
基于医疗卫生文本语义依存树库建设研究
2018-05-10 10:03:15陈亚波侯云霞
新疆师范大学学报(自然科学版) 2018年1期
于 清,陈亚波,徐 健,常 乐,侯云霞
(1.新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046;2.新疆大学 软件学院,新疆 乌鲁木齐 830008)
大数据、云平台、移动网络、社交媒体、深度学习、人工智能等计算机技术迅猛发展,颠覆了许多传统行业,行医治病模式也发生巨大变化,医学与计算机技术结合越来越紧密。此外,人们生活水平不断提高,对健康越来越重视,加速了医疗智能化发展,“互联网+健康医疗”开启了新时代,穿戴式计算产品、移动医疗应用越来越多走进人们生活[1]。但是,新疆维吾尔自治区民族居多,语言不通,加之基础医疗设施落后,造成偏远地区看病难,由此,开展医疗卫生服务信息化、翻译自动化研究意义深远。
实现医疗卫生领域信息化、自动化,最基础的技术研究词法分析、句法分析、语义分析是关键。现有分词工具应用于医学文本,出错率高,并且面对复杂专业的医学术语词汇,现有标注集中的符号,无法准确标注,目前医疗卫生领域,还没有统一标准的词性标注规范集。
语义依存分析是建立在精确分词,精准词性标注以及语义关系标记基础之上,它融合了句子的依存结构和语义信息,对高层次应用研究如:自动问答、信息抽取、机器翻译、信息检索、自动文摘等有很大帮助。关于医学文本数据语义依存树库建设,还没有检索到相关文献。文章研究目标是构建医学术语词典提高现有分词系统准确率;在现有词性标注规范集基础上,对医疗卫生文本数据词性标注提出建议;对语义依存句法分析工具错误的标注结果进行总结,为下一步实现自动化后处理以及探索维语依存树库建设奠定基础。

图1 研究内容设计方案
1 医学专业术语词典构建及切分规则
国内比较流行的中文分词工具有:结巴、THULAC、LTP[2]、ICTCLAS[3],这些分词工具在github上已经开源,对通用文本如:新闻、体育、政治有较高的自动识别率,但是应用于专业领域,识别率偏低[4]。
结巴分词系统优势在于支持用户添加自定义词典,并且用户添加词典的优先级高于系统原词典,根据第二届国际汉语分词测评,发布的国际中文分词测评标准,它的精确率为81.4%,未登录词召回率为80.9%,F值为81.1%。它的词性标注集参考了北大词性标注集、清华大学词性标注集及美国宾州大学中文词性标注集。将结巴分词工具应用于医疗卫生文本数据,准确率只有26%,造成切分不准确的主要原因:大量医学专业术语词汇,且词的组合形式多样,增加了分词工具识别难度,构建医学专业术语词典是提高分词工具切分准确率的可行方案。
医疗卫生领域疾病种类多、药物名称多、专业称呼复杂,专用动词出现频繁。经过对医学术语大量查找、筛选、查重,重点从以下几方面采集数据:国际疾病分类标准编码[5];搜狗医学词库;临床术语;人体器官名;常用药品名称;人体穴位及解剖学常用词汇;国际医学组织、医院科室、医用工具及医护人员专业称呼。最终获得65394个医学术语词汇,其中最长12字,对整理后的术语词汇进行人工词性标注,完成医学专业术语词典构建。
