文件云存储系统架构
存储接口管理子系统给应用程序提供操作数据文件的接口,包括文件操作相关接口和目录操作相关接口等,同时负责生成操作指令与集群管理子系统和存储管理子系统进行通信.它还负责管理应用程序自定义的存储目录树,生成多媒体文件的存储路径和访问路径,当存储服务器的存储负荷达到一定阈值之后,存储接口管理子系统会向集群管理子系统发送指令,对相应的存储目录进行逻辑扩容.
数据中心的每台存储服务器上都会部署一个存储管理子系统,它负责管理其所在存储服务器上所有文件元数据、文件引用信息和扩容状态信息,并提供查询文件元数据、查询存储目录引用信息和查询存储目录扩容状态信息等服务.多个存储管理子系统在查找文件指纹信息所对应文件元数据时是并行执行的,它们将各自的查找结果通过通信指令传输给集群管理子系统,集群管理子系统汇总各个存储管理子系统发来的查找结果,并将结果返回给存储接口管理子系统做后续的业务处理.
当存储接口管理子系统在验证多媒体文件是否属于冗余文件时,通过集群管理子系统与不同的存储管理子系统通信,当存储接口管理子系统在保存多媒体文件时,它直接与存储管理子系统通信.
集群管理子系统部署在单独的服务器上,负责管理新接入的存储服务器,监控各台存储服务器的运行状态,提供对存储目录进行逻辑扩容的服务,同时还提供文件指纹信息匹配验证服务.集群管理子系统中实现了一个布隆过滤器[32]负责管理MFCSS系统保存的所有文件指纹信息,在接收到存储接口管理子系统发来的验证文件指纹信息指令之后,它通过布隆过滤器判断文件指纹信息的存在性,如果文件指纹信息不存在于布隆过滤器中,集群管理子系统判定用户上传文件不属于冗余文件,否则,就将查找该指纹信息所对应文件元数据的指令发送给各个存储管理子系统,进一步确定冗余文件的具体位置.每个存储管理子系统根据指纹信息迅速在内存中找出该指纹信息所对应的文件元数据,集群管理子系统汇总所有存储管理子系统发送给它的匹配结果,并把结果反馈给应用程序,由应用程序根据该反馈结果做后续的业务处理.
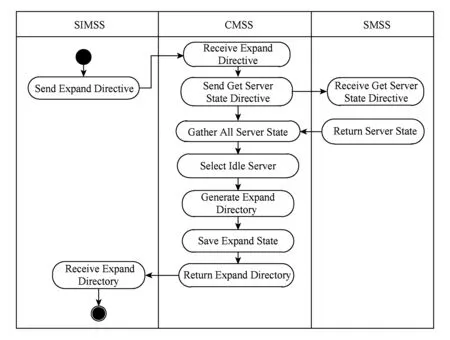
Fig. 3 The process of logical expansion图3 逻辑扩容流程图
数据中心的每台存储服务器都开启了FTP访问服务,供存储接口管理子系统操作文件和目录.应用程序在集成了存储接口管理子系统之后,可以自定义分布式存储目录模型,然后调用存储接口管理子系统提供的文件操作接口和目录操作接口就可以完成对多媒体文件的存储和查询过程,存储的过程中MFCSS系统会根据应用程序的需求对指定的存储目录或者整个存储服务器中的数据进行去冗,当某个存储服务器的磁盘空间利用率在超过一定的阈值之后,MFCSS系统会自动给该存储服务器中的存储目录进行逻辑扩容,应用程序在存储文件时不必担心存储目录会出现磁盘存储空间不足的情况.
MFCSS系统中的每个存储服务器都由部署在其上的Apache提供多媒体文件的Web访问服务,为了提高用户文件的存储安全性和访问安全性,避免用户文件被网络爬虫按照一定规则窃取,同时还要保证MFCSS系统保存的文件不被第三方应用程序访问.存储接口管理子系统会对用户上传的每个文件都生成一个时间戳并分配一个随机数存储于文件名中,它相当于每个多媒体文件的“私人秘钥”,该秘钥可以保证所有获取文件的请求都是经过MFCSS系统“批准”的,可以有效防止网络爬虫根据某些已知文件的访问路径通过暴力破解的方式非法获取到其他文件的访问路径.同时,应用程序在系统初始化时MFCSS系统会给它授权一个访问编号,在保存文件和访问文件时应用程序需要给MFCSS系统提供该编号,该编号相当于应用程序的“身份证”,可以有效防止第三方应用程序在知道了存储目录树结构的情况下非法窃取MFCSS系统中的用户文件.
