
电网数据存储技术选型的研究
2018-05-25 06:37李成岭郑雨翔洪祎祺李雯郭慧敏
电信科学 2018年5期
李成岭,郑雨翔,洪祎祺,李雯,郭慧敏
(1.国网上海市电力公司浦东供电公司,上海 200122;2.上海中兴电力建设发展有限公司,上海 200122)
1 引言
国网辽宁省电力有限公司全业务统一数据中心数据分析域非结构化数据接入方面涉及非结构化数据管理平台中电子文件管理系统、档案系统、电网GIS地理空间信息系统、营销业务系统、安监系统、PMS2.0、协同办公系统、电力交易系统、ERP、计量生产调度平台、营销GIS、基建管理信息系统等 34个业务系统接入非结构化数据管理平台的非结构化数据。综合考虑,主要通过测试80 GB文件的写入、读取场景过程中分布式文件系统性能各种指标的不同数量大小,如节点数量的大小、备份因子的大小、数据块的大小,对国网公司大数据平台分布式文件系统(基于HDFS优化封装)的读写性能进行测试。
2 非结构化数据存储
2.1 节点数量对读写性能的影响
下面以测试节点数量对分布式文件系统读写性能的影响作为用例来说明。为保障测试结果的准确性,所有的测试节点的物理配置需保持一致,且在一个分布式集群下,数据块大小统一默认为128 MB,其他参数都保持一致。在统一的测试环境下,实施测试操作:跨节点远程写入和读取80 GB文件,分别记录耗时;分别在不同工作节点上本地写入和读取80 GB文件,分别记录耗时;重复以上步骤,分别测试2个、3个DataNode的HDFS集群环境,跨节点远程写入文件、节点本地写入文件耗时,测试结果如下所示。
(1)1个DataNode的HDFS集群
1个DataNode的HDFS集群的测试结果见表1。
(2)2个DataNode的HDFS集群
2个DataNode的HDFS集群的测试结果见表2。
(3)3个DataNode的HDFS集群
3个DataNode的HDFS集群的测试结果见表3。
集群的规模增大,在DataNode上读取数据的性能优势将越来越小,因为数据块分布越来越稀疏,在一个数据节点上能够取得的数据块越来越少,需要通过网络进行传输的数据越来越多。另外,随着集群规模的增大,客户端读写的速率有递减的趋势。

表1 1个DataNode的HDFS集群的测试结果

表3 3个DataNode的HDFS集群的测试结果
2.2 备份因子数对读写性能的影响
下面以测试备份因子数对分布式文件系统读写性能的影响作为用例来说明。为保障测试结果的准确性,所有的测试节点的物理配置需保持一致,节点数量为3。在统一的测试环境下,实施测试操作:设置备份因子数为1,跨节点远程写入和读取80 GB文件,分别记录耗时;分别在不同工作节点上本地写入和读取80 GB文件,分别记录耗时;重复以上步骤,分别测试备份因子为2、3的HDFS集群环境中跨节点远程读写文件、节点本地读写文件耗时,测试结果如下所示。
(4)备份因子为1~3情况下的写性能测试
备份因子为 1~3情况下的写性能测试结果见表4。
(2)备份因子为1~3下的读性能测试
备份因子为 1~3情况下的读性能测试结果见表5。
备份因子的改变不影响客户端的读写性能,客户端的 I/O瓶颈依然是交换机的传输速率。备份因子数增加时,客户端写的时间有小幅度的增加,这是因为要把同一个块写到不同的机器上,增加了写的开销。备份因子的增加使本地写文件性能下降,本地读文件性能提高。

