
一种基于感知哈希选择的最邻近入侵检测方法
2018-05-03 06:14江泽涛韩立尧
计算机应用与软件 2018年4期
江泽涛 韩立尧 徐 智
(桂林电子科技大学广西可信软件重点实验室 广西 桂林 541004) (桂林电子科技大学计算机与信息安全学院 广西 桂林 541004)
0 引 言
KNN做入侵检测时具有建模时间短,受样本分布影响小等优点,因此被广泛应用到入侵检测中。为了提高KNN检测的准确率,Jamshidi 等[10]提出在KNN入侵检测中采用网格理论来计算检测对象之间的相似度,但是却增加了计算方面的开销。Liao等[11]利用批处理的思想提出了使用短时间序列方法来描述检测对象,但是构建短序列却需要大量的专家知识,这无形中增加了系统的复杂性。Zhao等[12]提出了两阶段KNN分类法来减少训练样本的数量却忽略了构建基向量带来的存储开销。
本文针对上面KNN入侵检测中存在的问题,提出了利用感知哈希来描述检测对象的方法和一种利用杂交带精简训练集合的方法。这种变精度的入侵检测方法可以在保持高检测率的情况下提高入侵检测的速度。
1 传统的KNN算法
K最近邻KNN是用来做分类的常用方法,其基本思想是相似的样本在特征空间中必定相邻。采用KNN做分类时一般分为两个阶段。
(1) 特征映射阶段 将训练集合与测试集合中的样本采用相同的方式映射到特征空间中。同时初始化用来做近邻分析的样本个数K。
(2) 分类阶段 计算待分类样本与训练集合中所有样本的相似度,选择相似度最大的前K个样本作为分类依据,然后采用相关规则做投票选择,将它归类为K个样本中出现频率最高的类。
2 基于感知哈希的KNN入侵检测
2.1 选择距离度量
在当前的KNN算法中,基于距离的度量函数主要有三种,曼哈顿距离(manhattan Distance),欧几里得距离(Euclidean Distance),车比雪夫距离(Chebyshev Distance),明氏距离(Minkowski Distance)。针对上面的几种距离,本文在KDDCUP99数据集上分别选择K为3、5、10做了相关的测试,测试结果如表1所示。
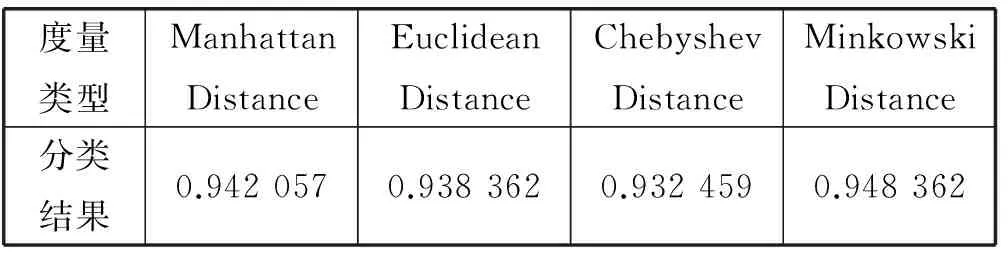
表1 不同度量函数在KNN分类中的结果
从表1中可以看出采用曼哈顿距离作为相似度距离度量时,分类结果与明氏距离最为接近且计算开销最小。因此本文采用曼哈顿距离作为构造感知哈希函数的度量准则。
2.2 生成检感知哈希摘要
