
基于用户命令序列的伪装入侵检测*
2018-05-25 03:09汤雨欢
通信技术 2018年5期
汤雨欢,施 勇,薛 质
(上海交通大学 电子信息与电气工程学院,上海 200240)
0 引 言
信息安全领域的大部分研究集中在对受保护系统的入侵检测[1]。在参与CERT(计算机应急响应小组)调查的组织中,46%表示由内部攻击造成的损害比外部攻击更为严重[2]。内部攻击者可以分为伪装者和叛徒两类。试图访问受限信息的每个合法用户都属于叛徒,他们非常了解内部组织架构,故倾向于像合法用户一样行事。对叛徒部署如蜜罐或诱饵文件之类的陷阱,是最常见的检测方法[3]。而伪装者是未经授权的外部用户。他们以某种方式模拟授权用户执行恶意活动,但伪装者很有可能不完全了解该系统[4]。已有许多方法被提出用于伪装检测,他们大多使用[5]介绍的Schonlau数据集,而该数据集由用户键入命令行的历史记录组成。Schonlau等人将6种不同的统计方法(uniqueness、Bayes one-step Markov、hybrid multistep Markov、compression和sequence-match等)应用到这个公开数据集,目的是检测伪装用户。但是,结果显示检测率很低(介于34.2%和69.3%之间),假阳性率在1.4%和6.7%之间。接着,Maxion[6]等人使用朴素贝叶斯模型来检测伪装。该模型的基本假设是命令的独立性。虽然这个假设在伪装情况下是不现实的,但朴素贝叶斯技术仍然比先前提到的6种技术提供了更好的结果。Coull等人[7]受生物信息学中匹配算法的启发,提出了一种半全局比对技术。Kim和Cha[8]将“共同命令”和“投票引擎”概念应用到支持向量机算法。Seo[9]等人研究了不同的SVM内核组合,并证明了N-gram和String内核配置优于通用的RBF内核。
以上这些方法中的基本假设是伪装者的行为可能会偏离正常用户的典型行为。任何给定技术的表现都是以误报率(False Positive Rate)和命中率(Hit Rate)来衡量的。同一个算法,伴随命中率的增加,误报率通常也会增加。一项成功的技术将具有较高的检测率(命中率)和较低的误报率。
本文提出了一种集成机器学习和自然语言处理的方法。使用自然语言处理中的N-Gram方法,选择合理N值对命令序列进行分段,结合TF-IDF加权技术用于特征提取,然后分别使用随机森林(Random Forest)分类器和多层感知器(MLP)对每个用户根据其正常命令序列特征构建模型检测伪装者。本文在Schonlau数据集上进行实验,并将获得的结果与现有研究方法的结果进行比较。使用以误报率(False Positive Rate)为横轴、命中率(Hit Rate)为纵轴组成的ROC曲线分析实验结果。
1 检测方案设计
1.1 伪装检测系统的体系结构
图1是UNIX系统中伪装检测系统的完整体系结构图。

