
Hadoop实现点击流日志的数据清洗
2018-05-09 02:52赵鑫
无线互联科技 2018年9期
赵 鑫
(辽宁行政学院人事处,辽宁 沈阳 110161)
1 数据仓库和Web
互联网极大地促进了商业的发展,每个电子商务企业都有自己的Web入口和后台系统,用户在网站页面上产生一个订单时,Web和后台系统就发生一次交互,交易请求数据被存在后台数据库中,对于这类结构化的数据,使用Hadoop Hive的HQL即可实现数据的清洗。每当用户在页面进行点击而跳转到另外一个页面时,一条点击流日志就产生了,如图1所示。点击流日志是了解用户心理倾向的关键,通过它企业能够更好地理解产品及营销,但点击流日志是非结构化数据,不能直接被用于分析,它记录了很多不需要的信息,将这些信息装载到数据仓库前,必须对点击流日志进行数据清洗,粒度管理器能够完此项任务,粒度管理器主要完成清除无关数据,清除错误数据,记录合、汇总与聚集。经过这些处理,80%~90%的数据被粒度管理器抛弃,清洗后的数据被传递给数据仓库[1]。其工作流程如图2所示。
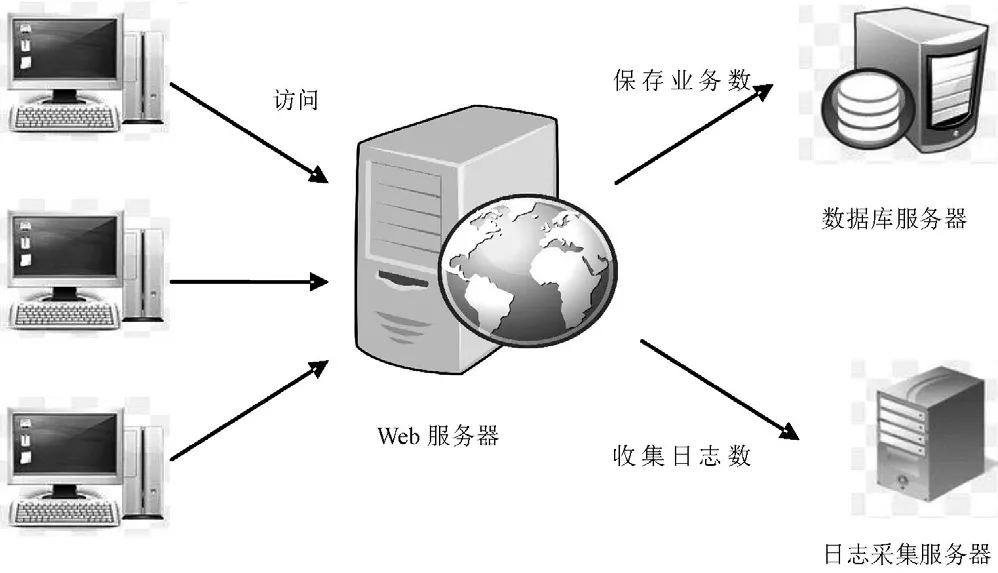
图1 Web和点击流
2 点击日志流数据清洗处理流程
点击流日志由日志收集服务器每天定期上传至分布式文件系统(Hadoop Distributed File System,HDFS)的指定目录,经过MapReduce作业清洗后输出至HDFS指定的目录,最后再由Hive将清洗后的数据加载到Clickstream_log表中指定的分区,完成点击流日志的数据清洗工作[2]。其流程如3所示。
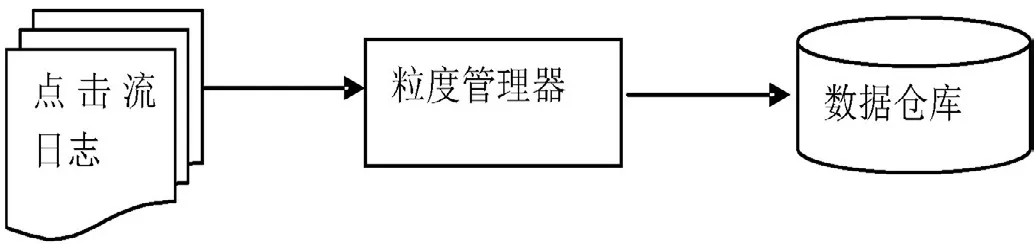
图2 粒度管理器工作流程
