
GPFS文件系统的安装配置与维护
2018-05-25 08:50张新诺
计算机技术与发展 2018年5期
张新诺,王 彬
(国家气象信息中心,北京 100081)
0 引 言
随着信息化进程的推动,各行各业所需的相关信息量越来越多,需要更高效更安全的数据存储环境。在并行存储迅速发展的情况下,由于性能优势而备受国内各企事业单位信赖的GPFS系统得到了广泛应用。
IBM公司的GPFS文件系统全称为general parallel file system(通用并行文件系统),是IBM公司开发并生产的一种并行文件系统,普遍应用于服务器集群系统中[1]。GPFS文件系统为集群中的节点提供统一的数据存储空间,并允许集群中任何一个节点同时访问相同的数据。简单来说,GPFS是一个高性能、可共享磁盘的并行文件系统[2]。
1 GPFS文件系统的特性
GPFS文件系统为服务器集群提供高性能的数据访问,该文件系统允许数据被集群中多个节点同时、高效的访问。大多数现有的文件系统是专为单一服务器环境提供服务的,添加更多文件服务器并不会提高文件系统的性能。GPFS文件系统将独立的数据分块,并存放在多块硬盘中,以并行的方式进行数据的输入和输出,能够为服务器提供高性能的数据服务[3-4]。GPFS提供的其他功能包括高可用性、支持异构集群、灾难恢复、安全性、数据管理接口(DMAPI)、分级存储管理(HSM)和信息生命周期管理(ILM)[5]。
2 GPFS文件系统的配置
GPFS文件系统的安装较为简便,对应不同的操作系统安装其相应的安装包即可。安装完成后,不同的操作系统其对应的配置方式略有不同。文中以SUSE 10为例,简述文件系统的配置方式。
2.1 配置节点文件
配置节点文件主要是确定该GPFS文件系统可用于集群的范围,并确定文件系统的管理节点和仲裁节点的位置,配置如下:
root@hs21-1 [/root]
# vim /usr/lpp/mmfs/nodef
hs21-1.site:quorum
hs21-2.site
hs21-3.site
x3650-01.site:quorum-manager
x3650-02.site:quorum-manager
在GPFS文件系统中,至少需要一个仲裁节点(quorum),用于集群间的通信及数据完整性检查。由于该集群中节点较多,故设置三个仲裁节点,当任何一个仲裁节点出现问题时,集群节点仍能和其他的仲裁节点保持通信,保证GPFS文件系统仍能正常运行[6-7]。若多个仲裁节点发生故障,则集群节点无法正常通信,此时GPFS文件系统将不可用。在hs命名为刀片服务器,x3650服务器为普通X86机架服务器,为了保证文件系统的安全性,将两台x3650机架服务器定义为仲裁节点(quorum)和管理节点(manager),即quorum-manager类型节点。该种类型节点用于管理集群的配置及文件系统监控等方面[8]。
2.2 建立GPFS集群
将hs21-1.site作为GPFS集群的主管理者,在该节点上进行GPFS集群建立的操作。操作命令为:
mmcrcluster -C 集群名 -U 域名 -N各节点名 -p 主NSD服务器 -s 备NSD服务器
具体命令如下:
root@hs21-1 [/root]
#mmcrcluster -C hs21.cma.GPFS -U hs21.cma.GPFS -N /usr/lpp/mmfs/nodef -p hs21-1.site -s x3650-02.site
该命令中各参数含义如下:
-C hs21.cma.GPFS:设定集群名称为hs21.cma.GPFS
-U hs21.cma.GPFS:设定域名为hs21.cma.GPFS
-N /tmp/GPFS/nodef:指定各节点的文件名
-p hs21-1.site指定主NSD:服务器为hs21-1.site
-s x3650-02.site指定备NSD:服务器为x3650-02.site
命令执行完成后,执行mmlscluster命令检查集群建立情况,结果见图1。

图1 GPFS文件系统建立情况
2.3 配置并创建GPFS共享磁盘
2.3.1 建立NSD(network shared disk)配置文件
该文件系统是创建在由36块硬盘组成的存储介质中,其中每3块硬盘组建RAID 5磁盘阵列[9-10]。可用fdisk -l查看各硬盘信息,显示结果如下:
