
AUCRF算法在信用风险评价中的特征选择研究
2018-05-03 06:14刘忻梅
计算机应用与软件 2018年4期
刘忻梅 唐 俊 段 翀
(内蒙古科技大学理学院 内蒙古 包头 014010)
0 引 言
信用风险又称违约风险,是指交易对手未能履行契约中的义务而造成经济损失的风险,即授信人不能履行还本付息的责任而使授信人的预期收益与实际收益发生偏离的可能性,它是金融风险的主要类型。信用风险评价过程中特征选择至关重要。特征选择是指从原始特征集中选择使某种评估标准最优的特征子集,以使在该最优特征子集上所构建的分类或回归模型达到比特征选择前更好的预测效果[1]。如何从高维特征中选出恰当的特征,将其用于模型进行风险评价,是信用风险评价需要解决的关键问题之一。
特征选择的方法依据是否独立于后续的学习算法,分为过滤式(Filter)和封装式(Wrapper)两种。Wrapper利用后续学习算法的训练效果评估特征子集,偏差小,计算量大,适用于关键特征的辨识,是当前特征选择研究领域的热点[2]。随机森林RF(random forest)算法由Breiman于2001年在《Machine Learning》上发表,被誉为当前最好的算法之一。该算法是以决策树为基础分类器的集成机器学习方法,是一种自然的非线性建模工具,具有较好的泛化性和准确性,对噪声和缺失值具有很好的鲁棒性,学习速度快,不容易产生过拟合[3]。与其他算法相比,随机森林的一大特色是对多元共线性不敏感,即使样本量较少、特征变量数以千计,也不必删除变量去建模。随机森林算法由于其出色的分类性能和可将特征重要性排序的特点,在国内外广泛用于各领域的分类、预测、特征选择和异常检测。该算法将特征变量重要性排序,为采用Wrapper方法做特征子集评价策略的特征选择方法奠定了重要基础。
近年来,随着随机森林在各个领域的应用研究成为热点,信用风险评价及其特征选择领域也出现了该算法的应用研究。具有代表性是萧超武等[4]将随机森林组合分类器应用于银行的个人信贷评估。方匡南等[5-6]利用随机森林算法对个人住房贷款和信用卡违约进行预测和特征选择。林成德等[7]将随机森林用于企业信用评估与特征选择中。这些研究都取得了较高的预测精度。目前,国内利用随机森林算法对信用风险评价及其特征选择的应用研究有一个共同特点,都将测试精度作为分类性能的度量。然而,信用风险评价中类错分代价是不对等的,致力于错分总数最少(或正确分类总数最多)的精度作为分类性能的度量,并不能满足重在识别违约样本的分类任务。例如,100个样本中,60个正常样本,40个违约样本,若正常样本预测全部正确,违约样本仅正确预测出50%,此时精度却高达80%。可见,高精度的分类模型未必能很好地识别出违约样本。因此,解决信用风险评价及其特征选择问题需要更科学的分类性能度量指标。Joshi[8]指出针对错分代价不对等的情况,使用ROC曲线下的面积AUC评价分类器的性能更合适。本文将随机森林(RF)作分类器算法、AUC作分类性能的度量进行信用风险评价及其特征选择,以下简称为AUCRF方法。由于AUC限于二分类问题,所以本文的AUCRF方法限于二分类的信用风险评价与特征选择,例如是否违约或信用好坏等二分类问题。
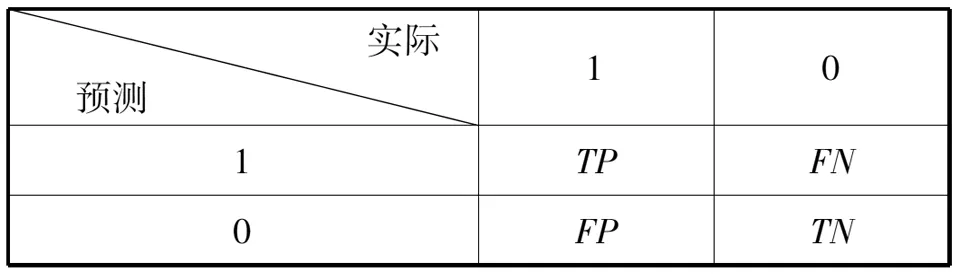
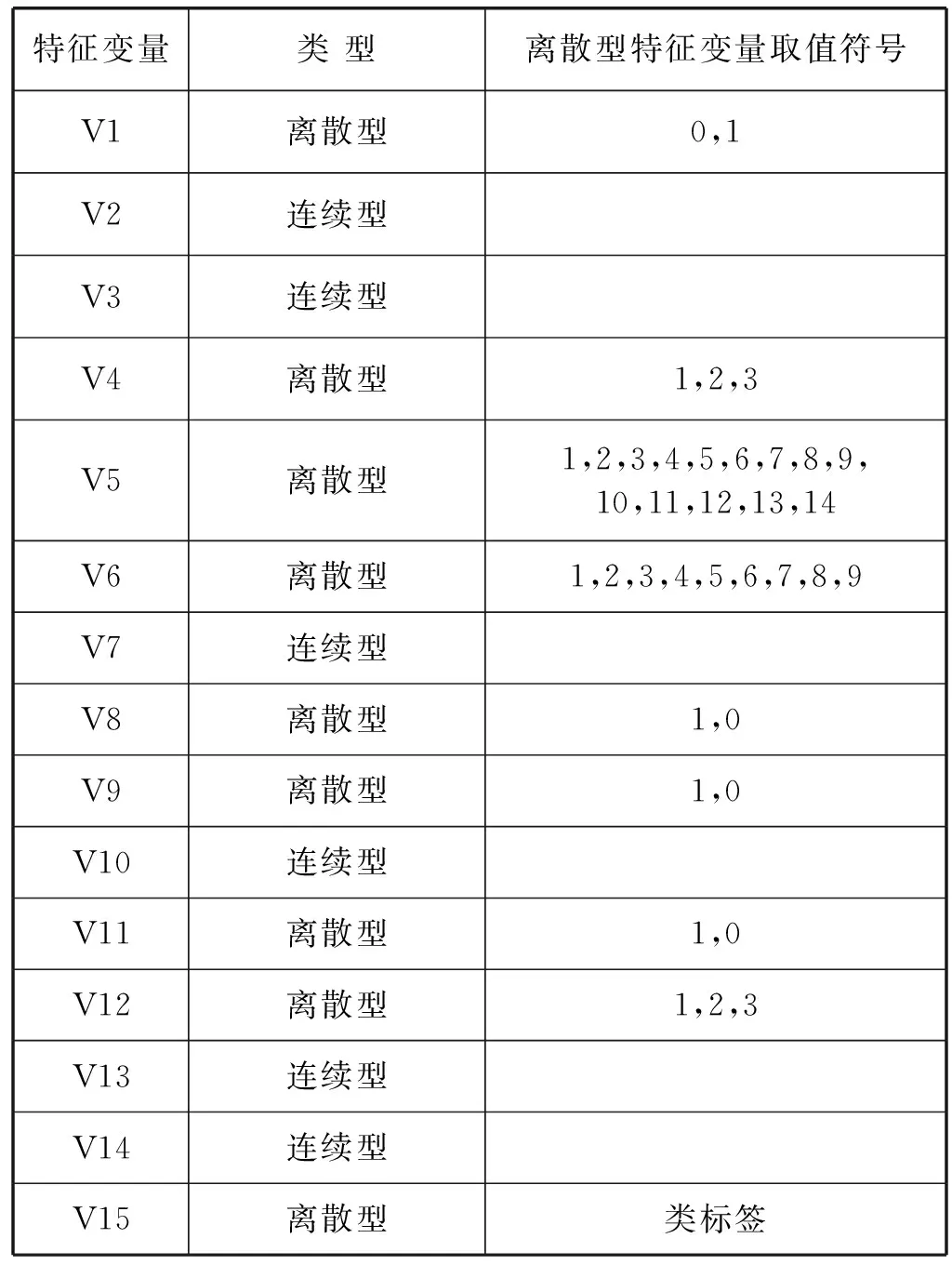
1 AUCRF算法
1.1 随机森林算法原理