3 存储目录逻辑扩容策略
为了提高系统的扩展性,保证文件系统服务的连续性,需要在系统运行过程中实时地给存储目录逻辑扩容.对于应用程序而言,它通过分布式存储目录模型可以定义存储目录的逻辑结构,在保存文件时应用程序只需要提供存储目录的逻辑结点编号以及相应的保存参数,MFCSS系统会维护逻辑结点到物理存储结点之间的映射关系.应用程序可以源源不断地把文件保存在某个存储目录逻辑结点中,不需要担心该结点对应的磁盘空间出现不足的问题,MFCSS系统在保存文件时如果发现某个磁盘的存储空间出现不足,会自动的给相应的存储目录逻辑扩容.
图3所示是MFCSS系统逻辑扩容的具体流程,主要步骤如下:
1) 存储接口管理子系统发送获取扩容存储目录指令给集群管理子系统;
2) 集群管理子系统收到获取扩容存储目录指令,发送获取服务器运行状态指令给所有的存储管理子系统;
3) 每个存储管理子系统收到获取服务器运行状态指令,将服务器运行状态返回给集群管理子系统;
4) 集群管理子系统汇总所有的存储服务器运行状态,确定空闲的存储服务器并生成扩容存储目录,然后保存扩容信息,并将扩容存储目录信息返回给存储接口管理子系统.
图4所示为一个具有扩容状态的分布式存储目录示意图,假设应用程序通过MFCSS系统向存储目录树DirectoryTree(SN2)中的静态目录结点F14添加一个文件结点fileNode1,则MFCSS系统进行2项判断:
1) 如果存储服务器结点SN2的磁盘存储空间利用率未超过其存储上限,那么fileNode1会被保存到结点F14中;
2) 如果存储服务器结点SN2的磁盘存储空间利用率超过了其存储上限,此时系统会为结点F14分配一个扩容结点并把fileNode1保存到该扩容结点中.

Fig. 4 Distributed directory tree structure with expand status图4 具有扩容状态的分布式存储目录示意图
任何一个存储服务器结点的磁盘存储空间利用率超过了其存储上限之后,MFCSS系统会给映射在其上的存储目录结点进行逻辑扩容,如果应用程序需要获取某个被扩容过的存储目录结点中的所有文件,MFCSS系统会自动把该存储目录结点对应的实际磁盘目录中的文件,还有存放在其扩容结点对应的实际磁盘目录中的文件一起返回给应用程序.该存储目录逻辑扩容机制使每个逻辑存储目录结点都能映射到多个实际磁盘存储目录,保证了文件系统服务的连续性,同时有效利用了存储服务器的磁盘空间.
4 数据去冗策略

Fig. 5 The process of deleting redundant files图5 数据去冗流程图
随着集群规模的扩大和存储多媒体文件的数量增加,为了降低整个云存储系统的运行成本,需要对系统中保存的多媒体文件进行数据去冗,节省磁盘占用空间.图5所示是多媒体文件云存储系统数据去冗的具体流程,整个去冗流程主要分为3个阶段:判定阶段、确认阶段和存储阶段.在判定阶段,应用程序将文件指纹信息发送给多媒体文件云存储系统,系统中的布隆过滤器快速判定该指纹信息是否存在,如果布隆过滤器中不存在该文件的指纹信息,系统就认为该文件不属于冗余文件,否则就进入确认阶段进一步确定文件的存在性.在确认阶段,系统通过通信指令告诉所有存储服务器上的客户端,使它们各自查找该指纹信息所对应的文件元数据,并将查找结果汇总反馈给应用程序,只要某个客户端找到了该指纹信息所对应的文件元数据,系统就认为该文件属于冗余文件.系统在以上2个阶段运行结束之后进入存储阶段,在该阶段系统保存相关的文件引用信息和文件指纹信息等核心数据.
