
基于半监督集成学习的多核设计空间探索
2018-05-04 00:46李丹丹姚淑珍王颖王森章谭火彬
北京航空航天大学学报 2018年4期
李丹丹, 姚淑珍,*, 王颖, 王森章, 谭火彬
(1. 北京航空航天大学 计算机学院, 北京 100083; 2. 中国科学院计算技术研究所 计算机体系结构国家重点实验室, 北京100190; 3. 南京航空航天大学 计算机科学与技术学院, 南京 211106; 4. 北京航空航天大学 软件学院, 北京 100083)
随着集成电路工艺的进步以及系统结构设计的复杂度不断提高,特别是随着多核技术的发展,处理器设计相关的参数变得越来越多,从而使得处理器的设计空间呈指数式增长; 且处理器的工作负载通常由大量具有不同特性的应用程序组成。为满足处理器性能、功耗和设计成本等方面的要求和限制,系统结构设计师面临着更加严峻的挑战:从庞大的设计空间中寻找满足约束条件的最优参数组合,即是设计空间探索。为解决该问题,系统结构设计师通常在制造芯片前,利用软件模拟技术来模拟一部分具有代表性的工作负载来探索处理器的设计空间,进而评估处理器各种参数组合的性能。然而,周期精准的模拟器的低速问题(比真实处理器运算速度慢了3~5个数量级),使得对设计空间中每种可能的设计参数组合都进行模拟是非常耗时且不可行的。导致的结果是,设计师被迫减少评估的参数配置数量:通常基于设计师对某些参数相对重要性的经验以及功率预算等来确定需要模拟的参数组合。但此类方法有以下缺点:
1) 针对不同的应用程序,微体系结构设计参数对性能或功耗的影响程度是不同的,因此,设计师的经验可能是不准确的。
2) 缺乏统计的严谨性,得到的结论可能不正确。
3) 缺乏对各个参数的重要性及意义、参数之间的相互作用等问题的探讨。
为了解决以上问题,近年来的相关的研究主要关注如下3个方向:分析模型、快速的模拟技术和基于机器学习技术构建预测模型的方法。理论上,分析模型用来准确表征处理器性能和各种微体系结构参数之间的关系,能够消除对耗时模拟的需要。然而,现有的处理器性能分析模型技术基于几个简化的假设,仅对少量的微结构参数建模[1-2]。并且,分析模型需要大量的专业领域知识,不具备通用性。因此,此类模型缺乏在处理器设计周期使用的准确性和灵活性。快速的模拟技术主要通过减少模拟指令来加速模拟,比较著名的有SimPoint[3]和SMARTS[4],能够极大地加快单个模拟的速度。这些方法在一定程度上减少了设计空间探索中的模拟成本,但设计空间中的配置数量太过于庞大,仅仅通过减少单个配置模拟的时间非常有限。随着机器学习技术的日益发展以及其在数据挖掘、社交网络分析等领域[5-6]的广泛应用,近年来,统计机器学习算法也被引入到系统结构设计领域中[7-20]。首先通过对设计空间中的一小部分配置进行模拟,然后根据模拟结果组成训练数据集,并构建机器学习预测模型来预测设计空间中未模拟的配置性能或功耗响应,从而极大地减少设计空间探索中的模拟成本。这种方法取得了较好的实验结果,往往和快速模拟技术SimPoint结合起来进行设计空间探索。例如,Joseph等提出使用线性模型建模处理器性能与微系统结构参数的关系[7]。然而,在实际应用中,处理器的响应结果与体系结构设计参数的关系并非只有简单的线性关系。Joseph等又提出基于径向基函数(RBF)的非线性回归模型预测处理器性能[8]。Lee等在线性模型的基础上,提出了采用样条函数来刻画两者之间的非线性关系[9-10]。Ïpek等提出了基于人工神经网络(Artificial Neural Network, ANN)的预测模型[11]。郭崎等提出基于模型树的预测模型[12]。庞九凤等提出基于支持向量机(SVM)的预测模型[13]。Palermo等提出结合实验设计和响应面模型技术来识别满足系统级约束的Pareto解集合[14]。2015年,Palermo等又提出基于监督的高水平分析的谱感知Pareto迭代细化方法,以寻找设计空间中满足多约束的解集合[15]。针对单一预测模型的预测结果抖动的问题,郭崎等于2015年提出一种结合神经网络模型、SVM和模型树3种预测模型的元模型,从而提高了预测模型的鲁棒性[16]。2016年, 考虑到随机采样训练样本的缺点,Li 等提出基于主动学习采样的设计空间探索方法[17]。针对通用处理器的设计而言,为了避免对每个不同的程序都构建一个预测模型, Khan、Dubach和 Li等分别提出交叉应用的预测模型[18-20]。由于模拟太过耗时且设计空间过于庞大,对于设计空间探索来讲,关键是如何利用一个足够小的样本集来构建预测模型,准确学习参数和响应之间的关系。传统方法多数都是基于有监督学习的预测模型,通常需要模拟大量的配置来提高预测模型的精度。为了减少模拟成本(次数),一个直观的考虑是基于少量已标记的样本集,标记设计空间中未模拟(即没有标记的)的配置(样本),从而达到扩充训练数据集的目的,进而提升预测模型的精度。此外,集成学习技术能够通过结合多个基本预测模型,来提升模型的预测精度。因此,本文的目标是利用半监督学习和集成学习技术尽量减少模拟的次数并保证预测模型的精度。