文献[6]分别应用三种分词方法:基于词典的分词方法,基于统计的分词方法和词典与统计相结合的分词方法对医疗数据进行分词实验,其中,基于词典的分词方法准确率最高。文章深入探索该方法的实际应用,发现如果合理解决医学术语中大量组合词何时组合、何时拆分,该方法用于对医疗文本数据切分,效果明显提升。提出组合词切分规则“如果该词切分后,每个词都有实际意义,做切分处理,否则组合成一个词”[7]。具体实例如下:
1.“肾上腺利尿激素”这个组合词,由“肾上腺”和“利尿激素”两个词构成,由于“肾上腺”在医学词汇中有实际意义,而“利尿激素”也具有实际意义,所以对该类词拆分处理。
2.“阿尔茨海默蛋白”这个组合词,分词系统处理结果为“阿尔茨海默”(被标注为人名(nr))和“蛋白”(名词,(n))两个词。虽然“阿尔茨海默”表示人名,但在医学用语中,通常见它与“病”,“症”等词组合,表示一种疾病或病理。将该类词组合成一个词,方能表达出词汇真实含义。
遵循切分规则,构建医学术语常用词典,结巴分词系统添加了自定义的词典后,对医疗卫生文本数据再切分,准确率达到78.5%,较之前提高了52.5%。
2 医学文本词性标注建议
对中文文本信息化处理过程中,首要问题是分词,从而需要制订分词标准以及词性标注规范集,判断词与词的分界,以及对不同词类进行词性标注。现有的标注集有:《信息处理用现代汉语分词规范》(简称国家规范)[8],1992年颁布;《现代汉语语料库基本加工规范》,由北京大学2002年颁布;《现代汉语语料库文本分词规范Ver3.0》,由清华大学计算机科学与技术系和北京语言文化大学语言信息处理研究所1998年颁布;《973当代汉语文本语料库分词、词性标注加工规范》,由山西大学2003年颁布,以及《资讯处理用中文分词规范》,由台湾1998年颁布。除了台湾颁布的规范集外,其余规范集都是在大陆规范的基础上制定的。但是,对于医疗卫生领域,目前没有统一标准的规范集。
不同于新闻报纸词汇,医疗卫生领域词汇有明显医学特色及特殊含义,如果完全参考原标注体系,有些词将无法表示出实际意义。如:“肌力4+级”,分词系统对符号“+”的标注结果为“x”,而它在句中的真实含义是“强”,标注为“a”形容词更贴切。诸如此类情况,迫切需要医疗领域信息化进程中,基于原有标注集,进行完善补充。
对分词工具处理后的医疗卫生文本进行分析发现,一般词汇都能准确切分,医学专业术语出错率极高,而包含大量医学专业术语命名实体,尤其名词是医学文本主要特征。文章就名词类展开研究,综合上述已有规范,名词类常见词性标记如表1。

表1 名词类词性标注
细观自动分词标注后的医疗卫生文本数据,大量命名实体,类型繁杂,上述名词词性标记,不足以反映出医学术语专有名词特点,建议在原有标注集基础上增加一类标记,医学术语专有名词标记“ny”,由名词代码n和“医”的声母y并在一起构成,ny又可细分为以下3类:
(1)“眼眶”、“脊髓”、“静脉”等器官名称,包括中医人体穴位,在医疗卫生文本中大量出现,建议列为医学术语专有名词一个子类——器官类“nyq”。