具体的数据去冗步骤如下:
步骤1. 针对用户上传的多媒体文件,通过浏览器计算该多媒体文件的指纹信息并传输给应用程序.
用户在通过浏览器访问应用程序并上传文件时,应用程序提供的浏览器页面上的JavaScript脚本首先计算文件的指纹信息并将它发送给应用程序.
步骤2. 应用程序获取到该多媒体文件的指纹信息,调用存储接口管理子系统的接口生成验证文件指纹信息指令.
应用程序通过存储接口管理子系统向集群管理子系统发送验证文件指纹信息指令;应用程序在存储文件和访问文件时需要提供MFCSS系统授权给它的编号,只有经过MFCSS系统认证才能进行后续的文件操作和目录操作,存储接口管理子系统对用户上传的每个文件都生成一个时间戳并分配一个随机数存储在文件名中,这种设计可以在不影响MFCSS系统服务效率的同时保证用户数据的访问安全.
步骤3. 存储接口管理子系统把验证文件指纹信息指令发送给集群管理子系统.
步骤4. 集群管理子系统在收到验证文件指纹信息指令后,判断该多媒体文件的指纹信息是否存在,如果存在,进入步骤5;否则,生成文件指纹信息验证结果,进入步骤7.
如果集群管理子系统通过布隆过滤器判断得出该指纹信息已存在,则系统需要进一步找到该指纹信息所对应的文件元数据,在查找指纹信息所对应的文件元数据过程中,集群管理子系统给每个存储管理子系统发送查找文件元数据的指令,把存储管理子系统返回的查找结果汇总并发送给存储接口管理子系统,否则,生成文件指纹信息验证结果并发送给存储接口管理子系统.
集群管理子系统在找到与用户上传的多媒体文件具有相同指纹信息的文件后,会把文件元数据返回给应用程序,由应用程序根据文件元数据进行后续的业务处理,防止用户无法访问到该文件的情况发生;
步骤5. 集群管理子系统发送查找该指纹信息对应的文件元数据指令给所有的存储管理子系统.
在查找文件指纹信息所对应文件元数据的过程中,每个存储管理子系统的查找过程是并行的,有效提高了定位冗余文件的速度,提升了用户体验.
步骤6. 每个存储管理子系统收到查找文件元数据指令,在各自的内存中查找该多媒体文件指纹对应的文件元数据,并生成文件指纹信息验证结果返回给集群管理子系统.
步骤7. 集群管理子系统汇总文件指纹信息验证结果,并发送给存储接口管理子系统.
步骤8. 存储接口管理子系统获取文件指纹信息验证结果,根据结果判断MFCSS系统中是否存在相同文件,如果存在,进入步骤9;否则,进入步骤10.
步骤9. 向存储管理子系统发送添加文件引用信息指令和增加文件引用频率指令,并生成文件上传结果;然后进入步骤14.
存储接口管理子系统根据集群管理子系统发来的消息判断用户上传的文件是否属于冗余文件,如果MFCSS系统中的存储服务器SNi上已经存在一个文件filex和用户上传的文件具有相同的指纹信息,则应用程序把它分配的用来保存该多媒体文件的存储目录结点编号idx传递给存储接口管理子系统,然后存储接口管理子系统向idx所在的存储管理子系统发送添加文件引用信息的指令,收到该指令之后,存储管理子系统会保存idx和filex之间的映射关系;之后存储接口管理子系统向filex所在的存储管理子系统发送增加文件引用频率的指令,收到该指令之后,存储管理子系统会找到filex的元数据并对其引用频率加1.如果MFCSS系统中已经存在某个文件与用户上传的文件具有相同的指纹信息,则中断用户文件的上传过程并提示文件秒传成功,减少了用户上传文件需要消耗的平均时间,同时降低了存储服务器的存储负载和数据中心的存储成本;如果MFCSS系统内不存在某个文件与用户上传的文件具有相同的指纹信息,则存储接口管理子系统向应用程序请求文件的二进制流.
