
基于视频深度学习的时空双流人物动作识别模型
2018-05-21 00:50杨天明岳文静
计算机应用 2018年3期
杨天明,陈 志,岳文静
(1.南京邮电大学 计算机学院,南京 210023; 2.南京邮电大学 通信与信息工程学院,南京 210003)
0 引言
深度学习被运用于图片分类[1-3]、人物脸部识别[4]和人物位置预测[5]等识别领域。视频人物动作识别可看作随时间变化图片的分类问题,所以图片识别的深度学习方法也被大量使用在视频人物动作识别研究中[6-8]。与计算机视觉的其他领域相比,深度卷积神经网络(Convolutional Neural Network, CNN)在动作识别领域的表现并不突出,原因有以下两点:第一,现今视频数据集较小并且噪声信息较多。视频中目标的移动以及视角的变化增加了动作识别的难度,所以需要比图片识别更多的训练样本。图片数据集ImageNet每一类具有1 000个例子,而视频数据集比如佛罗里达大学YouTube行为数据集(University of Central Florida YouTube action dataset 101, UCF101)每一类仅仅有100个例子,比图片数据集少很多。第二,传统卷积神经网络结构不能充分地提取时间特征。视频是一种按时变化数据,任意像素与其邻域像素之间的相似性很大,具有很强的时间相关性与空间相关性,具有时空特征。然而卷积神经网络通常用于单一、静止的图片,不能有效地提取出连续帧之间的关联特征。
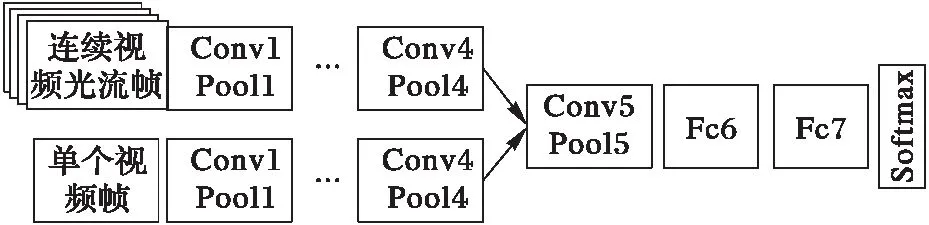
为了利用视频的时间特征,文献[9]提出了一种时空双流结构,该结构包含两个并行卷积神经网络结构。两个卷积神经网络分别以等间隔抽样视频帧和视频的一系列光流图片作为输入,提取视频人物动作的空间以及时间信息,最后将这两方面信息融合用以辨别视频人物动作类别;同时该结构也表明了仅仅通过光流信息也能够辨别数据集UCF101中的大部分人物动作。虽然该结构在一定程度上利用了视频的时间特征,但识别准确度仍然不高。
为了解决上述问题,本文在时空双流识别模型的基础上,提出了一种3D卷积神经网络模型。该模型首先利用两个卷积神经网络分别抽取视频人物动作片段的空间以及时间特征;接着融合这两个卷积神经网络提取的特征,并将融合后的特征输入到3D卷积神经网络中完成视频中人物动作的识别。本文在数据集UCF101以及人物行为数据集(Human Motion DataBase, HMDB51)上进行视频人物动作识别实验,实验结果表明本文提出的基于时空双流的3D卷积神经网络模型能够有效地识别视频人物动作。此网络模型能够同时学习静态图片内容的信息以及视频人物运动信息,并且能够将这两个特征进行融合进而提取时空相关性信息。
1 相关工作
利用卷积神经网络(CNN)提取利用视频的时间信息一直是视频人物动作识别的难点。卷积神经网络比较适用于提取单一静态图片的特征,对于视频的时间信息不是特别的敏感。然而用于静态图片识别的卷积神经网络的发展在很大程度上促进了视频识别领域的发展,近些年来众多CNN的调整方法被提出来,使得CNN能够在一定程度上利用视频的时间信息。
为了能够让CNN的第一层就能够学习到视频的时空特征,相关文献提出了修改卷积神经网络输入的方法。文献[10]中提出了将一定数量连续的视频帧作为CNN的输入。与文献[10]的视频帧的简单叠加不同,文献[11]更进一步地提出了多种时间域上视频帧采样融合方法,其中:早期融合(early fusion)与文献[10]中提出的方法相同,缓慢融合(slow fusion)是一种逐层次地增加神经网络输入时间域长的方法,晚期融合(late fusion)方法融合了时间域间隔一定长度不同视频帧对应CNN的全连接层。与单一空间卷积神经网络相比,上述视频识别方法在准确率上只是略有提升,说明上述研究方法没有充分地利用视频的时间信息。
文献[12]提出3D卷积神经网络结构,该结构是原先2D神经网络在时间维度上的一种扩展,使得可以学习视频片段时间上的特征。这种神经网络结构使用若干个连续的视频帧作为输入,使用大小为3×3×3卷积核学习视频的时空特征。实验结果表明这种结构的准确率比文献[10]提出的多种输入视频帧融合方法更高;但是这种结构是一种更加深度的结构,实验训练与测试的过程中需要占用更多的资源。

图2 空间流卷积神经网络结构 Fig. 2 Framework of spatial convolutional neural network