root@hs21-1 [/root]
#fdisk -l
Disk /dev/sdal: 1998.9 GB,1998985153536 bytes
255 heads, 63 sectors/track,243029 cylinders
Units=cylinders of 16065 * 512=8225280 bytes
……
根据硬盘信息建立NSD配置文件,配置文件的文件名可根据个人习惯命名,文中将其命名为DescFile,用于NSD的划分。NSD配置文件内容格式为:磁盘名:主节点名:备节点名:磁盘类型:失效组别:NSD名:存储池:(“:”为必须内容)。
根据命令格式编辑DescFile文件:
root@hs21-1 [/root]
# viDescFile
/dev/sdal:hs21-1.site:x3650-02.site:dataAndMetadata:4001:ft01_nsd1::
/dev/sdam:hs21-1.site:x3650-02.site:dataAndMetadata:4001:ft01_nsd2::
……(省略其他NSD硬盘)
/dev/sdbu:hs21-1.site:x3650-02.site:dataAndMetadata:4001:ft01_nsd36::
该文件中各字段具体解释如下:
(1)/dev/sdbu:代表硬盘名称,通过fdisk -l命令获得,不同系统对应的硬盘名称略有不同。
(2)hs21-1.site:代表NSD的主I/O节点,该节点名称根据文件系统的实际情况配置。
(3)X3650-02.site:代表NSD的备I/O节点。无该节点可以不填。
(4)dataAndMetadata:代表磁盘类型。NSD磁盘根据数据类型可以分为四种,分别为dataAndMetadata、dataOnly、metadataOnly和descOnly。
GPFS需要保存两种类型的数据,即data和metadata。metadata(元数据)是用于GPFS自身索引数据以及内部配置信息。这部分元数据只能保存在dataAndMetadata或者metadataOnly类型的磁盘中。dataAndMetadata说明该磁盘既可以存放元数据,也可以存放其他数据。在一些对元数据访问要求非常高的系统中,推荐使用Flash单独存放GPFS的元数据。在这种情况下,Flash里的磁盘就设置为metadataOnly,其他的磁盘就设置为dataOnly。descOnly类型的磁盘仅用于存放文件系统副本,并且在发生故障时可根据第三失效组恢复相关配置。一般来说,dataAndMetadata为NSD磁盘的默认类型[11-13]。
(5)4001:代表失效组(FailureGroup),可以不填,默认为4001。失效组主要用于定义一组来自于同一存储系统或者有一定隔离效果(如同一存储中的同一个RAID)的磁盘[14]。如果启用GPFS的Replica(复制)功能,GPFS会把同一个数据块的2个或者3个replica放置在不同的FailureGroup里。这样的话,同一个FailureGroup里不管坏多少个磁盘,都不会影响数据访问。FailureGroup的数值本身没有具体含义,主要为了区分不同失效组,数值相同的磁盘属于同一个失效组。如果启用GPFS的replica功能,每个数据块会多占用一倍(replica=2)甚至两倍(replica=3)的磁盘空间。一般而言,如果存储系统在硬件上已经保证了冗余,比如RAID以及多路径到SAN交换机,磁盘失效的概率已经很低,一般情况没必要启用Replica功能。
(6)ft01_nsd*:代表NSD盘的名称,可根据需要自行命名。
(7)命令最后一位代表存储池,如不填代表系统默认的存储池。
2.3.2 创建GPFS所需的NSD盘
编辑DescFile完成后,执行mmcrnsd -F命令,即可生成NSD盘。命令格式为:mmcrnsd -F NSD配置文件。
命令执行如下:
root@hs21-1 [/root]
#mmcrnsd -F DescFile
mmcrnsd:Processing disk sdal
……
mmcrnsd:Propagating the cluster configuration data to all
affected nodes.This is an asynchronous process.
