
Training and Testing Object Detectors With Virtual Images
2018-05-02 07:11YonglinTianXuanLiKunfengWangandFeiYueWang
Yonglin Tian,Xuan Li,Kunfeng Wang,,and Fei-Yue Wang,
I.INTRODUCTION
DATASETS play an important role in the training and testing of computer vision algorithms[1],[2].However,real-world datasets are usually not satisfactory due to the insufficient diversity.And the labeling of images in real world is time-consuming and labor-intensive,especially in largescale complex traffic systems[3],[4].Moreover,it is a highly subjective work to annotate images manually.For example,different people may have different annotation results for the same image.As a result,the labeling result will deviate to some extent from the ground truth and even seriously affect the performance of computer vision algorithms.
Most existing datasets originate from the real world,such as KITTI,PASCAL VOC,MS COCO,and ImageNet.Each of these datasets has many advantages,but they also have shortcomings.The KITTI[5]dataset is the world’s largest computer vision dataset for automatic driving scenarios,including more than one hundred thousand labeled cars.However,KITTI lacks some common types of objects(e.g.,bus),and the number of trucks is small.The PASCAL VOC[6]dataset serves as a benchmark for classification,recognition,and detection of visual objects.PASCAL VOC contains 20 categories,but there is a small number of images per category,with an average of less than one thousand.The ImageNet dataset[7]is the world’s largest database of image recognition,including more than 1000 categories.However,there is no semantic segmentation labeling information in it.There are 328000 pictures of 91 classes of objects in the MS COCO[8]dataset.But the task of annotating this dataset is onerous.For example,it takes more than 20000 hours to determine which object categories are present in the images of MS COCO.
Generally speaking,real datasets are confronted with many problems,such as small scale and tedious annotation.Setting up a dataset with precise annotations from the real world means great labor and financial investments,and it is more difficult to build a dataset with specific features like diverse areas of objects and occlusion levels.However,the latter occupies a significant position in addressing the problems of visual perception and understanding[9]-[11].In[9],[10],Wanget al.proposed the theoretical framework of Parallel Vision by extending the ACP(Artificial systems,computational experiments,and parallel execution)approach[12]-[14]and elaborated the significance of virtual data.The ACP methodology establishes the foundation for parallel intelligence[15]-[17],which provides a new insight to tackle issues in complex systems[18].Under the framework of Parallel Vision depicted in Fig.1,it is obvious to see the great advantage of virtual world to produce diverse labeled datasets with different environmental conditions and texture changes which are usually regarded as important image features for object detection[19].In our work,we take the specifically designed virtual datasets as resources to train object detectors and also as a tool to produce feedback of the performance of trained models during the testing phase.
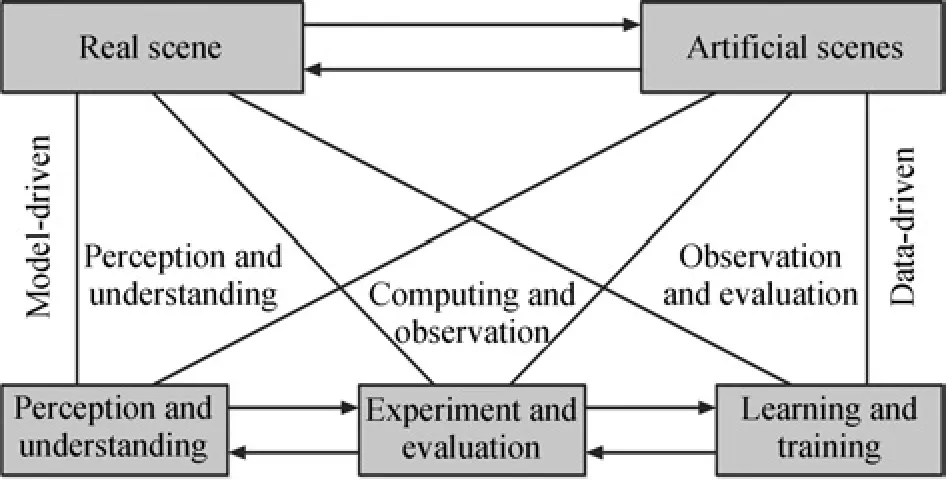
Fig.1. Basic framework and architecture for parallel vision.