本文借鉴了传统感知哈希摘要的生成方法,并且在特征提取和量化编码方面做了相关的改进以适应入侵检测的需要。改进后的感知哈希生成流程图如图1所示。

图1 感知哈希生成模块
1) 特征提取流程
(1) 特征向量提取:将收集到的系统摘要转化为其相应的属性表示,取不同的系统摘要属性表示的并集,将每一个系统摘要转化为该并集表示的一个特征向量X=[x1,x2,…,xn]。其中n为并集集合中元素的个数。对于系统摘要中没有的属性,则做留空处理。
(2)特征向量筛选:删除特征向量提取阶段中产生的重复的特征向量和由于系统噪声带来的异常特征向量,从而保证训练模型的精度。
2) 特征量化流程
(1) 按照式(1)计算特征向量的质心分布:
(1)
质心的每一个分量是所有向量分量的均值。其中j为向量f的第j个特征分量,l为向量f的维度。
(2) 按照式(2)计算各个分量的方差:
fd(j)=fc([fi(j)-fc(j)]2)
(2)
同时删除方差为0的分量。方差代表了检测对象在每一个维度上的波动情况。
(3) 以质心和方差为衡量标准,对每一个特征的分量按照式(3)进行量化:
(3)
式中:N为样本的大小,M为每一个样本的维度。
3) 特征编码流程
对经过量化后的特征向量按照式(4)进行哈希编码:

(4)
式中:xi,j代表被检测对象i的第j个分量。Wj表示第j个分量的权重因子,W的确定依赖于特定的检测对象,在实验部分将给出W的确定方法。
根据上面的方法可以为相似的对象赋予相同的感知哈希值,从而完成了粗粒度分类。但是由于存在不同属性之间属性值相互抵消的问题,即不同类别的对象可能有相同的感知哈希值,因此需要建立杂交带来完成细粒度分类。
2.3 基于杂交带的KNN算法
为了减少K近邻分类过程中的时间开销和空间开销,文献[13]提出了超球面的概念,即以被检测对象在特征空间中所在的位置为球心,以某个相似度阈值的倒数为半径,将相似度大于该阈值的测试样本加入到超球面中,从而构造了如图2所示的超球面。
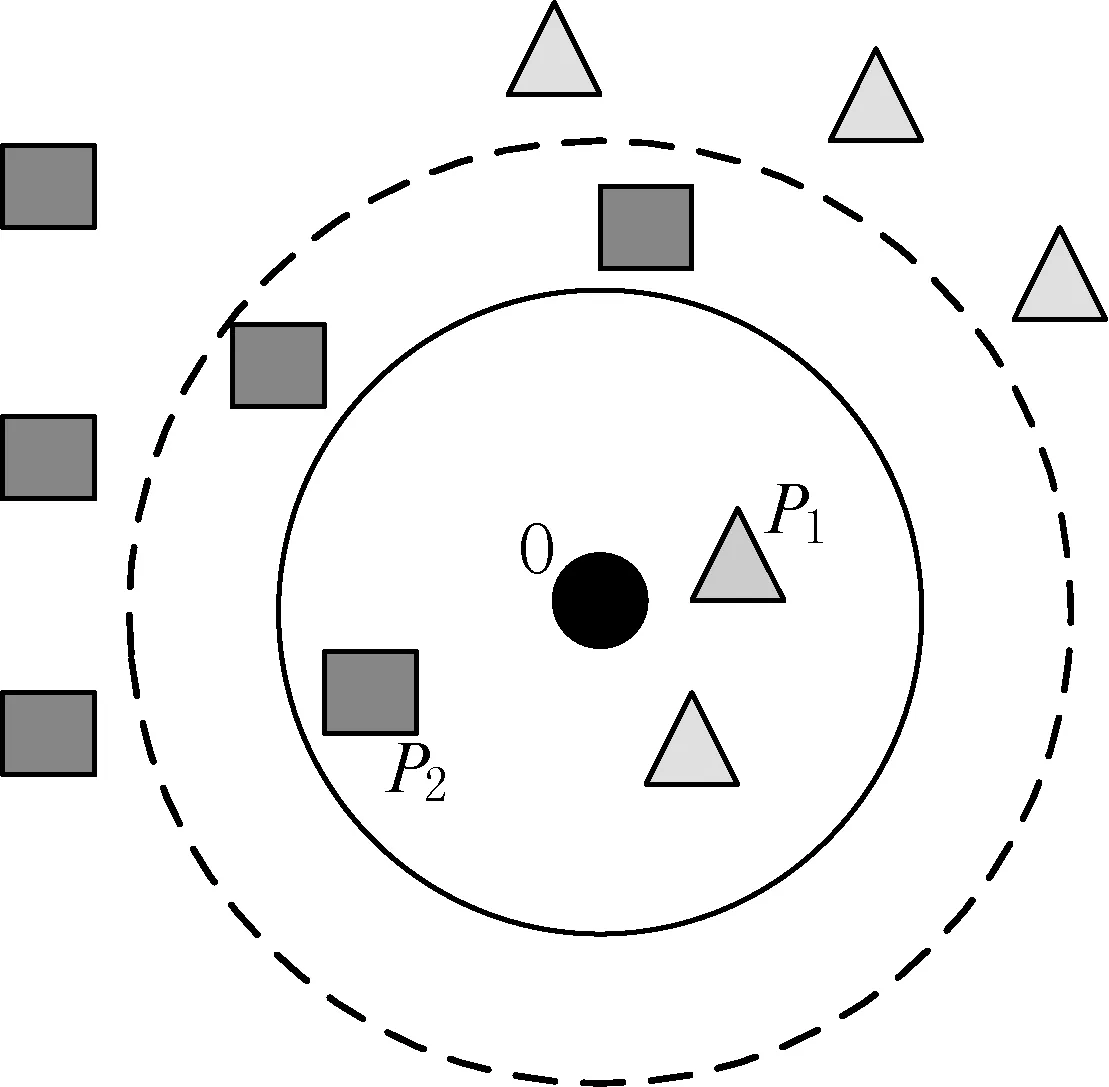
图2 超球面
在图2中,球心O表示待分类的样本在特征空间中的位置,P1、P2表示训练集中与该样本超过相似度阈值的样本,由这些样本点构成一个超球面,它们的比例决定了检测对象的类型。由此可以推断出待分类样本在特征空间中所在的位置只有如图3所示的三种可能。
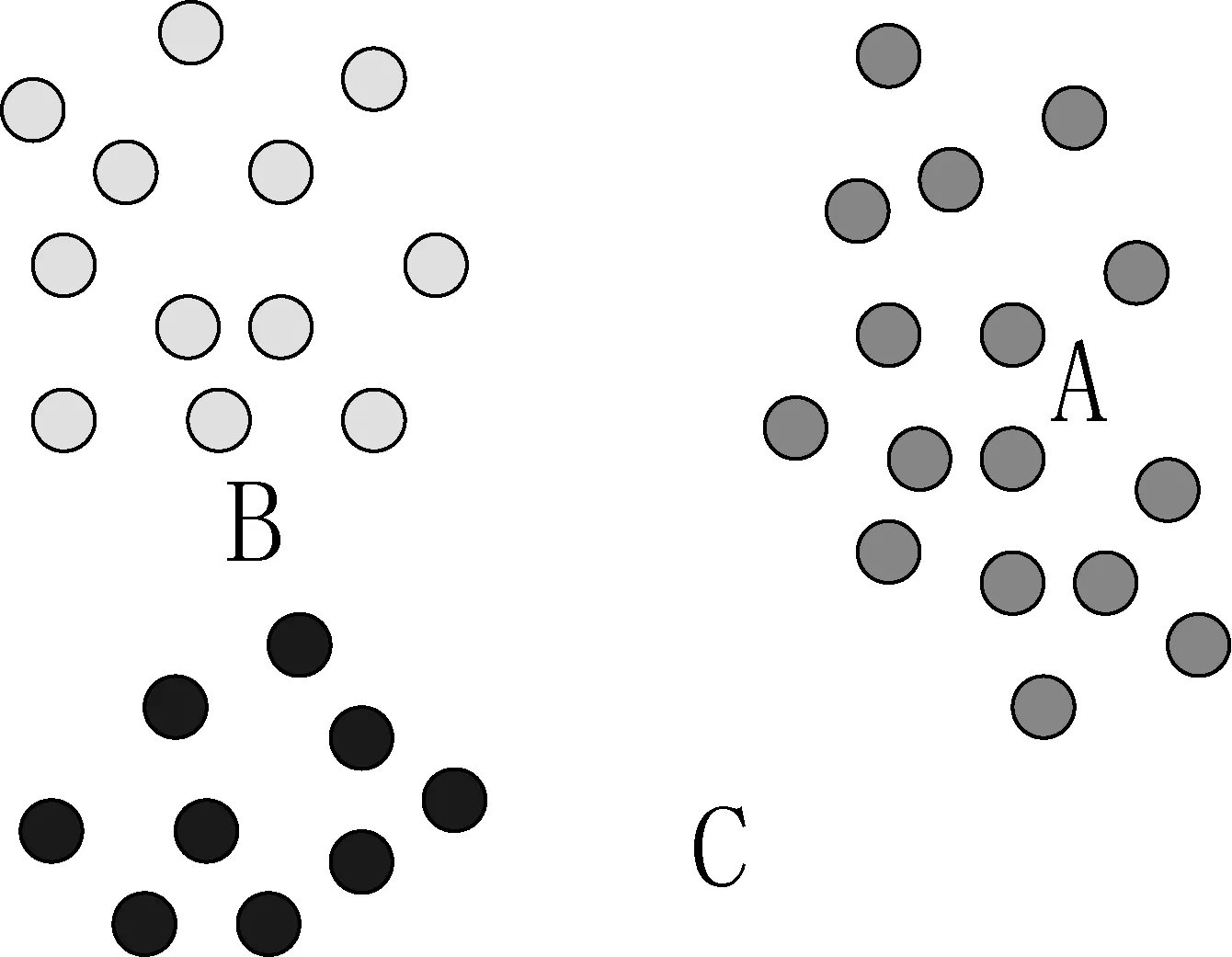
图3 样本在特征空间中的分布
