
基于Good-Turing平滑SO-PMI算法构建微博情感词典方法的研究
2018-05-18 07:58姜伶伶何中市张航
现代计算机 2018年10期
姜伶伶,何中市,张航
(重庆大学计算机学院,重庆 400044)
0 引言
互联网时代的快速发展,尤其是Web2.0的蓬勃发展,加强了网站与用户之间的互动,为人们获取信息、发表意见和交流情感提供了新的渠道。自然语言处理领域中的一个重要的研究分支是文本情感分析,在微博盛行的今天,大量的学者致力于微博文本情感分析的研究。
微博文本情感分析的质量取决于情感词典的质量,好的情感词典需要包含最新的情感词语,因此必须保证情感词典的实时更新。在构建情感词典时,情感词典[1-2]的自动扩充有着巨大的研究意义。
在微博情感分析中,微博情感词典的构建具有重要的研究意义和使用价值。在情感词典的自动扩充中,对候选情感词的倾向性判断是重点也是难点。在计算情感词的倾向性时,目前通用的两种方法分别是基于语义相似度的计算方法[3]与基于统计的计算方法[4]。文献[5]将HowNet和NTUSD两种词典进行合并从而构建了一个带有情感倾向性程度的情感词典。文献[6]在构建情感词典时考虑了上下文相关性。文献[7]提出了一种在HowNet的基础上使用PMI计算词语极性扩展词典的方法。文献[8]提出了一种拉普拉斯平滑的SO-PMI算法计算候选情感词与种子词的互信息。基于HowNet的语义相似度计算方法[9]以及基于SO-PMI的情感倾向性计算方法[10]首先选取若干正面种子词和若干负面种子词,基于HowNet的语义相似度计算方法[9]需要计算上述选取的正、负面种子词与待分类词语的相似度,基于SO-PMI的情感倾向性计算方法[10]需要计算上述选取的正、负面种子词与待分类词语的互信息。中文微博中存在大量的新词无法在HowNet中找到义原,从而也无法计算词语与义原的相似度。因此基于HowNet的语义相似度计算方法不适用于中文微博的候选情感词倾向性判断。
基于SO-PMI的方法[11]需要计算候选情感词与正、负种子词的互信息,由于微博是短文本,因此微博中候选情感词与正、负种子词的共现频次为0的概率较大,在出现零概率问题时无法计算候选情感词与正、负种子词间的互信息,从而无法判断候选情感词的极性。针对这一问题,本文在已有情感词典资源的基础上,提出了一种基于Good-Turing平滑SO-PMI算法的微博情感词典构建方法。
1 Good-Turing简介
Good-Turing基本思想:通过用高频计数的N元语法重新估计0计数或者低频计数的N元语法发生的概率。对于任何发生r次数的N元语法,都假设它发生了r*次。

式中:
Nr是训练语料中正好发生r次的N元组的个数;
Nr+1是训练语料中正好发生r+1次的N元组的个数。
即,发生r次的N元组的调整由发生r次的N元组与发生r+1次的N元组两个类别共同决定,统计数为r*词的N元组。
2 SO-PMI算法
通常用点互信息(PMI)这个指标来衡量两个事物之间的相关性,两个事物同时出现的概率越大,其相关性越大。
两个词语word1与word2的PMI值计算公式为:

p(w ord1word2)表示两个词语word1与word2共同出现的概率,可转化为word1与word2共同出现的文档数与总文档数的比值,如式:

p(w ord1)与p(w ord2)分别表示两个词语单独出现的概率,可转化为word1和word2出现的文档数与总文档数的比值,如式:

式(3)~(5)中:
count(w ord1,word2)为词word1与词word2共同出现的文档数;
count(w ord1)为词word1出现的文档数;
count(w ord2)为词word2出现的文档数;
q为总文档数。
word1与word2共现的概率越大,两者关联度越大,反之,关联度越小。
其值可以转化为以下3种状态:
p(w ord1word2)>0,两个词语是相关的;
p(w ord1word2)=0,两个词语是统计独立的,不相关也不互斥;
p(w ord1word2)<0,两个词语是互斥的。
情感倾向点互信息算法(SO-PMI)是将PMI方法引入计算词语的情感倾向中。SO-PMI算法的基本思想是:分别选取一组正向种子词Pwords和一组负向种子词Nwords。每个种子词必须具有明显的倾向性。计算候选情感词word跟Pwords的点间互信息与word跟Nwords的点间互信息的差值,根据该差值判断词语word的情感倾向。计算公式如式(6)所示。