We choose deformable parts model(DPM)[20]and Faster R-CNN[21]as the object detectors in our work.DPM was one of the most effective object detectors based on histogram of oriented gradient(HOG)before the resurgence of deep learning.Faster R-CNN is currently a state of the art approach and widely used in object detection.Based on Fast R-CNN[22],Renet al.[21]introduced the region proposal network(RPN)that can share convolutional features of the whole image with the detection network.This work greatly reduced the time cost to generate region proposals and improved their qualities as well.Faster R-CNN lays the foundation for many 1st-place detection models in recent years.
In this paper,we present an efficient way to construct virtual image datasets with advanced computer graphics techniques.It provides a flexible and feasible method to build training datasets that can greatly satisfy our needs such as diversity,scale,and specific occlusion level.On this basis,we study the effectiveness of our virtual dataset to train and test the object detectors.
II.RELATED WORK
There have been many attempts that use virtual world to carry out scientific researches.Bainbridge[23]investigated the feasibility of utilizing Second Life and World of Warcraft as sites for research in social,behavioral,and economic sciences,as well as computer science.With a virtual living lab,Prendingeret al.[24]conducted several controlled driving and travel studies.
In the area of computer vision,early works involved training pedestrian detectors based on histogram of oriented gradients(HOG)and linear support vector machine(SVM)[25]and part-based pedestrian detector[26]with virtual datasets generated by the video game Half-Life 2.Besides training models,virtual-world data was also used to explore the invariance of deep features of deep convolutional neural networks(DCNNs)to missing low-level cues[27]and domain adaptation issues[28].For semantic segmentation research,Richteret al.[29]presented a way to build virtual datasets via modern video game and got the corresponding annotations using an outside graphics hardware without access to the source code of the game.Most of the above approaches rely on video games rather than setting up the virtual world from the scratch,resulting in bad flexibility in the research process.Recently,Roset al.[30]set up a virtual world on their own and collected images with semantic annotations by virtual cameras under different weather conditions and observing angles.They generated a virtual dataset named SYNTHIA in a flexible way which was used for training DCNNs for semantic segmentations in driving scenes.However,SYNTHIA lacks the annotations for other computer vision tasks such as object detection,tracking,and so on.In a similar way,Gaidonet al.[31]proposed a real-to-virtual world cloning method and released the video dataset called “Virtual KITTI”for multiobject tracking analysis.Basically the dataset is a clone of the real KITTI[5],so the overall framework and layout are constricted by the real KITTI dataset.Nowdays,generative adversarial networks(GANs)[32]are widely used to produce photorealistic synthetic images[33],however,those images lack the corresponding annotations.
In our work,a flexible approach to building artificial scenes from the scratch is proposed.We intend to set up virtual datasets with specific features and diverse annotations to train and test the object detectors.
III.THEVIRTUALDATASETPARALLELEYE
A.Construction of Arti ficial Scene
To imitate the layout of urban scene in real world,we exported the map information of the area of interest,Zhongguancun Area,Beijing,from the platform Open Street Map(OSM).Then,based on the raw map,we generated buildings,roads,trees,vegetation,fences,chairs,traffic lights,traffic signs and other“static”entities using the computer generated architecture(CGA)rules of City Engine.Finally,we imported the scene into the game engine Unity3D where cars,buses and trucks were added.Using the C#scripts,we controlled the vehicles to move according to certain traffic rules in the virtual world.Also,with the help of the Shaders in Unity3D,the weather and lighting conditions were adjusted as needed.The artificial scene is shown in Fig.2.

Fig.2.The appearance of artificial scene.Top:Map information exported from OSM.Bottom:Final artificial scene.
B.Annotations of Virtual Images
To build a dataset,we need to get the annotations of the corresponding images.Data labeling has always been a headache of the machine learning researchers.However,it is very simple and efficient to get the ground truths of the virtual images from our artificial scene via the components in Unity3D like Mesh Filter,Shader,and so on.We achieved simultaneous ground truth generation including depth,optical flow,bounding box and pixel-level semantic segmentation while the scene was running.Fig.3 shows the ground-truth annotations for different vision tasks.