(1) 如果待分类样本位于特征空间中的A点的时候,在按照图2的方式构造的超球面内P1和P2将属于同一种类型。(2) 如果待分类样本位于特征空间中B点位置,则P1和P2将属于不同类型。(3) 如果待分类样本位于特征空间中的C点的位置,则超球面内没有样本点。
本文在此基础上提出了特征空间杂交带的概念。杂交带是指在训练集合上构成的特征空间中,由位于图3中B处的样本构成的数据边界集合。杂交带区域如图4所示。
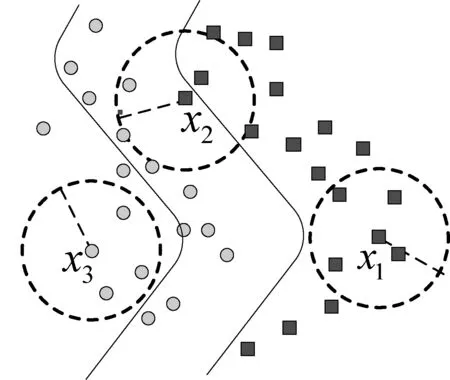
图4 特征空间杂交带
在图4中,x1、x3代表杂交带外部的特征向量,x2代表杂交带内部的特征向量。可以看出,在给定相似度阈值θ的情况下,位于杂交带内部的特征向量按照图2方式构造的超球面内存在不同类型的特征向量。而x1和x3对应的超球面内只有一种类型的特征向量。算法1将给出杂交带的构造方法,其中θ是由特征空间中样本的分布来决定的。本文在实验部分将给出阈值θ与生成杂交带的关系和相应的确定方法。
算法1杂交带构建算法
输入Train={(x1,y1),(x2,y2),…,(xn,yn)}为训练集合
Test={(x1,y1),(x2,y2),…,(xm,ym)}为测试集合
Cross={}为杂交带集合
_Cross={}为非杂交集合
θ相似度阈值
输出Set={}为特征空间的杂交带
构建杂交带算法步骤如下:
1) 对于Train集合中的训练数据做数值化和归一化处理。然后将其映射到特征空间中。
2) 根据式(1)-式(4)计算Train集合中每一个检测对象的感知哈希值。
3) 在由相同感知哈希值构成的子集T上计算训练样本相似度(公式见3.2节中的式(6)),如果存在两个相似度大于θ的不同类别的样本,则将这两个样本同时加入到Cross集合中。
4) 将训练集合中剩余的特征向量加入到非杂交带集合_Cross中。
2.4 阈值测评值
定义1阈值测评值 选取某一个阈值θ下的检测率与误报率的比值。以T_DSθ表示阈值测评值,则:
(5)
式中:θ表示建立杂交带时选定的阈值;DRθ表示该阈值下的检测率;FRθ表示该阈值下的误报率。若在某一个阈值下检测率越高,误报率越低,其阈值测评值越大,表示分类能力越好。
2.5 入侵检测算法
根据上述的感知哈希和杂交带方法构造如图5的入侵检测模型 。
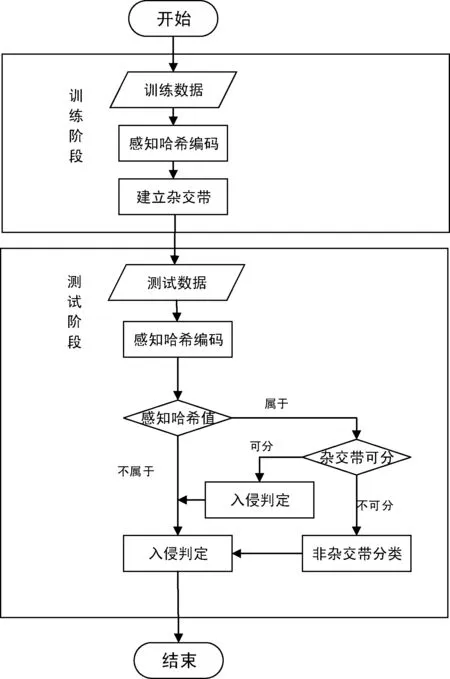
图5 本文算法流程图