图1 伪装检测系统架构
此方案中,系统架构与审计数据库中的源数据无关。审计数据可以是关于计算机系统的各种记录,如文件访问记录、邮件收发记录、资源使用情况、系统登录记录、网络数据包、命令跟踪和界面交互式事件等。
本研究专注于基于主机的IDS,通过分析用户在UNIX环境中键入的命令行数据来执行伪装检测。可以使用UNIX的acct审计机制收集用户的Shell命令。为了有效比较新方法的检测精度与以前方法的检测精度,本实验基于SEA[4]公共命令数据集。
由于工作内容、输入习惯以及对计算机系统的熟悉程度不同,每个用户在发布命令时都表现出特定的特征,而用户之间的这些差异使伪装检测成为可能。本文对每个用户提取其历史正常命令序列的特征,由此构建模型后,将待检测的命令序列与当前用户模型进行比较,区分入侵者。因此,建立特征是学习算法的第一步,然后从每个用户的命令序列中提取N-Gram频率特征。
1.2 序列信息的特征提取
特征信息的提取是伪装入侵检测中最重要的部分。在基于UNIX命令的伪装入侵检测中,单个命令是能够反映用户活动并具有一定含义的最小单元。然而,单一命令在表达用户特征方面非常有限。本文使用SEA数据集的固有配置,即连续的100个命令作为一个命令块,以便与其他先前的实验进行公平比较。词袋模型(Bag of Words)忽略了命令顺序,只是单纯统计命令块中同一命令出现的次数。
为了减少伪装检测系统中的误报数量,提取序列信息特征,同时考虑命令顺序和出现频率,用于训练准确的用户行为模型。命令序列可以是多个N-Gram序列的组合。N-Gram作为简单文本表示技术,将字符串转换为固定长度的高维特征向量,其中每个特征对应于连续的子字符串,可以评估2个长度相同或不同的字符串间的差异程度。它的关键优势在于,短语本身可以携带比单个元素更多的信息。因此,使用N-Gram作为特征的用户行为的表达能力大于单个词的表达能力。广义的N-Gram是指长字符序列中的N个字符片段,本文中即指N个连续的命令。这里只关心相邻命令之间的关系,特别是在命令序列中出现多次的N-Gram片段之间的关系,显示出用户输入命令的偏好,如图2所示。一般,包含K个命令的命令序列包含K-N+1个N-Gram序列。

图2 N-Gram对命令序列的分割
建立N-Gram特征的过程较为简单,只需要对每个用户的审计数据分别进行扫描,将具有大于K的频率的N-Grams提取为用户特征。考虑到频率低的N-gram特征更具有特异性,频率高的N-Gram特征通用性高,应将N值限制在一定的合理范围内,以提供更好的用户区分性和出现在待检测序列中的更大可能性。
1.3 使用TF-IDF计算N-Gram序列权重
在待检测序列被分成一系列N-Gram序列组合后,必须为当前用户计算每个N-Gram序列的权重,以评估整个序列。
根据Unix环境下的命令输入特性和异常检测目的,权重计算应符合以下条件。首先,应该赋予用户频繁出现的命令序列更大的权重,因为这些命令代表了用户经常参与的某些特定行为。其次,为单个用户频繁出现但其他用户很少使用的命令序列赋予更大的权重,因为这些命令对区分用户非常有用。最后,每个用户频繁出现的基本操作命令应该受到权重限制,因为这些命令通常会干扰检测。
基于上述考虑,引入TF-IDF[10]模型计算每个命令序列特征的权重。TF-IDF作为一种数字统计量,旨在反映某个单词对集合或语料库中的文档的重要性。
TF-IDF的值随文档出现在文档中的次数成比例增加,并且被文档中单词的频率所抵消,这有助于调整一些频繁出现的单词。
TF-IDF的计算公式如下:

词频tf(t,d )是指给定N-Gram序列在检测当前用户时出现的次数,平滑后的逆文档频率idf(t)按式(2)计算:

其中,nd是用户总数,df(t,d )是包含N-Gram序列t的用户数量。逆文档频率idf(t)表示如果用户使用该序列的频率越低,则该序列的idf(t)越大,表明该序列具有更大的区分用户的能力。
1.4 随机森林(Random Forest)
由于具备良好的分类能力、可扩展性强、易解释性等特点,随机森林方法[11]是最流行的集成方法之一。直观上,随机森林可视为多棵决策树的集成,弱分类器决策树通过集成得到鲁棒性更强的分类器,具备更好的泛化误差,不容易产生过拟合现象。
1.5 多层感知器(MLP)
多层感知器是一个典型的前馈人工神经网络[12],前馈是指每一层的输出都直接作为下一层的输入。除输入节点外,每个节点都是使用非线性激励函数的神经元。图3解释了3层MLP的概念,即输入层、隐藏层和输出层。多个隐藏层和非线性激励函数的使用将多层感知器与线性感知器区别开来,具备了分类不线性可分数据的能力。