步骤10. 应用程序获取用户待上传的多媒体文件流,并传输文件流和应用程序指定的存储目录结点编号给存储接口管理子系统.
步骤11. 存储接口管理子系统生成存储目录结点编号对应的存储目录对象,并获取该存储目录的磁盘存储空间利用率,之后根据磁盘存储空间利用率判断该存储目录是否需要扩容,如果存储目录需要扩容,则存储接口管理子系统获取扩容存储目录,然后生成文件保存路径;否则,直接生成文件保存路径.
存储接口管理子系统根据应用程序指定的存储目录编号生成保存文件流的存储目录对象,之后存储接口管理子系统通过该存储目录编号所在存储管理子系统获取该存储目录的磁盘存储空间利用率,如果此时存储接口管理子系统发现该存储目录所在的存储服务器的磁盘空间利用率已经达到指定的阈值,则存储接口管理子系统根据图4描述的逻辑扩容流程,向集群管理子系统发送给该存储目录逻辑扩容的指令,然后获取到扩容的存储目录对象,之后存储接口管理子系统就会把文件流保存到扩容存储目录中.
步骤12. 存储接口管理子系统对用户待上传的多媒体文件类型进行识别,并判断文件类型是否合法,如果合法,则生成文件名,进入步骤13,否则,生成文件上传结果,进入步骤14.
存储接口管理子系统根据文件流识别用户上传多媒体文件的文件类型,如果文件类型合法,则存储接口管理子系统生成一个时间戳并分配一个随机数作为文件名;如果文件类型不合法,则生成相应的文件上传结果.
步骤13. 存储接口管理子系统保存文件,并向集群管理子系统发送添加文件指纹信息指令,同时向存储管理子系统发送添加文件元数据指令,并生成文件上传结果.
如果应用程序分配的保存该多媒体文件的存储目录idx不需要扩容,则存储接口管理子系统把用户上传的多媒体文件流保存到应用程序指定的存储目录idx中,否则,集群管理子系统会给存储目录idx分配一个扩容存储目录idy并记录相关扩容信息,然后存储接口管理子系统把用户上传的多媒体文件流保存到扩容后的存储目录idy中.文件流被保存之后,存储接口管理子系统向集群管理子系统发送添加文件指纹信息指令,集群管理子系统收到指令之后会把该文件的指纹信息添加到布隆过滤器中.如果idx没有被扩容,则存储接口管理子系统向idx所在的存储管理子系统发送添加文件元数据指令,否则,存储接口管理子系统向扩容存储目录idy所在的存储管理子系统发送添加文件元数据指令.存储管理子系统收到指令之后会保存该文件的元数据信息.
步骤14. 应用程序获取文件上传结果,并发送文件上传结果给用户.
步骤15. 用户查看文件上传结果,多媒体文件被保存到了MFCSS系统中.
为了快速地确定数据中心内是否存在某个文件与用户上传的文件具有相同的指纹信息,效率最高的方案是将所有的文件元数据都加载到服务器的内存中,每次查询时在内存中进行匹配,但是考虑到服务器内存大小的限制,以及MFCSS系统在运行的过程中文件数量会快速增长,所有的文件元数据很难全部加载到一台服务器的内存中.在MFCSS系统中,每个存储管理子系统都将它所管理的存储服务器上的全部文件元数据从磁盘预加载到内存中,并维护文件指纹信息和文件元数据之间的映射关系,这样整个数据中心内全部的文件元数据都分散存储于各台存储服务器的内存中,充分利用了每台服务器的内存空间,并且在匹配文件指纹信息的过程中多个存储管理子系统的匹配过程是并行执行的,有效的提高了冗余文件的定位速度,提升了用户存储文件的交互体验.