在图5所示的入侵检测模型中,首先按照2.2节的方法将训练样本映射到特征空间中同时计算他们的感知哈希值。按照感知哈希值将训练集合分为若干个子集合,在这些子集合上用算法1构建杂交带和非杂交带,并且通过交叉验证的方式确定杂交带相似度阈值θ。在测试阶段,将待分类样本转化为特征向量并且计算其感知哈希值。如果可以找到该感知哈希值对应的训练子集,首先在该子集的杂交带上按照投票选择法完成分类任务。如果该杂交带不能完成分类任务,则在这个子集的非杂交带上按照投票选择法完成分类任务。如果无法在训练集合上找到对应的哈希值,则直接判定为异常入侵。从而完成网络入侵检测。
3 实验与分析
本实验采用的数据集为KDDCup99,每一条记录均是由从一条原始链接中抽取的41维特征组成。其中分别包含了9个基本连接特征,13个内容连接特征和19个网络流量特征。在KDDCUP99上抽取10%的数据用来做训练,另外的90%的数据用来做测试。
3.1 数据预处理
(1) 数据去重 由于网络的不稳定性以及数据采集中存在噪声等因素,训练集合中存在着大量重复的样本。重复的样本不仅会带来时间上的开销还增大某种入侵类型的概率密度,从而对分类的精度造成影响,因此需要对数据做去重处理。训练样本去重前后的变化如表2所示。
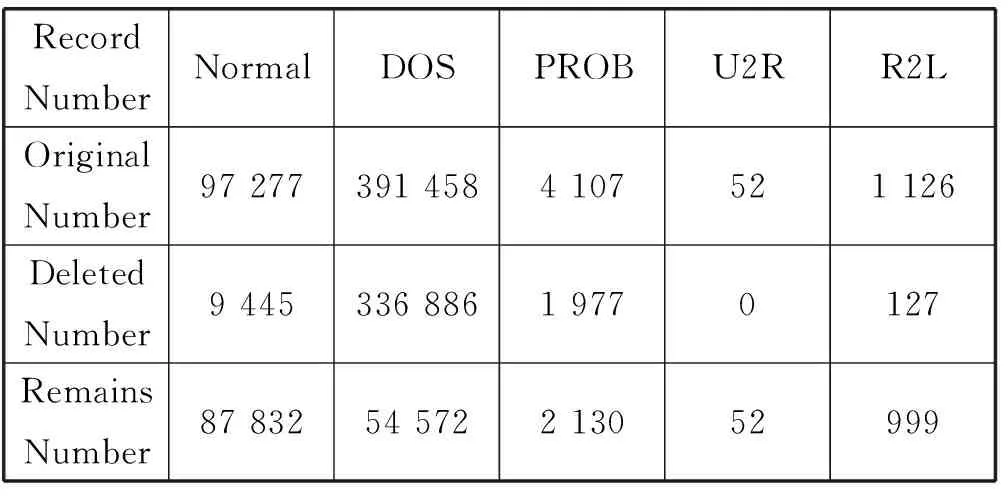
表2 训练集合去重前后
(2) 数据的标准化 为了消除不同量纲对相似度计算造成的影响,这里采用z-scope来对数据做标准化,即:
新数据=(原始数据-均值)/标准差
3.2 样本之间相似度计算
D为训练集合,即D={(x1,y1),(x2,y2),…,(xn,yn)},n为训练集合中样本的个数。对于记录xi,它是由df维的特征表示,即xi={xi,1,xi,2,…,xi,df}。训练集合中存在c类攻击,则y∈{1,2,…,c+1}。
在集合D中对于任意两个样本xi和xj,其中i,j∈{1,2,…,N}。式(6)给出了样本之间相似度的计算方法:
(6)
3.3 相似度阈值的选取
下面在由训练集合中抽取感知哈希值为-1的样本组成的子集合上做杂交带测试,其中包含399个正常样本和235个异常样本。不同的相似度阈值θ与杂交带的对应情况如表3所示。
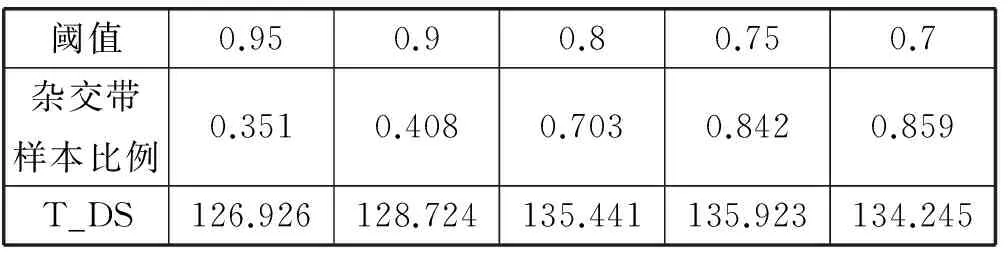
表3 哈希值为-1不同阈值下杂交带样本比例
在由训练集合中抽取感知哈希值为0的样本组成的子集合上做杂交带测试,其中包含114个正常样本和22 331个异常样本。实验的结果如表4所示。
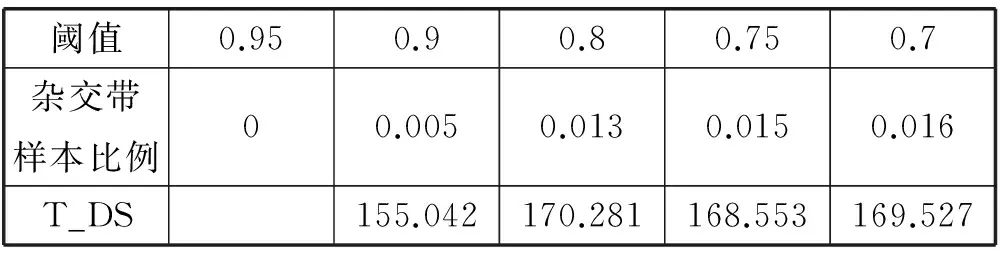
表4 哈希值为0不同阈值下杂交带样本比例
