
一种基于预判筛选的频繁项集挖掘算法
2018-05-28 01:24李德辰吕一帆赵学健
计算机技术与发展 2018年5期
李德辰,吕一帆,赵学健
(1.南京邮电大学 物联网学院,江苏 南京 210023; 2.南京邮电大学 现代邮政学院,江苏 南京 210003)
0 引 言
近年来,数据挖掘技术在各行各业的决策支持活动中扮演着越来越重要的角色[1-2]。关联规则分析作为数据挖掘最活跃的研究领域之一,在精准营销[3]、个性化医疗诊断[4]、网络优化与管理[5]等领域均有着广泛的应用。所谓关联规则就是隐藏在海量数据中的事物之间的联系和规律。在数据量急剧膨胀的今天,如何从海量数据中快速、高效地找出这些隐藏信息,提高关联规则分析算法的效率,具有十分重要的意义和应用价值。关联规则挖掘通常分两步进行:频繁项集挖掘,即找出所有满足最小支持度的项集,找出的这些项集称为频繁项集;生成关联规则,在第一步产生的频繁项集的基础上生成满足最小置信度的规则,产生的规则称为强规则。频繁项集挖掘作为关联规则挖掘技术的关键步骤,其性能对关联规则挖掘具有重要的意义。
Agrawal和Skrikant在1994年提出了第一个关联规则分析算法——Apriori算法[6]。Apriori算法是最经典的关联规则分析算法之一。Apriori算法使用重复迭代的方法生成频繁项集。首先扫描数据库,得到所有项目的出现频率,并与给定的最小支持度阈值进行比较,得到频繁1-项集L1。接下来,对频繁1-项集进行自连接,并根据频繁项集的向下闭包特性进行剪枝,产生候选频繁项集2-项集C2,接下来进行扫描数据库判决,得到频繁2-项集L2。以此类推,直至得到所有频繁项集为止。
Apriori算法在对候选频繁项集进行剪枝操作的过程中,用到了频繁项集的向下闭包特性。该特性是指如果一个集合是频繁项集,则它的所有子集都是频繁项集;反之,如果一个集合不是频繁项集,则它的所有超集都不是频繁项集。Apriori算法利用频繁项集的向下闭包特性对候选频繁项集进行剪枝,从而有效地控制候选项集的指数增长。
从上述可以看出,Apriori算法生成关联规则的过程包含两个步骤:挖掘隐藏在海量数据集中的所有频繁项集;根据挖掘出的频繁项集生成关联规则。其中第二步相对比较简单,第一步才是Apriori算法实现关联规则分析的关键,当然也是决定算法性能优劣的关键。目前对于Apriori算法的改进方法也大多数是针对第一步进行的。
Apriori算法产生频繁项集的过程有两个重要特点。首先,Apriori算法通过重复迭代生成频繁项集,在由候选频繁项集生成频繁项集的过程中,都要通过扫描数据库对候选频繁项集进行判别;其次,Apriori算法在每次迭代过程中,都要通过自连接生成候选频繁项集。这两个特点使得算法虽然思想简单,较容易实现,但是却存在两个缺点:在规则产生过程中,算法必须反复扫描事务库,I/O负载较大,且算法的运行效率较低;在自连接的过程中,会产生过多候选项集,使得挖掘的候选项集所含的项数过多,导致计算量惊人。这两个缺点使得Apriori算法在处理一些项集较多且长度较长的事务数据库时,显得力不从心。