C.Setting Up Virtual Dataset
In order to increase the diversity of the virtual dataset,we con figured different weather(cloudy,sunny,rainy and foggy)and illumination(from sunrise to sunset)conditions for the artificial scene as shown in Fig.4.These changes are deemed to have a significant effect on the performance of object detectors in real world[34]-[36].We placed a virtual camera on a moving car that was used for capturing images in the scene.To produce obvious change in object’s appearance,we set different parameters for the camera including height,orientation and the field of view.The virtual camera is illustrated in Fig.5.The sight distance of the camera can be adjusted and it is much longer in practice.We placed several cars,buses and trucks on the lanes which can move following the instruction of the scripts.More vehicles were put near the roads in different manners,sparse or dense,to create diverse occlusion levels.For the purpose of testing and improving the performance of object detectors on objects with distinct colors and poses,we achieved real-time color and pose change of the interesting objects in artificial scene while the virtual camera was collecting images.Based on the above techniques,we built the virtual dataset named Parallel Eye[37],which is composed of three sub-datasets.
Parallel Eye 01 is the first part of the virtual dataset which was set up with an on-board camera looking at five directions(i.e.,0,±15,±30 degree with respect to the moving direction).Therefore,the camera had a long sight distance to capture small and far objects.In Parallel Eye 02,the orientation of the camera was adjusted to around±90 degree with respect to the moving direction and we set the vehicles to rotate around their axes.The images were collected from both sides of the road.Occlusion was not intentionally introduced to get a better understanding of the effect of pose change on the trained models.Parallel Eye 03 was designed to investigate the influence of color and occluded condition on the performance of the object detector.We placed the vehicles closely and changed their colors in every frame.The camera was set to look at three directions(i.e.,0,±30 degree with respect to the moving direction).Sample images from these three parts of the virtual dataset are shown in Fig.6.
D.Dataset Properties

Fig.3. Annotations for different vision tasks.Top:Depth(left)and optical flow(right).Bottom:Bounding box(left)and semantic segmentation(right).

Fig.4. Diversity of illuminations and weather conditions.Top:Virtual images taken at 6:00 am(left)and 12:00 pm(right).Bottom:Virtual images with weather of foggy(left)and rainy(right).
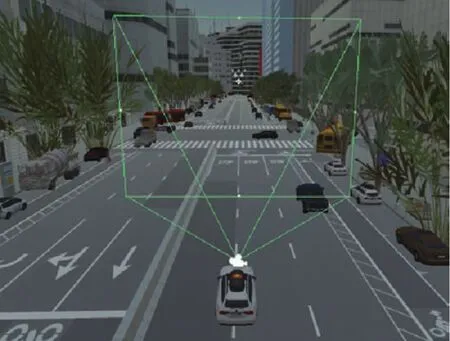
Fig.5. Virtual camera in the artificial scene.

Fig.6. Sample images of three virtual sub-datasets.First row:Parallel-Eye 01.Second row:Parallel Eye 02.Third and fourth rows:Parallel Eye_03.
Parallel Eye includes 15931 images and annotations of three classes of objects(car,bus and truck)in VOC format.The numbers of images and objects in three sub-datasets are recorded in Table I.The bar graphs in Fig.7 depict the object occurrence and object geometry statistics as well as the occlusion level of three sub-datasets.The objects are labelled as “Small”whose areas are smaller than 32×32 pixels and“Large”for those whose areas are larger than 96×96 pixels.The rest are labelled as “Medium”.For occlusion level,the objects are labelled as “Slightly occluded”whose occlusion rates are less than 0.1 and “Largely occluded”for those whose occlusion rates are more than 0.35 and “Partly occluded”for the rest.It is clear to see that Parallel Eye_01 and Parallel-Eye_03 are more crowded than Parallel Eye_02,which means there are less objects in one image in Parallel Eye_02 compared with the other sub-datasets.More importantly,Parallel Eye_01 has more small objects and Parallel Eye_03 has a higher occlusion level.

TABLE INUMBERS OF IMAGES AND OBJECTS IN THREE VIRTUAL SUB-DATASETS
E.Discussion
In the experiments,our platform can work at 8-12 fps(frames per second)to produce virtual images with different annotations on our workstation.It is efficient compared with manual labor,for example,it usually takes dozens of minutes to finish the labeling work on a single image containing various categories used for segmentation task.
This virtual dataset was mainly built for research on intelligent vehicles.For now,we included three common types of objects.Other objects such as person and motorbikes have not yet been contained due to their less appearance from the view of the virtual camera shown in Fig.5.In the future,we will add more objects in our virtual scene under the framework shown in Fig.8 to build a dataset containing more categories.Specifically,we add the models such as person,motorbikes and animals in the virtual scene during step 3○and take them into account in the C#scripts during steps 4○5○6○.Then,we are able to capture images containing these objects with diverse annotations.