从上面的实验结果可以看出,边界阈值θ越小,则杂交带中的样本越多。而阈值测评值则随着阈值的降低而提高,最终会在某个值附近波动。由此说明该由该阈值构造的杂交带集合可以近似表示其对应原始集合。后面的实验将证明通过用杂交带缩减训练样本,可以在保证高检测率的同时降低时间开销。
3.4 相同哈希值下的分类器性能比较
下面将本文方法与NB[15]、SVM[16]、Decision Tree[17]做比较。在感知哈希值为0的子集合上随机选取80%的数据做训练,20%的数据做测试。实验结果如表5所示。
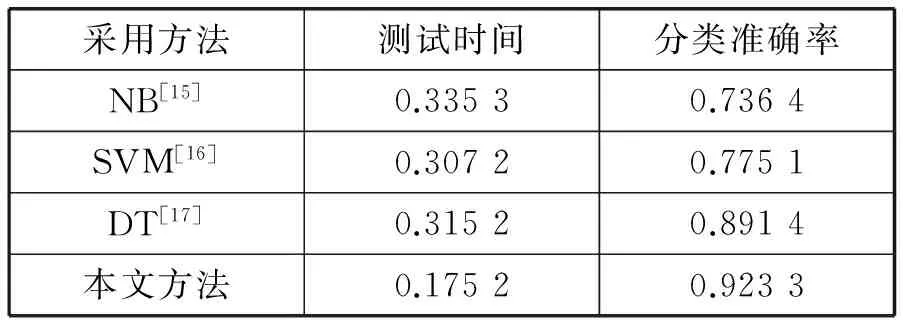
表5 不同小样本分类器比较
从表5中可以看出应用本文方法在做小样本分类的时候测试时间短,分类准确率高。原因在于NB算法的准确率依赖于其在训练集样本上先验知识的获取,同时需要保证训练样本与测试样本中在特征空间中分布的一致性。SVM则通过核方法将线性不可分的样本投影到高维空间变得线性可分,但是在样本数量少且特征维度高的情况下容易梯度爆炸从而影响分类器的性能。DT算法在训练集上建立决策规则,但是较少的训练样本使得决策规则很难刻画对象在特征空间的分布。而本方法可以在缩减了样本的同时不受样本在特征空间中分布的影响,从而取得较好的结果。
3.5 不同特征选取下哈希选择算法
下面采用不同的特征选择方法来确定式(4)中的权重W,即在KDDCUP99上分别采用GFR[18]、F-Score[19]、IIG[20]做特征选择,结果如表6所示。
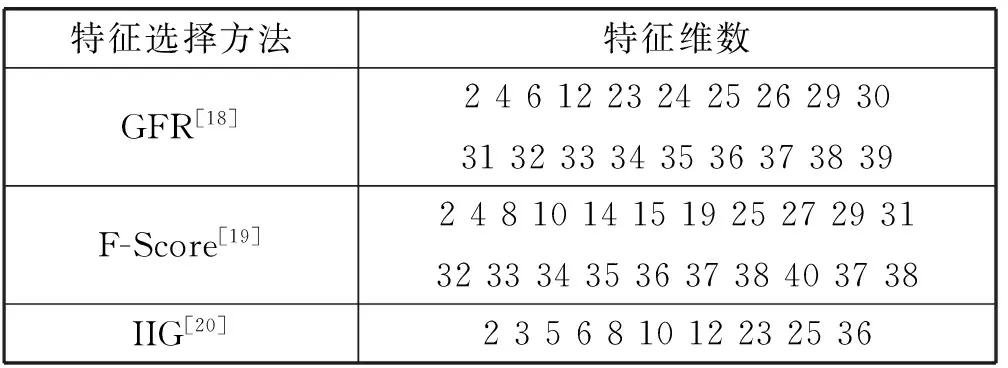
表6 特征选择算法
针对上面的三种特征选择方法,图6、图7中展示了不同选择方法的准确率和它们在时间上面的开销。
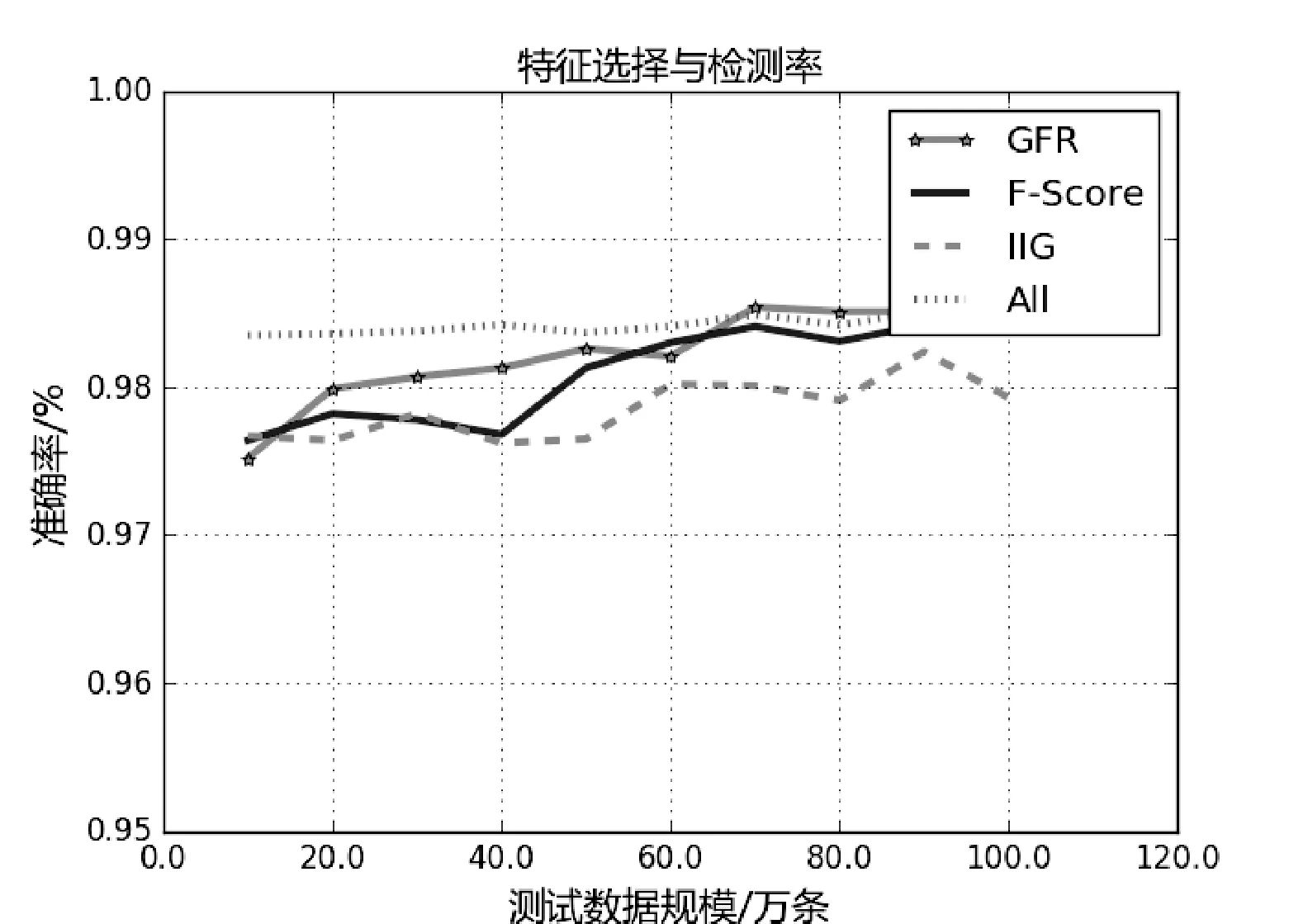
图6 特征选择准确率
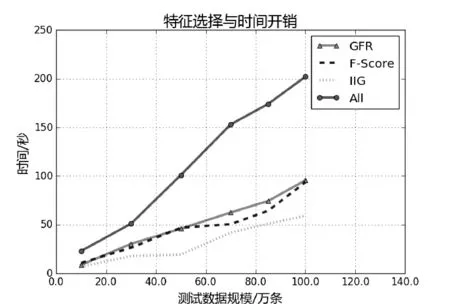
图7 特征选择时间消耗
从图6中可以看出用所有特征来构造哈希函数会增大计算开销大,但是在检测对象较少的时候,检测效果明显优于其他方法。另一方面随着检测样本的增多,特征选择带来的负面影响越来越小。从图7中可以看出特征选择方法可以减少入侵检测系统开销并且随着检测样本的增多,这种优势越发明显。综上所述,当分类样本较少的时候,一般采用全部特征来计算其感知哈希值,当检测对象较多的时候,一般采用GRF[18]选择的特征来计算被检测对象的感知哈希值。
3.6 最邻近哈希选择算法的抗压测试