表4 备份因子为1~3情况下的写性能测试结果

表5 备份因子为1~3情况下的读性能测试结果
2.3 数据块大小对写入性能的影响
下面以测试数据块的大小对分布式文件系统读写性能的影响作为用例来说明。为保障测试结果的准确性,同上一项测试设置相同,节点数量为3个,备份数为3。在统一的测试环境下,实施测试操作:设置设置块大小为4 MB,跨节点远程写入80 GB文件,记录耗时;重复以上步骤,分别测试备份因子为4 MB、8 MB、16 MB、32 MB、64 MB、128 MB、256 MB、512 MB、1 024 MB时的HDFS集群环境,跨节点远程读写文件、节点本地读写文件耗时,测试结果如下所示。
经测试,当数据块逐渐增大,写入时间在总体上是一个递减的趋势,但当块增大到一定程度之后,写入时间趋于平稳,即数据块的增大只能在一定的范围内影响HDFS的读写性能,如果把数据块的大小设置为更大的,那对性能的影响就微乎其微。
分布式文件系统功能方面主要需测试分布式文件系统的负载均衡、节点动态拓展。
2.4 负载均衡
下面以测试分布式文件系统负载均衡的功能作为用例来说明。为保障测试结果的准确性,测试节点在1个分布式集群下,集群上已有一定数据存储负载,测试新添节点后执行负载均衡。在统一的测试环境下,实施测试操作:搭建一个2个节点的 HDFS统集群;写入一定量数据,查看HDFS监控页面,查看并记录每个节点中块的数量;集群新添加一个节点,执行负载均衡命令,过20 min后,查看每个节点中块的数量;多次执行负载均衡,过20 min后,查看每个节点块的数量测试结果如下所示。
(1)新增测试节点前每个节点中块的数量情况
搭建的两个节点:BG8S01和BG8S03,新增测试节点前每个节点中块的数量分别为458和457。
(2)新增节点后,执行负载均衡每个节点中块的数量情况
新增节点后,执行负载均衡每个节点中块的数量情况如图1所示。

图1 执行负载均衡每个节点中块的数量情况
负载均衡的目的虽然是平衡数据,但它并不追求毕其功于一役,而是事先设定目标,每一次执行只实现预设目标,即只是缩小了过载/负载节点与集群平均使用率的差值,而通过反复多次的执行使集群内的数据逐渐趋于均衡。可见,分布式文件系统能通过搭建分布式节点实现系统的负载均衡。
2.5 节点动态拓展
分布式文件系统具备良好的扩展性,能够动态增加节点,并能保持数据的分布均衡和存储空间的扩容。
3 实时数据存储
大数据平台分布式列式数据库基于 Hadoop HBase优化封装,HBase是基于Hadoop的NoSQL数据库,能够为大数据提供实时的读/写操作,能够利用 HDFS的分布式处理模式,并通过MapReduce获取强大的离线处理或批量处理能力,同时能够融合key/value存储模式,以实现实时查询能力。HBase是一个分布式、可扩展、面向列的数据库,因此可部署在廉价的PC服务器集群上处理大规模的海量数据。
3.1 节点数量对读写性能的影响
下面以测试节点数量对HBase读写性能的影响作为用例来说明。为保障测试结果的准确性,节点的物理配置一致,测试节点在同一个分布式集群下;HBase配置参数均为默认值。在统一的测试环境下,实施测试操作:写入1 000万条数据,其中,每条数据300 byte;rowkey为散列值,长度为12;列族下有3个字段,字段名分别为TN、MP、TO。完成写入后,计算写入总时间;对上述表进行读取性能测试,测试指定rowkey方式单次读取的速率;重复上述步骤,分别测试在2、3个工作节点的 HBase分布式集群环境下的读写性能,测试结果如下所示。

表6 HBase写入数据测试结果
(1)HBase写入数据测试
HBase写入数据测试结果见表6。
(2)HBase读取数据测试
HBase读取数据测试结果如图2所示。

图2 HBase读取数据测试结果
随着集群的规模增大,HBase写入性能呈线性递增,单次rowkey读取的速率近似相等。
3.2 列族数量对读写性能的影响
下面以测试列族数量对HBase读写性能的影响作为用例来说明。为保障测试结果的准确性,节点的物理配置一致,测试节点在同一个分布式集群下;HBase配置参数均为默认值。在统一的测试环境下,实施测试操作如同上一项测试步骤,测试结果如下所示。
(1)HBase写入性能测试
HBase写入性能测试结果如图3所示。