本文首先提出采用集成学习算法AdaBoost提升人工神经网络算法的预测精度和鲁棒性。然后结合AdaBoost算法的特点,提出一种基于半监督学习的AdaBoost(Semi-Supervised Learning based AdaBoost,SSLBoost)模型,利用未标记样本来扩展训练数据集,进一步提升预测模型的精度。最后采用SSLBoost模型对未模拟配置的性能进行预测,从而搜索到最佳设计参数组合。
1 基于半监督集成学习的预测模型
本文结合半监督学习和集成学习技术,以更少的模拟成本,来提升设计空间模型的精度。采用AdaBoost模型提升ANN的鲁棒性和预测精度,并在此基础上,提出一种半监督集成学习算法。图1给出了本文提出的设计空间探索框架,主要分为2个阶段:训练数据集采样阶段和预测模型阶段。在采样阶段,首先利用基于均匀随机采样方法从处理器设计空间中选取一部分设计配置(设计参数组合,如核的数目、Cache大小和发射宽度等的设计结构组合),利用模拟器进行模拟得到相应的性能响应(执行时间);然后将这些性能响应与设计参数共同组成初始训练数据集。在预测模型阶段,利用第1个阶段的训练数据集构建基于半监督学习的AdaBoost模型,迭代地对未标记样本进行标记,从而扩大训练数据集的规模,更加精确地预测设计空间中未模拟的设计结构的性能。

图1 基于半监督集成学习的设计空间探索框架Fig.1 Design space exploration framework based on semi-supervised ensemble learning
1.1 AdaBoost.RT模型
考虑到预测模型的鲁棒性和准确性,本文采用集成算法AdaBoost中的一个变种AdaBoost.RT算法[21]构建设计空间探索的预测模型。AdaBoost.RT是Shrestha和Solomatine在2006年提出一种基于回归问题的提升算法[21],和其他提升算法一致,通过对多个弱学习器集成并提升为强的学习器。本文采用ANN作为弱学习器。
设L={(x1,y1),(x2,y2),…,(xm,ym)}为训练集,m为模拟配置的数量,xm为由设计空间所有设计参数的取值组成的向量,例如,设计参数有频率、发射宽度、核数目等,x1=(2,6,2,…)就表示x1是一个频率大小为2 GHz,发射宽度为6,核的数目为2的一个设计配置。yi为模拟相应配置的处理器性能响应,如常用性能指标执行时间。(xi,yi)即配置与模拟的性能组成的向量,在机器学习领域被称为一个已标记样本,组成的已标记样本集合被称为训练数据集。AdaBoost.RT模型迭代地训练多个弱预测器h1,h2,…,hT,这些弱预测器的线性组合作为最终的预测模型H。算法的初始,弱预测器都是由m个带相同权重D1(i)=1/m的样本训练得到的。ANN弱预测器的性能是使用训练数据的输出估计值和真实值的相对误差来评价的。即ANN的错误率由一个预设的相对误差阈值φ来计算的,φ用来区分预测是正确或错误的。若一个配置的相对误差(Absolute Relative Error,Et(i))大于阈值φ,那么就认为该配置的预测响应是错误的,否则就是正确的。错误预测的数量可以用来计算误差率εt,计算公式如下:
(1)

(2)
式中:Zt为一个标准化因子。在T次迭代以后,如式(3)所示,得到最终的回归模型H,为每个输入配置x分配一个响应值H(x),即预测模型对未模拟配置的性能预测值。
(3)
1.2 基于半监督学习的AdaBoost模型
基于有监督学习的预测模型往往需要模拟大量的配置,才能构建出比较精确的预测模型,模拟成本较高。为了减少模拟次数,一个直观的考虑是利用已有的、大量未模拟的设计配置(也称为未标记样本)来提高预测模型的精度。即采用半监督学习技术,根据少量已经标记的样本为基础,选取置信度较高的未标记样本进行“伪”标记,来增加训练数据集。
因此,本文提出了SSLBoost模型。其基本思想是结合半监督学习和集成学习技术,一方面基于已标记训练样本,利用多个学习器集成地提升为更强的学习器,另一方面,通过自训练(self-training)的半监督学习技术利用未标记样本增加训练数据集的规模,进一步提升模型的预测精度。即将AdaBoost算法引入到半监督学习的过程当中,通过多次迭代训练来提高预测模型的精度。