下面对本文算法做压力测试,测试的平台为Intel(R) Core(TM)i5-3337U (1.8 GHz)笔记本。采用KDDCUP99的测试集。其相关信息如表7所示。

表7 KDDCUP99数据
在图8中,横坐标代表用来做入侵检测的数据规模,纵坐标代表在给定规模下做入侵检测需要的时间。从图6、图7中可以看出正常检测的时间开销大于异常检测。主要原因在于通过感知哈希值可以很好地找到大部分异常样本,而正常样本的确定需要在杂交带上做相似度计算,因此增大了系统的开销。经实验测定,本文的方法检测一条入侵样本需要的时间为1e-6 s,正常样本的时间为1e-3 s,平均的时间为1e-5 s。从实验测定的数据可以看出本文提出的入侵检测方法可以满足当前实时性的要求,并且对于异常样本具有较高的敏感性。
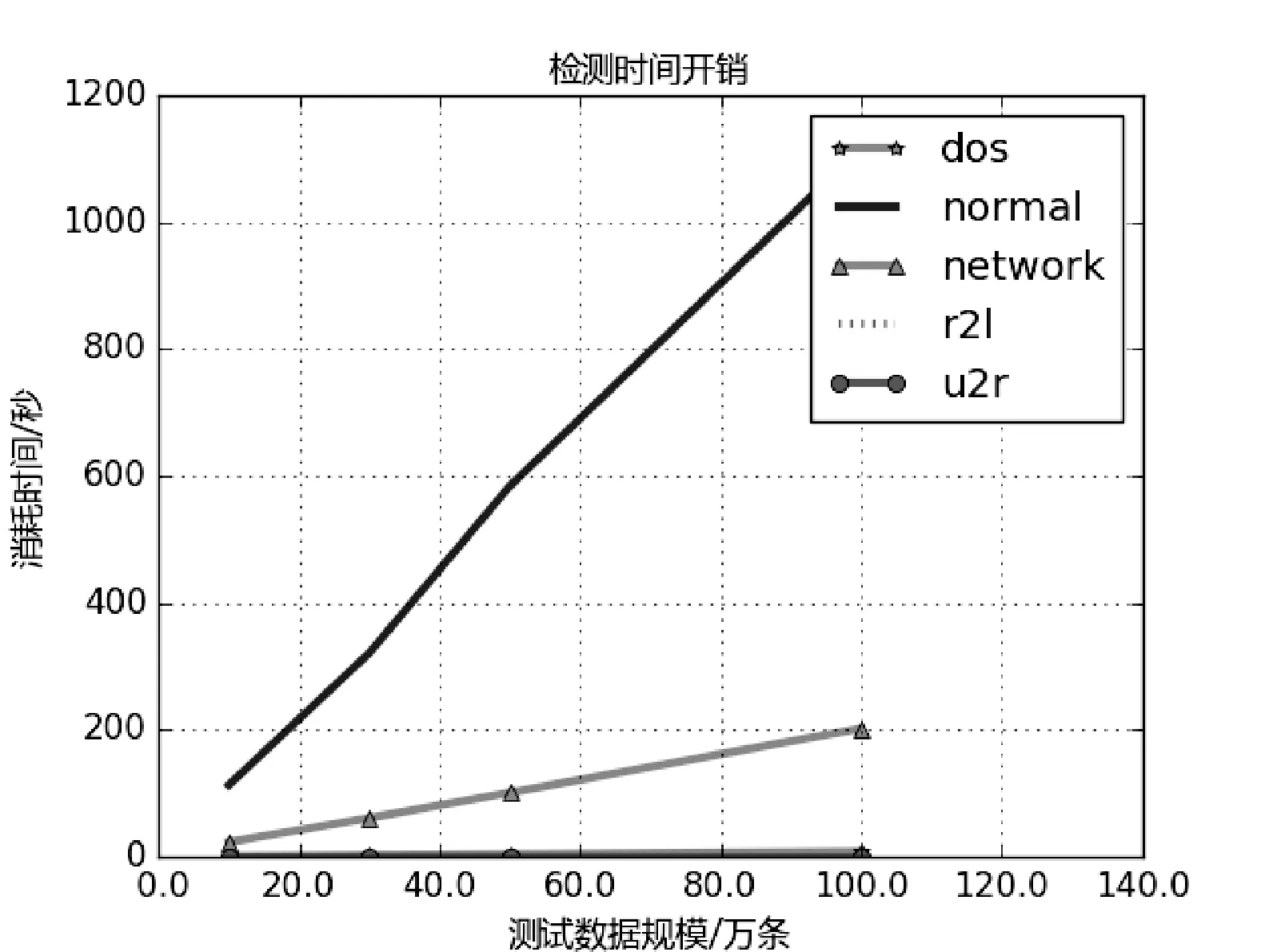
图8 检测时间开销
3.7 相关实验对比
本文与文献[7,18-20]中提出的方法做了相关的对比试验,对比试验的结果如表8所示。
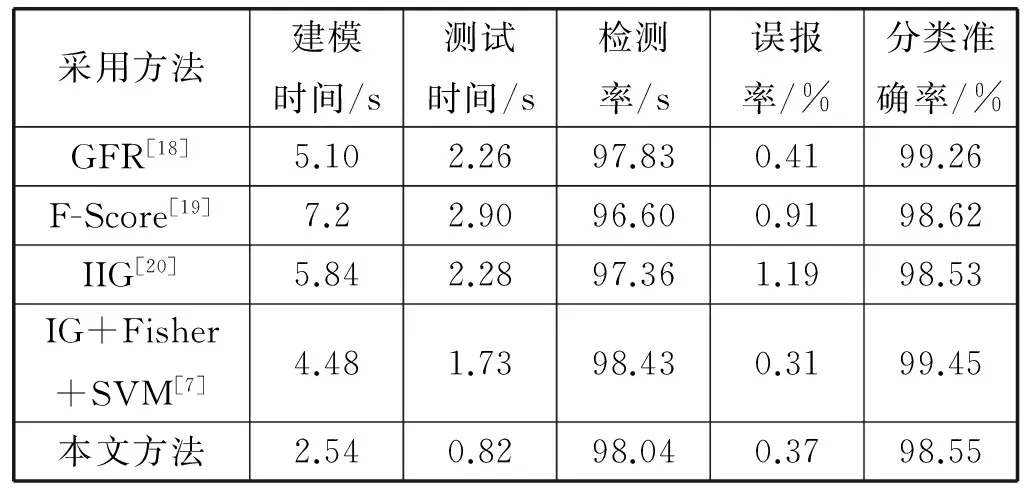
表8 不同方法比较
表8中的建模时间指的是指在经过数据预处理后的训练集合上训练模型所需要的时间,测试时间指的是从测试集合中随机抽取10 000条记录,连续抽取10次所测得的平均测试时间。可以看出本文方法缩短了建模的时间和测试的时间而检测率和误报率与文献[7]的方法基本持平,然而在分类准确率上较其他方法有所降低。原因在于感知哈希算法在数据压缩过程中会丢失部分信息,从而对最后的分类精度造成影响。但是本文提出的方法仍然可以满足当前入侵检测系统的要求。
4 结 语
本文借鉴了感知哈希的思想设计了适用于入侵检测的感知哈希函数提高了入侵检测速度,同时扩展了基于超球面的KNN算法,提出了基于杂交带的入侵检测方法。仿真实验结果表明,本文的方法在保证原来检测率的基础上提高了入侵检测速度。同时本文的方法对于入侵对象具有高度的敏感性,从而可以更加有效地保护系统安全。
[1] 田志宏,王佰玲,张伟哲,等.基于上下文验证的网络入侵检测模型[J].计算机研究与发展,2013,50(3):498-508.
[2] 魏宇欣,武穆清.智能网格入侵检测系统[J].软件学报,2006,17(11):2384-2394.
[3] Tsai C F,Hsu Y F,Lin C Y,et al.Review:Intrusion detection by machine learning:A review[J].Expert Systems with Applications An International Journal,2009,36(10):11994-12000.