图3 HBase写入性能测试结果
列族的数量影响写入的性能,数量越多则写入性能越差。在相同列族上的读取性能差别不大,如果跨列族读取,列族数量越多则读取性能越差。
3.3 列名及列族名长度对读写性能的影响
下面以测试列名及列族名长度对HBase读写性能的影响作为用例来说明。为保障测试结果的准确性,测试节点在 1个分布式集群下,HBase配置参数均为默认值。在统一的测试环境下,实施测试操作:搭建一个3个工作节点的HBase分布式集群环境;新建一张列族名长度为一个字符的HBase列族表,写入1 000万条数据,其中,每条数据300 byte;rowkey为散列值,长度为12;列族下有1个字段,字段名长度为1个字符。完成写入后,计算写入总时间;对上述表进行读取性能测试,测试指定rowkey方式单次读取的速率;重复上述步骤,分别测试在列族明长度为1,列名长度为2、3;以及列名长度为1,列族名长度为2、3的HBase分布式集群环境下的读写性能,测试结果如下所示。
(1)HBase 列名及列族名长度不同写入测试
HBase 列名及列族名长度不同写入测试结果见表7。
(2)HBase 列名及列族名长度不同读取测试
HBase 列名及列族名长度不同读取测试结果见表8。
列名、列族名的长度影响HBase的读写性能,长度越长则性能越差。
3.4 rowkey结构对读写性能的影响
下面以测试rowkey组成结构对HBase读写性能的影响作为用例来说明。为保障测试结果的准确性,测试节点在1个分布式集群下,HBase配置参数均为默认值。在统一的测试环境下,实施测试操作:搭建一个3个工作节点的HBase分布式集群环境;新建一张只有一个列族,列族名长度为一个字符的HBase表;写入1 000万条数据,其中,每条数据300 byte;rowkey为流水号散列值,长度为12;列族下有1个字段,字段名长度为1个字符。完成写入后,计算写入总时间;对上述表进行读取性能测试,测试指定rowkey方式单次读取的速率;重复上述步骤,分别测试rowkey的结构为不散列时在HBase分布式集群环境下的读写性能,测试结果如下所示。
(1)不同结构的rowkey写HBase性能测试
不同结构的rowkey写HBase性能测试结果如图4所示。

图4 不同结构的rowkey写HBase性能测试结果
(2)不同结构的rowkey 读HBase性能测试
不同结构的rowkey读HBase性能测试结果如图5所示。

图5 不同结构的rowkey读HBase性能测试结果

表7 HBase 列名及列族名长度不同写入测试结果
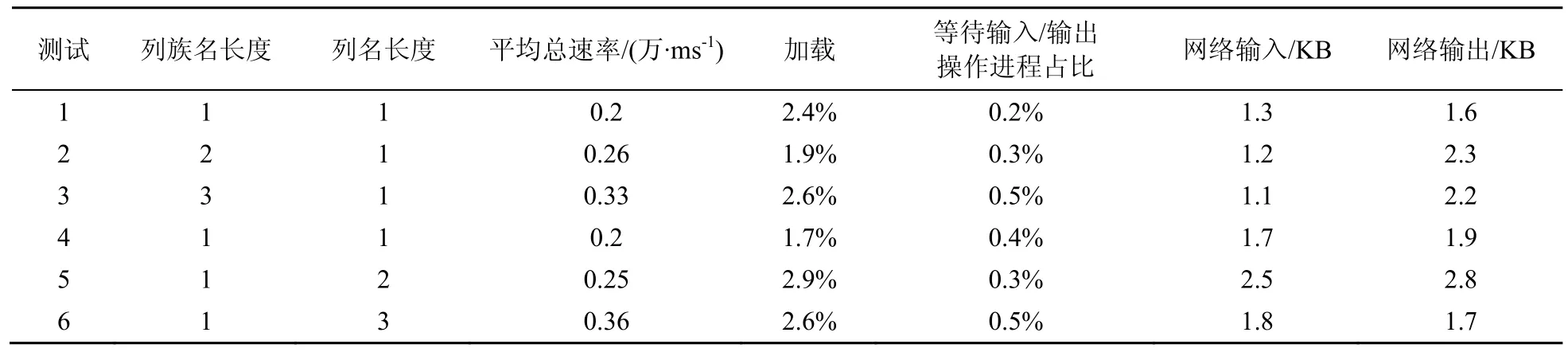
表8 HBase 列名及列族名长度不同读取测试结果
rowkey结构设计得越离散,读写出吞吐量越高,速度越快。
3.5 rowkey长度对读写性能的影响
下面以测试rowkey长度对HBase读写性能的影响作为用例来说明。为保障测试结果的准确性,测试节点在1个分布式集群下,HBase配置参数均为默认值。在统一的测试环境下,实施测试操作同上一项测试步骤,重复上述步骤,分别测试在rowkey的长度为20、30在HBase分布式集群环境下的读写性能,测试结果如下所示。
(1)不同长度的rowkey 写HBase性能测试
不同长度的rowkey 写HBase性能测试结果如图6所示。

图6 不同长度的rowkey写HBase性能测试结果
(2)不同长度的rowkey 读HBase性能测试
不同长度的rowkey 读HBase性能测试结果如图7所示。

