
基于贝叶斯算法的用户阅读行为分析设计与实现
2018-05-25 17:59:56王与尧
韶关学院学报 2018年3期
王与尧
(北京理工大学 珠海学院计算机学院,广东 珠海519088)
朴素贝叶斯分类模型是一种非常简单有效的分类器模型,核心思路是模型训练阶段和分类预测阶段.假设某个体有n项特征(Feature),分别为 w1,w2,...,wm.现有 m个类别(Category),分别为 c1,c2,...,cm.贝叶斯分类器就是计算出概率最大的那个分类.过程是在训练阶段对每一个集合的元素估算先验条件概率,然后在分类阶段计算后验概率,返回后验概率最大的类.
使用朴素贝叶斯分类模型时需要假设各个定义的分量对于决定变量之间是不存在任何关系的,即给属性值时属性之间需要相互独立.虽然在现实世界中各个分类条件不可能完全相互独立,但是这样的假设条件能够减少朴素贝叶斯分类模型的工作量和复杂度,所以训练数据量越大,模型越精确.
先验条件概率:

后验条件概率:

公式解释:
P(d):从文档空间中随机抽取一个文档d的概率.
P(c):从文档空间中随机抽取一个文档d,它属于类别c的概率(某类文档数/总的文档数).P(d|c):文档d对于给定类c的概率(文档中的单词数/某类中总的单词数).
类别集:c={c1,c2,…,cn}.
β文档向量:d={w1,w2,…,wn}.
P(c|d):测试文档d属于某类c的概率.
1 中文分词的实现
本文所用分词工具为:Lucene全文搜索引擎、Paoding分词器.MapReduce程序默认的输入格式如图1所示.

图1 默认的输入格式
本程序的设计如图2所示.

图2 本程序的设计
根据图1和图2可以知道,如果使用Hadoop默认的输入格式,当需要处理的文件数量达到上万、上亿时,在执行任务时也需要创建相应数量的Mapper,这样的做法实际上是相当低效的,会大量开销系统资源并且使程序的执行时间变得很长.可以看出Hadoop的默认输入格式是非常不适合执行这个分词任务的.为了解决这个问题,本程序使用了CombineFileInputFormat,改变了程序读取数据的方式,使得程序的执行效率大大提高.
本研究中使用的工具类:
(1)InputFormat
InputFormat是对Mapper有非常重要的影响,它决定Mapper的数量以及Mapper接受数据的格式.输入的数据会被分割成逻辑分片(Split),分片的数据会被RecordReader读取后交给Mapper处理.
(2)CombineFileInputFormat
CombineFileInputFormat继承了FileInputFormat,是一个用来处理大量小文件任务而设计的输入格式.在本程序中重写了getSplit方法,返回的分片类型是CombineFileSplit.本程序还需要实现createRecordReader方法,建议返回值的类型是CombineFileRecordReader,它可以处理类型为CombineFileSplit的数据分片.另外,CombineFileRecordReader的构造函数中需要指定一个RecordReader,用于处理分片内的单个文件.
技术实现:继承Mapper类,通过Mapper调用MapReduce程序,创建庖丁分词器analyzer实例,StringReader接收输入数据,然后调用analyzer实例的tokenStream方法进行分词,Paoding分词器将会对中文文本进行细粒度全切分.MapReduce中文分词结果,文本分词的结果如图3、图4所示.

图3 未分词的文本

图4 分词后的文本
2 朴素贝叶斯模型的实现
2.1 训练集与测试集的构建
(1)随机抽取20%的数据作为测试集.
(2)提取剩余样本作为训练集,左连接测试集.
(3)测试集和训练集划分的比例为1∶4.
2.2 训练模型生成
(1)用trainclassifier命令来对训练集进行训练.命令:mahout trainclassifier-i digital/train-o digital/model-bayes-type bayes-ng 1 source hdfs.
(2)训练之后得到互补的朴素贝叶斯分类器.能够在Eclipse直接查看到HDFS上面已经生成了贝叶斯模型,也可以在命令行中使用hadoop dfs-ls+路径指令来查看模型是否已经生成.该模型文件夹下的其他3个文件夹主要用于存储贝叶斯分类器模型的参数.
这里的生成的模型是Mahout的朴素贝叶斯分类器模型,它假设各类的先验概率都相等,同时,为了提高分类器的效率,该模型还对P(Xi|Ci)的计算方式进行了改进,另外Mahout还提供了一种新的朴素贝叶斯算法-Complementary Naive Bayes.
3 朴素贝叶斯模型的测试结果
3.1 模型测试结果
本文使用Mahout的测试集的命令进行测试,命令为:mahout testclassifier-d digital/test-m digital/model-bayes-type bayes-ng 1-source hdfs-method mapreduce,输出的矩阵叫做混淆矩阵(Confusion Matrix),对角线的数字代表分类正确的文章,对角线上的数字越大,代表分类器的精度越高,模型的分类结果如图5所示.

图5 模型输出的结果
3.2 结果评价指标
(1)局部评价指标:模型对某一类的分类性能,只能代表局部性能.
查全率:模型的覆盖能力,即文章被分类正确的比例.