图2给出了该算法流程图,首先利用已标记样本集L训练AdaBoost模型;然后从未标记样本集U中随机选择一部分组成未标记样本池P,利用AdaBoost对未标记样本池P中的样本进行预测,根据AdaBoost中基本学习器(ANN)对样本的预测结果,对样本进行置信度评估,选择出置信度最高的样本;利用预测结果对其标记(本文称为“伪”标记),添加到训练数据集中,同时在未标记样本池中删除该样本。重复迭代该过程,利用未标记样本来增加训练样本的数量,从而提升预测模型的精度。

图2 基于半监督学习的AdaBoost模型流程图Fig.2 Flowchart of AdaBoost model based on semi-supervised learning
在半监督学习技术中,一个关键的问题就是样本的置信度评估,其直接关系到算法是否选择出有效的未标记样本,影响算法的预测精度[22]。相比半监督分类学习,半监督回归学习中的样本置信度评估更难。分类问题中可以通过比较未标记样本属于不同类别的概率来评估,但回归问题的类别标签是连续的实值,很难找到这样的估计概率。而本文的设计空间探索模型对性能的预测为回归问题。
本文通过2个指标对未标记样本进行置信度评估。①一致性(consistency)指标:AdaBoost模型中基本学习器预测未标记样本分歧越小(即一致性越高)的样本置信度越高;②误差下降指标:将AdaBoost模型预测结果对未标记样本进行“伪”标记,添加到训练样本集中,更新AdaBoost模型,对已标记样本集进行预测,相比没有添加该“伪”标记样本时,使对已标记样本集的预测误差减小的样本,置信度越高。也就是说,如果多个基本学习器对一个未模拟的设计配置预测得出比较一致、分歧很小的性能结果,则可以认为该配置的预测结果是相对稳定且准确的。若同时将该配置加入训练数据集中,使得预测模型对已模拟设计配置的性能预测精度更高,那么该配置就是置信度较高的样本。
本文采用变异系数(coefficient of variation)对未标记样本的一致性进行评估。变异系数为标准差与平均数的比值称,记为C,反应了数据在单位均值上的离散程度。变异系数值越低,代表设计配置的预测结果分歧越小,一致性越高。
算法1给出了SSLBoost算法的伪代码。该算法的目标是迭代地依次扩大已标记的数据集,提升预测模型的精度。在训练过程的每一次迭代,每个学习器预测未标记样本池中的样本,选择出置信度高的样本加入到训练数据集中。在算法开始,由初始训练集初始化AdaBoost.RT模型H。设h1,h2,…,hT为模型H的T个ANN,因为AdaBoost中的每个ANN对未模拟的配置样本预测的结果不同,变异系数越小代表这T个ANN对该样本的预测一致性越高。第i个未标记配置xi的C值由式(4)来计算:
(4)

基于AdaBoost中所有ANN对同一个未标记样本池中的样本预测,对能够达成比较一致的预测结果的、且能够使得模型对已标记样本的预测误差下降的样本,基本上可以断定该样本的预测响应值是非常接近真实模拟响应值的,则可以省去不必要的模拟,将其添加到训练数据集,进而提升AdaBoost模型的预测精度。
算法1SSLBoost算法
输入:已标记的配置集合L, 所有未模拟的配置集合U。
输出:未模拟的配置x的预测性能值。
创建未标记的样本池P,随机从U中选择p个未标记样本到P。
利用L训练出AdaBoost.RT模型H。
迭代K次:
1H预测P中每一个未标记的配置,对于每个未标记样本xi∈P,获取预测结果hj(xi)。
2 计算未标记样本池P中每个未标记样本的变异系数C,基于C值对P中样本升序排序
3 利用模型H预测L,记录百分比误差eL。
4 forn=1∶p
选择C值排名为n的样本xn,将H对xn的预测结果yn=H(xn)作为“伪”标记赋予该样本(xn,yn),加入L形成新的集合L′←L∪{(xn,yn)},更新模型为H′,预测L,记录百分比误差eL′。
IfeL′ 样本xn是置信度最高的样本,记录π←(xn,yn) 跳出循环; 5 ∥更新L和P P←P-π;L←L∪π 6 利用新的集合L重新构建Adaboost模型H。 7 从U中随机挑选出来的样本来补充未标记样本池P,使其大小为p。 8 输出预测结果H(x)。 本文采用科研领域广泛使用的周期精准的模拟器GEM5[23]模拟应用程序在多核处理器多种配置之上的性能。由于多核处理器主要关注并行程序的执行性能,因此本文选取了PARSEC(The Princeton Application Repository for Shared-memory Computers)基准测试集[24],一个多线程应用程序组成的测试程序集。