为了克服Apriori算法存在的上述缺点,提出一种A_RSPS算法(Apriori with random sampling based prejudgment and screening)。通过对原始数据集的随机取样,进行Apriori算法计算,得出样本频繁项集的支持度集合,再计算原始数据集的频繁项集,遍历数据之前通过之前得到的样本支持度集合进行预判筛选对候选项集进行二次剪枝,并且引入阻尼因子和补偿因子对预判筛选产生的误差进行修正,以减少扫描数据库的次数,降低算法的运算时间,提高算法的运算效率。
1 相关研究
研究人员对频繁项集挖掘算法进行了研究,取得了大量研究成果。文献[7]采用矩阵的方法表示数据库,每个项目对应矩阵的一行,每个事务对应矩阵的一列,则矩阵的行向量之和为所对应项目在各事务中出现的次数,即该项目的支持度。可以看出,通过对矩阵的操作实现频繁项集的挖掘,无需多次扫描数据库,可以提高关联规则分析算法的时间效率,但是算法的空间复杂度较大。文献[8]使用Hash表存储事务数据以减少存储空间,同时使计算频繁项集更高效方便。此外,通过删除无用项表可以减少扫描Hash表的数量。用该方法在不损失频繁项集的前提下提高了发现频繁项集的效率。文献[9]对产生的每一个项集,采用包含两个线性表的类进行存储。事务标识符列表由支持该项集的所有事务标识符组成。因此一个项集的支持度就等于该项集的事务标识符列表长度。候选项集的支持度只要取其相应子集的事务标识符列表的交集得到,从而避免了为得到候选项集的支持度而去扫描数据库。文献[10]提出了一种新的产生候选集的方法,在k-1项频繁集中的一个项集与其余所有项集进行连接,把连接得到的不同k项集存储,然后立即确定所有符合剪枝后的候选k项集。这样就省略了寻找k项集的所有k-1项子集的费时剪枝操作,从而使剪枝步的平均扫描量大为减少。文献[11]把算法和负关联规则理论相结合,提出了一种基于负关联规则的数据挖掘算法。文献[12]提出的算法只需要一次数据库扫描。该算法在扫描数据库并计算每个项目的支持度时不会产生支持度为0的候选项,减少了候选项的数量。该文献还提到利用基于聚类的算法通过压缩事务数据库,通过节省无效的数据库扫描以提高算法的效率。文献[13]提出了基于用户的兴趣度的预处理的算法。该算法使用兴趣项排除不相关的项目以减少候选集D,其采用的纺织数据库包含众多参数,改进的算法只需要其中两个参数,同样减少了数据库扫描。文献[14]提出了一种有效的贪婪算法,以在给定的事务数据库中生成不相交的频繁项集的集合。该算法从给定的不相交频繁项集开始,发现更频繁的项目集。文献[15]提出预判筛选算法,该算法在Apriori算法连接、剪枝的基础上,添加了预判筛选的步骤,通过使用先验概率对候选频繁k项集集合进行缩减优化,并且引入阻尼因子和补偿因子对预判筛选产生的误差进行修正,以减少扫描数据库的次数,降低算法的运算时间,提高算法的运算效率。文中正是基于该文献提出的预判筛选的思想,结合采样思想进行的改进。
2 A_RSPS算法
2.1 相关定义
假设D是挖掘的事务数据库,该数据库中包含n个事务,即D={T1,T2,…,Tn}。I为数据库中全部项目的集合I={I1,I2,…,Im}。对∀Tq∈D,有Tq⊆I(1≤a≤n)。如果项目集X包含k个不同的项目,称X为k项集。如果X⊆Tq,称项集出现在事务Tq中,所有可能的k项集X组成集合Ck。统计该事件在D中发生的频率Px,称为X在D中的支持度(support),给出一个D的最小支持度min_support,若Px>min_support,则称X为频繁k项集,所有可能的频繁k项集X组成集合Lk。