5 实验结果与分析
为了评估MFCSS系统的各项性能指标,对系统做了如下测试:写性能测试、系统响应时间测试、系统吞吐量测试、集群管理子系统和存储管理子系统内存使用情况测试以及磁盘占用空间测试.为了比较MFCSS与HDFS在保存具有不同冗余度的多媒体文件时性能的差异,在相同的测试环境下搭建了HDFS原型系统.集成了存储接口管理子系统的应用程序服务器具有4 GB内存,处理器是Intel®CoreTM2 Duo CPU P9400@2.40 GHz;部署集群管理子系统的服务器具有16 GB内存,处理器是Intel®CoreTMi7-4610M CPU@3.00 GHz,同时它还作为HDFS命名空间结点;2台部署存储管理子系统的服务器具有2 GB内存,处理器是Intel®CoreTM2 Duo CPU E7500@2.93 GHz,同时这2台服务器还作为HDFS数据结点.整个实验环境都在以太网交换机构建的局域网中,使用的交换机是传输速率为100 Mbps的TP-LINK TL-SF1008.
5.1 写性能测试
为了评估MFCSS系统在用户上传不同大小多媒体文件情况下系统的写性能,实验过程中使用了具有不同大小的17类多媒体文件,每类文件都由数据冗余度为0%,25%,40%,50%的样本构成,实验过程中对各类型的文件分别做了10次实验,分析写性能时使用的是这10次实验结果的平均值.北京理工大学的焦晨宇[33]在2015年研究了一种可伸缩的分布式文件系统SDFS,并针对海量小文件存储进行了性能优化.为了对比不同文件系统写性能的差异,本文对HDFS,SDFS,MFCSS系统的写性能做了对比,图6显示了这3个文件系统之间写性能的差异,其中SDFS的实验数据来源于焦晨宇的论文.

Fig. 6 The writing performance of MFCSS图6 MFCSS系统写性能
MFCSS系统在保存非冗余文件时需要由存储接口管理子系统动态生成文件的保存路径,集群管理子系统需要保存文件指纹信息,存储管理子系统需要保存文件元数据,同时存储接口管理子系统需要把文件流传输到存储服务器上,这些操作结束之后文件就保存成功了.如果MFCSS系统保存的是冗余文件,那么系统只需保存相关的引用信息就会提示用户文件保存成功.HDFS和SDFS由于没有数据去冗措施,因此在保存数据冗余度较高的多媒体文件时,本文实现的MFCSS系统的性能要优于其他2个文件系统,而且MFCSS系统的性能优势随着数据冗余度的提高会变得更加显著.
5.2 系统响应时间测试
为了评估MFCSS系统在保存多媒体文件时系统的响应时间,实验过程中使用了大量内容不同的小文件,这些文件的平均大小为100 KB,实验过程中分别对HDFS和MFCSS系统执行读写操作各200次,统计系统读写的平均响应时间,其中SDFS的实验数据来源于焦晨宇同学的论文[33].
图7所示为HDFS,SDFS,MFCSS系统响应时间的差异.从图7中可以看出本文实现的多媒体文件云存储系统MFCSS在小文件的读写上相较于HDFS和SDFS有更好的性能优势,平均响应时间远低于HDFS,同时也优于SDFS.

Fig. 7 The system response time图7 系统响应时间
5.3 系统吞吐量测试
为了测试存储目录逻辑扩容策略的有效性,证明此方法可以有效提高系统的运行效率,实验过程中采用的数据集是100个具有不同内容的1MB大小的文件,模拟了多用户并发上传文件的场景,测试了系统从1台存储服务器逐渐扩容到3台存储服务器时各个阶段的吞吐量,每次实验都做了10次并取平均值作为实验结果.
图8所示是系统吞吐量的测试结果,随着MFCSS系统存储服务器的增加,系统的吞吐量逐渐提高,但增加了存储服务器后系统的吞吐量优势并非立刻展现出来,因为增加存储服务器的同时系统会增加内存资源、CPU资源和网络等资源的消耗,随着并发用户数的增加吞吐量的优势才能得以展现.在实验环境下,当云存储系统的存储服务器数量从1台扩展到2台时,并发用户数在9以内并不能显示出扩容优势,只有并发用户数超过了9个,具有2台存储服务器的系统才会比具有1台存储服务器的系统具有更高的吞吐量.当云存储系统的存储服务器数量从2台扩展到3台时,系统的吞吐量优势在并发用户数为5时就开始展现出来,并随着并发用户数的增加,具有3台存储服务器的系统具有更加明显的性能优势.