文献[9]提出了时空双流深度学习策略,用来分别提取视频的空间信息与时间信息,最后将这两个信息融合,其具体结构如图1所示。首先提取视频的RGB帧和连续视频光流帧,将视频分解成空间与时间元素。然后将这两个元素分别输入到两个独立的深度卷积神经网络当中,来学习场景中运动目标外形以及动作的空间以及时间信息。用这两个流分别进行视频行为动作的识别,在最后将softmax层的分数通过晚期融合(late fusion)的方式进行合并[11]。文献[9]比较了不同的连续光流帧融合方法,得出结论:连续的10帧的水平光流场与竖直的光流场表现最好。相比传统的视频人物动作识别方法,该方法有效地融合了视频的时间信息,但是仍然存在以下的问题:
问题1 文献[9]提出的深度学习结构的输入量太少,仅仅是单个光流帧以及若干个时间域上等间隔抽样的光流。
问题2 文献[9]提出的空间特征与时间特征的融合仅仅是在最后的softmax层进行融合,没有考虑到空间与时间特征之间的关联性以及这些关联如何随着时间变化。
问题3 文献[13]自编码学习过程产生的参数数量太多,增加了深度学习的难度。
基于上述方面的考虑,本文对于文献[9]提出的时空双流深度学习模型的改进基础上,引入了3D卷积神经网络,提出一种基于视频深度学习的时空双流视频人物动作识别模型(Spatio-temporal Convolutional Neural Network based on 3D-gradients, Spatiotemporal-3DCNN)。
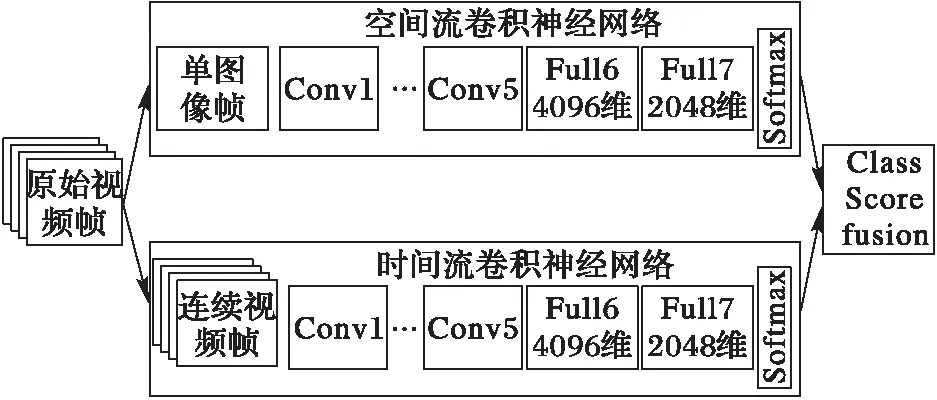
图1 时空双流卷积神经网络结构 Fig. 1 Framework of spatio-temporal two-stream convolutional neural network
2 时空双流人物动作识别模型设计
2.1 相关工作
2.1.1 空间流卷积神经网络
空间流卷积神经网络的输入是单个视频帧,它是一种通过提取静态图片信息来完成视频人物动作识别的深度学习模型。静态的外形特征是一个非常有用的信息,因为视频人物的某些行为动作与某些物体有着密切的关联性。通过后面章节的实验也可得知,仅仅通过空间流卷积神经网络也能够完成部分视频人物动作的识别。空间流卷积神经网络在本质上属于一种图片分类结构,本文所述的空间流卷积神经网络结构使用的是文献[14]中的图片分类卷积神经网络,其具体结构采用的是牛津大学视觉几何组(Visual Geometry Group,VGG)开发的VGG-M-2048模型,如图2所示,并且该结构会在图片数据集进行预训练。
2.1.2 时间流卷积神经网络
时间流神经网络结构如图3所示,同样也是采用的是VGG-M-2048模型。与空间流卷积神经网络不同,时间流卷积神经网络输入的是若干连续视频帧之间的光流图片。光流图片可以理解为连续视频帧之间的像素点位移场,显式地表述了视频的运动信息,有效地提取了视频的时间特征,提高了视频人物动作识别的准确率。本文中把用于输入的若干连续光流图片称为光流栈。光流栈的具体描述如下:
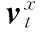
a=[1;ω],b=[1;h],k=[1;L]
(1)
其中ω和h分别表示视频的像素长度与像素宽度。

图3 时间流卷积神经网络结构 Fig. 1 Framework of temporal convolutional neural network
2.2 整体架构设计
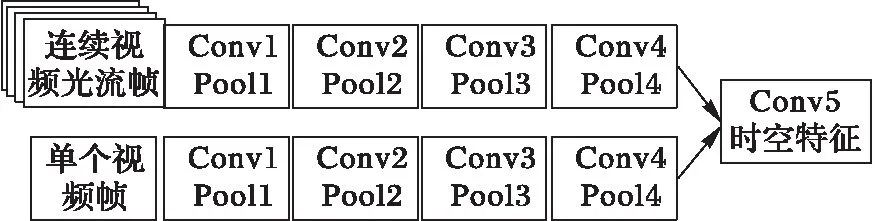
本文提出的Spatiotemporal-3DCNN框架如图4所示。该模型主要包括三个模块:空间特征与时间特征的提取、空间特征与时间特征的融合、基于3D卷积神经网络的视频人物动作识别。首先,分别训练两个2D卷积神经网络流,用来分别提取视频的空间特征与时间特征;之后,将空间流与时间流网络进行再卷积进行融合,并对参数进行微调,用于提取视频时空中层特征;最后,通过3D卷积神经网络模型完成视频人物动作的识别。
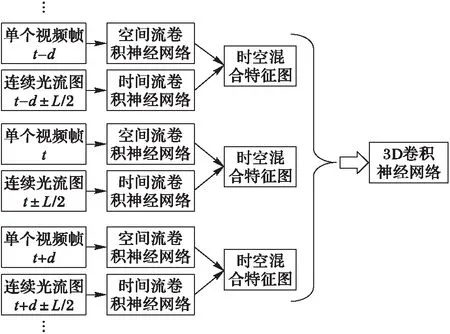
图4 Spatiotemporal-3DCNN框架 Fig. 4 Framework of spatiotemporal-3DCNN
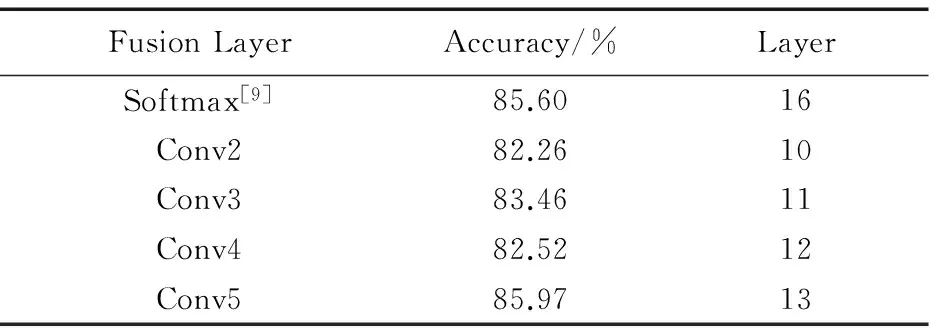