命令执行完成后,可执行命令mmlsnsd -L检查NSD盘的创建情况。
2.4 创建文件系统
NSD盘创建完成后,需执行mmstartup -a启动GPFS。只有启动GPFS后,才能继续进行文件系统的创建。创建文件系统的命令为:
mmcrfs 文件系统设备名 “NSD盘名” -T 文件系统挂载点 -A yes/no -B 数据块大小
具体命令如下:mmcrfs /dev/fs1 "ft01_nsd1;ft01_nsd2;…(中间略)…;ft01_nsd36" -T /GPFS/fs1
命令中各字段具体解释如下:
/dev/fs1为文件系统设备名,创建文件系统时,系统会在集群所有节点自动创建。在4.2.1版本及更新的版本中,GFPS在Linux中将不会在/dev目录下生成文件系统设备名,因此在Linux版本的mount命令中也不会出现/dev的前缀。
“ft01_nsd1;……ft01_nsd36”为前文创建的NSD盘。也可使用创建NSD盘的DescFile文件,命令为:mmcrfs /dev/fs1 -F /root/DescFile -T /GPFS/fs1。
-A表示开机是否自动加载挂载点,默认是no,命令中可以不使用。
-B表示数据块大小,默认是256K,如果不加-B则表示使用默认数据块大小,文件系统创建后不可更改。数据块的大小选择与应用程序下发的I/O的大小接近时,GPFS的性能较好。GPFS本身有很多机制来适应不同的I/O大小。当应用程序下发的I/O大小不是很清楚,或者很复杂时,可以选择1 MB来折中。
2.5 挂载文件系统
执行挂载文件系统命令挂载文件系统,命令为:mmmount文件系统名。文件系统挂载完成后,可执行df命令查看文件系统情况。如能够显示所建文件系统的路径和名称,说明文件系统已经建设完成。具体执行命令为:mmmount fs1。
3 GPFS的管理与维护
3.1 GPFS启动与关闭
(1)mmstartup:为启动文件系统的命令,根据添加不同参数可以启动单节点的文件系统,也可启动所有集群文件系统。
单节点文件系统启动方式:执行mmstartup命令。
集群文件系统启动方式:执行mmstartup -a命令。
(2)mmshutdown:为关闭文件系统命令,同样根据添加不同参数可以关闭单节点文件系统,也可关闭所有集群文件系统。
单节点文件系统关闭方式:执行mmshutdown。
集群文件系统关闭方式:执行mmshutdown -a,其执行结果显示的时间会比关闭单节点时间略长。
通常在重启节点时,要先关闭GPFS文件系统等常用软件,避免节点重启完成后GPFS软件出现故障。
3.2 GPFS文件系统故障检查处理
通过长时间使用和维护GPFS文件系统,发现GPFS文件系统出现的故障多为硬件故障,因此文中主要从硬件角度处理GPFS故障。当GPFS文件系统出现建故障时,需要通过查看集群GPFS状态、磁盘状态、文件系统故障范围等多方面来确定故障原因。
3.2.1 查看集群节点状态
通过命令mmgetstate -a可查看集群各节点GPFS状态,执行结果如下:
root@hs21-1 [/root]
#mmgetstate -a
Node number Node name GPFS state
1 hs21-1 active
3 hs21-3 active
mmgetstate: The following nodes could not be reached:
hs21-2.site
从执行结果可以看到,节点hs21-2.site出现故障无法加入到集群中,其他节点GPFS都是健康的active状态,若GPFS state显示其他状态,如GPFS stat显示down时,登录到相关节点查看GPFS是否被关闭。检查/var/adm/ras目录下的mmfs.log.latest文件内容,查看是否有GPFS关闭的信息,如执行如下命令:
root@mdss-zc2 [ /var/adm/ras ]
# tail -500mmfs.log.latest
……
Wed May 17 00:40:42 GMT 2017:mmremote: Completing GPFS shutdown ...