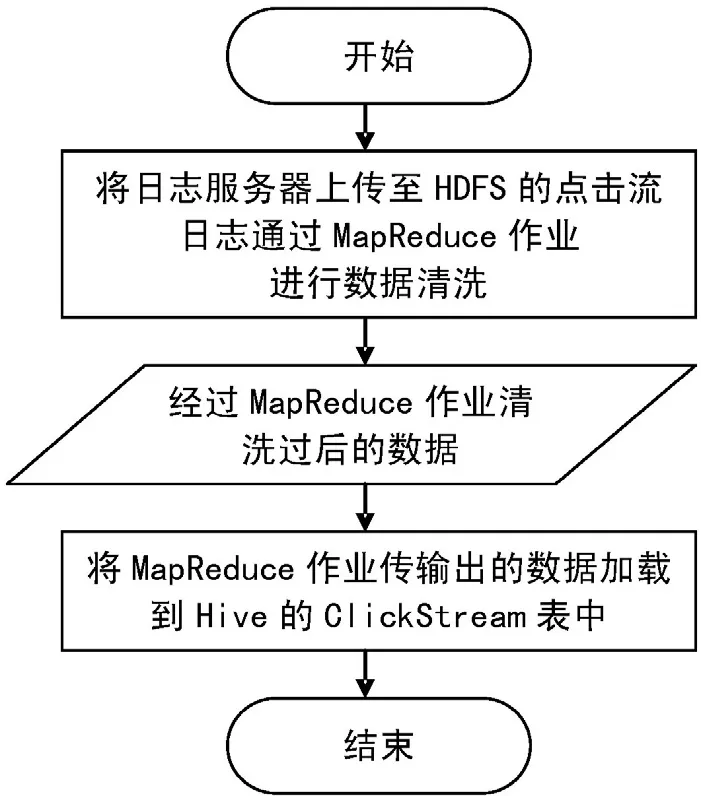
图3 点击流日志的数据清洗处理流程
3 从点击流日志获取重要信息的字段构成
点击流日志数据的体量巨大,但价值密度很低,下面为一条标准的Apache服务器日志信息[3]。

Clickstream_log表中主要字段如表1所示,其字段对map reduce任务产生影响。
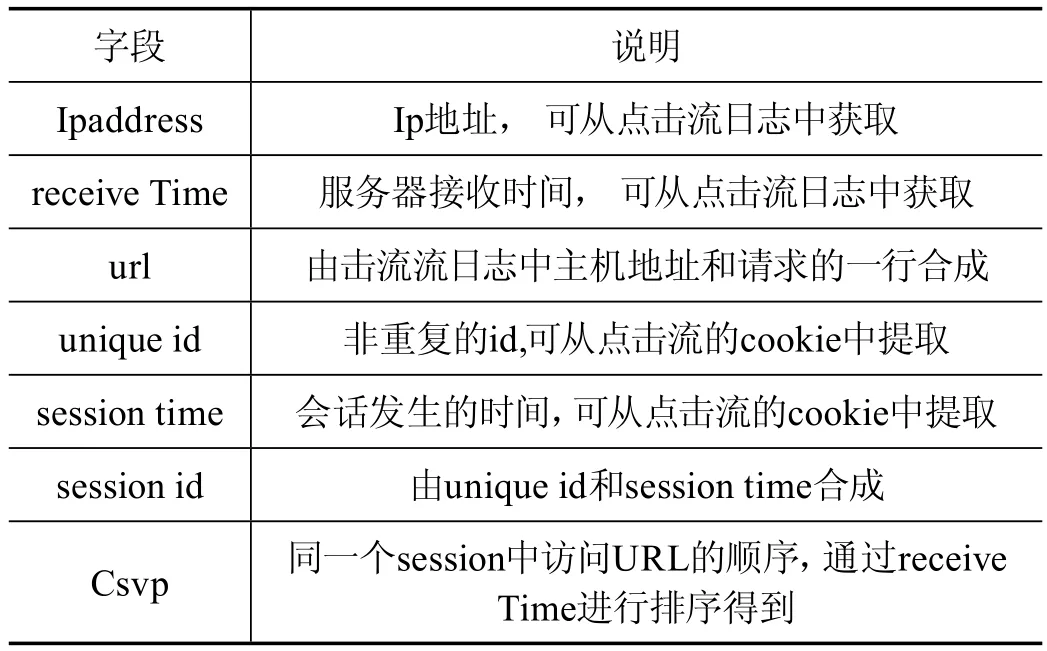
表1 Clickstream_log表中主要字段
在Clickstream_log表中,除Csvp字段外,其他的字段可以在map函数中直接获取,但Csvp必须经过reduce函数才能获得,如同一个用户在同一个session中有两条点击流记录,receive Time分别是1413482169623和1413482169642,那么这两条记录的Csvp分别为1和2,有了这个字段,才能完整得到用户在网站的点击行为[4-6]。
4 Csvp排序流程
为了对Csvp进行排序,首先对map的key进行了重构,session id 由unqiue id和session time合成而成,其中经典的流程如图4所示。
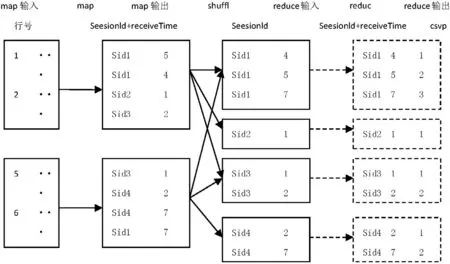
图4 将session id作为键值输出的mapreduce排序流程
5 Reducer重要代码部分解释
其执行代码为map/reduce/partion/二次排序等,主要部分如下:


6 结语