图3 包含一个隐藏层的多层感知器
2 实验结果分析
2.1 基于实验数据及配置
Schonlau等人[5]提出了伪装者内部攻击的形式,收集并构造了一套检测伪装入侵的数据集。该数据集凭借公开性和广泛使用性,已成为伪装入侵检测领域事实上的标准。他们共收集了70个用户的UNIX命令历史记录,从中随机选择50个组成数据集的用户,其他20名用户则被用作伪装者。50个用户中的每个用户的前5 000个命令都保持不变,这些没有任何异常的“干净块”被用作训练数据,之后的10 000个命令构成针对入侵进行测试的测试数据;其余20个用户的命令被随机插入到50个用户的测试数据中,由此将50个用户的命令替换为未在数据集中表示的20个用户的命令。
数据集以块为单位进行分组,一个数据块即由100个命令组成。目标是准确地检测“脏块”并将它们分类为伪装块。按照惯例,基于这些配置的实验被称为Schonlau et al(SEA)实验。
Maxion和Townsend[6]使用Schonlau数据集中相同的数据进行了另一项实验。他们分析了不同配置下的数据,称为1 vs 49配置。其中,前5 000个命令用于构建模型,并且使用其余49个用户输入的前5 000个命令作为测试数据。
本文实验基于SEA配置方法,为每个用户建立伪装入侵检测模型。每个用户的训练数据由作为正例的50个自身命令块和作为负例的50×49个来自其他用户的命令块构成,测试数据为100个命令块,其中包含0到24个伪装块。
2.2 实验结果评估与比较
将实验结果与同样使用Schonlau数据集的其他文献方法进行公平对比。
2.2.1 基于ROC曲线的性能对比
受试者工作特征曲线(Receiver Operating Characteristic,ROC)[13]是反映检测命中率和误报率连续变量的综合指标。根据不同阈值下的检测命中率(Hit Rate)和误报率(False Alarm Rate)绘制接收机工作特性曲线,通常用于评估不同方法伪装入侵检测的整体性能。

宽松的决策阈值可以获得更高的检测命中率,但带来了更高的误报率。曲线上的每个点都表示命中率和误报率之间的特定折衷。靠近图左上角的点是最合适的,因为它们表示高命中率和相应低的误报率。对于SEA数据配置而言,每个用户包含0~24个伪装数据块,50个用户共存在231个可能错过的警报。
图4展示了本文提出的基于命令序列的随机森林(Random Forest)和多层感知器(MLP)算法与先前各种方法的叠加结果。曲线本身显示的是随着决策阈值在其范围内逐步提升应用于2种算法的结果。
分析图4中2种分类器的ROC曲线,命中率在0~0.5时,随机森林算法的误报率略低于多层感知器;而命中率在0.5~1时,多层感知器的误报率明显低于随机森林算法,且多层感知器ROC曲线下方的面积AUC(Area Under the Curve)大于随机森林。AUC用于描述模型的整体性能,在类别比例相差很大的情况下,依然是很好的度量手段。它可以作为判断这2种分类预测模型优劣的标准,说明多层感知器分类器的整体表现优于随机森林分类器。
从与现有方法的叠加可以看出,除了使用更新算法的朴素贝叶斯分类器和使用Adaboost-决策树桩的效果优于本文算法,其他方法的检测性能均劣于本文算法。
而使用更新算法的朴素贝叶斯使用的测试方案与本文并不相同,因为更新过程是一个额外的部分,在复杂性和处理时间增加的情况下,需要比平常更多的训练数据。在与不使用更新算法的朴素贝叶斯分类器比较时,本文的2种算法效果都明显更优。
2.2.2 基于代价函数的性能对比
尽管伪装入侵检测器的性能可以根据其最大化命中率的能力和限制误报率的能力来判断,但是ROC曲线作为传统方法,这有时会过于简单并缺乏针对性。因为在实际应用中通常对误报率或漏报率(Missing Alarm Rate)有不同的倾向,而人们关心的是漏报率和误报率之间的权衡。因此,可以使用Maxion和Townsend[6]提出代价函数的概念评估每种检测方法的总体性能。代价函数表示漏报率和误报率的总和,定义如下:
代价=α*漏报率+β*误报率 (5)
参数α和β用于决定衡量成本时漏报率和误报率两者的比重。在大多数真实的入侵检测应用中,漏报被视为比误报更严重的错误。入侵可能会对系统造成严重影响,然而许多误报可以额外进行分析。在这个数据集中,伪装样本远远少于正常样本,误报对分类模型的总体准确性影响要比漏报更大。因此,将误报的成本设置为漏报的6倍,即使用如下代价函数:
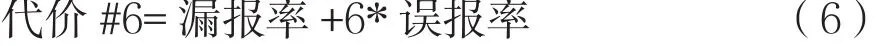
表1列出了对不同检测方法根据代价函数值计算的由小到大的排列结果,误报成本是漏报的6倍。由于使用更新算法的测试方案与本文及其他方法的的测试方案并不相同,我们排除了图3中参与比较的采用更新算法的朴素贝叶斯,将不使用更新算法的各类方法进行比较。由表1可知,本文提出的2种方法分别位列第1、第2位,在现有方法中获得了最低的入侵代价。