It is also worth mentioning the ways to reduce computational complexity when we generalize the virtual scene to a bigger city or other large-scale environments by importing the corresponding maps during step 1○and more models at step 3○in Fig.8.Great computational capacity is demanded as the scale of the virtual world increases if no action is taken.In practice,there are two widely-used methods to handle this problem.One is that we can only take into account the objects which are visible to the virtual camera instead of all the objects in the scene via some tricks like occlusion culling.Besides,it is also an effective way to replace the intricate textures and structures with rougher ones for the objects that are far from the camera.These measures help to decrease the workload of CPU and GPU of the platform,e.g.,the number of vertex to compute,thus leading to an acceptable frame rate even when a large-scale scene is running.
IV.EXPERIMENTS
In our experiments,all the images and annotations were stored in the form of PASCAL VOC.For Faster R-CNN,the weights were initialized with Image Net pre-trained weights.For the experiments of DPM,we used a three-component model for each category and the ratio of positive and negative examples was set as 1:3.
A.Training Experiments on VOC+COCO and Parallel Eye
To obtain a real dataset containing three common traffic objects,i.e.,car,bus and truck,we selected 1997 images including car and bus from PASCAL VOC[6]and 1000 images containing truck from MS COCO[8]that were transformed to VOC style.MS COCO includes more images containing truck.But we only chose 1000 images and excluded images where truck shared a fairly small proportion.These images and corresponding annotations from VOC and COCO were combined together and randomly divided into training set and testing set with the proportion of 3:1.Firstly,we trained the Faster R-CNN model with the real training set.Initial learning rate was set to 0.001 and decreased by the factor of 10 after 50000 iterations.We chose one image as the batch size and momentum factor of 0.9 with the weight decay factor of 0.0005.Then,we randomly picked 2000 images out from the virtual dataset Parallel Eye and combined them with the real training data as a mixed training set to train another model with the same setting.We used VGG-16 and Res Net-50 for Faster R-CNN respectively in our experiments.Finally,we carried out experiments for DPM using the same datasets.

Fig.7. Object occurrence,object geometry and occlusion level of our virtual datasets.This figure shows(from left to right):Distribution of the number of instances within an image,object area distribution and occlusion level.

Fig.8.Framework of constructing the virtual dataset.1○:In CityEngine,set up a static city including buildings and roads using the CGA rules based on the map information from OSM.2○3○:In Unity3D,import the models of interesting objects such as cars,people,animals and trees into the static city thus forming several static scenes.4○:In Unity3D,activate the static scenes by controlling virtual objects to move using C#scripts.5○:Control the virtual camera to move and capture images using C#scripts.6○:Compute the annotations such as bounding box and semantic segmentation using C#scripts and Shaders in Unity3D.
These models were evaluated on the real testing set generated from PASCAL VOC and MS COCO.We followed the steps of the standard evaluation procedure of PASCAL VOC to calculate the average precision(AP)of each category.The intersection over union(IoU)was set to 0.7 for Faster RCNN and 0.5 for DPM.The results are shown in Table II.The examples of detection results for Faster R-CNN based on VGG-16 architecture are shown in Fig.9.We noticed that the average precision(AP)on bus for DPM is higher than Faster R-CNN.This may be caused by the fact that the shape of bus is not as flexible as car and truck,so it is easier to learn.Also,the number of buses is less than the other two types of objects[6]which is adverse for Faster R-CNN,because deep learning models usually require more data to learn than the traditional ones.We also noticed that after introducing the truck category from MS COCO,the AP of car and bus is decreased compared with models trained purely on the PASCAL VOC dataset for Faster R-CNN[21],which may be interpreted by the fact that MS COCO dataset is more challenging for object detection and contains more difficult images of objects that are partially occluded,amid clutter,etc[8].

Fig.9. Examples of object detection results(VGG-16).The upper row of every couple:Objects detected by the model trained purely with the real training set.The lower row of every couple:Objects detected by the model trained with real and virtual datasets.