Spatiotemporal-3DCNN包含T个时空流。空间流的输入的是视频帧,从视频片段的时间t开始以时间域距离d进行等间隔取样,将在时间t,t+d,…,t+Td的视频帧作为输入。时间流对应的输入是连续光流帧,在时间t时刻对应的连续光流帧图片在时间域上的位置是(t-L/2,t+L/2)。通过融合得到在时间域上连续的T个时空特征图,并且光流域的长度L和空间流视频帧的取样间隔d必定满足关系L Spatiotemporal-3DCNN利用3D卷积神经网络对2D时空双流卷积神经网络在时间轴上的进一步扩展,充分利用了视频的时间信息。这里时空双流卷积神经没有使用全连接层最后的特征融合,因为全连接层输出的是高层特征会丢失图像特征在时间轴上的信息。将时空双流在卷积层(Conv5)的时空特征进行融合得到的特征图作为3D卷积神经网络的输入,提高了时空特征在像素点上的关联性,因为在模型输入中加入了光流图片,提高了处理静态图像视频帧采样的鲁棒性,每一秒的采样都会都是帧图像的所隐含的运动信息,而光流特征可以作为补偿。接着3D卷积神经网络对同一人物动作视频的不同时间片段的时空特征图进行3D卷积与池化进一步提取了时间信息。 时空网络的融合在于使用视频的空间特征与时间特征的关联性判断人物的行为动作。比如对于梳头与刷牙两个行为动作,空间流网络识别出了静态的物体头发与牙齿,时间流网络识别出了在一定的空间位置手部进行周期性的运动,结合这两个网络可以分辨梳头和刷牙这两个人物动作。本节从时空双流的融合位置角度阐述时空双流卷积神经网络融合策略。 时空融合位置如下。 神经网络之间的融合不是简单地将一个神经网络叠加到另一个神经网络:首先要考虑的是特征图的大小是否一致,如果不一致需要对较小的特征图进行上采样;接着还要考虑空间流卷积神经网络与时间流卷积神经网络通道之间的对应关系。本文所述的结构使用的时空融合方法具体可用如下公式进行描述: ysum=fsum(ma,mb) (2) (3) 式(2)表示将两个网络的特征图ma∈RH×W×D和mb∈RH′×W′×D′通过求和的方式将两个网络的特征融合成一个新的特征图ysum∈RH″×W″×D″,其中:H表示特征图的高度,W表示特征图的宽度,D表示特征图通道数,并且满足关系H=H′=H″,W=W′=W″,D=D′=D″。该公式能够被应用于卷积层、全连接层及池化层的融合。 式(3)具体描述了如何使用求和的方法在第d通道特征图的像素点(i,j)处进行融合,其中1≤i≤H, 1≤j≤W,1≤d≤D,ma,mb,y∈RH×W×D。 图5 时空双流融合网络结构 Fig. 5 Framework of spatio-temporal fusion convolutional neural network 图6 时空特征提取模型结构 Fig. 6 Framework of spatio-temporal feature extraction model 本节提出的3D卷积神经网络模型如图7所示,这种网络结构包含5个卷积层、5个池化层、2个全连接层以及一个识别视频行为动作的softmax损失层。这5个卷积层所使用的卷积核的数量依次是64,128,256,256,256。与传统的卷积神经网络不同的是,3D卷积神经网络不仅仅对空间的水平与竖直维度进行卷积,同时将时间维度也考虑在内进行3D卷积,所有的3D卷积核的大小都是3×3×3,在空间与时间维度上的深度都是3,并且在时间与空间维度的跨度是1×1×1。池化层采用的池化方法是max pool,3D池化核的大小都是2×2×2,在空间与时间维度上的深度都是2,在时间与空间维度上的跨度是1×1×1。3D卷积神经网络的第一层输入是由时空双流结构提取的T个中层时空特征图M∈RH×W×D×T,其中H是时空特征图的高度,W是时空特征图的宽度,D是时空特征图的通道数。最后的两个全连接层都是2 048维的特征向量。 图7 3D卷积神经网络结构 Fig. 7 Framework of convolutional neural network based on 3D-gradients 本节实验的数据集来源于两个有名的视频动作识别数据集:UCF-101与HMDB51[15]。UCF-101是目前动作类别数、样本数最多的数据库之一,一共包含13 320段视频样本101个视频类别,其数据库样本来自从BBC/ESPN的广播电视频道收集的各类运动样本,以及从互联网尤其是视频网站YouTube上下载而来的样本。HMDB51数据集包含6 849段视频样本51个视频类别,视频多数来自于电影,小部分来自于公共数据库以及YouTube等网络视频库。本文将这两个数据集都分成3份训练集与测试集进行实验,通过计算同一数据集3次实验的准确率的平均值作为最终的实验结果。 本文提出的Spatiotemporal-3DCNN模型的主要实验过程,主要分为三大步: 1)预训练空间与时间流卷积神经网络。 