表1 不同文献方法关于代价函数的比较
2.2.3 参数N的取值对准确性的影响
为了评估N-Gram中参数N的取值对检测精度的影响,图5显示了改变N值时ROC曲线的变化。
此处,图5中1-gram意味着特征中只存在1-gram特征,而2-gram意味着特征中只存在2-gram特征,1,2-gram表示同时考虑了1-gram特征和2-gram特征。图5表明,单纯使用1-gram特征的效果优于单纯使用2-gram特征,说明1-gram特征出现在待检测命令序列中的可能性较高。事实上,不少已有检测方法中使用的词袋法(Bag of Words)就是单纯使用1-gram特征,亦能取得较好效果。图5还表明,联合使用1-gram和2-gram特征的效果均优于单独使用,能更具体和详细地表达用户特征。因此,在一定范围内将不同长度的N-Gram特征联合使用,对于提高伪装检测的准确性非常有用。然而,若继续增加N值,即将更多不同长度的N-Gram特征联合使用,检测精度不会再显著增加。由于3-gram特征出现在要检测的命令序列中的可能性较低,再提取更多特征需要更多的附加计算时间,却对检测性能几乎没有改善,所以仅靠提高N的值来提高检测精度的效果是有限的。本研究中,另N值为3,即联合使用1-gram、2-gram和3-gram特征。

图5 参数N对随机森林算法的影响
2.2.4 TF-IDF加权技术对准确性的影响
图6利用ROC曲线反映出多层感知器算法在使用TF-IDF和不使用TF-IDF情况下检测精度的巨大差异。分别以相同的命中率(71.35%)截取2条曲线上的点,使用TF-IDF的多层感知器算法以(3.0%)的低误报率展示出优异性能,而未使用TF-IDF的多层感知器算法则达到了(8.1%)的高误报率。