B.Training Experiment on KITTI and Parallel Eye
6684 images with annotations containing the car object were picked out from the KITTI dataset and divided into real training set and testing set with the ratio of one to one.First,we trained the Faster R-CNN detector purely with the real training set.Next,4000 images with annotations containing the car object were randomly selected from Parallel Eye dataset that were used for pre-training the Faster R-CNN model.Then,we fine-tuned the pre-trained model using the real trainingset.And we performed experiments on DPM with real and mixed data.These experiments were executed with the same setting as experiments on VOC+COCO.These trained models were tested on the real KITTI testing set and the Average Precision is recorded in Table III.Fig.9 depicts the examples of the detection results for Faster R-CNN based on VGG-16 architecture.

TABLE IIPERFORMANCE OF MODELS EVALUATED ON VOC+COCO
C.Testing Experiments on KITTI and Parallel Eye
In this section,we investigate the potential of using our virtual dataset to test the object detector trained on real dataset.KITTI was chosen as the real dataset to train Faster RCNN models due to its diversity of object area and occlusion condition[5].6684 images with annotations containing the car object were picked out from the KITTI dataset and divided into training set and testing set with the ratio of one to one.We named the full training set Train Full to avoid confusion.The Train Full set possessed 3342 images with 28742 cars.First,we trained a Faster R-CNN detector with Train Full.This detector was used as the reference for the detectors below.To evaluate the impact of small objects on model’s performance,we deleted these objects in Train Full whose areas were smaller than 3600 pixels according to the annotations.By this standard,we got 2419 images containing 14346 cars.We called the devised training set Train Large which was used to train the second Faster R-CNN detector.The third detector was trained with so-called Train Visible which only kept objects labeled as “fully visible”in Train Full and had 3113 images with 13457 cars.All the experiments were carried out with the same setting as those in VOC+COCO.
These three detectors were tested on Parallel Eye 01 characterized by small area of objects on average and Parallel Eye 03 marked by high level of occlusion as well as Parallel Eye 02 with larger objects and lower occlusion level.We calculated the average precision in the manner of PASCAL VOC.The results are recorded in Table IV.For the purpose of making the results more explicit,we also calculated the rate of descent of AP after we removed small objects and occluded objects respectively from the training set.The AP of model trained with Train_Full set was regarded as the reference and the results are shown in Table V.