使用两个预先训练的图片分类模型来单独训练空间流卷积神经神经网络和时间流卷积神经网络。VGG-M-2048模型具有5个卷积层和3个全连接层,结构更深层的牛津大学视觉几何组(Visual Geometry Group,VGG)开发的VGG-16模型具有13个卷积层和3个全连接层。在训练空间流卷积神经网络的过程中,使用单个视频帧图像对预先在图片数据库ImageNet上训练的模型进行训练,输入的是大小为224×224视频帧随机位置裁剪的子图,并且对这个子图进行水平翻转和RGB随机颜色抖动增加训练的数据。在时间流卷积神经网络的训练过程中,同样也使用了图像分类模型进行训练,输入立方体是大小为224×224×2L在原光流图像上随机位置裁剪的连续子视频光流帧。根据文献[9]中的结论,将光流在时间域上的长度设置为L=10表现效果最好。将丢失率设置为0.85,初始的学习率设置为10-2,在第30 000次迭代后每20 000次迭代将学习率缩小为原先的1/10,在迭代80 000次后停止训练。 2)训练时空混合卷积神经网络。 在上述空间流与时间流卷积神经网络的基础上进行时空双流融合网络的训练。实验过程中将会尝试在不同的卷积层进行融合,并且通过上采样的方法使两个神经网络的特征图分辨率大小一致。没有在全连接层进行融合是因为全连接层在某些程度上已经破坏了时间与空间特征,不能有效地提高识别准确率。在训练的过程中,每一批的大小设置为96,通过反向传播对融合后的结构参数进行微调。初始的学习率设置为10-3,在迭代14 000次后学习率降为10-4,在迭代30 000次后停止训练。训练完成后的时空融合结构可被用于初步提取时空融合特征。 3)基于3D卷积神经网络进行人物动作识别。 将由时空混合卷积神经网络提取到的中层时空特征输入到3D卷积神经网络当中进行训练,这个过程中进一步提取利用的时间特征并且完成人物动作的识别。将连续等间隔时间段的时空特征图作为3D卷积神经网络的输入,抽样的起始时间随机选取,时间段个数取值为T=5,并且每个融合的时空特征图共有1 024个特征通道。3D卷积核的大小为3×3×3并且在第一个卷积层共有64个卷积核。3D卷积神经网络比较容易过拟合,所以丢失设置较高为0.9。初始的学习率设置为0.003,每150 000次迭代会将学习率除以2,当迭代次数达到1 900 000时停止训练。 实验过程中采用了两个数据库UCF-101和HMDB-51,并将它们分成3份,每份UCF-101数据集包含9 500个训练视频,每份HMDB-51包含3 700个训练视频。对数据集分成的3份内容都进行训练与测试,得到3个视频人物动作识别准确率,将得到的3个识别准确率的加权平均值作为视频人物动作识别模型的定量评估指标。 通过VGG-M-2048模型来分别提取RGB图像特征与光流图像特征,对于在不同位置融合时空双流结构的动作识别准确率如表1所示。由表1可知双流在卷积层进行融合时,从Conv1层到Conv5层动作识别的准确率逐步提升,说明在卷积层中更深层的融合能够更加有效地利用时空信息。同时表1给出了文献[9]提出的时空双流卷积神经网络的识别准确率,该结构在softmax层进行融合,结果表明在卷积层(Conv5)融合的结构略优于在softmax层融合的结构。本文提出的时空域3D卷积神经网络模型,都将在最深层次的卷积层进行融合提取中层时空特征图。本文最终的模型使用更深层的神经网络模型VGG-16模型来提取中层融合时空信息,之后将提取到的中层时空信息输入到3D卷积神经网络中。将提出的时空域3D卷积神经网络模型与文献[16]提出的长周期循环卷积神经网络(Long-term Recurrent Convolutional Network, LRCN)模型、文献[12]提出的3D卷积神经网络(Convolutional neural network based on 3D-gradients, C3D)模型、文献[9]提出的双流卷积神经网络(Two-Stream Convolutional neural network, Two-Stream ConvNet)模型和在文献[17]提出的因式分解卷积神经网络(Factorized Convolutional neural Network, Factorized ConvNet)模型进行了对比。从表2可以看出单个的时间流与空间流卷积神经网络也能够识别部分视频人物动作,并且可以看出本文提出的时空双流3D卷积神经网络模型能够更加精确地识别出视频人物动作。 