该程序集代表了未来运行在片上多核系统中的共享内存应用程序的发展趋势。本文从中选取了10个程序来对设计空间进行评估,包括blackscholes、bodytrack、canneal、dedup、facesim、ferret、fluidanimate、freqmine、streamcluster和vips等。由于基准程序中需要模拟的动态指令过多,本文采用了快速模拟技术SimPoint来模拟1亿条有代表性的指令,来节省每次模拟的模拟时间。本文采用执行时间作为性能响应。 表1给出了本文需要探索的多核处理器设计空间,涉及了10个主要与存储系统密切相关的设计参数。这些设计参数的不同组合构成的设计空间包含了超过419万个(4 194 304个)不同的设计配置。 本文采用均匀随机采样的方法对设计空间分别采集了2 200个设计进行模拟,从中随机选择200个样本作为训练数据集,剩余2 000个样本作为测试数据集。本文将构建的预测模型对测试数据集进行预测的误差作为对模型准确性的评估。 表1 多核设计空间 为了评估本文所提的基于半监督集成学习的设计空间探索方法对多核处理器建模的有效性,本文主要针对以下3个方面进行实验评估:①对SSLBoost模型中的集成学习算法AdaBoost的有效性进行评估,通过与ANN性能进行比较,来验证AdaBoost能否有效提升ANN的性能。②对SSLBoost模型中半监督学习算法的有效性进行评估,通过对比SSLBoost模型和有监督学习的AdaBoost模型的性能,来验证半监督学习算法的有效性。本文所采用的对未标记样本进行置信度评估的2个指标,是半监督集成学习算法的主流成熟技术,具有广泛的应用[22,25-26]。其中,一致性指标能够保证多个基本学习器ANN对样本预测的确定性,确定性越高即分歧越小的样本的预测准确率越高,属于预测器已经学习到的知识[22-25];误差下降指标也是半监督学习中增加样本的一个普遍采用的评价指标[26]。③将SSLBoost的预测结果与当前主流的设计空间探索方法进行了比较,包括基于ANN[11]和基于SVM[13]的预测模型。对于ANN,本文实验中的参数设置与文献[11]中的设置一致,即包含一个16个神经元的隐含层,learning rate为0.001,而momentum为0.5。对于SVM,本文采用LIBSVM[27]中所提供的参数选择工具来对每个程序分别自动搜索最优的训练参数,以得到精确的预测模型。本文的SSLBoost模型中的基本学习器ANN设置的是双隐含层,每层8个神经元,其他参数设置与文献[11]中的一致。ANN基本学习器设为20个。半监督迭代次数K设为100,也就是说,本文训练样本集经过半监督学习后,被扩大到300的规模。鉴于训练样本集是随机采样的,对所有方法运行10次取预测误差的平均值作为模型的预测误差。 图3(a)、(b)分别给出了在多核处理器设计场景下,上述方法对于性能的预测误差RMAE和MSE的对比结果,Avg为平均值。从图3可以看出,SSLBoost模型的RMAE分别比SVM、ANN和AdaBoost模型平均降低了7.6%、5.2%和1.5%。尤其是较难预测的程序streamcluster,SSLBoost与SVM、ANN和AdaBoost模型相比,RMAE平均降低了14%、10%和4.2%。图3(b)展示了以ANN的预测误差作为标准,几种方法经过归一化处理后的MSE对比。可以看出,SVM、ANN和AdaBoost模型的MSE平均是SSLBoost模型的4.9倍、3.1倍和1.5倍。 以上实验结果表明,在同样的模拟次数(200)开销下,本文提出的设计空间探索方法可以显著地提升预测模型精度。与ANN相比,有监督的AdaBoost算法能够明显提升ANN的预测精度,并且鲁棒性较好,表明了本文所采用的集成学习算法的有效性。而SSLBoost模型是结合了半监督学习算法的AdaBoost模型,因此SSLBoost模型的预测精度高于原始的AdaBoost模型,则表明了本文提出的半监督学习算法的有效性。SSLBoost不但利用了有标记样本对单个样本精确描述的优势,而且发挥了无标记样本对训练数据集整体描述的重要作用,从而使训练出的模型具有更好的泛化性能,充分体现了半监督学习的优势。 为了评估半监督学习的迭代过程中预测模型的精度变化,本文以基准程序vips为例,图4(a)给出预测模型的RMAE随着迭代过程的变化;图4(b)给出将迭代初始的预测误差MSE作为标准进行归一化后,MSE随着迭代过程的变化。RMAE基本是随着迭代次数的增长均匀逐渐下降的,MSE在迭代次数大于10时,下降幅度较大,之后趋于平缓。由于初始训练样本集的限制,从未模拟配置中学习到的知识是有限的,当逐渐用尽能够提升预测模型精度的优秀未标记样本后,再选择的置信度高的未标记样本,对于训练数据集来说是冗余的。 