Fig. 8 The throughput of MFCSS图8 系统吞吐量
5.4 内存使用测试
在评估MFCSS系统的内存使用情况时,分别测试了用户上传2 000,4 000,6 000,8 000,10 000个文件的情况下,集群管理子系统和存储管理子系统各自的内存占用情况,在相同测试环境下测试了HDFS原型系统在保存这些文件时命名空间结点和数据结点的内存使用情况.其中图9(a)表示集群管理子系统与HDFS命名空间结点的内存使用实验结果,图9(b)表示存储管理子系统与HDFS数据结点的内存使用实验结果.

Fig. 9 The memory usage of MFCSS comparing with HDFS图9 MFCSS与HDFS的内存使用对比
从图9(a)可知,在保存相同个数文件的情况下,集群管理子系统使用的内存少于HDFS命名空间结点,主要是因为HDFS命名空间结点保存了HDFS集群中所有的文件元数据,而MFCSS系统的集群管理子系统仅保存了文件元数据中的文件指纹信息,因此HDFS命名空间结点消耗更多的内存.从图9(b)可知,即使存储管理子系统把它所在的存储服务器上所有文件元数据都加载到内存中,它需要使用的内存空间依然少于HDFS数据结点,主要是因为HDFS原型系统的数据结点需要维护每个数据块的块报告(block report)以及其他数据块相关信息,因此它需要消耗更多的内存空间.
5.5 磁盘占用空间测试
为了评估MFCSS系统在节省磁盘占用空间方面的性能,实验过程中把系统部署在课题组局域网后,供课题组的其他成员通过本系统上传多媒体文件,图10所示为10周之内课题组成员通过MFCSS系统累计上传的多媒体文件总量和这些文件实际占用磁盘空间的对比图.

Fig. 10 The disk usage of MFCSS图10 磁盘占用空间
在刚开始的几周里,MFCSS系统积累的用户数据较少,因此用户上传的多媒体文件都需要保存到磁盘中,过一段时间之后MFCSS系统积累了大量用户数据,因此用户上传的多媒体文件会越来越多的被系统判定为冗余文件,此时系统只会记录相关的文件引用信息,并不会重复的保存用户数据,因此用户累计上传的文件大小和这些文件的实际磁盘占用空间之间的差距逐渐增大,而且差距越来越明显.
6 总 结
本文分析了目前主流的分布式文件系统的优点和不足,为了解决数据冗余度高的应用程序在低存储成本条件下对多媒体文件进行分布式存储的难题,提出了一种分布式存储目录建模方案,该建模方案具有很高的灵活性,允许应用程序自定义存储目录树的结构.为了去除数据中心内重复的多媒体文件数据,提出了一种数据去冗方案,并在降低了存储成本且不影响用户体验的情况下,解决了多媒体文件在MFCSS系统内的数据去冗难题.在识别重复数据的过程中,使用布隆过滤器加快了识别冗余文件的速度.基于分布式存储目录建模方案实现的MFCSS系统,简化了应用程序管理分布式环境中多媒体文件的过程,在保存数据冗余度较高的多媒体文件时具有良好的写性能,可以有效提高磁盘的存储效率,同时具备良好的扩展性,还可以加快用户与MFCSS系统之间传输文件的平均速度.
在未来的工作中,为提高系统的可靠性,将会使用副本策略保护MFCSS系统中存储的文件,提高系统的可靠性,同时将会对多媒体文件进行分类,不同类型的多媒体文件由不同的布隆过滤器进行管理,进一步提高冗余文件的定位速度.