点击流日志的数据清洗,代表了一种非结构化数据清洗的方式。当拥Clickstream_log表后,意味着数据仓库又多了一份宝贵资产,可以通过Clickstream_log表进行网站的分析,更好地维护网站,增加网站浏览量。网站运营商根据不同用户的浏览行为和习惯可以对现有网站进行改进和优化,尤其对从事电子商务的企业,通过点击流日志可以更多地了解用户的消费心理,深刻地理解产品、营销和广告是如何对用户产生影响的。日志分析在企业发展中将越来越重要,从日志中将挖掘出大量重要信息。
[参考文献]
[1]杨丕仁.基于Hadoop下利用Hive进行网络日志存储和分析[J].电子技术与软件工程,2017(2):163-165.
[2]蒋焕亮.基于hive的日志仓库构建研究[J].计算机时代,2016(11):21-24.
[3]张俊瑞,代洋.基于Hadoop平台的Web日志业务分析[J].山西电子技术,2017(6):71-73.
[4]宋梦馨,缪红萍,王溯,等.基于Hadoop平台的网站日志分析[J].信息系统工程,2015(12):35-36.
[5]陆嘉恒.大数据挑战NoSQL数据库技术[M].北京:电子工业出版社,2013.
[6]范东来.Hadoop海量数据处理技术详解与项目实战[M].北京:人民邮电出版社,2016.
猜你喜欢
江苏科技信息(2022年16期)2022-07-17
自然资源信息化(2019年4期)2019-03-29
数码世界(2018年2期)2018-12-21
电子制作(2016年15期)2017-01-15
山东工业技术(2016年15期)2016-12-01
中国教育信息化(2015年10期)2015-08-23
电子设计工程(2015年12期)2015-02-27
图书馆建设(2015年10期)2015-02-13
新世纪图书馆(2014年7期)2014-09-19
图书馆建设(2014年3期)2014-02-12