对于给定的事务数据库D,给定的最小支持度为min_support。D中客观存在的频繁项集集合为L,包含N个成员;运行ARSPS算法所得频繁项目集集合为La。属于集合La但不属于集合L的项集数量记为Nf,属于集合L但不属于集合La的项集数量记为No。文中称属于集合La但不属于集合L的项集为误判项集,其中误判率MR=Nf/N,称属于集合L但不属于集合La的项集为遗漏项集,其中遗漏率OR=No/N。
2.2 算法描述
ARSPS算法寻找频繁项集的过程如下:
步骤1:对D进行随机取样取其子集Ds,取适当的Δ2,以(1-Δ2)*min_support对Ds进行Apriori算法运算构建频繁项集Ls,与对应的支持度集合sample_support组成一个筛选用的预判概率集合PS_set(Ls,sample_support)。
步骤2:扫描事务数据库D,对D中包含项目It的事务数Nt进行统计,其中It∈I,得到候选1项集C1=I,及其支持度集合support={Nt/|D|,∈[1,m]}。
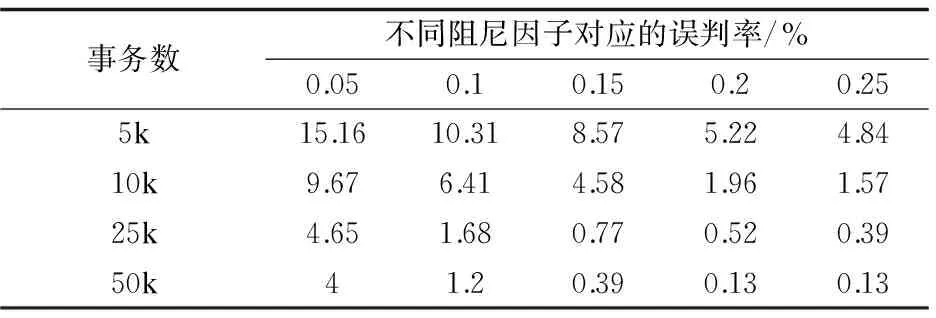
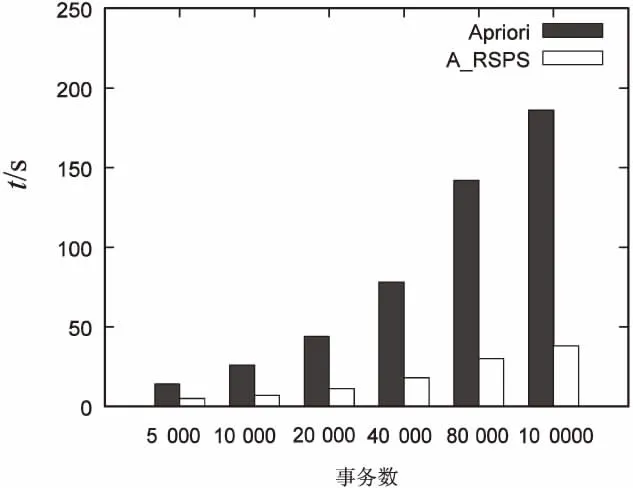
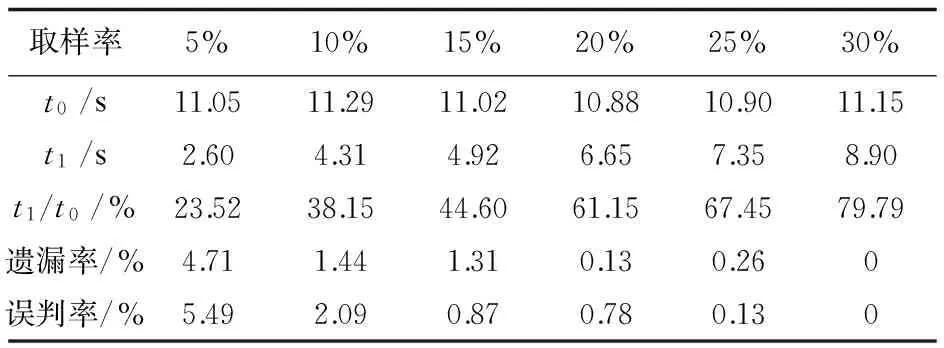
步骤3:对于C1中的每一个候选项Ci,判断它是否存在于之前的先验概率集合PS_set中,如果不在则把它从C1中删去,如果有,取适当的Δ1,如果Ci大于min_support*(1+Δ1)那就把它添加到L1,并且从C1中删除。最后扫描C1,删除那些Nt 步骤4:假设Lk-1已生成,现在可用它来生成Lk,Lk-1与自身进行连接得到候选k项集Ck,k∈{2,3,4…},第1次执行时k=2,每循环执行一次k加1。 连接过程如下:对于∀x1,x2∈Lk-1,若x1[1]=x2[1],x1[2]=x2[2],x1[k-2]=x2[k-2],…,x1[k-1]=x2[k-1],则将x1,x2连接生成候选项c={x1[1],x1[2],…,x1[k-1],x2[k-1]}。 步骤5:根据Apriori原理(如果某个项集是频繁的,那么它的所有子集也是频繁的),从候选k项集Ck中删除所有k-1项子集不完全包含在频繁k-1项集Lk-1中的项。 步骤6:对于剪枝后的Ck中的每一个候选项Ci,判断它是否存在于之前的先验概率集合PS_set中,如果不存在则把它从Ck中删去,如果存在且大于min_support*(1+Δ1),那就把它添加到Lk,并且从Ck中删除。 步骤7:扫描数据库,判断预判筛选后的每个成员是否满足最小支持度要求,满足则加入频繁项集循环执行直至为空,不能发现更大的频繁项目集为止。 步骤 8:最终获得的频繁项目集集合为L。 采用Python语言实现了Apriori和改进的A_RSPS算法,并通过实验对两个算法进行了对比。数据集使用Frequent Item-set Mining Dataset Repository(http://fimi.ua.ac.be/data/)网站提供的IBM Almaden Quest研究组生成的数据,算法增加的取样步骤中设置取事务数的一定百分比作为采样数据,引入阻尼因子和补偿因子两个参数,通过合理设置阻尼因子1和补偿因子2可有效降低误判率和遗漏率。 首先,设计实验1对阻尼因子和补偿因子的取值进行分析,每一组实验采用控制变量法,相同参数重复实验5次取平均值。