利用Bootstrap重抽样方法从原始训练样本集中抽取k个子样本集,每个子样本集样本容量与原始训练样本集都一样。对新的子样本集的M个特征,随机抽取m (1) 式中:H(x)表示组合分类模型;hi表示单个决策树分类模型;Y表示目标变量;I(•)表示示性函数。 此外,随机森林还可以对特征变量的重要性进行排序。原理是对已生成的模型,利用OOB数据测试其性能,得到OOB精度或基尼值。之后,对某个特征变量加入一定噪声,再利用OOB数据测试模型的性能,得到新的OOB精度或基尼值。将前后两次的OOB精度或基尼值之差作为特征变量重要性的度量。 随机森林算法中,利用OOB数据作测试集,测试结果可形成如表1的混淆矩阵,其中1表示违约,0表示正常。 表1 混淆矩阵 常用的分类性能度量有正确率Acc和错误率Err,正确率Acc就是指精度。 (2) (3) 显然,Err=1-Acc精度高未必能够说明对违约样本的预测性能就好。由混淆矩阵还可以产生分类性能度量指标TPR和FPR。TPR为正确预测为违约的样本占实际违约样本的比例,FPR为错误预测为违约的样本占实际正常样本的比例。 (4) (5) 将二者结合,以TPR为纵轴、FPR为横轴构造的平面上,每个点对应一个分类器模型。与右下端点相比,左上端的点表示所有正常样本中错误预测为违约样本的比例低,同时所有违约样本中正确预测为违约样本的比例高。因此,越靠近左上端的点对应的分类器性能越好。分类器取不同的阈值就形成了ROC曲线。一个分类器可能在ROC曲线上的一个点上具有较好的性能,而在另一个点上却性能较差,采用ROC曲线下的面积AUC做度量可对分类性能进行综合评价。AUC取值介于0.5与1之间,越接近于1说明分类性能越好。以上分析表明,AUC比精度更适合在信用风险评估及其特征选择中作为分类性能的度量。 特征选择算法采用Wrapper方法作为评价策略,在筛选特征的过程中直接用所选特征子集训练分类器,根据分类器在测试集的性能度量该特征子集的优劣。本文基于随机森林算法对特征重要性的排序,以AUC作为分类性能的度量,通过以下步骤确定最优特征子集: (1) 利用随机森林算法对所有特征重要性排序。 (2) 将所有特征作为初始特征集,计算该分类器的AUC。 (3) 基于特征重要性排序,去除重要性最小的特征变量,用剩余的所有特征作为特征集,计算该分类器的AUC。 (4) 重复(3),直至特征集中特征数量等于或小于预设值。 (5) 比较所有分类器的AUC,AUC最大的分类器所用特征集为最优特征子集。 本文数据源自UCI中的Australian Credit Approval。该数据集为二分类数据,两类客户的数量大致平衡,信用“良好”的样本383个,信用“不良”的样本307个。每个样本有14个特征变量和1个类标签,14个特征变量中6个是连续型,8个是离散型。其中,连续型缺失数据用均值替代,离散型缺失数据用众数替代。为了保护商业机密,数据把特征变量和特征值都换成了符号,如表2所示。 表2 特征变量的属性与取值 2.2.1 特征变量重要性排序 图1给出了特征变量的重要性排序。图1中横轴为精度或者基尼值平均下降的指标,纵轴为特征变量的编号。其中MeanDecreaseAccuracy 和MeanDecreaseGini值越大表示该变量的重要性越大。这些特征变量是否有冗余,做信用风险评价时选择哪些特征进入评价模型最好,下面的AUCRF方法可进行特征选择。 图1 特征变量重要性排序 2.2.2 基于AUCRF方法的特征选择 依据AUCRF的计算原理,最优子集确定过程中各特征子集的AUC值如图2所示。