如结果所示,可知该节点GPFS被执行shutdown操作,可用mmstartup命令尝试能否重启GPFS文件系统。若mmfs.log.latest文件中没有GPFS文件系统的shutdown信息,则GPFS文件系统进程被关闭或由于其他原因造成文件系统无法正常工作,可先执行mmshutdown,再执行mmstartup尝试重启文件系统。如果无法正常启动,可用其他命令检查物理硬盘等其他故障原因。
3.2.2 查看NSD状态检查物理硬盘
在使用GPFS文件系统过程中,有时会发生文件系统出现挂起状态,从而导致文件系统不可用,如在执行df命令时,显示“df:`/dev/fs1:Stale NFS file handle”,说明fs1文件系统被挂起。此时可检查文件系统对应NSD是否出现故障。
查询文件系统NSD命令:mmlsdisk文件系统名。
执行命令见图2。
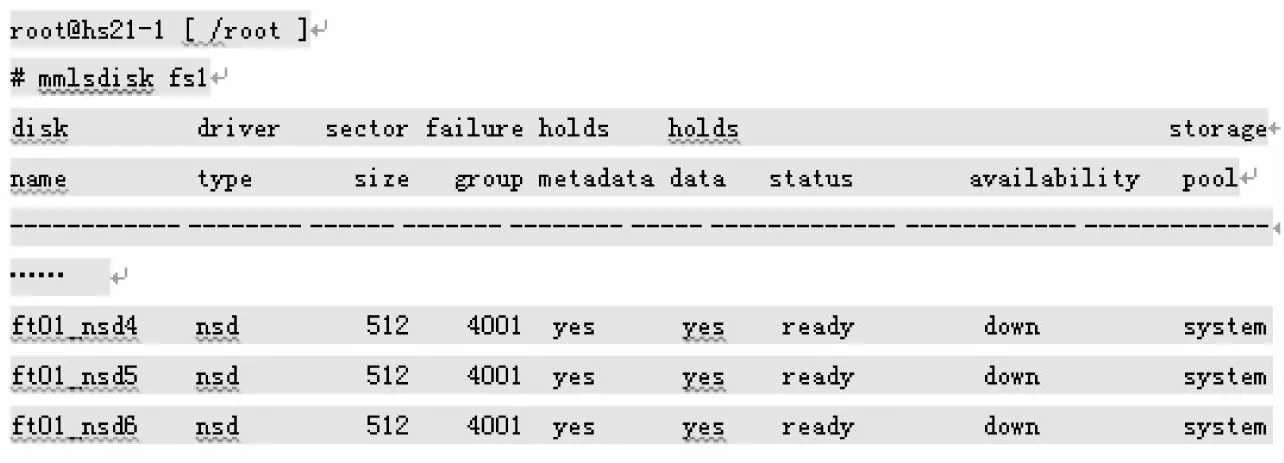
图2 查看文件系统NSD状态
通过查看可以看出,该文件系统中有三个NSD出现故障,显示出down的状态。当NSD出现down的状态时,说明系统中与down状态NSD相对应的物理硬盘出现故障。根据硬盘状态检查该硬盘所在RAID状态。如果RAID完好,只需更换故障硬盘,重新挂载文件系统即可;如果RAID出现故障,则可能需要重建文件系统。
当存储系统中的RAID出现故障,首先要查看3块物理硬盘出现故障的原因,尝试能够将故障NSD的状态改为up。如果NSD状态能够恢复,则说明不是所有的硬盘都存在物理故障,文件系统中的数据也不会出现丢失的现象,此时,文件系统也可以被恢复并被挂载。恢复NSD状态可使用如下命令:
mmchdisk 文件系统名 start -d “故障NSD1;故障NSD2;……;故障NSDn”
具体操作命令为:mmchdisk fs1 start -d “ft01_nsd4;ft01_nsd5;ft01_nsd6”。
执行完成后,检查NSD状态。如果NSD状态都是UP状态,则可执行mmumount fs1和mmmount fs1来恢复文件系统的正常运行。
若NSD状态仍是down或者unreacoverd,则表示文件系统仍存在问题,文件系统中的数据可能已经无法恢复。
在故障状态下,故障NSD已经无法与正常NSD同步数据,此时文件系统可以挂载,但无法对文件系统中的内容进行操作。为了恢复文件系统的正常运行,需要重建文件系统。重建文件系统会造成文件系统中的数据丢失,因此需要尽量备份文件系统数据。
为了尽可能备份文件系统中的数据,可以先屏蔽故障NSD,再尝试以只读模式挂载文件系统。由于文件系统缺少3个NSD,文件系统中的数据已经不完整,在备份数据过程中会出现数据不完整情况[15-19]。屏蔽故障NSD和以只读模式挂载文件系统命令如下:
屏蔽故障NSD:mmfsctl 文件系统名 exclude -d “故障NSD1;故障NSD2;故障NSD3”。
以只读模式挂载文件系统:mmmount 文件系统名-o rs。
3.2.3 重建GPFS文件系统
数据备份完成后,需要重建文件系统才能使文件系统恢复正常工作。重建文件系统时,文件系统中所有数据都将丢失。重建文件系统的步骤:删除故障文件系统,删除故障文件系统NSD,重建NSD,重建文件系统。具体命令如下:
(1)删除故障文件系统。
mmdelfs -p 故障文件系统名:删除故障文件系统,为重建系统做准备。
(2)删除故障文件系统NSD。
mmdelnsd “NSD1;NSD2;……NSDn”:更换故障硬盘后,为了重建故障文件系统,需要将该文件系统所有NSD硬盘初始化,因此需要先删除现有NSD,再进行NSD和文件系统的重建。
(3)重建NSD和重建文件系统。
具体操作可参考前文创建NSD和创建文件系统时的步骤,完成相关的操作后,即可重新使用该文件系统。
4 结束语
目前,GPFS并行文件系统广泛应用于各企事业单位。随着信息化的发展,各企事业单位需要结合自身情况来配置使用GPFS并行文件系统,保证数据能够被高效、安全地使用。因此,为了更加高效、稳定地使用各种数据,应该继续深入探讨GPFS并行文件系统相关内容,为更好地使用GPFS文件系统打下基础。
参考文献:
[1] 王 鸥,赵永彬.GPFS共享文件系统在企业门户系统中应用的研究[J].电脑知识与技术,2015,11(10):15-17.