将0作为阈值,得到以下三种情况:
SO-PMI(word)>0,为正面倾向,即 word是褒义词;
SO-PMI(word)=0,为中性倾向,即 word是中性词;
SO-PMI(word)<0,为负面倾向,即 word是贬义词。
3 情感词典
情感词典是词的集合,包含一组情感词以及对应的情感倾向性程度值。目前常用的公共情感词典有知网(HowNet)发布的情感词典、大连理工大学情感本体、台湾大学自然语言处理实验室提供的简体中文情感词典(National Taiwan University Sentiment Dictionary,NTUSD)、《学生褒贬义词典》等,这些公共的情感词典是情感分类研究的重要基础。但已有的公共情感词典对中文微博中涌现出的大量网络新词覆盖率较低,已经无法满足我们的需求,因此,本文提出一种基于Good-Turing平滑的SO-PMI算法用于微博情感词典的构建。
4 基于Good-Turing平滑SO-PMI算法的微博情感词典构建
4.1 基础情感词典的构建
本文首先将现有情感词典《大连理工大学情感本体》和《知网》进行合并,并去除重复的情感词得到微博技术情感词典,如表1所示。

表1 微博基础情感词典
表1中,HowNet为知网情感词典,Dalian为大连理工大学情感本体,Base为整理后组成的微博基础情感词典。
4.2 候选微博情感词的提取
候选微博情感词指微博中可能含有情感倾向的词语,主要以名词、动词、形容词、副词的形式存在。首先,使用ICTCLAS对COAE2014任务四的测评语料中随机抽取的200条微博进行切词处理,提取词性为noun、verb、adjective、adverb的词;人工筛选出带有情感的待入选候选微博情感词;然后过滤掉微博基础情感词典Base中已有的正、负极情感词;则剩下的词即为候选微博情感词,将该类词存入dic_w,记为dic_w={C1,C2,…,Cn}。
4.3 候选微博情感词倾向性的判断
使用基于SO-PMI的方法判断候选情感词倾向性时,需要计算候选情感词与正、负种子词的互信息,因此需要选取正、负情感种子词。由于微博属于短文本,词频较高的情感词文档频率不一定高。若种子词在微博文档中出现的频率很低会导致微博候选情感词与种子词共现的频次较低,此时出现零概率事件,无法计算候选情感词的互信息。因此,本文提出选取文档频次较高的情感词作为种子词。
当微博候选情感词和种子词在整个语料中共现的频次为0时,根据公式(2)无法计算候选情感词和种子词的互信息,此时无法对候选情感词的倾向性进行判断。基于此问题,本文对SO-PMI算法进行了如下改进:
选取m个正面情感种子词,正面情感种子词集为P={ p1,p2,…,pm},m个负面情感种子词,负面情感种子词 集 为R={r1,r2,…,rm} ,对 候 选 微 博 情 感 词dic_w={c1,c1,…,cn}中的每个词ci(i =1,2,…,n ),其与正面情感种子词pj( j=1,2,…,m )的互信息为:
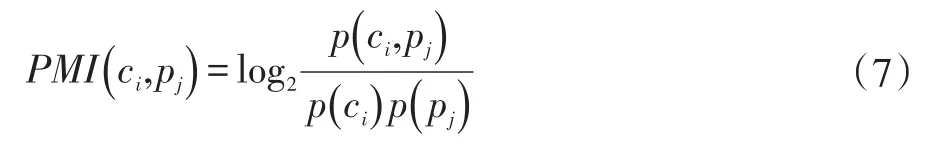
式中:
p(ci,pj)为词ci与pj在训练语料中共现的概率;
p(ci)为词ci在训练语料中出现的概率;
p(pj)为词pj在训练语料中出现的概率。
在实际计算过程中,上述概率值可用频率进行估计,即:

式(8)~(10)中:
count(ci,pj)为词ci与pj在训练语料中共现的微博条数;
count(ci)为词ci在训练语料中出现的微博条数;
count(pi)为词pj在训练语料中出现的微博条数;
q 为训练语料集中总的微博条数。
将式(8)~(10)代入式(2)后得到式(11):

由于在实际计算过程中,count( )ci,pj的值可能为0,此时 PMI( )
ci,pj无意义,本文对式(8)引入Good-Turing平滑技术:

式中:
count*(ci,pj)为count(ci,pj)的Good-Turing平 滑计数
将其代入式(1)得:

式中:
是训练语料中正好发生count(ci,pj)次的N元组的个数;
是训练语料中正好发生count(ci,pj)+1次
的N元组的个数。
则式(11)可改进为:

同理,可计算词ci(i =1,2,…,n)与负面情感种子词rj( j=1,2,…,m )的互信息,则词ci的SO-PMI值计算公式如下:

将式(15)化简后得:
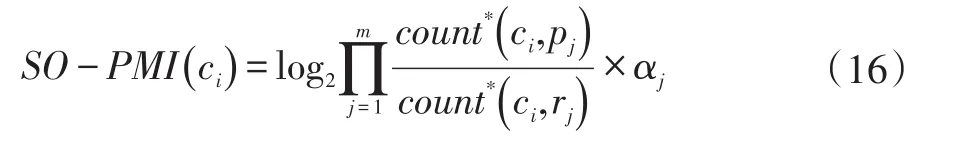
式中:

在封闭的语料库中,出现正、负面种子情感词的微博条数是固定的,因此αj可以看作常数,在训练语料中,如果:

则词ci可视为中性词,为便于计算,将αj赋值为1,改进后的SO-PMI计算公式为:

最终,候选微博情感词的情感倾向可以通过式(19)进行判断:
SO-PMI(ci)>0,ci为正面情感词,将其加入微博正面情感词典;
SO-PMI(ci)=0,ci为中性词;
SO-PMI(ci)<0,ci为负面情感词,将其加入微博负面情感词典;
从而组成微博领域情感词典。
5 实验结果与分析
5.1 实验数据选择
实验选取COAE2014任务四的测评语料,共40000条微博(含干扰数据),随机选取数据对其进行人工标注,得到正向、负向情感微博各3000条用于实验。首先对测评语料进行数据预处理,如分词、去除非法字符、数据格式规范化处理。使用3.2节中的方法从随机抽取出的200条微博中提取出400个待入选候选微博情感词,过滤掉微博基础情感词典已有的词169个,得到候选微博情感词共231个;然后选取TF-IDF值最高的正、负面情感种子词各25个,针对231个候选微博情感词使用公式(19)计算其极性如表2所示。

表2 候选微博情感词极性
最后,组成微博领域情感词典如表3所示。

表3 微博领域情感词典
5.2 实验方案
5.3 评价指标
本文用准确率(Precision)、召回率(Recall)和 F1值(F1Score)作为评价分类结果的指标,准确率和召回率计算公式如下。

实验在上述构建的微博领域情感词典的基础上,采用基于规则的方法[12]对实验数据进行情感倾向性判断,首先按照3.1小节中的方法得到微博基础情感词典Co,再通过3.2/3.3小节中的方法构建微博领域情感词典,同时将本文提出的算法与文献[8]中提出的拉普拉斯平滑算法进行对比。
准确率计算所有“正确检索的(T P )”占所有“实际被检索到的(T P+FP )”的比例。
召回率计算所有“正确被检索的(T P )”占所有“应该检索到的(T P+FN )”的比例。
F1值被定义为准确率和召回率的调和平均数,它认为召回率和准确率同等重要:

5.4 实验结果
表4中,PosP、PosR、PosF1分别为正面准确率、召回率和F1值,NegP、NegR、NegF1分别为负面准确率、召回率和F1值。从实验结果可以看出,本文提出的方法相对于另两种方法,针对正、负面情感微博都有较高的准确率和召回率,证实了本文提出的方法在判别微博情感倾向上的可行性。
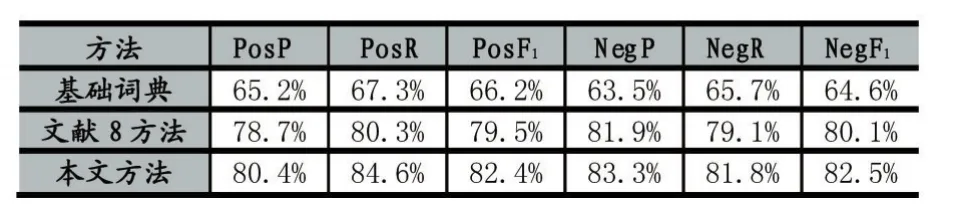
表4 微博倾向性分析结果

6 结语
本文基于平滑SO-PMI算法对微博基础情感词典进行扩展,针对微博候选情感词和种子词共现频次为0时无法计算其互信息的问题,引入Good-Turing平滑技术。以COAE2014任务四的测评语料作为实验数据,采用改进后的SO-PMI算法构建了微博领域情感词典,利用此微博领域情感词典对微博进行情感倾向性分析。实验结果表面,本文提出的方法取得了较好的效果。
由于在分词过程中,采用现有的ICTCLAS分词系统,导致部分网络词汇没有被正确切分,因此对微博候选情感词的提取率不高。基于规则的方法依赖于使用的情感词典,这造成一定的局限性。因此使用基于规则和机器学习融合的方法进行情感倾向性的判断将是下一步研究工作的重点。
参考文献:
[1]陈晓东.基于情感词典的中文微博情感倾向分析研究[D].华中科技大学,2012.
[2]陈国兰.基于情感词典与语义规则的微博情感分析[J].情报探索,2016(2):1-6.
[3]金博,史彦军,滕弘飞.基于语义理解的文本相似度算法[J].大连理工大学学报,2005,45(2):291-297.
[4]张彬.文本情感倾向性分析与研究[D].河南工业大学,2011.
[5]杨超.基于情感词典扩展技术的网络舆情倾向性分析[D].东北大学,2009.
[6]Lu Y,Castellanos M,Dayal U,et al.Automatic Construction of a Context-Aware Sentiment Lexicon:an Optimization Approach[C].International Conference on World Wide Web,WWW 2011,Hyderabad,India,March 28-April.DBLP,2011:347-356.
[7]王振宇,吴泽衡,胡方涛.基于HowNet和PMI的词语情感极性计算[J].计算机工程,2012,38(15):187-189.
[8]杜锐,朱艳辉,田海龙,等.基于平滑SO-PMI算法的微博情感词典构建方法研究[J].湖南工业大学学报,2015(5):77-81.
[9]朱嫣岚,闵锦,周雅倩,等.基于 HowNet的词汇语义倾向计算[J].中文信息学报,2006,20(1):14-20.
[10]Wiebe J,Riloff E.Creating Subjective and Objective Sentence Classifiers from Unannotated Texts[M].Computational Linguistics and Intelligent Text Processing.Springer Berlin Heidelberg,2005:486-497.
[11]Yang A M,Lin J H,Zhou Y M,et al.Research on Building a Chinese Sentiment Lexicon Based on SO-PMI[J].Applied Mechanics&Materials,2013,263-266:1688-1693.
[12]Raaijmakers S,Kraaij W.A Shallow Approach to Subjectivity Classification[C].International Conference on Weblogs and Social Media,Icwsm 2008,Seattle,Washington,Usa,March 30-April.DBLP,2008.
猜你喜欢
体育科技文献通报(2022年3期)2022-05-23
有色金属(矿山部分)(2021年4期)2021-08-30
厦门大学学报(自然科学版)(2021年4期)2021-06-22
天津医科大学学报(2021年2期)2021-03-29
电脑知识与技术(2019年23期)2019-11-03
魅力中国(2018年11期)2018-08-06
计算机应用(2016年10期)2017-05-12
电脑知识与技术(2016年1期)2016-03-22
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
航空兵器(2014年5期)2015-02-10
