
基于聚类算法和神经网络的客户分类模型构建
2018-05-23 09:36蒲杰方卢荧玲
软件 2018年4期
蒲杰方,卢荧玲
(重庆工商大学 数学与统计学院,重庆 400067)
0 引言
在当今市场经济极度繁荣的情况下,每个客户的需要都各不相同,充分了解客户需求,有针对性的为客户提供产品,是企业在激烈的市场竞争中脱颖而出的必要条件。客户分类作为分析客户需求的关键步骤,对客户关系管理以及营销活动的开展具有重要意义,将具有相同或相似特点和需要的客户分到相同的类别,提供相同或相似的产品,最大化客户的需求。将具有不同特点或需求的客户划分到不同类别,提供差别化的产品和服务,实现产品的差异化和多样化。
客户分类的主要目的在于通过对银行客户的大量数据和信息处理,了解数据之中的隐含关系,挖掘其潜在信息,找到不同客户的不同特征,从而有针对性地为其提供产品。因而,分析客户的内在属性,挖掘客户特征,对客户进行分类,是客户管理最核心的内容[3]。关于客户分类的研究,国内外已经做了很多工作,Jon Anton[1]认为客户分类是将企业的客户和公司重要资源进行整合的过程;Bolton[2]将客户分类与客户满意度紧密地联系起来,指出客户分类的本质就是要让客户满意。国内外学者对聚类算法的研究主要有:Aronis[4]提出极大似然分类方法和K-means算法,是迄今为止应用最为广泛的数据挖掘算法;公丽艳[5]等人利用聚类算法对苹果加工品质进行评价,为苹果品种的培育和加工提供了理论支撑。神经网络方法研究主要有Hagan[7]研究了神经网络的学习规则;吕恩辉[8]等人提出了基于反卷积特征提取的神经网络方法。
1 客户分类模型的构建原理及算法
K-means聚类算法作为一种常用的数据挖掘技术,在实际的数据处理中扮演着举足轻重的作用,同时,它也是一种非监督机器学习,相对于有监督机器学习来说,聚类分析是在数据未知的情况下按照一定的分类标准对数据进行分类。通过聚类分析,从而将相似高的数据聚到一起,而差异性较大的数据被分到不同的组[6]。
把n个对象分为k类,K-means算法坚持的原则是:聚类内的相似性达到最高,同时聚类间的相似性达到最低,而相似性通常是按照样本之间的距离远近来度量。K-means算法的流程通常如下:首先随机地从n个对象中选取k个对象作为k个初始簇中心,计算其余对象到k个初始簇中心的距离,并将其赋给最近的簇;然后分别计算更新后的k个簇中对象的平均值,并将其作为新的簇中心。这个过程不断交替重复,直到平方误差准则函数最小,其形式如下所示:

其中,p表示n个样本对象中某一个对象,mi表示类iC的平均值(总共有k类),E表示所有对象与其所对应的的簇中心的距离平方和。
BP(Back Propagation)神经网络相对于上面提到的 k-means算法而言,是在数据信息已知的情况下进行有监督的学习。BP神经网络可以看成一个从输入层到输出层的非线性映射,输入值作为该函数的自变量,通过隐含层映射到输出层,输出层的结果可以视为该非线性函数的因变量[9]。
BP神经网络的学习过程采用最快梯度下降法,通过反向传播不断调整隐含层的阈值与权值,从而使得输出层的期望输出与实际输出的误差平方和达到最小。算法分为两个阶段:第一个阶段是向输入层输入学习样本,通过设置的隐含层的网络结构和参数,向后计算各神经元的输出,若输出层的期望输出与实际输出相差较大,则进入第二阶段;第二个阶段是从最后一层开始向前计算各个阈值和权重对总误差的影响大小,利用最快梯度下降法从最后一层开始对权值和阈值进行修正。以上两个阶段反复进行,直至收敛。
接下来,具体展示了BP神经模型的构建步骤,为了后文描述方便,给出所需变量定义如表1所示:

表1 变量定义Tab.1 Variable definitions
第一步,随机地给各权值赋予区间[-1,1]内的数值,设置网络结构,同时设定计算精度和最大学习次数。
第二步,随机地抽取k个样本,并记录其对应的特征输入值和期望输出值:
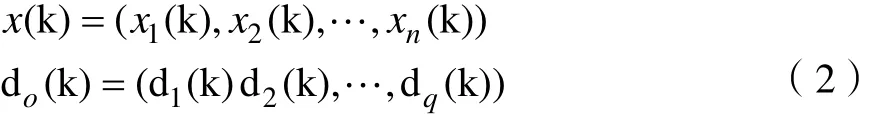
第三步,向前逐层计算隐含层各神经元的输入和输出:
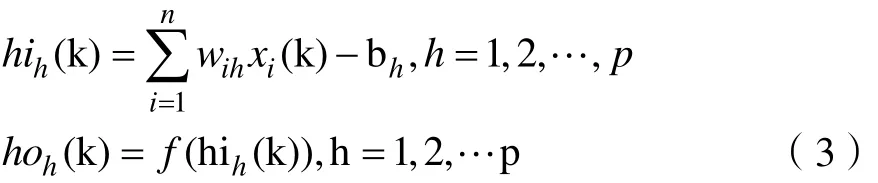
第四步,利用输出层实际输出结果和样本的期望输出值,计算误差函数对输出层各神经元的偏导数 δo(k):

由(4)式可以计算误差函数对隐含层与输出层的连接权值how 的导函数为:

第五步,利用第四步计算得到的 δo(k)和hoh(k),以及隐含层到输出层的连接权值,计算误差函数对隐含层各神经元的偏倒数 δh(k):

由(7)式可以计算误差函数对输入层与隐含层的连接权值ihw 的导函数为:

第六步,利用第四步计算得到的 who(k)和δo(k),选取最快梯度下降法将梯度从最后一层反向传播调整更新权值:

第九步,当全局误差达到预设精度的要求或者学习次数达到预设最大学习次数,算法终止,否则,循环第三步到第九步,直到收敛。
2 数据的选取及特征初步分析
考虑到国内银行对客户的隐私保护,数据无法获得,因此本文的数据来源于葡萄牙一家银行。收集的数据发生在2008年5月和2010年11月之间,数据包含40690个样本,每个样本包含17个特征属性,其中 16个为描述客户信用状况的相关属性指标。包括:年龄、职业类型、婚姻状况、教育水平、是否有信用卡违约、平均年存款、是否有住房贷款、是否有个人贷款、活动联系方式、最近一次联系的日期、最近一次联系的月份、上次接触的持续时间 、本次活动接触的次数、之前活动最后一次联系到现在的时间间隔、本次活动之前与该客户的接触次数、之前市场活动的效果。第17个指标是根据16个属性指标综合判断后对每个客户是否会订购定期存款的分类。
由于金融客户的数据库庞大而复杂,根据业务需求收集的大量客户数据中包含着很多重复的、不完整的和错误的数据,同时各指标的量纲不统一,因此不能够直接进行数据挖掘,需要对原始数据进行清洗、构造与标准化处理。数据的清洗主要是针对重复数据、缺失数据的处理,剔除不相关数据,同时将定性指标转化为定量指标;因为各个指标之间量纲不统一可能会对结果造成很大的误差,故需要对每个数据指标进行标准化处理。我们选取了最为常见的 z-score标准化方法对各特征指标进行标准化处理。标准化公式为:

其中,u和σ分别是样本数据的均值和标准差。
在建立预测模型之前,为了对数据有整体上的了解,我们先对几个重要的特征进行简单的描述性统计分析。
样本年龄分布情况以及各年龄段订购定期存款的比例如表 2所示,可以看出样本主要分布在26-35,36-35,46-55这三个年龄段,占总体的86.18%,其中分别占比34.24%,30.67%,21.09%。各年龄段订购定期存款的情况:从整体来看,40690个样本中,只有11.63%订购了定期存款;在年龄段16-25岁和大于65岁,订购定期存款的比例高于整体的比例;而年龄段 26-55岁订购的比例较低。导致这一现象的原因可能是:由于青年人和老年人,主要生活花费依靠父母或者子女,没有生活负担和较大的开支,所以更有可能将积蓄存在银行。而对于中年人,虽然大多数有固定的收入,但是要承担家庭中的各类开销,并且要抚养子女和赡养老人,所以可能没有多余的积蓄去订购存款。
接下来,我们分析工作类型对订购定期存款的影响,由于工作指标分类太多,大多工作类别相似,由上面11种不同工作性质,可以把工作类型大致分为:没有工作、中下收入水平、中上收入水平。从表3可以看出:没有工作的这类人群中,由于其中学生和退休人员占大多数,所以最后订购定期存款的比例21.56%与整体情况11.63%相比较高;中下收入水平的情况是最后订购定期存款的比例 8.80%,相比整体情况低;而中上收入水平的情况是最后订购定期存款的比例是12.70%,相比整体情况高。
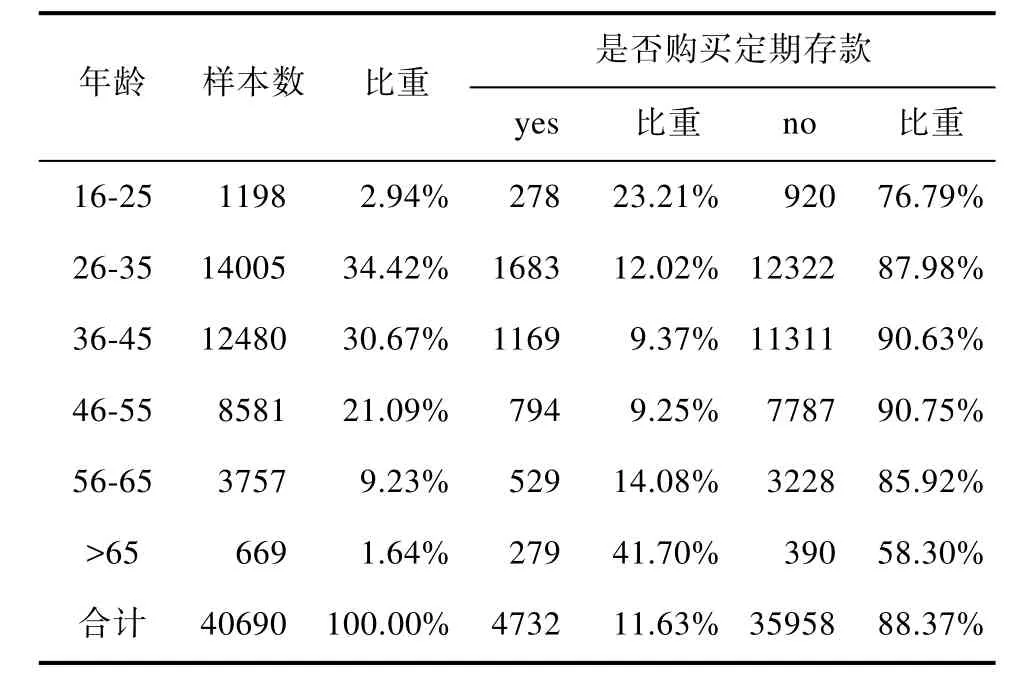
表2 样本年龄分布及订购情况Tab.2 Sample age distribution and order

表3 归类后的样本工作类型分布和订购情况Tab.3 Distribution and ordering of samples after classification
从婚姻状况来分析,样本分布情况和订购情况如表4所示:由表中的数据可以发现,单身者订购定期存款的比例较高,有21.31%;而结婚了的人订购定期存款的比只有 7.01%。这一现象的原因可能是由于结婚的人中可能大多数是中年人,他们要承担家庭的开销,而单身者中青年人占多数,所以没有什么负担。
同样对教育水平进行分析,结果如表5所示。订购定期存款的比例随着受教育水平的提高而增加。也许是因为受教育水平越高,工作收入水平越高。

表4 样本婚姻状况分布及订购情况Tab.4 Distribution of sample marital status and order

表5 样本受教育水平分布及订购情况Tab.5 Distribution of education level and order
对信用卡违约记录、住房贷款情况、个人贷款情况三者对购买定期存款的影响进行简单的统计分析。结果如表6所示:其中,在信用卡有违约记录、有住房贷款、有个人贷款的情况下,订购定期存款的比例相比整体水平低,所以可以得出是否有住房贷款和个人贷款、违约记录对是否订购定期存款有影响。