横轴表示各子集所含特征变量的个数,纵轴表示该子集通过AUCRF方法计算得到的AUC值。图2表明通过AUCRF方法确定的最优子集含特征变量kopt为11个,依重要性排序分别为V8、V10、V5、V7、V14、V3、V2、V13、V9、V6、V4,冗余变量为V1、V11、V12。此时,AUC值最大为0.934 6,接近于1,表明分类性能较好。所以,使用该数据进行信用风险评价和特征选择时,仅用最优子集中的11个特征变量即可达到最优的预测。 图2 最优特征子集与AUC 本文提出在错分代价不对等的信用风险评价及其特征选择过程中,AUC作为分类性能的度量要比精度更科学。基于随机森林RF算法以AUC作分类性能的度量,并采用Wrapper方法作为特征选择的评价策略,可以解决信用风险评价中的特征选择问题。最终可确定出冗余特征变量和最优特征子集,以及最优特征子集对应的AUC值。通过UCI数据的实证分析表明,应用AUCRF方法进行风险评价及其特征选择时分类性能较好,最优特征子集对应的AUC值可达0.934 6。因此,AUCRF算法可用于错分代价不对等的信用风险特征选择。 [1] 姚登举, 杨静, 詹晓娟. 基于随机森林的特征选择算法[J]. 吉林大学学报(工学), 2014, 44(1):137-141. [2] 姚旭, 王晓丹, 张玉玺,等. 特征选择方法综述[J]. 控制与决策, 2012, 27(2):161-166. [3] Breiman L. Random Forests[J]. Machine Learning, 2001, 45(1): 5-32. [4] 萧超武, 蔡文学, 黄晓宇,等. 基于随机森林的个人信用评估模型研究及实证分析[J]. 管理现代化, 2014, 34(6):111-113. [5] 方匡南, 吴见彬. 个人住房贷款违约预测与利率政策模拟 [J]. 统计研究, 2013, 30(10): 54-60. [6] 方匡南, 吴见彬, 朱建平,等. 信贷信息不对称下的信用卡信用风险研究[J]. 经济研究, 2010(S1):97-107. [7] 林成德, 彭国兰. 随机森林在企业信用评估指标体系确定中的应用[J]. 厦门大学学报(自然版), 2007, 46(2):199-203. [8] Joshi M V. On evaluating performance of classifiers for rare classes[C]//IEEE International Conference on Data Mining,2002.ICDM 2003.Proceedings.IEEE,2002:641-644.
1.2 分类性能的度量指标AUC
1.3 AUCRF算法
2 实验分析
2.1 数据资料描述
2.2 分析结果



3 结 语
猜你喜欢
化工管理(2022年13期)2022-12-02
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
南京理工大学学报(2021年4期)2021-09-15
现代电子技术(2021年3期)2021-02-02
南京大学学报(数学半年刊)(2020年1期)2020-03-19
小型微型计算机系统(2018年5期)2018-07-04
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年15期)2016-07-04
都市丽人(2015年4期)2015-03-20