表1表示min_support=0.02,阻尼因子Δ1取值从0.05到0.25的过程中事务数分别为5k,10k,25k,50k对应的频繁项集误判率。由表可知,当同一大小数据集Δ1取值变大时误判率逐渐减小,当Δ1取值确定时误判率随事务数增大而减小,尤其当事务数大于10k后,Δ1大于0.1后发生误判的概率已经低于1%。 表1 阻尼因子-误判率 实验2的数据如表2所示,表示min_support=0.02,补偿因子Δ2取值从0.05到0.2变化过程中5k,10k,25k,50k四组事务数据库的遗漏率。同实验1一样,事务数越大,遗漏率越小,Δ2越大,遗漏率越小。尤其在事务数较小的情况下,Δ2取较小值则会造成较大的遗漏率,而数据集很大时则遗漏率小于1%,可以接受。 表2 补偿因子-遗漏率 实验3对算法运行时间与事务数规模的关系进行了分析,设置min_support=0.02,在保证误判率和遗漏率的情况下Apriori和改进的A_RSPS算法运行时间如图1所示。由图1可见,Apriori算法的运行时间随着事务数增大迅速增加,100k事务数的数据集需要约193 s,而改进算法对于100k事务数的数据集需要约34 s。可以看出,A_RSPS相对于Apriori算法来说,时间效率得到了较大提升。 图1 算法运行时间随事务数的变化 实验4对算法运行时间随最小支持度min_support的变化情况进行了分析。对于10k的数据集,在保证误判率和遗漏率的情况下,分别设置min_support为0.01,0.02,0.04,0.08,为保证min_support取较小情况下的误判率不会过高,选择10%取样,设置Δ1=0.4,Δ2=0.35,见表3。 表3 最小支持度对运行时间的影响 实验5对算法取样率对运行时间、遗漏率和误判率的影响进行分析。设定min_support=0.02,10k数据集,Δ1=0.25,Δ2=0.25,分别取样5%,10%,15%,20%,25%,在同一参数下进行5次测试取均值,相应的运行时间、遗漏率和误判率如表4所示。由该表可知,改进算法占原始算法时间比随着取样率的增加而增加,15%取样率时约需要消耗44%原始Apriori算法所需的时间,同时,遗漏率和误判率相应减少,在30%取样率时已经几乎不出现遗漏和误判了,而取10%以下取样率时遗漏率和误判率会明显增大,不宜采用。 表4 算法取样率对运行时间、遗漏率和误判率的影响 文中提出一种基于预判筛选和采样思想的关联规则挖掘算法A_RSPS。该算法在对数据集处理之前取样部分数据进行经典Apriori算法计算得出样本数据的支持度,在原始算法连接、剪枝的基础上,增加了预判筛选的步骤,通过使用样本计算得到的支持度对候选频繁k项集集合进行缩减优化,从而减少关联规则挖掘过程中扫描数据库的次数。此外,算法引入阻尼因子和补偿因子对预判筛选引起的误判率和遗漏率进行控制。经实验验证,A_RSPS算法在保证误判率和遗漏率的前提下降低了算法的运算时间,提高了算法的运算效率。 参考文献: [1] 王光宏,蒋 平.数据挖掘综述[J].同济大学学报:自然科学版,2004,32(2):246-252. [2] 毕建欣,张岐山.关联规则挖掘算法综述[J].中国工程科学,2005,7(4):88-94. [3] 阮利男.大数据时代精准营销在京东的应用研究[D].成都:电子科技大学,2016. [4] 黄新霆,包小源,俞国培,等.