表6 样本各信贷指标下的分布及订购情况Tab.6 The distribution and order of sample credit indicators
3 实证模型
在40690个训练样本集中,有4519个客户样本是购买了定期存款的客户,利用 R3.4.2软件中k-means聚类算法包对这 4519个客户样本进行分类,得到最有可能购买定期存款的5类客户群体,由于联系方式对是否购买定期存款没有直接影响,故剔除。表7表示的5类客户群的聚类中心。
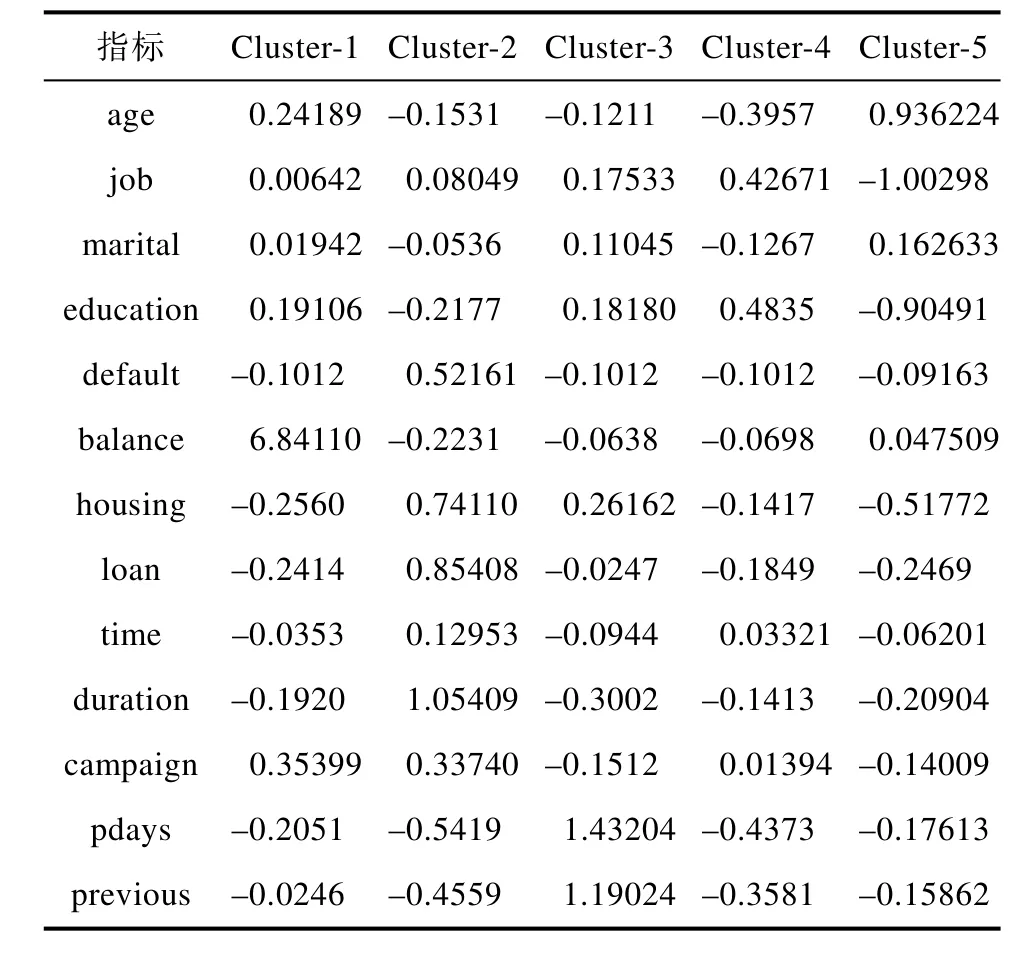
表7 聚类中心Tab.7 Cluster center
要利用聚类结果支持银行的经营决策,制定详细的营销方案,我们对这五类客户的具体特征进行分析。从聚类中可以看出五类在各个变量上均有较大差异。由于在聚类分析时输入的变量是经过标准化处理之后的,为了使聚类中心更直观,对聚类中心进行标准化还原,将其转化为原始数据的量纲形式。标准化还原公式为:

其中,μ和σ分别为样本数据的均值和标准差,x*为经过标准化还原处理后的样本数据,x为未标准化还原的数据。
转换成原始变量表达的聚类中心如表8所示。
接下来,将上面5类客户群的特征变量与变量均值作比较,具体分析每一类客户群的具体特征。下面选择了其中 3类客户群的比较结果,如表 9、表10、和表11所示。
根据表9可以明确的知道,这一类客户群体属于中年的技术人员,具有较高学历和较多存款,个人信用较好,没有违约记录,同时也没有贷款(个人贷款和住房贷款)。本次活动以及之前的活动接触均较多,上次活动距离现在的时间间隔也比较短。这说明这类客户是收入比较稳定,且拥有大量存款的人,个人信用也较好,因此,该类客户购买定期存款的可能性比较大。由于其收入较为稳定,生活也较为稳定,因此是银行的优质客户,银行应该对该类客户多加关注,针对地为其推荐适合的高份额资金的定期存款。
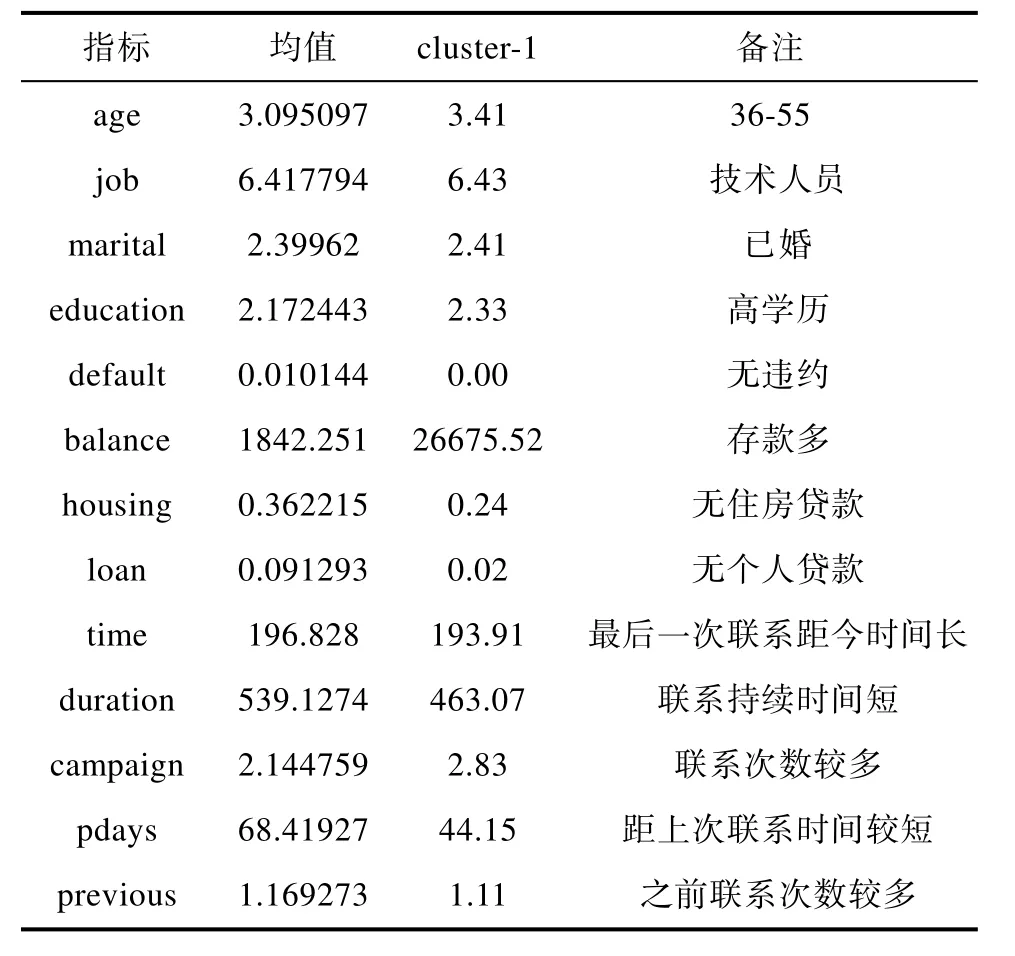
表9 客户群一Tab.9 Customer group 1