(2)“脑性瘫痪”、“高血压”为疾病;“CT”、“B超”为检查;“手术刀”、“止血钳”为医疗器械。医疗卫生文本包含大量疾病治疗过程,其中疾病病理名称、疾病症状,所用器械、检查、手术名称及治疗过程等与疾病密切相关,建议列为医学术语专有名词一个子类——疾病类“nyj”。
(3)大量与治疗疾病相关的药物,不但包括药物名称(包括通用名,正式商品名,以及药物主要成分命名的医用名),而且包括药物的施治方式,计量,用药频率等,建议列为医学术语专有名词中一个子类——药物类“nyy”。针对医疗卫生文本数据特点,医学术语专有名词分类细则参见图2所示。
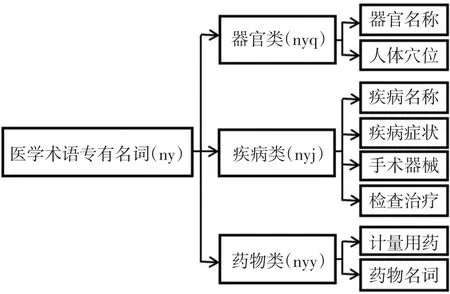
图2 医学术语专有名词分类
以上对原有标注集的补充完善,必将促进医疗领域文本数据的自动化处理。
3 医学文本语义依存分析
语义依存分析的目标是跨越句子表层句法结构束缚,分析句子各个语言单位之间的语义关联,并将具有直接语义关联的语言单元直接连接依存弧,并标记上相应的语义关系,从而获取深层语义信息[9]。
语义依存关系分为三类,语义角色:包含34种关系,每一种语义角色对应存在一个嵌套关系和反关系;事件关系:描述两个事件间的关系,包含19种类型;语义依附标记:标记说话者语气等依附信息,包含17种标记;此外还包含一个根节点Root,是全句的核心节点,详见哈工大LTP语言云,目前已经开放。
语义依存分析,是用以上制订的各种关系标记,深刻描述出句子语义信息,人工标记费时费力耗财,借助语义依存分析平台,可实现对句子的自动化标记。然而由于医学文本句子有其独特风格,自动化处理结果往往包含错误。此外,语义分析是继分词,词性标注后的自动化处理过程,如果分词和词性标注出现错误,会导致语义依存分析错误累积。以上诸因素,自动生成的依存树库,需要后处理。
文献[10]提到,句子太短不能表达完整语义,句子太长超过一定限度,依存句法分析会产生划分错误。句子长度阈值介于8-40字为合适范围[11]。于是构建了45215条医学文本句子,从中抽取2万条,每条句子长度介于8-40个字,先进行自动化依存句法分析,通过对500条标注后的句子,人工校对,发现如下规律。
3.1 词性调整会改变语义依存关系
人工校对过程中,关于词切分、词性标注仍然存在大量分歧,通过搜索和查阅大量文献,信息处理用电子病历词性标注遵循以下原则:第一,语法功能原则;第二,允许有兼类[12]。名词类和动词类最容易出错,需根据语法功能,判断词性,人工重新标注,语义依存关系自动变化。常见标注错误有以下几方面:
(1)名词或动词词性标注冲突
如分词处理结果:免疫/v抑制剂/n、/wp免疫/v增强剂/n。
其中,“免疫”可为动词也可为名词。百度搜索后:“免疫是人体的一种生理功能,人体依靠这种功能识别"自己"和"非己"成分,以维持人体的健康。”在医学方面大量使用其名词属性。因此将“免疫”重新标注为名词。
(2)分词歧义造成错误
如分词处理结果:有/v此前/nt驱/v症状/n。/wp
根据语法、语义,应修改为:有/v此/nt前驱/n症状/n。/wp
上述句子属于交集型歧义。
(3)医学术语造成的分词错误
如分词处理结果:口腔/n念/v珠菌病/n
修正①:口腔念珠菌病/nd