[1]Fu Yinxun, Luo Shengmei, Shu Jiwu. Survey of secure cloud storage system and key technologies[J]. Journal of Computer Research and Development, 2013, 50(1): 136-145 (in Chinese)
(傅颖勋, 罗圣美, 舒继武. 安全云存储系统与关键技术综述[J]. 计算机研究与发展, 2015, 50(1): 136-145)
[2]Liu Jian, Huang Kun, Rong Hong, et al. Privacy-preserving public auditing for regenerating-code-based cloud storage[J]. IEEE Trans on Information Forensics and Security, 2015, 10(7): 1513-1528
[3]Lü Yisheng, Duan Yanjie, Kang Wenwen, et al. Traffic flow prediction with big data: A deep learning approach[J]. IEEE Trans on Intelligent Transportation Systems, 2015, 16(2): 865-873
[4]Vandenbroucke K, Ferreira D, Goncalves J, et al. Mobile cloud storage: A contextual experience[C] //Proc of the 16th Int Conf on Human-computer Interaction with Mobile Devices & Services. New York: ACM, 2014: 101-110
[5]Eyben F, Weninger F, Gross F, et al. Recent developments in opensmile, the munich open-source multimedia feature extractor[C] //Proc of the 21st ACM Int Conf on Multimedia. New York: ACM, 2013: 835-838
[6]Armbrust M, Fox A, Griffith R, et al. A view of cloud computing[J]. Communications of the ACM, 2010, 53(4): 50-58
[7]Zhao Zhenpeng, Badam S K, Chandrasegaran S, et al. A multimedia sketching system for collaborative creativity[C] //Proc of the 32nd Annual ACM Conf on Human Factors in Computing Systems. New York: ACM, 2014: 1235-1244
[8]Dinh H T, Lee C, Niyato D, et al. A survey of mobile cloud computing: architecture, applications, and approaches[J]. Wireless Communications and Mobile Computing, 2013, 13(18): 1587-1611
[9]Kwon S J. A cache-based flash translation layer for TLC-based multimedia storage devices[J]. ACM Trans on Embedded Computing Systems, 2016, 15(1): 11-12
[10]Levi A, Mokryn O, Diot C, et al. Finding a needle in a haystack of reviews: Cold start context-based hotel recommender system[C] //Proc of the 6th ACM Conf on Recommender Systems. New York: ACM, 2012: 115-122
[11]Duan Huiying, Liu Feifei. Building and managing reputation in the environment of Chinese e-commerce: A case study on Taobao[C] //Proc of the 2nd Int Conf on Web Intelligence, Mining and Semantics. New York: ACM, 2012: 43-49
[12]Ross R B, Thakur R. PVFS: A parallel file system for Linux clusters[C] //Proc of the 4th Annual Linux Showcase and Conf. Berkeley, CA: USENIX Association, 2000: 391-430
[13]Piernas J, Nieplocha J, Felix E J. Evaluation of active storage strategies for the lustre parallel file system[C] //Proc of ACM/IEEE Conf on Supercomputing. New York: ACM, 2007: 28-30
[14]Ghemawat S, Gobioff H, Leung S T. The Google file system[J]. ACM SIGOPS Operating Systems Review, 2003, 37(5): 29-43
[15]Shvachko K, Kuang H, Radia S, et al. The hadoop distributed file system[C] //Proc of the 26th IEEE Conf on Mass Storage Systems and Technologies. Piscataway, NJ: IEEE, 2010: 7-13
[16]Chu Yu. Taobao file system[OL]. [2016-05-06] http://code.taobao.org/p/tfs/wiki/intro/
[17]Kubiatowicz J, Bindel D, Chen Y, et al. Oceanstore: An architecture for global-scale persistent storage[J]. ACM SIGPLAN Notices, 2000, 35(11): 190-201
[18]Adya A, Bolosky W J, Castro M, et al. FARSITE: Federated, available, and reliable storage for an incompletely trusted environment[J]. ACM SIGOPS Operating Systems Review, 2002, 36(1): 9-14
[19]Weil S A, Brandt S A, Miller E L, et al. Ceph: A scalable, high-performance distributed file system[C] //Proc of the 7th Symp on Operating Systems Design and Implementation. Berkeley: USENIX Association, 2006: 307-320