表1 双流结构在不同融合位置的比较(VGG-M-2048模型)Tab. 1 Comparison of two-stream convolutional neural network fused in different layers (VGG-M-2048 model) 表2 本文人物动作识别方法与其他方法的准确率比较 %Tab. 2 Accuracy comparison of human action recognition method presented in this article with others % 图8为数据集部分视频中人物动作识别正确案例的展示。视频(a)(b)(c)表示了刷牙、剃胡子与头部按摩三种相似的人物动作,视频(d)(e)(f)表示了三种常见的体育运动。 图8 数据集部分视频中人物动作识别正确案例 Fig. 8 Some correct cases of human action recognition in dataset 本文提出了一种基于视频深度学习的时空双流人物动作识别模型,来完成视频中的人物动作识别任务。该模型先利用预先训练好的图片分类模型训练空间流与时间流卷积神经网络,并在最深层次的卷积层进行时空双流的融合,完成中层时空特征信息的提取;再将提取的中层时空特征信息输入到3D卷积神经网络中,来完成识别视频人物动作识别任务。实验表明本文提出的动作学习模型能够比较有效地识别出部分视频中人物简单的动作。 但是,本文模型仍存在很多不足之处需要改进与提高,比如:视频中的音频、文本等固有信息没有被充分地利用与考虑;以及当视频出现多人物并且存在互相遮挡,这些都是识别视频中人物语义的重要线索[18-19],如果可以很好地利用与融合这些线索信息,对视频中人物动作的识别能力必定会得到很大的提升。后面本人将会继续研究怎么利用与融合视频中更多语义线索。 参考文献(References) [1] 唐宋, 陈利娟, 陈志贤, 等. 基于目标域局部近邻几何信息的域自适应图像分类方法[J]. 计算机应用, 2017, 37(4): 1164-1168.(TANG S, CHEN L J, CHEN Z X, et al. Domain adaptation image classification based on target local-neighbor geometrical information [J]. Journal of Computer Applications, 2017, 37(4): 1164-1168.) [2] XIONG H, YU W, YANG X, et al. Learning the conformal transformation kernel for image recognition [J]. IEEE Transactions on Neural Networks and Learning Systems, 2017, 28(1): 149-163. [3] SZEGEDY C, LIU W, JIA Y, et al. Going deeper with convolutions [C] // Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2015: 1-9. [4] SCHROFF F, KALENICHENKO D, PHILBIN J. FaceNet: a unified embedding for face recognition and clustering [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2015: 815-823. [5] TOMPSON J, GOROSHIN R, JAIN A, et al. Efficient object localization using convolutional networks [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2015: 648-656. [6] ZHANG J, HAN Y, TANG J, et al. Semi-supervised image-to-video adaptation for video action recognition [J]. IEEE Transactions on Cybernetics, 2016, 47(4): 960-973. [7] LIU L, SHAO L, LI X, et