图3 在多核设计场景下不同方法的预测精度对比Fig.3 Prediction accuracy comparsion of different methods in multicore design scenarios 图4 多核设计场景下SSLBoost模型关于不同数量的训练迭代次数的预测精度Fig.4 Prediction accuracy of SSLBoost model with respect to different numbers of training iterations in multicore design scenarios 由3.2节表明,本文提出的SSLBoost模型的预测精度在配置模拟次数相同的情况下优于其他2种方法(ANN和SVM)。本节则评估ANN、SVM分别需要多少训练模拟样本才能达到与SSLBoost模型相同的预测精度。 对于每个基准程序,和3.2节相同,采用200个均匀随机采样的训练样本来构建SSLBoost模型、ANN和SVM。从2.2节提到的2 000个测试样本集中均匀随机采样选出300个样本,作为ANN和SVM的备用训练集。为公平起见,剩余的1 700个样本作为3种方法的共同测试样本集。然后从备用训练数据集中随机选择10个样本加入到训练数据集中,重新构建ANN和SVM,检验ANN和SVM的预测精度是否达到SSLBoost的预测精度。重复这个过程,利用10个样本作为增长步长,直到ANN和SVM达到与SSLBoost相同的预测精度,或者用尽备用训练数据集里的样本。 从表2可以看出,ANN和SVM分别需要191%、228+%的模拟样本,才能达到和SSLBoost模型相当的预测精度。“+”表示对于一些基准程序,ANN或SVM用尽了所有备用训练样本(300),还是不能达到SSLBoost模型的预测精度。总之,SSLBoost模型能够节省大量的训练模拟。 表2 为达到SSLBoost模型相同的预测精度,ANN和SVM所需要的模拟配置(训练样本)数量Table 2 Numbers of simulated configurations (trainingexamples) required by ANN and SVM to achieve thesame level of prediction accuracy as SSLBoost model 通常来说,模拟108条指令需要10 min以上的模拟的时间。基于本文的训练数据集,SSLBoost的训练时间从0.5~1 h不等(随基准程序变化)。虽然比ANN和SVM的训练开销时间(秒级)要长,但是节省了更多的模拟次数,即减少了大量的模拟时间开销。实际在工业实践中,每个程序的全部动态指令数目通常都有数109、甚至1010条。在这种情况下,SSLBoost模型的训练开销与模拟开销相比基本上可以忽略不计。因此,3.3节的模拟次数比较,也表明了SSLBoost模型能够极大地减少设计空间探索时间。 通常来说,除非将整个设计空间中的配置都模拟了,才能找到最优的配置,但这是不可行的。一个折中方案是对比由SSLBoost模型预测出的最优配置和由现有设计空间探索方法ANN和SVM预测的最优配置相对比。具体来讲,从整个设计空间中随机采样3 000个配置,然后利用这3种方法来预测这3 000个配置的性能响应,从而寻找到其中的最优配置。最后模拟3种方法找到的最优配置,并直接比较其真实的模拟性能响应。以基准程序vips为例,表3展示了SSLBoost模型和其他2种模型预测的最优配置以及预测精度(RMAE)。这里ANN、SVM的训练样本集和SSLBoost模型的初始训练集大小都为200,测试样本集合大小为2 000。从表3可以看出,与其他2种方法相比,SSLBoost模型寻找的最优配置的性能最好,并且,SSLBoost模型对该配置预测的性能响应非常接近这个配置的真实模拟性能,仅仅3.5%的预测误差。而其他2个方法得到的最优配置性能都较低,且预测精度也较低(误差为12.9%、23.8%)。因此,在探索更优配置方面,SSLBoost模型无论在准确性和还是有效性上都优于ANN和SVM。 表3 各种模型预测的最优配置对比(vips) 本文提出了一种有效且高效的结合集成学习和半监督学习算法的多核设计空间探索框架。实验结果表明: 1) 采用集成学习算法AdaBoost模型来集成ANN的预测模型能够有效地提升ANN的预测精度。 2) 半监督集成学习模型SSLBoost模型利用未标记配置来扩充训练样本集,在相同的模拟代价下,相比现有的基于ANN和SVM的探索方法,能够极大地降低模型的预测误差。 