[4] Wagh S,Neelwarna G,Kolhe S.A Comprehensive Analysis and Study in Intrusion Detection System Using k-NN Algorithm[M]//Multi-disciplinary Trends in Artificial Intelligence.Springer Berlin Heidelberg,2012:143-154.
[5] 杨雅辉,黄海珍,沈晴霓,等.基于增量式GHSOM神经网络模型的入侵检测研究[J].计算机学报,2014(5):1216-1224.
[6] 李志东,杨武,王巍,等.多源入侵检测警报的决策级融合模型[J].通信学报,2011,32(5):121-128.
[7] 武小年,彭小金,杨宇洋,等.入侵检测中基于SVM的两级特征选择方法[J].通信学报,2015,36(4):19-26.
[8] 刘勇,孙东红,陈友,等.基于主成分分析和决策树的入侵检测方法[J].东北大学学报(自然科学版),2010,31(7):933-937.
[9] 彭云峰,何模雄,隆克平.入侵检测灰色空间模型及应用[J].电子科技大学学报,2012,41(3):453-458.
[10] Jamshidi Y,Nezamabadi-Pour H.A Lattice based Nearest Neighbor Classifier for Anomaly Intrusion Detection[J].Journal of Advances in Computer Research,2013,4(4):51-60.
[11] Liao Y,Vemuri V R.Use of K-Nearest Neighbor classifier for intrusion detection[J].Computers & Security,2002,21(5):439-448.
[12] Zhao W,Tang S,Dai W.An Improved kNN Algorithm based on Essential Vector[J].Elektronika ir Elektrotechnika,2012,123(7):119-122.
[13] 郭春.基于数据挖掘的网络入侵检测关键技术研究[D].北京邮电大学,2014.