al. Learning spatio-temporal representations for action recognition: a genetic programming approach [J]. IEEE Transactions on Cybernetics, 2016, 46(1): 158-170. [8] HUSAIN F, DELLEN B, TORRAS C. Action recognition based on efficient deep feature learning in the spatio-temporal domain [J]. IEEE Robotics and Automation Letters, 2016, 1(2): 984-991. [9] SIMONYAN K, ZISSERMAN A. Two-stream convolutional networks for action recognition in videos [EB/OL]. [2017- 05- 06]. http://www.datascienceassn.org/sites/default/files/Two-Stream%20Convolutional%20Networks%20for%20Action%20Recognition%20in%20Videos.pdf. [10] JI S, YANG M, YU K, et al. 3D convolutional neural networks for human action recognition [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(1): 221-231. [11] KARPATHY A, TODERICI G, SHETTY S, et al. Large-scale video classification with convolutional neural networks [C]// CVPR ’14: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2014: 1725-1732. [12] TRAN D, BOURDEV L, FERGUS R, et al. Learning spatiotemporal features with 3D convolutional networks [C]// ICCV ’15: Proceedings of the 2015 IEEE International Conference on Computer Vision. Washington, DC: IEEE Computer Society, 2015: 4489-4497. [13] DONAHUE J, JIA Y, VINYALS O, et al. DeCAF: a deep convolutional activetion feature for generic visual recognition [EB/OL]. [2017- 05- 09]. https://people.eecs.berkeley.edu/~nzhang/papers/icml14_decaf.pdf. [14] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks [EB/OL]. [2017- 05- 07]. http://xanadu.cs.sjsu.edu/~drtylin/classes/cs267_old/ImageNet%20DNN%20NIPS2012(2).pdf. [15] KUEHNE H, JHUANG H, GARROTE E, et al. HMDB: a large video database for human motion recognition [C]// ICCV ’11: Proceedings of the 2011 International Conference on Computer Vision. Washington, DC: IEEE Computer Society, 2011: 2556-2563. [16] DONAHUE J, HENDRICKS L A, GUADARRAMA S, et al. Long-term recurrent convolutional networks for visual