3) 相比基于ANN和SVM的方法,SSLBoost模型能够使用更少的模拟样本来达到相当的预测精度。 因此,本文所提出的多核设计空间探索方法SSLBoost模型比现有的探索方法更加高效、准确。 参考文献 (References) [1] NOONBURG D B,SHEN J P.Theoretical modeling of superscalar processor performance[C]∥Proceeding of International Symposium on Microarchitecture.New York:ACM,1994:52-62. [2] KARKHANIS T S,SMITH J E.Automated design of application specific superscalar processors:An analytical approach[C]∥Proceedings of the 34th International Symposium on Computer Architecture.New York:ACM,2007:402-411. [3] HAMERLY G,PERELMAN E,CALDER B.How to use SimPoint to pick simulation points[J].ACM Sigmetrics Performance Evaluation Review,2004,31(4):25-30. [4] WUNDERLICH R E,WENISCH T F,FALSAFI B,et al.SMARTS:Accelerating microarchitecture simulation via rigorous statistical sampling[C]∥Proceedings of the 30th Annual International Symposium on Computer Architecture.New York:ACM,2003:84-97. [5] WANG S,HU X,YU P S,et al.MMRate:Inferring multi-aspect diffusion networks with multi-pattern cascades[C]∥ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York:ACM,2014:1246-1255. [6] WANG S,LI Z,CHAO W,et al.Applying adaptive over-sampling technique based on data density and cost-sensitive SVM to imbalanced learning[C]∥ International Symposium on Neural Networks.Piscataway,NJ:IEEE Press,2012:1-8. [7] JOSEPH P J,VASWANI K,THAZHUTHAVEETIL M J.Construction and use of linear regression models for processor performance analysis[C]∥Proceedings of the 12th International Symposium on High-Performance Computer Architecture.Piscataway,NJ:IEEE Press,2006:99-108. [8] JOSEPH P J,VASWANI K,THAZHUTHAVEETIL M J.A predictive performance model for superscalar processors[C]∥Proceedings of the 39th Annual IEEE/ACM International Symposium on Microarchitecture.Piscataway,NJ:IEEE Press,2006:161-170. [9] LEE B C,BROOKS D M.Accurate and efficient regression modeling for microarchitectural performance and power prediction[C]∥ Proceedings of 12th International Conference on Architectural Support for Programming