[2] 张志坚,伍光胜,孙伟忠,等.IBMFlexP460高性能计算机系统及气象应用[J].现代计算机,2016(9):51-55.
[3] 庞丽萍,何飞跃,岳建辉,等.并行文件系统集中式元数据管理高可用系统设计[J].计算机工程与科学,2004,26(11):87-88.
[4] 肖 伟,赵以爽.并行文件系统简介及主流产品对比[J].邮电设计技术,2012(7):31-36.
[5] 杨 昕.GPFS文件系统原理和模式IO优化方法[J].气象科技,2006,34:27-30.
[6] 张 玺.并行文件系统下数据迁移功能的实现[J].北京信息科技大学学报:自然科学版,2012,27(5):77-80.
[7] 解宝琦,王金国.构建CentOS+GPFS集群[J].网络安全和信息化,2017(2):85-88.
[8] 叶雅泉.GPFS在省级通信系统中的应用[J].移动信息,2016(6):113.
[9] SCHMUCK F,HASKIN R L.GPFS:a shared-disk file system for large computing clusters[C]//Proceedings of the conference on file and storage technologies.Berkeley,CA,USA:USENIX Association,2002:231-244.
[10] PLANK J S.The Raid-6 Liber8Tion code[J].International Journal of High Performance Computing Applications,2009,23(3):242-251.
[11] CAULFIELD A M,SWANSON S.QuickSAN:a storage area network for fast,distributed,solid state disks[J].ACM SIGARCH Computer Architecture News,2013,41(3):464-474.
[12] 沈 瑜,孙 婧,李 娟.中国气象局高性能计算机系统高可靠性设计[J].信息安全与技术,2013,4(6):42-45.
[13] JONES T,KONIGES A E,YATES R K.Performance of the IBM general parallel file system[C]//Proceedings of the 14th international symposium on parallel and distributed processing.Cancún,Mexico:IEEE,2000:673-681.
[14] LIU Gia-Shie.Three m-failure group maintenance models for M/M/N unreliable queuing service systems[J].Computers & Industrial Engineering,2012,62(4):1011-1024.
[15] VIJZELAAR S,BOS H,FOKKINK W.Brief announcement:a shared disk on distributed storage[C]//Proceedings of the 29th ACM SIGACT-SIGOPS symposium on principles of distributed computing.Zürich,Switzerland:ACM,2010:79-80.
[19] SZELIGA B,NGUYEN T,SHI Weisong.DiSK:a distributed shared disk cache for HPC environments[C]//International conference on collaborative computing:networking,applications and worksharing.Washington D.C,USA:IEEE,2009:1-8.
猜你喜欢
娃娃乐园·综合智能(2022年3期)2022-04-19
电脑爱好者(2020年18期)2020-09-26
家庭影院技术(2020年7期)2020-08-24
家庭影院技术(2020年1期)2020-06-24
网络安全和信息化(2019年1期)2019-12-22
网络安全和信息化(2019年10期)2019-11-26
电脑爱好者(2019年2期)2019-10-30
网络安全和信息化(2019年7期)2019-07-10
军营文化天地(2018年2期)2018-04-20
电脑知识与技术(2017年14期)2017-07-10