查准率:模型正确判断文章类型的能力,指模型分类的准确率.
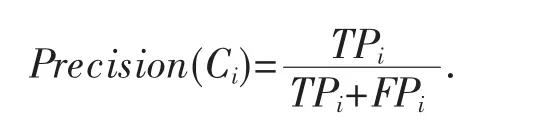
(2)整体评价指标:整体评价模型性能的指标.
宏平均值为所有局部指标的平均值.查全率的宏平均值(MacRecall)和查准率的宏平均值(MacPrecision)分别为:
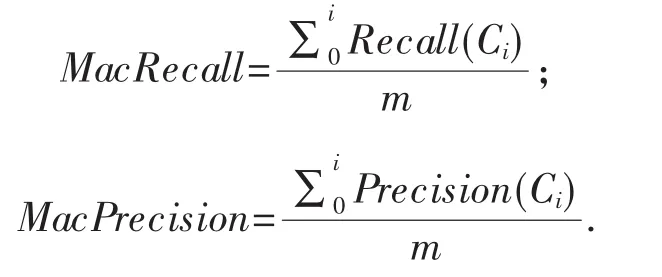
微平均值为被正确分类的文档所占的比例:

3.3 朴素贝叶斯模型测试结果
根据混淆矩阵和评价指标进行计算可得表1,可以看出该模型在各种参数上的表现都比较出色,基本符合一开始的预期结果.理论上,该模型在效率、速度上也非常出色,但是由于实验的样本数据的数量级还没有达到一定的级别,该实验结果暂时不能说明该模型在处理更大规模数据的优势.

表1 测试评估结果
4 用户阅读行为分析结果
4.1 任务说明
(1)任务描述
搜集一些用户在某些网站浏览过的页面文本,每个用户浏589览的文本放在一个文件夹中,代表一个用户的访问记录,根据这些文本文件计算用户的阅读偏好.
(2)输出结果
每个用户的阅读偏好,即按照类别进行排序.
4.2 MapReduce并行程序设计思想
本程序的设计思想如图6所示.

图 6 Mapper、Reducer输入输出格式
4.3 使用MapReduce程序实现分析用户阅读行为
(1)在Hadoop平台上运行分类程序的jar包.在命令行输入命令:hadoop jar-MR/MRClassify.jar user/processed user/output digital/model-cbayes cbayes,可以得到用户对不同类型的文章的阅读偏好,结果如图7所示:

图7 用户对不同文章的阅读次数
(2)使用Pig脚本对各个用户的阅读进行排序.执行之后可以显示每个用户最喜欢读的文章类型和数量,Pig脚本的代码如图8所示.执行Pig脚本之后得到最终的输出结果.
Pig脚本代码解释:
–group:对相同user的阅读记录进行聚合
–sorted:根据times进行降序排序
–top:保存sorted的第一行

图8 Pig脚本代码
(3)输出结果.排序后的输出结果如图9所示,最左侧代表的是用户的编号,中间的是用户阅读数量最多的文档的类别,最右侧的一列代表用户阅读最多的一类文章的数量.

图9 每个用户阅读偏好的最终排序结果
5 结语
通过对Lucene全文搜索引擎以及Paoding分词器的使用和研究,得出如下结论:Paoding分词器可以很好地完成本实验的分词任务,Paoding分词器在本实验中表现出非常好的分词精度和分词效率,而且算法非常容易理解、模型复杂度低、新词的辨识能力强.
本研究使用了Hadoop下的MapReduce设计模型,为了使程序能过更高效的完成并行计算的工作,本程序修改了MapReduce程序的输入方式,使得大量小文件的处理能过更加高效,节省了大量的时间和机器资源.
在测试朴素贝叶斯分类模型之后,得出如下结论:朴素贝叶斯分类器拥有很好的分类精度,在查全率、查准率、宏平均值等方面的表现说明朴素贝叶斯分类模型在文本分类处理任务上有非常可观的效率.最后,本研究通过MapReduce程序进行并行计算,可以计算出每个用户的阅读各种文章的数量,然后通过排序得出用户对各种类型的文章的阅读偏好.
[1]李静梅,孙丽华,张巧荣,等.一种文本处理中的朴素贝叶斯分类器[J].哈尔滨工程大学学报,2003,24(1):72-74.
[2]周颜军,王双成,王辉.基于贝叶斯网络的分类器研究[J].东北师大学报(自然科学版),2003,35(2):23-25.
[3]王树良,丁刚毅,钟鸣.大数据下的空间数据挖掘思考[J].中国电子科学研究院学报,2013,8(1):8-17.
[4]邹腊梅,肖基毅,龚向坚.Web 文本挖掘技术研究[J].情报杂志,2007,37(2):53-55.
[5]代六玲,黄河燕,陈肇雄.中文文本分类中特征抽取方法的比较研究[J].中文信息学报,2004,18(1):28-32.
[6]熊子奇,张晖,林茂松.基于相似度的中文网页正文提取算法[J].西南科技大学学报,2010,25(1):80-84.
[7]Chickering D M,Meek C,Heckerman D.Large-sample learning of Bayesian networks is hard[J].Journal of Machine Learning Research,2004(5):1287-1330.
[8]Friedman N,Koller D.Being Bayesian about network structure:A Bayesian approach to structure discovery in Bayesian networks[J].Machine Learning,2003,50(1/2):95-126.
猜你喜欢
小资CHIC!ELEGANCE(2021年36期)2021-10-15 02:25:24
四川文学(2020年11期)2020-02-06 01:54:30
当代陕西(2019年23期)2020-01-06 12:18:04
智富时代(2019年6期)2019-07-24 10:33:16
当代陕西(2019年9期)2019-05-20 09:47:38
数理化解题研究(2017年4期)2017-05-04 04:07:54
高中生·天天向上(2016年9期)2016-11-22 09:10:34
铁道通信信号(2016年6期)2016-06-01 12:10:20
电子器件(2015年5期)2015-12-29 08:43:15
郑州大学学报(理学版)(2014年2期)2014-03-01 04:20:49