[14] 李秋洁,茅耀斌,王执铨.基于多配置特征包的目标检测[J].模式识别与人工智能,2011,24(6):869-874.
[15] 朱克楠,尹宝林,冒亚明,等.基于有效窗口和朴素贝叶斯的恶意代码分类[J].计算机研究与发展,2014,51(2):373-381.
[16] 吴静,刘衍珩,孟凡雪.入侵检测中的多分类SVM增量学习算法[J].北京工业大学学报,2009,35(12):119-124.
[17] 马志远,曹宝香.改进的决策树算法在入侵检测中的应用[J].计算机技术与发展,2014(1):151-154.
[18] Li Y,Xia J,Zhang S,et al.An efficient intrusion detection system based on support vector machines and gradually feature removal method[J].Expert Systems with Applications,2012,39(1):424-430.
[19] Zhang X Q,Gu C H,Lin J J.Intrusion Detection System Based on Feature Selection and Support Vector Machine[C]//International Conference on Communications & Networking in China.IEEE,2006:1-5.
[20] Jia X,Liu P,Gong W,et al.An algorithm application in intrusion forensics based on improved information gain[C]//2011 3rd Symposium on Web Society (SWS),2011:100-104.
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
保定学院学报(2022年2期)2022-04-07
今日农业(2021年19期)2022-01-12
今日农业(2021年10期)2021-11-27
大数据(2021年6期)2021-11-22
疯狂英语·初中天地(2021年6期)2021-08-06
电脑爱好者(2021年8期)2021-04-21
电脑爱好者(2020年20期)2020-10-22
数学学习与研究(2018年15期)2018-11-12
电脑爱好者(2015年13期)2015-09-10