修正②:口腔/n念珠菌病/nd
修正③:口腔/n念珠菌/nd病/n
百度搜索:念珠菌病是由念珠菌病主要是白色念珠菌引起的皮肤、粘膜或内脏器官真菌病。根据查询结果及分词规则,最终保留第二种纠正结果。
3.2 自动语义依存分析存在问题
尽管当前语义依存工具强大,但是面对特定领域,尤其医疗卫生领域,由于语句明显有医学特点,需要进一步人工校对。通过实践,总结出以下规律:
(1)主语并列引发root节点指向不明
如原句:营养不良、变态反应体质、不良的卫生习惯及阴暗潮湿的居住环境等可诱发本病。
词法分析后的句子:营养/n不良/a、/wp变态反应/i体质/n、/wp不良/a的/u卫生/a习惯/n及/c阴暗/a潮湿/a的/u居住/v环境/n等/u可/v诱发/v本病/r。/wp
经修改后,语义依存分析标注为:

图3 主语并列项的句子标注结果
如图3所示:本句用到了根节点(Root)、描写角色(Feat)、当事关系(Exp)、并列关系(eCoo)、的字标记(mAux)、多数标记(mMaj)、情态标记(mMod)和标点标记(mPunc),共8种语义依存标注关系。图中“营养不良”、“变态反体质”、“不良的卫生习惯”及“阴暗潮湿的居住环境”作为句子的并列主语,引发root节点指向“不良”形容词,在标记规范中root节点是全句的核心节点,应该指向核心词,本句的核心词是动词“诱发”。
(2)缺少主语,影响词间关系标注
如原句:多见于青少年及儿童。
词法分析后的句子:多/a见于/v青少年/n及/c儿童/n。/wp
句子没有主语,只有谓语宾语,“多”字起修饰作用,与动词的词间关系没有自动生成,经讨论描写关系(Feat)为最接近的关系表示,修改后,语义依存分析标注为:

图4 缺少主语的句子标注结果
如图4所示:本句用到根节点(Root)、受事关系(Pat)、描写角色(Feat)、连词标记(mConj)、并列关系(eCoo)和标点标记(mPunc),6种语义依存标注关系。
(3)存在多个相连动词
如原句:多认为是由多种微生物蛋白质引起的迟发型变态反应性疾病。
词法分析后的句子:多/a认为/v是/v由/p多种/m微生物/n蛋白质/n引起/v的/u迟发型/b变态反应性/n疾病/n。/wp
存在多个相连动词,造成根节点(Root)指向错误,修改后,语义依存分析标注为:
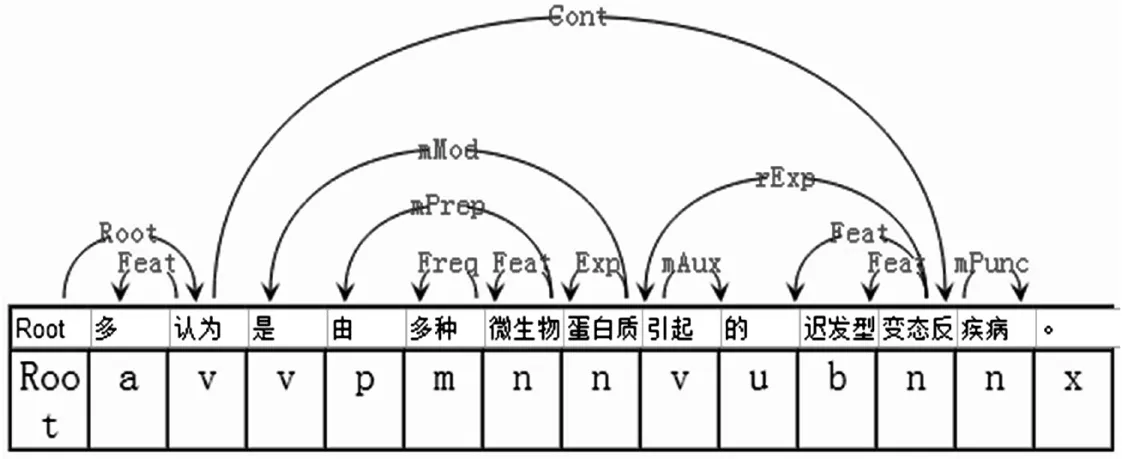
图5 存在多个动词的句子标注结果
(4)医疗文本中的顺承关系有延伸
如原句:用0.1%利福平眼药水、0.1%肽丁胺眼药水或0.5%氯霉素眼药水等点眼。
词法分析后的句子:用/p 0.1%/m利福平/v眼药水/n、/wp 0.1%/m肽丁胺/n眼药水/n或/c 0.5%/m氯霉素/n眼药水/n等/u点眼/n。/wp
修改后,语义依存分析标注为:
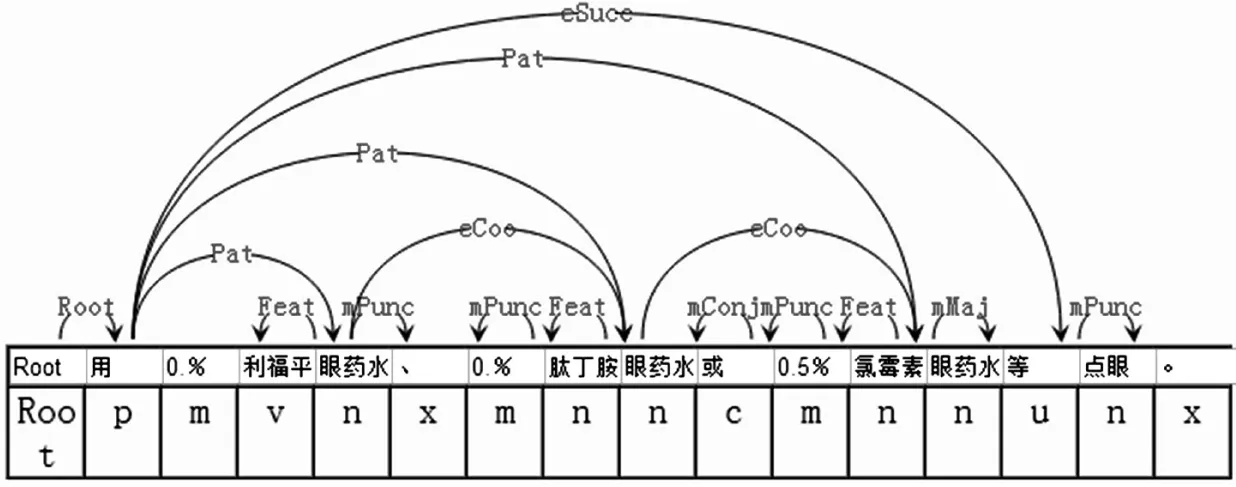
图6 存在顺承关系的句子的标注结果
顺承关系(eSucc)中,代表性关键词为“随后,然后”。顺承关系表示前后两个行为之间只有时间的先后,不一定有程度的加深、范围的扩大。而在医疗文本中,顺承关系(eSucc)有扩张,不仅表现在出现的关键词,而且表现在动词与动词之间。