根据表10可以较为清楚地知道,这一类客户群体属于青年管理人员,具有较高学历,没有住房贷款和个人贷款,同时也没有违约经历,存款较多,本次活动接触较多,之前的接触较少,上次活动距离现在的时间比较短。这说明这类客户是属于年轻有为,事业正处于上升时期,收入比较稳定,且拥有一定量存款的人,同时个人信用也较好。银行可以将该类客户看作潜在优质客户,该类客户具有极大的上进心,对于新生事物的学习欲望和能力都较强,因此,银行应该为该类客户更多地推荐多元化的产品。
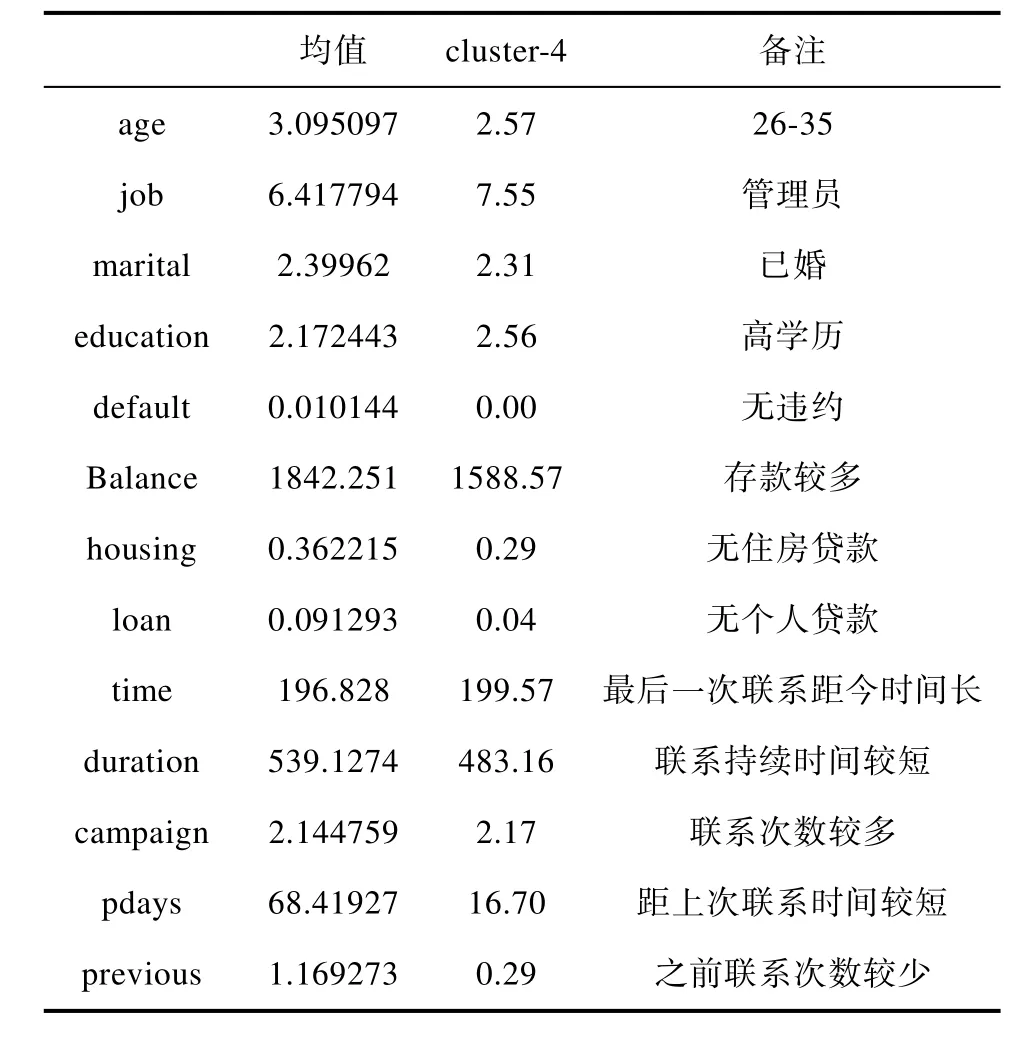
表10 客户群二Tab. 10 Customer group 2
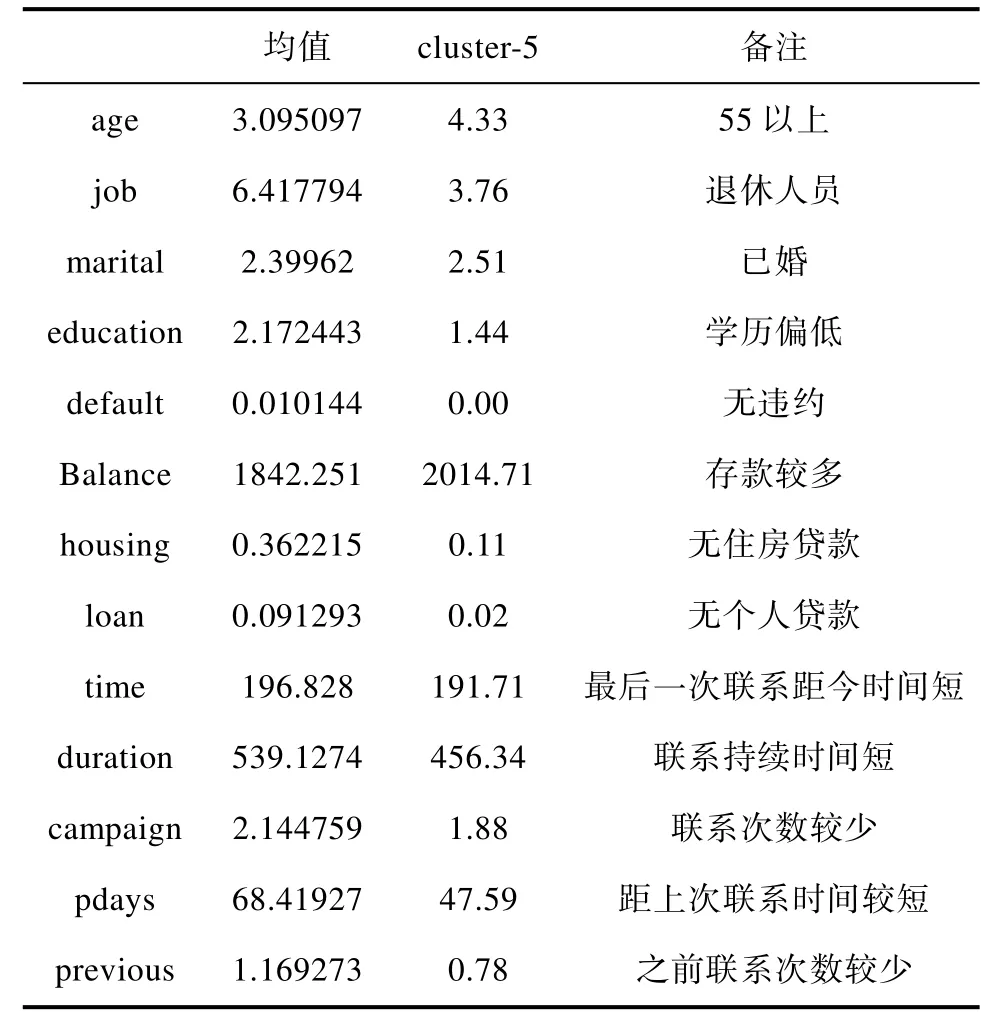
表11 客户群三Tab.11 Customer group 3
根据表11可以明确的知道,这一类客户群体年龄较大,属于退休了的老年人群,他们的学历普遍偏低,但拥有较多的资金,同时个人信用较好,且没有贷款(个人贷款和住房贷款),本次活动以及之前的活动接触均较少,上次活动距离现在的时间比较短。这说明这类客户大多是年纪较大的退休人群,该类客户虽然没有固定的收入来源,但是他们却拥有较多的存款,而且相对于年轻人的敢于挑战的精神,他们更多的是愿意接受安全性较高、收益稳定的产品。因此,该类客户有较大的概率购买定期存款。
最后,运用软件MATLAB建立三层BP神经网络预测模型,输入层神经元个数是14个,输出层神经元为1个,隐含层神经元个数为10个,学习次数500次,允许误差取为0.01。
为了更加直观、准确地检验所构建的 BP神经网络的有效性,我们接下来对样本集进行分割,训练样本集总共有40690个客户样本,将数据样本的70%作为训练集,剩下的 30%作为测试集,首先,对分割后的28418个训练集,采用 MATLAB神经网络工具箱学习训练网络,得到神经网络预测模型,模型的拟合效果如图1所示,模型收敛较快。将训练后的网络模型用于分割得到的12272个测试集,并将其预测值与实际值进行比较,比较结果如表12所示:

图1 误差曲线图Fig.1 Error curve

表12 预测结果与期望值比较分析Tab.12 Comparison and analysis of predicted and expected values
因此该 BP神经网络模型的精度可以由如下计算得到:

由式(15)计算得到该 BP神经网络模型的精确度为89.77%,这说明基于BP神经网络信用评价模型是有效的,并且,通过MATLAB软件可以快速的得出理想的判别结果,说明这个方法具有较高的准确性和可操作性。本文所利用的数据样本较大,因此具有一定的可信度。
基于以上研究表明,该 BP神经网络模型的适用性较强,可信度较高,可以将其运用到银行客户分类系统,有助于银行通过对不同客户属性和行为分析,为每一类客户群体有针对性的提供多元化的产品,在满足客户更多需求的同时,拓展银行业务,提高银行营销的效率和利润。
4 结束及建议
本文将BP神经网络模型和k-means聚类分析法结合起来运用于银行客户分类中,得出了有效结论:以下三类客户群体购买定期存款的可能性较大,第一类为收入稳定且无贷款的青年人,这类客户是属于年轻有为,事业正处于上升时期,收入比较稳定,且拥有一定量存款的人,同时个人信用也较好。银行可以将该类客户看作潜在优质客户,该类客户具有极大的上进心,对于新生事物的学习欲望和能力都较强,因此,银行应该为该类客户更多地推荐多元化的产品。第二类为退休的老年人,这类客户群体虽然没有固定的收入来源,但是他们却拥有较多的存款,没有较大生活开支,所以更有可能将积蓄用于订购定期存款,而且相对于年轻人的敢于挑战的精神,他们的风险偏好更低,因此更愿意接受收益比较稳定、风险较低的理财产品。因此,该类客户购买定期存款的可能性比较大。第三类为少数收入稳定且没有贷款的中年人,他们属于社会的中产阶级,具有稳定的高收入水平,是银行应该多加关注的优质客户,可以定期为其推荐或者设计有较稳定收益的高份额资金产品;而对大多数中年人来说,虽然有固定的收入,但是要承担家庭中的各类开销和住房贷款,并且要抚养子女和赡养老人,所以可能没有多余的积蓄订购定期存款。
参考文献
[1] Anton J. The past, present and future of customer access centers[J]. International Journal of Service Industry Management,2000, 11(2): 120-130.
[2] Bolton R N. A Dynamic Model of the Duration of the Customer's Relationship with a Continuous Service Provider: the Role of Satisfaction[J]. Marketing Science, 1998, 17(1): 45-65.
[3] 秦秀洁. 数据挖掘在银行客户关系管理中的应用研究[D].华南理工大学, 2014.
[4] Aronis J M.Provost F J. Increasing the Efficiency of Data Mining Algorithms with Breadth-First Marker Propagation[C]//1997: 59-63.
[5] 公丽艳, 孟宪军, 刘乃侨, 毕金峰.基于主成分和聚类分析的苹果加工品质评价[J]. 农业工程学报, 2014, 30(13):276-285.
[6] 李冰, 王悦, 刘永祥. 大数据环境下基于K-means的用户画像与智能推荐的应用[J]. 现代计算机(专业版), 2016,(24): 11-15.
[7] Hagan M T, Demuth B, Beale M. Neural Network Design[J].PWS Publishing Company Boston, 1996, 12(20): 25-45.
[8] 吕恩辉, 王雪松, 程玉虎. 基于反卷积特征提取的深度卷积神经网络学习[J/OL]. 控制与决策: 1-9[2018-01-09].https://doi.org/10.13195/j.kzyjc.2017.0048.
[9] 王宏涛, 孙剑伟. 基于BP神经网络和SVM的分类方法研究[J]. 软件, 2015, 36(11): 96-99.