[20]Burns A, Wellings A. Real-Time Systems and Programming Languages: Ada, Real-Time Java and C/Real-Time POSIX[M]. Boston: Addison-Wesley Educational Publishers Inc, 2009
[21]Chung C-Y, Lee C-L, Liu T-J. A high performance and low cost distributed file system[C] //Proc of the 2nd Int Conf on Software Engineering and Service Science (ICSESS). Piscataway, NJ: IEEE, 2011: 47-50
[22]Hao Peng, Wang Lirong, Wang Jiacai, et al. Design and implement of file linked distributed file system[C] //Proc of Conf on the Computer Science and Information Engineering. Piscataway, NJ: IEEE, 2009: 305-309
[23]Xiong Jin, Li Jianyu, Tang Rongfeng, et al. Improving data availability for a cluster file system through replication[C] //Proc of the 6th Conf on the Parallel and Distributed Processing. Piscataway, NJ: IEEE, 2008: 7-15
[24]Cao Liang, Wang Yu, Xiong Jin. Building highly available cluster file system based on replication[C] //Proc of the 7th Conf on the Parallel and Distributed Computing. Piscataway, NJ: IEEE, 2009: 94-101
[25]Chao H-C, Liu T-J, Kong-H, et al. A seamless and reliable distributed network file system utilizing webspace[C] //Proc of the 10th Int Symp on Web Site Evolution. Piscataway, NJ: IEEE, 2008: 65-68
[26]Dong Bo, Qiu Jie, Zheng Qinghua, et al. A novel approach to improving the efficiency of storing and accessing small files on Hadoop: A case study by PowerPoint files[C] //Proc of Conf on the Services Computing (SCC). Piscataway, NJ: IEEE, 2010: 65-72
[27]Dong Bo, Zheng Qinghua, Tian Feng, et al. An optimized approach for storing and accessing small files on cloud storage[J]. Journal of Network and Computer Applications, 2012, 35(6): 1847-1862
[28]Chandrasekar S, Dakshinamurthy R, Seshakumar P G, et al. A novel indexing scheme for efficient handling of small files in hadoop distributed file system[C] //Proc of Conf on the Computer Communication and Informatics (ICCCI). Piscataway, NJ: IEEE, 2008: 5-9
[29]Vorapongkitipun C, Nupairoj N. Improving performance of small-file accessing in Hadoop[C] //Proc the 11th of Conf on Computer Science and Software Engineering (JCSSE). Piscataway, NJ: IEEE, 2014: 200-205
[30]Fu Yinjin, Xiao Nong, Liu Fang. Research and development on key techniques of data deduplication[J]. Journal of Computer Research and Development, 2012, 49(1): 12-20 (in Chinese)
(付印金, 肖侬, 刘芳. 重复数据删除关键技术研究进展[J]. 计算机研究与发展, 2012, 49(1): 12-20)
[31]Boucher T D, Auslander D M, Bash C E, et al. Viability of dynamic cooling control in a data center environment[J]. Journal of Electronic Packaging, 2006, 128(2): 137-144
[32]Song Haoyu, Dharmapurikar S, Turner J, et al. Fast Hash table lookup using extended bloom filter: An aid to network processing[J]. ACM SIGCOMM Computer Communication Review, 2005, 35(4): 181-192
[33]Jiao Chenyu. The design and application of a scalable distributed file system [D]. Beijing: Beijing Institute of Technology, 2015 (in Chinese)
(焦晨宇. 可伸缩分布式文件系统及其应用[D]. 北京: 北京理工大学, 2015)
猜你喜欢
电脑报(2019年12期)2019-09-10 05:08:20
数学物理学报(2018年1期)2018-03-26 08:16:42
电子制作(2017年13期)2017-12-15 09:00:32
科学与财富(2016年29期)2016-12-27 00:31:46
江西通信科技(2015年3期)2015-12-05 05:52:09
电子设计工程(2014年12期)2014-02-27 11:58:23
电脑迷(2012年15期)2012-04-29 17:09:47
苏州市职业大学学报(2010年1期)2010-01-29 02:26:40
计算机世界(2009年34期)2009-11-17 09:04:02
计算机世界(2009年29期)2009-08-14 09:27:54