4 结论与展望
文章针对现有分词工具对医疗卫生领域文本分词、词性标注出现的诸多问题进行研究,提出扩充词性标注集方案,对词切分错误进行归纳总结,并构建了专业的医学术语词典。进一步深入研究了医疗卫生领域句子的依存句法特征,构建了小规模语义依存树库。这些研究为医学文本信息化处理奠定了基础。
下一步将继续扩充语义依存树库,对医疗卫生领域文本的语义依存特征进行更深入分析和总结,实现用统计方法对现有依存工具句法标注结果进行自动化后处理,扩大树库规模,达到高层应用需求。
参考文献:
[1]《全国医疗卫生服务体系规划纲要(2015-2020年)》国务院办公厅(2015)14号文件[EB/OL].http://www.gov.cn/zhengce/content/2015-03/30/content_9560.htm.
[2]刘挺,车万翔,等.语言技术平台[J].中文信息学报,2011,25(6):53-62.
[3]唐涛.面向特定领域的中文分词技术的研究[D].沈阳航空航天大学,2012.
[4]魏进.中文分词技术在公安信息系统中的应用研究[D].解放军信息工程大学,2007.
[5]卜擎燕,熊宁宁.ICH国际医学用语词典[M].上海:上海交通大学出版社,2007.
[6]于清,陈永杰,等.适用于医疗卫生领域的中文分词方法研究[J].新疆师范大学学报(自然科学版),2017,36(01):62-66.
[7]蒋志鹏,赵芳芳,等.面向中文电子病历的词法语料标注研究[J].高技术通讯,2014,24(06):609-615.
[8]杨锦锋,于秋斌,等.电子病历命名实体识别和实体关系抽取研究综述[J].自动化学报,2014,24(8):1537-1562.
[9]袁毓林.论元角色的层级关系和语义特征[J].世界汉语教学,2002,3(002):10-22.
[10]李向宏,王丁,等.自然语言句法分析研究现状和发展趋势[J].微处理机,2003,1(2):4-12.
[11]孟谣,李生,等.基于统计的句法综述分析技术[J].计算机科学,2003,30(9):54-58.
[12]杨梅,白楠.国内语料库翻译研究现状调查——基于国内学术期刊的数据分析[J].中国翻译,2010,6(1):46-50.
猜你喜欢
文苑(2019年24期)2020-01-06 12:06:50
智富时代(2019年6期)2019-07-24 10:33:16
疯狂英语(双语世界)(2017年3期)2018-01-19 01:40:36
疯狂英语(双语世界)(2017年1期)2017-07-01 17:11:10
高中生·天天向上(2016年9期)2016-11-22 09:10:34
青苹果·教育研究版(2013年2期)2013-04-29 00:44:03
当代修辞学(2013年4期)2013-01-23 06:43:10
中国科技术语(2012年3期)2012-03-20 14:36:13
中国科技术语(2012年3期)2012-03-20 14:36:11
外语学刊(2011年3期)2011-01-22 03:42:20