医疗大数据驱动的个性化医疗服务引擎研究[J].中国数字医学,2014,9(8):5-7. [5] 岳彦杰.基于规则的网络数据关联分析器的优化设计[D].哈尔滨:哈尔滨工业大学,2008. [6] AGRAWAL R,SRIKANT R.Fast algorithms for mining association rules[C]//Proceedings of the 20th international conference on very large data bases.[s.l.]:[s.n.],1994:487-499. [7] 马盈仓.挖掘关联规则中Apriori算法的改进[J].计算机应用与软件,2004,21(11):82-84. [8] 陈文庆,许 棠.关联规则挖掘Apriori算法的改进与实现[J].微机发展(现名:计算机技术与发展),2005,15(8):155-157. [9] 刘华婷,郭仁祥,姜 浩.关联规则挖掘Apriori算法的研究与改进[J].计算机应用与软件,2009,26(1):146-149. [10] 胡吉明,鲜学丰.挖掘关联规则中Apriori算法的研究与改进[J].计算机技术与发展,2006,16(4):99-101. [11] 张 玺.数据挖掘中关联规则算法的研究与改进[D].北京:北京邮电大学,2014. [12] RAJESWARI K.Improved Apriori algorithm-a comparative study using different objective measures[J].International Journal of Computer Science and Information Technologies,2015,6(3):3185-3191. [13] INGLE M G,SURYAVANSHI N Y.Association rule mining using improved Apriori algorithm[J].International Journal of Computer Applications,2015,112(4):37-41. [14] PALSHIKAR G K,KALE M S,APTE M M.Association rules mining using heavy itemset[C]//Proceedings of data & knowledge engineering.[s.l.]:[s.n.],2007. [15] 赵学健,孙知信,袁 源.基于预判筛选的高效关联规则挖掘算法[J].电子与信息学报,2016,38(7):1654-1659.3 实验分析


4 结束语
猜你喜欢
保健医苑(2022年5期)2022-06-10
辽宁大学学报(自然科学版)(2022年1期)2022-04-26
鸭绿江(2021年17期)2021-11-11
成都信息工程大学学报(2021年6期)2021-02-12
天津诗人(2020年4期)2020-11-18
计算机应用(2020年5期)2020-06-07
计算机技术与发展(2019年7期)2019-07-23
计算机与数字工程(2018年10期)2018-10-23
天津诗人(2017年2期)2017-03-16
读者·原创版(2015年6期)2015-11-14