图7 不同长度的rowkey读HBase性能测试结果
rowkey的长度影响存取的性能,长度越长则性能越差。
3.6 批量操作对读写性能的影响
下面以测试批量操作对HBase读写性能的影响作为用例来说明。为保障测试结果的准确性,测试节点在1个分布式集群下,HBase配置参数均为默认值。在统一的测试环境下,实施测试操作同上项测试步骤,对上述表进行读取性能测试,测试指定rowkey方式单次读取一条的速率,重复上述步骤,分别测试批量100条、1 000条、10 000条在HBase分布式集群环境下的读写性能,测试结果如下所示。
(1)不同批量操作数对HBase写性能的影响
不同批量操作数对HBase写性能的影响的测试结果见表9。
(2)不同批量操作数对HBase读性能的影响
不同批量操作数对HBase读性能的影响的测试结果见表10。
合适的批量数能够有效提升读写性能,并能达到一个最优效率。然后随着批量数的增大,性能逐步下降。
分布式列式数据库功能方面主要需测试分布式列式数据库的负载均衡、数据压缩功能。
3.7 负载均衡
下面以测试HBase在负载均衡方面的功能作为用例来说明。为保障测试结果的准确性,测试节点在1个分布式集群下,集群上已有一定数量的表(region数超过节点数),测试过程中新添加节点。在统一的测试环境下,实施测试操作:搭建一个2个工作节点的分布式文件系统集群,并观察region的数量及分布情况;集群新添加1个工作节点,等待5 min(balancer默认定期检查时间)查看region分布情况,同2个工作节点的情况比较,测试结果如下所示。