图6 TF-IDF加权技术对多层感知器算法的影响
3 结 语
本文提出的2种伪装入侵检测模型在训练数据量较小的情况下,仍能在检测命中率和误报率之间获得良好的折衷,体现出准确性高的特点。此外,在经过短时间学习后,它们能快速建立模型,发现入侵行为,体现出检测效率高的特点。依据代价函数的评估标准,本文2种方法的代价均远小于其他方法,多层感知器比随机森林的代价更小。
参考文献:
[1] 王永全.入侵检测系统(IDS)的研究现状和展望[J].通信技术 ,2008,41(11):139-143.
[2] WANG Yong-quan.Research Status and Prospects of IDS[J].Communications Technology,2008,41(11):139-143.
[3] Salem M B,Stolfo S J.Decoy Document Deployment for Effective Masquerade Attack Detection[C].Detection of Intrusions and Malware, and Vulnerability Assessment,International Conference,2011:35-54.
[4] Salem M B,Hershkop S,Stolfo S J.A Survey of Insider Attack Detection Research[J].In Advances in Information Security,2008(39):69-90.
[5] Schonlau M,Dumouchel W,Ju W H,et al.Computer Intrusion:Detecting Masquerades[J].Statistical Science,2001,16(01):58-74.
[6] Maxion R A,Townsend T N.Masquerade Detection Using Truncated Command Lines[C].International Conference on Dependable Systems and Networks,IEEE Computer Society,2002:219-228.
[7] Coull S,Branch J,Szymanski B,et al.Intrusion Detection:A Bioinformatics Approach[C].Computer Security Applications Conference,2003:24-33.
[8] Kim H S,Cha S D.Empirical Evaluation of SVM-based Masquerade Detection Using UNIX Commands[J].Computers & Security,2005,24(02):160-168.
[9] Seo J,Cha S.Masquerade Detection Based on SVM and Sequence-based User Commands Profile[C].ACM Symposium on Information,Computer and Communications Security ACM,2007:398-400.
[10] Jones K S.A Statistical Interpretation of Term Specificity and Its Application in Retrieval[J].Journal of Documentat ion,1972,28(01):493-502.
[11] Breiman L.Random Forests[J].Machine Learning,2001,45(01):5-32.
[12] White B W.Principles of Neurodynamics:Perceptrons and the Theory of Brain Mechanisms,by Frank Rosenblatt[M].Spartan Books,1962.
[13] Fawcett T.An Introduction to ROC Analysis[J].Pattern Recognition Letters,2006,27(08):861-874.
[14] Sen S.Using Instance-weighted Naive Bayes for Adapting Concept Drift in Masquerade Detection[J].International Journal of Information Security,2014,13(06):583-590.
[15] Huang L,Stamp M.Masquerade Detection Using Profile Hidden Markov Models[J].Computers &Security,2011,30(08):732-747.
[16] Ke W,Stolfo S J.One-Class Training for Masquerade Detection[C].IEEE Conference Data Mining Workshop on Data Mining for Computer Security,2003.
[17] Ju W H,Vardi Y.A Hybrid High-Order Markov Chain Model for Computer Intrusion Detection[J].Journal of Computational & Graphical Statistics,2001,10(02):277-295.
[18] Coull S,Branch J,Szymanski B,et al.Intrusion Detection:A Bioinformatics Approach[C].Computer Security Applications Conference,2003:24-33.
[19] Dumouchel W.Computer Intrusion Detection Based on Bayes Factors for Comparing Command Transition Probabilities[R].Washington DC:National Institute of Statistical Sciences,1999
[20] Jian Z,Shirai H,Takahashi I,et al.Masquerade Detection by Boosting Decision Stumps Using UNIX Commands[J].Computers & Security,2007,26(04):311-318.
[21] Davison B D,Hirsh H.Predicting Sequences of User Actions[J].Predicting the Future Ai Appreaches to Timeseries Analysis,1998:5-12.
[22] Kim H S,Cha S D.Empirical Evaluation of SVM-based Masquerade Detection Using UNIX Commands[J].Computers & Security,2005,24(02):160-168.
[23] Dash S K,Reddy K S,Pujari A K.Episode Based Masquerade Detection[C].International Conference on Information Systems Security,2005:251-262.
[24] Salem M B,Stolfo S J.Modeling User Search Behavior for Masquerade Detection[C].Recent Advances in Intrusion Detection,International Symposium,2010:181-200.
猜你喜欢
黑龙江工业学院学报(综合版)(2022年7期)2022-08-29
体育科技文献通报(2022年5期)2022-06-05
湖南文理学院学报(自然科学版)(2022年2期)2022-05-06
娃娃乐园·综合智能(2022年3期)2022-04-19
煤气与热力(2021年6期)2021-07-28
网络安全和信息化(2019年1期)2019-12-22
中国生殖健康(2019年11期)2019-01-07
长江丛刊(2018年31期)2018-12-05
军营文化天地(2018年2期)2018-04-20
NBA特刊(2017年8期)2017-06-05
