
基于深度学习的生物医学英文文献中中国学者的身份识别
2018-05-07 01:45
中华医学图书情报杂志 2018年11期
建立机构知识库,收集整理科研成果,已成为很多单位科研部门近年来的一项重要工作。建立机构知识库最关键、最难的环节是清洗机构科研成果数据,特别是清洗学者英文成果的数据最为繁琐,其中相当一部分需要人工辨认。据中科院机构知识库项目组统计,目前很多单位虽然建设了机构知识库,但因数据清洗不彻底而导致数据无法使用,其原因就是中国学者发表英文文献时,学者名称著录格式多样、机构和科室的英文名称书写不规范。如我国著名的呼吸疾病专家钟南山在SCI和PubMed数据库中的科研成果,作者名称标注有zhong nanshan、zhong nan-shan、zhong n-s、zhong NS、zhong N等形式,所在单位附属第一医院的英文写法有:first hospital、1st hospital、hospital 1、First Affiliated Hospital等形式。著录格式的多样化造成自动化程度不高,大量成果需要人工清洗,而学者自行认领个人成果的模式因没有行政命令和利益驱动导致无法进行,最终科研管理部门只能通过人工辨认学者成果,费人费时费力。
人工智能时代的到来,医学数据、图像、信号等各种形式的数据日益增多,医疗大数据的智能化处理变得越来越重要,其巨大的潜力引起了很多专家学者和高科技公司的关注[1]。深度学习是最近几年人工智能领域发展起来的一项新技术,是一种基于大数据的新型机器学习方法,具有分布式、并行信息处理及智能计算的功能[2]。它通过调整内部大量节点之间相互连接的关系,达到处理信息的目的,并具备学习、自组织、泛化及训练的能力。本文探索利用人工智能的深度学习技术,模拟人工辨认学者身份,进而解决英文文献中中国学者身份的智能化识别问题。
1 探索识别学者身份的深度学习模型
深度学习技术主要有径向基函数网络(Radial Basis Function,RBF)、卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络(Recurrent Neural Networks,RNN)等几种类别[3]。径向基函数网络通常只有输入层、中间层和输出层3层,中间层计算输入矢量与样本矢量欧式距离的径向基函数值,输出层计算它们的线性组合。循环神经网络的目的是用来处理序列数据,但处理速度比较慢。卷积神经网络不但用于图像识别,还可对自然语言处理,能够有效地从原始输入中学习到高阶不变性的特征,广泛应用于图像识别、人脸检测、语音识别和语义分析等领域。
1.1 卷积神经网络
卷积神经网络主要结构为一个多层的感知器,每层由多个二维平面组成,而每个平面由多个独立神经元组成。网络中包含一些简单元和复杂元,分别记为C元和S元,C元聚合在一起构成卷积层。卷积层是卷积神经网络的核心层,用它来进行特征提取。如图1中输入数据通过一组卷积核进行卷积运算,在C层产生N个特征图,通常会使用多层卷积层来得到更深层次的特征图S元聚合在一起构成池化层,实现对特征图的压缩。然后,特征图通过激活函数( Logistic、Softmax等函数)得到S层的特征图。根据设定的C层和S层的数量,以上过程依此循环。最终对最尾部的卷积层和输出层进行全连接,然后将输出值送给分类器[4]。