表9 不同批量操作数对HBase写性能的影响的测试结果

表10 不同批量操作数对HBase读性能的影响的测试结果
HBase负载均衡测试结果如图8所示。
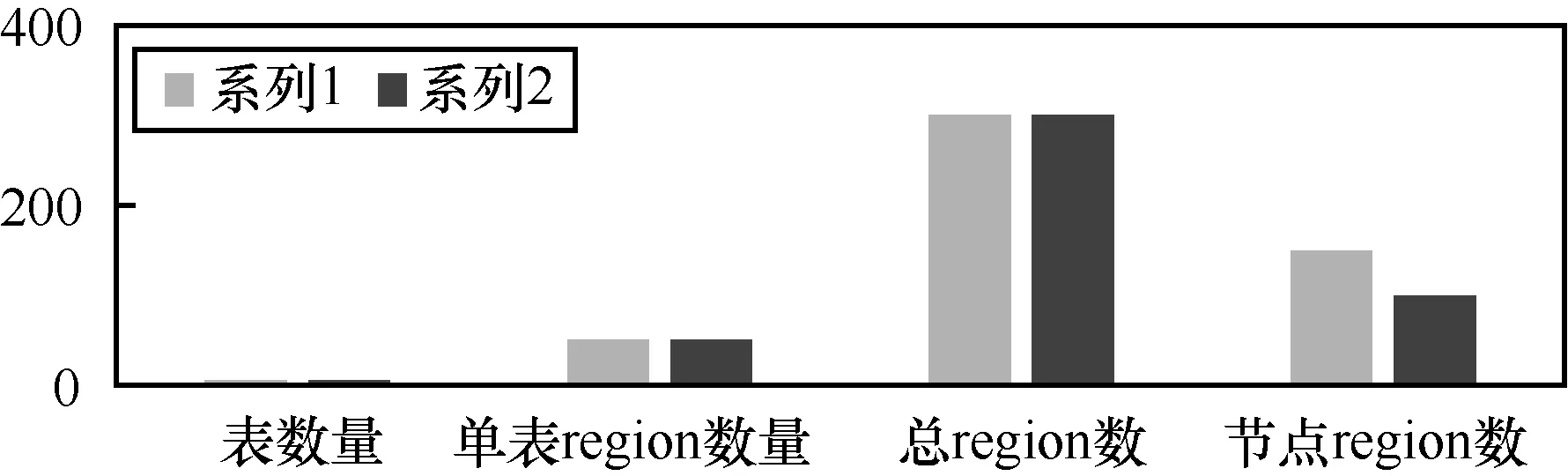
图8 HBase负载均衡测试结果
HBase定期检查,并平衡各工作节点的region数量。
3.8 数据压缩
下面以测试HBase数据压缩的功能作为用例来说明。为保障测试结果的准确性,测试节点均在分布式集群下,两次写入数据的数据量大小一样。在统一的测试环境下,实施测试操作:搭建一个只有1个工作节点分布式文件系统集群;未开启数据压缩,新建HBase数据表,写入一定量的数据,查看集群的磁盘利用率;配置LZO数据压缩,将相应JAR文件放到HBase的lib文件夹下,新建HBase数据表并设置LZO数据压缩,清空集群数据,写入相同的数据,查看磁盘的利用率,测试结果如下所示。
数据压缩的测试结果见表11。
数据压缩功能能够有效地压缩数据大小,减少磁盘的空间使用。
3.9 节点动态扩展
下面以测试分布式文件系统的扩展性作为用例来说明。为保障测试结果的准确性,测试节点均在分布式集群下,两次写入数据的数据量大小一样。在统一的测试环境下,实施测试操作:搭建一个只有1个工作节点的HBase集群,观察HBase的region的数量及分布情况;集群新添加1个工作节点,等待5 min(balancer默认定期检查时间)查看region分布情况,同只有1个工作节点的情况比较;查看集群的可用空间,测试结果如下所示。
HBase动态扩展测试结果如图9所示。
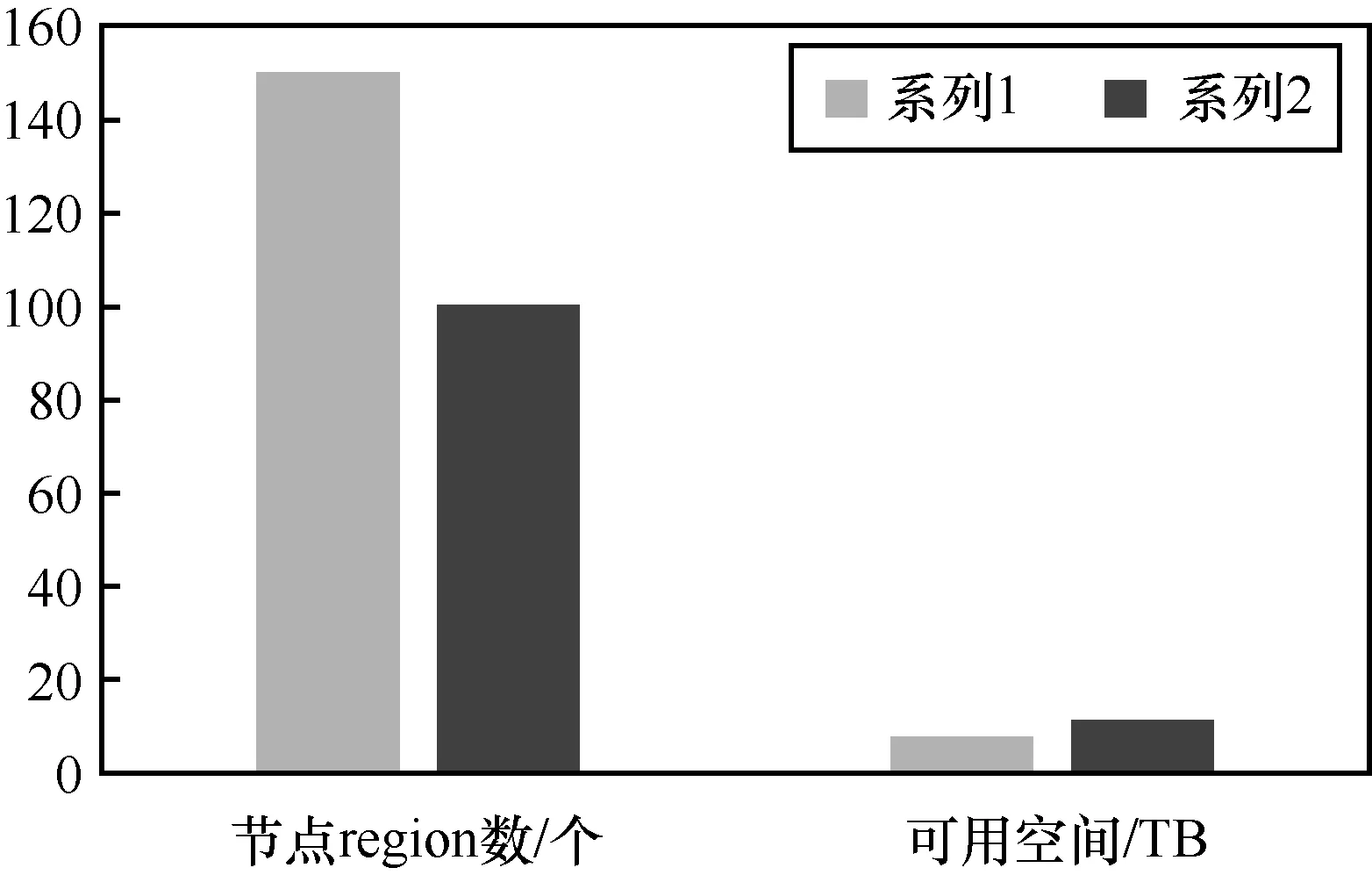
图9 HBase动态扩展测试结果
HBase具备良好的扩展性,能够动态增加节点,并能保持region分布均衡和存储空间的扩容。