Language and Operating Systems.New York:ACM,2006:185-194. [10] LEE B C,COLLINS J,WANG H,et al.CPR:Composable performance regression for scalable multiprocessor models[C]∥ Proceedings of the 41 st Annual IEEE/ACM International Symposium on Microarchitecture.Piscataway,NJ:IEEE Press,2008:270-281. [11] ÏPEK E,MCKEE S A,CARUANA R,et al.Efficiently exploring architectural design spaces via predictive modeling[C]∥Proceedings of 12th International Conference on Architectural Support for Programming Language and Operating Systems.New York:ACM,2006:195-206. [12] 郭崎,陈天石,陈云霁.基于模型树的多核设计空间探索技术[J].计算机辅助设计与图形学学报,2012,24(6):710-720. GUO Q,CHEN T S,CHEN Y J.Model tree based multi-core design space exploration[J].Journal of Computer-Aided Design & Computer Graphics,2012,24(6):710-720(in Chinese). [13] PANG J F,LI X F,XIE J S,et al.Microarchitectural design space exploration via support vector machine[J].Acta Scientiarum Naturalium Universitatis Pekinensis,2010,46(1):55-63. [14] PALERMO G,SILVANO C,ZACCARIA V.ReSPIR:A response surface-based Pareto iterative refinement for application-specific design space exploration[J].IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems,2009,28(12):1816-1829. [15] XYDIS S,PALERMO G,ZACCARIA V,et al.SPIRIT:Spectral-aware Pareto iterative refinement optimization for supervised high-level synthesis[J].IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems,2015,34(1):155-159. [16] GUO Q,CHEN T,ZHOU Z H,et al.Robust design space modeling[J].ACM Transactions on Design Automation of Electronic Systems,2015:20(2):18. [17] LI D,YAO S,LIU Y H,et al.Efficient design space exploration via statistical sampling and AdaBoost learning[C]∥Design Automation Conference.New York:ACM,2016:1-6. [18] KHAN S,XEKALAKIS P,CAVAZOS J,et al.Using predictivemodeling for cross-program design space exploration in multicore systems[C]∥Proceedings of the 22nd International Conference on Parallel Architectures and Compilation Techniques.Piscataway,NJ:IEEE