recognition and description [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2015: 2625-2634. [17] SUN L, JIA K, YEUNG D Y, et al. Human action recognition using factorized spatio-temporal convolutional networks [C]//Proceedings of the 2015 IEEE International Conference on Computer Vision. Washington, DC: IEEE Computer Society, 2015: 4597-4605. [18] NAHA S, WANG Y. Beyond verbs: understanding actions in videos with text [C]// Proceedings of the 2016 23rd International Conference on Pattern Recognition. Piscataway, NJ: IEEE, 2016: 1833-1838. [19] HU R, XU H, ROHRBACH M, et al. Natural language object retrieval [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2016: 4555-4564. This work is partially supported by the National Natural Science Foundation of China (61501253), the Basic Research Program of Jiangsu Province (Natural Science Foundation) (BK20151506), the 11th Six Talent Peaks Program of Jiangsu Province (XXRJ-009), the Key Research and Development Program (Social Development) of Jiangsu Province (BE2016778), the Scientific Research Foundation of Nanjing University of Posts and Telecommunications (NY217054). YANGTianming, born in 1993, M. S. candidate. His research interests include machine learning, video data mining. CHENZhi, born in 1978, Ph. D., professor. His research interests include sensor network, cyber-physical system, machine learning, data mining, Agent and multi-Agent system. YUEWenjing, born in 1982, Ph. D., associate professor. Her research interests include cognitive radio network, data mining.2.3 时空融合策略
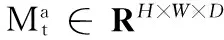
2.4 基于3D卷积神经网络的视频人物动作识别

3 实验分析
3.1 实验设计
3.2 结果分析


4 结语
猜你喜欢
现代经济信息(2022年22期)2022-11-13
中小学校长(2022年7期)2022-08-19
四川党的建设(2022年8期)2022-04-28
作文大王·低年级(2022年2期)2022-02-28
北京航空航天大学学报(2021年9期)2021-11-02
小学生学习指导(低年级)(2020年11期)2020-12-14
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
作文大王·低年级(2018年10期)2018-12-06
动漫星空(兴趣英语)(2018年9期)2018-10-30