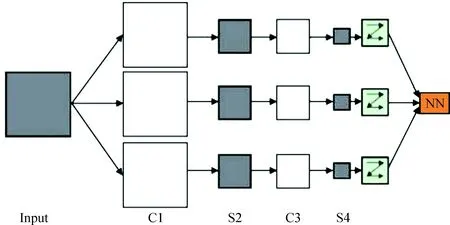
图1 CNN原理示意图
鉴于单一类型信息处理的身份识别效果很难达到理想的要求,而现实生活中人们在识别英文文献的学者身份时,总是结合不同类别的学者特征信息如单位名称、院系名称、合作关系等,人脑是对多种特征信息综合分析的基础上进行最终的辨别确认。所以,笔者从融合多种特征信息的观点出发,提出了融合学者名称、学者机构、学者院系/科室、合作关系等特征信息的身份识别神经网络模型[5](图2)。
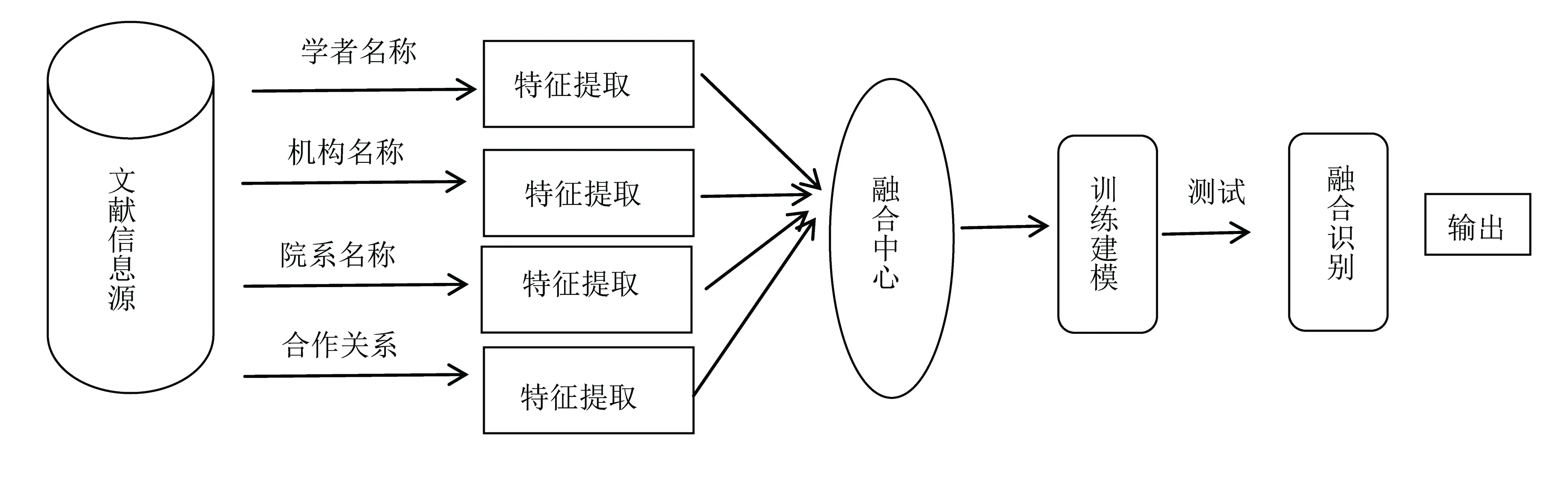
图2 学者身份识别神经网络模型
该模型的计算过程为:输入初始数据给CNN的初始层,各层依次计算出输出值;每一层的输入值都是由上一层的输出值乘以当前层的权值向量,取得加权数组成;应用非线性函数如修正线性单元(ReLU)或双曲正切函数加权总数计算输出层。
1.2 数据采集
利用北京唯博赛科技公司开发的网络爬虫软件从Web of Science数据库采集2000年以来国内6所知名医学高校(首都医科大学、哈尔滨医科大学、南方医科大学、南京医科大学、北京协和医学院、天津医科大学)的数据共95 364条,采集到的SCIE数据的著录字段包括标题、作者、地址信息、年代、期刊名、WOS号等。
1.3 方法与测试
当前主要解决多分类问题,本文选用Softmax函数作为分类函数。Softmax函数其实就是一个归一化的指数函数,其定义如下:
通过Softmax函数,可以使P(i)的范围在0~1。在回归和分类问题中,通常θ是待求参数,通过寻找使得P(i)最大的θ作为最佳参数。
CNN中最重要的部分是“学习规则”,即类似人类大脑,需要很长时间来训练模型,通过训练过程调整网络中运算单元间连接的权重,以期达到最理想的结果[6]。随着CNN模型训练次数的增加,根据输出的结果不断调整CNN的连接权重,使目标值与CNN输出值的误差逐渐减小直至为零,此时称CNN已收敛,训练完成。CNN的工作性能与样本也有直接关系,若训练集样本数量少或太相似,则模型的工作能力将大大降低[7]。因此,样本量越大,样本差异性越强,则CNN模型的能力越强。而测试样本选取值与训练样本值越相近,其输出值与实际值的差异就越小,模型准确度也会增加[8]。
为避免样本数据差异化对识别结果的影响,对这6所知名医学高校从1到6进行标号,从每个高校的数据池中随机挑选两段为训练样本,每段选出5 000条数据,最终得到60 000条训练集。其余35 364条数据为测试样本,训练数据与测试数据之间不重叠。
模型采用前期无监督训练和后期微调两个阶段。4个特征信息的原始权值可设置同等比例,输出数据的阈值设置为0.8,若输出数据的权值超过阈值即完全匹配,可判定为该学者的成果。阈值在0.5~0.8为高匹配度,阈值低于0.5为低匹配度。通过CNN的训练优化权值向量,从而获得更加准确的输出值。
CNN训练结束后,还需要用另几组与训练集不同的样本,测试其输出是否与所要求的相近,从而验证模型的推广性[9]。通过对已有样本的学习,将所提取样本的非线性映射关系存储在训练的权重矩阵中,即使向模型输入训练时未曾见过的非样本数据时,网络也能完成由输入层向输出层的正确映射[10]。