表11 数据压缩的测试结果
4 结束语
HBase具备良好的扩展性,能够动态增加节点,并能保持region分布均衡和存储空间的扩容。集群的规模增大,在DataNode上读取数据的性能优势将越来越小,因为数据块分布越来越稀疏,在一个数据节点上能够取得的数据块越来越少,需要通过网络进行传输的数据越来越多。另外,随着集群规模的增大,客户端读写的速率有递减的趋势。
参考文献:
[1]GEORGE L.HBase权威指南[M].代志远, 刘佳, 蒋杰, 译.北京: 人民邮电出版社, 2013.GEORGE L.HBase: the definitive guide[M].Translated by DAI Z Y, LIU J, JIANG J.Beijing: Posts & Telecom Press, 2013.
[2]蔡斌, 陈湘萍.Hadoop技术内幕: 深入解析Hadoop Common和 HDFS架构设计与实现原理[M].北京: 机械工业出版社,2013.CAI B, CHEN X P.Hadoop internals: in-depths study of common and HDFS[M].Beijing: China Machine Press, 2013.
[3]孟鑫, 马延辉, 李立松.HBase企业应用开发实战[M].北京:机械工业出版社, 2014.MENG X, MA Y H, LI L S.Enterprise application development with HBase[M].Beijing: China Machine Press, 2014.
[4]皮雄军.NoSQL数据库技术实战[M].北京: 清华大学出版社, 2015.PI X J.NoSQL database technology combat[M].Beijing:Tsinghua University Press, 2015.
[5]DIMIDUK N, KHURANA A.HBase实战[M].谢磊, 译.北京: 人民邮电出版社, 2013.DIMIDUK N, KHURANA A.HBase in action[M].Translated by XIE L.Beijing: Posts & Telecom Press, 2013.
[6]蒋燚峰.HBase管理指南[M].北京: 人民邮电出版社, 2013.JIANG Y F.HBase administration cookbook[M].Beijing: Posts& Telecom Press, 2013.
[7]SHRIPARV S.Learning HBase[M].周彦伟, 娄帅, 蒲聪, 译.北京: 电子工业出版社, 2015.SHRIPARV S.Learning HBase[M].Translated by ZHOU Y W,LOU S, PU C.Beijing: Publishing House of Electronics Industry, 2015.
[8]董西成.Hadoop技术内幕: 深入解析MapReduce架构设计与实现原理[M].北京: 机械工业出版社, 2013.DONG X C.Hadoop internals: in-depths study of MapReduce[M].Beijing: China Machine Press, 2013.
[9]GROVER M, MALASKA T, SEIDMAN J.Hadoop应用架构[M].郭文超, 译.北京: 人民邮电出版社, 2017.GROVER M, MALASKA T, SEIDMAN J.Hadoop application architecture[M].Translated by GUO W C.Beijing: Posts &Telecom Press, 2017.
[10]王雪迎.Hadoop构建数据仓库实践[M].北京: 清华大学出版社, 2017.WANG X Y.Practice of Hadoop data warehouse[M].Beijing:Tsinghua University Press, 2017.
[11]WHITE T.Hadoop权威指南: 大数据的存储与分析(第4版)[M].王海, 华东, 刘喻, 等译.北京: 清华大学出版社, 2017.WHITE T.Hadoop: the definitive guide[M].Translated by WANG H, HUA D, LIU Y, et al.Beijing: Tsinghua University Press, 2017.
猜你喜欢
恋爱婚姻家庭(2023年1期)2023-02-15
网络安全和信息化(2020年1期)2020-01-15
军事运筹与系统工程(2019年4期)2019-09-11
电子制作(2018年11期)2018-08-04
能源(2017年10期)2017-12-20
能源(2017年5期)2017-07-06
中国交通信息化(2017年3期)2017-06-08
知识就是力量(2017年2期)2017-01-21
太空探索(2016年10期)2016-07-10
雷达与对抗(2015年3期)2015-12-09