Press,2007:327-338. [19] DUBACH C,JONES T,OBOYLE M.Microarchitectural design space exploration using an architecture-centric approach[C]∥Proceedings of the 40th Annual IEEE/ACM International Symposium on Microarchitecture.Piscataway,NJ:IEEE Press,2007:262-271. [20] LI D,WANG S,YAO S,et al.Efficient design space exploration by knowledge transfer[C]∥Eleventh IEEE/ACM/IFIP International Conference on Hardware/software Codesign and System Synthesis.New York:ACM,2016:1-10. [21] SHRESTHA D L,SOLOMATINE D P.Experiments with AdaBoost.RT,an improved boosting scheme for regression[J].Neural Computation,2006,18(7):1678-1710. [22] ZHOU Z H,LI M.Semi-supervised learning by disagreement[J].Knowledge and Information Systems,2010,24(3):415-439. [23] BINKERT N,BECKMANN B,BLACK G,et al.The gem5 simulator[J].ACM SIGARCH Computer Architecture News,2011,39(2):1-7. [24] BIENIA C,KUMAR S,SINGH J P,et al.The PARSEC benchmark suite:Characterization and architectural implications[C]∥Proceedings of the 17th International Conference on Parallel Architecture and Compilation Techniques.New York:ACM,2008:72-81. [25] HAMED V,RONG J,ANIL K.Semi-supervised boosting for multi-class classification[C]∥European Conference on Principles of Data Mining and Knowledge Discovery,2008:522-537. [26] ZHOU Z H,LI M.Semi-supervised regression with co-training[C]∥Proceedings of the 19th International Joint Conference on Artificial Intelligence.New York:ACM,2005:908-913. [27] CHANG C C,LIN C J.LIBSVM:A library for support vector machines[J].ACM Transactions on Intelligent Systems and Technology,2011,2(3):27-1-27-27.2 实验方法与环境
2.1 模拟器及基准测试程序
2.2 处理器设计空间

3 模型评估与比较
3.1 评估指标

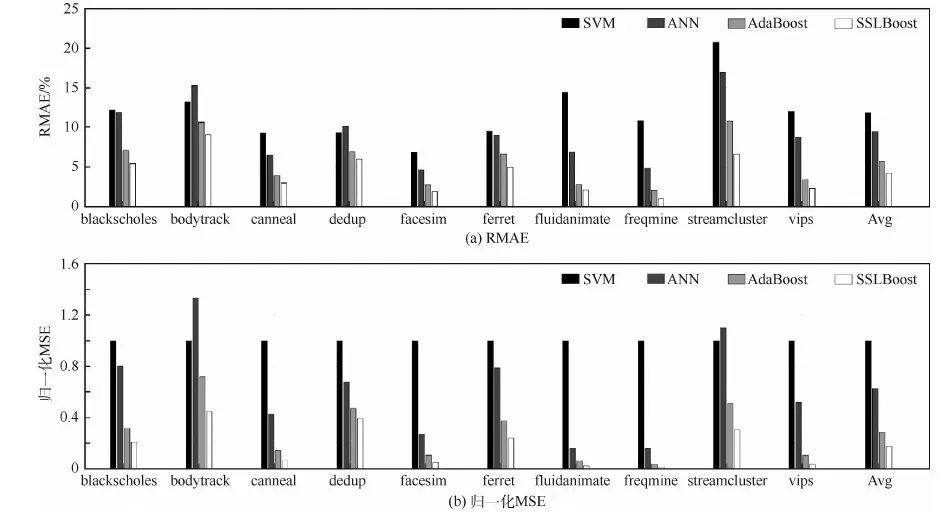
3.2 预测精度评估

3.3 模拟次数

3.4 设计空间探索时间
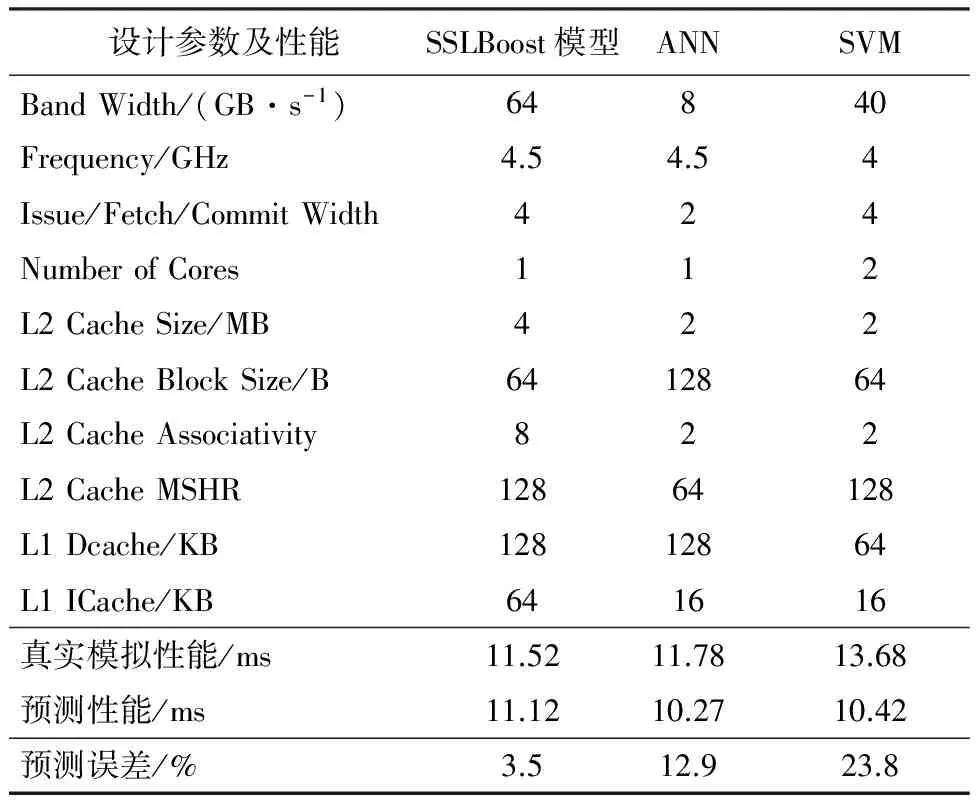
3.5 探索更优配置
4 结 论
猜你喜欢
导航定位学报(2022年5期)2022-10-13
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
一重技术(2021年5期)2022-01-18
中学生数理化(高中版.高一使用)(2021年2期)2021-03-19
领导决策信息(2018年16期)2018-09-27
数学学习与研究(2017年3期)2017-03-09
华人时刊(2016年16期)2016-04-05