从每个学校的测试数据结果中随机选出1名学者进行查验,将测试数据结果分别标记为完全匹配、高匹配度、低匹配度3种,并以人工确认该学者SCIE成果数为基数。每个学者以深度学习模型识别的准确成果总数与该学者全部SCIE成果数中的比值来算出准确率(表1)。
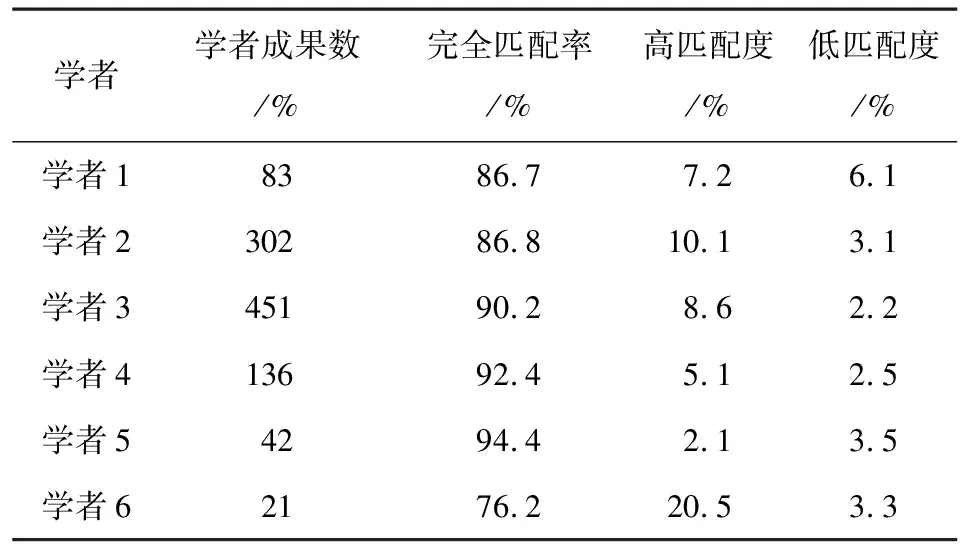
表1 CNN模型检测匹配结果
1.4 与传统检索方法比较
本文的学者身份识别是典型的文献检索问题,利用标准的“学者全拼+学者机构”查询学者的数据,以保证此数据绝对是该学者的。如在Web of Science数据库中查询学者,检索式如下:AU=Zhong Nanshan SAME AD=Guangzhou medical univ,因学者名称著录格式多样、机构和科室的英文名称书写不规范,查询结果远不及利用模型识别的数据全面,且传统检索方式必须需要人工设置检索式进行查询,耗时时间长。利用深度学习模型进行识别的方式不但精准度高,且节省了大量的人工工作量[11]。
2 深度神经网络模型效果分析
使用训练集样本训练网络模型,当训练次数到10次时,网络代价函数收敛较佳。然后再用测试样本集中的35 364条数据对网络进行验证,结果如表1所示。网络有较高的可靠性识别出学者的身份(识别率为:86.7%、86.8%、90.2%、92.4%、94.4%和76.2%),且每条数据平均耗时约2秒。可见,利用深度学习模型解决生物医学英文文献的学者身份识别问题,不但识别效率与准确性较高,而且速度已经大大快于人工辨别,能满足快速识别海量数据的要求。
从结果中还可以发现,相对于学者名是两个字(如学者1、2),当学者名字为3个字时(如学者3、4、5)网络识别的效果更好。利用训练过的神经网络模型对中国学者的英文文献进行辨别的整体识别率达到85%以上,而且凡是模型识别的文献均准确[12]。
但如果两个学者名字是同音,而且又在同一院系,如李君如和李俊茹,他们的英文名称均为li,junru或li,jr,通过以上模型无法进行区分辨别,只能进行人工辨认。而学者名字是两个字的,同时只写了名字的缩写,如李军,li,j,这种情况容易和li,js;li,jb;li,ja等名字的缩写混淆,相对于名字是3个字的成果辨别度要低一些,如表1中的学者6。另外,学者发生迁徙后,学者的成果署名单位变更,成果识别度也会降低,这些问题有待进一步研究。
3 结语
综上所述,通过学者多元特征建立的基于深度学习的神经网络模型,对学者英文文献中的身份能够自动精准识别,可在很大程度上解决中国学者的英文文献人工辨别的麻烦,大大提高了工作效率,对目前很多单位建立机构学者库中存在的数据清洗难题具有很好的实际意义。
猜你喜欢
管子学刊(2022年2期)2022-05-10
中北大学学报(自然科学版)(2022年2期)2022-05-05
管子学刊(2022年1期)2022-02-17
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
时代英语·高二(2017年4期)2017-08-11
学生天地·小学中高年级(2017年5期)2017-06-09
红领巾·成长(2016年10期)2017-05-10