D.Discussion
On the one hand,the results above show that our virtual datasets are viable to improve the performance of object detector when used for training it together with the real dataset.On the other hand,we can conclude that our purposefully designed virtual datasets are potential tools to assess the performances of trained models from a specific aspect.The results in Table IV and Table V show that with small objects removed from the training set,performance of the model became worse on all sub-datasets while a bigger rate of descent of AP occurred on Parallel Eye_01 in the testing phase,which may result from the smaller average area of object of Parallel Eye_01.And Parallel Eye_03 witnessed a huger drop of the rate of AP after we deleted occluded objects from the training set because Parallel Eye_03 has a higher occlusion rate.
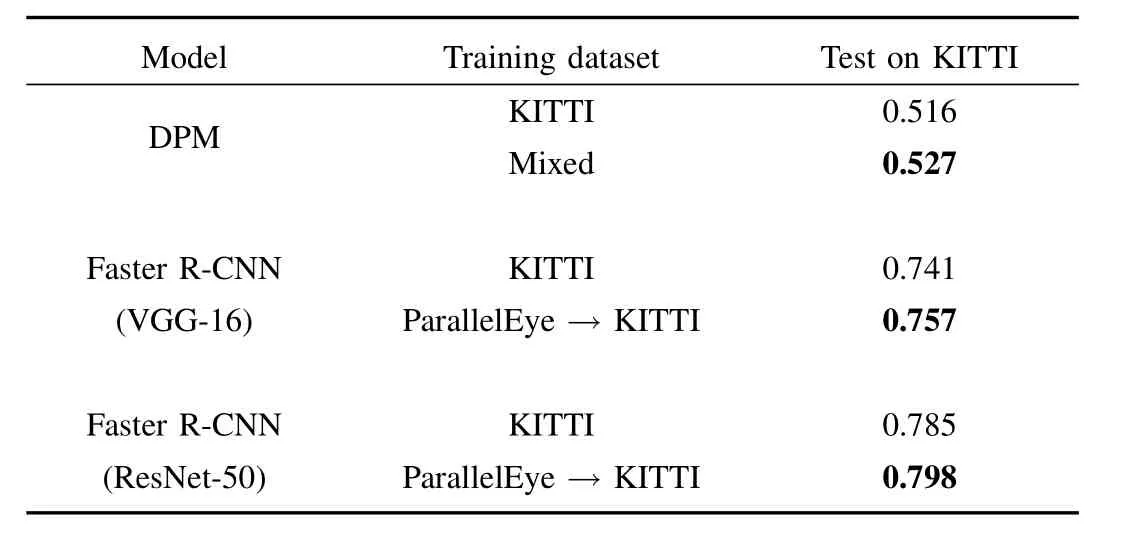
TABLE IIIPERFORMANCE OF MODELS EVALUATED ON KITTI
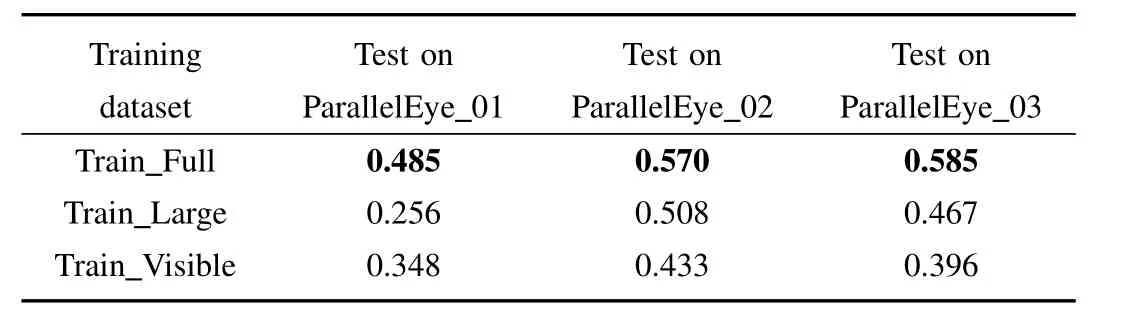
TABLE IVEVALUATION WITH PURPOSEFULLY DESIGNED VIRTUAL DATASETS
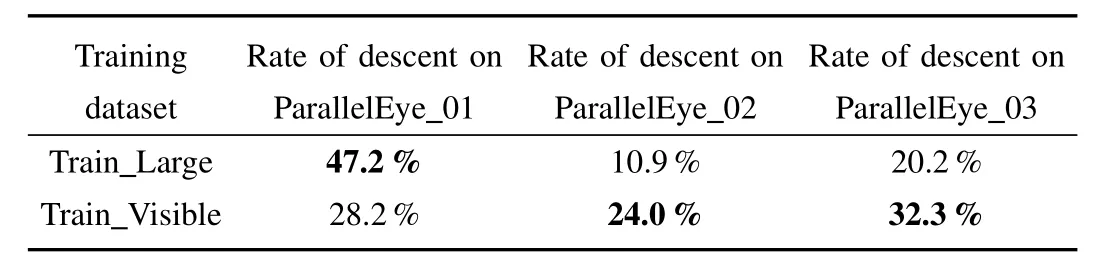
TABLE VRATE OF DESCENT ON VIRTUAL DATASETS
V.CONCLUSION
This paper presents a pipeline to build artificial scenes and virtual datasets possessing some specific characteristics we de-sire like the occlusion level,area of objects and so on under the framework of Parallel Vision.We prove that mixing the virtual dataset and several real datasets to train the object detector helps to improve the performance.Also,we investigate the potential of testing the trained models on a specific aspect using intentionally designed virtual datasets.This work may help deep learning researchers to get a better understanding of their models especially in the areas of autonomous driving.
[1]B.Kaneva,A.Torralba,and W.T.Freeman,“Evaluation of image features using a photorealistic virtual world,”inProc.2011 IEEE Int.Conf.Computer Vision,Barcelona,Spain,2011,pp.2282-2289.
[2]Y.Q.Liu,K.F.Wang,and D.Y.Shen,“Visual tracking based on dynamic coupled conditional random field model,”IEEE Trans.Intell.Transp.Syst.,vol.17,no.3,pp.822-833,Mar.2016.
[3]C.Gou,K.F.Wang,Y.J.Yao,and Z.X.Li,“Vehicle license plate recognition based on extremal regions and restricted Boltzmann machines,”IEEE Trans.Intell.Transp.Syst.,vol.17,no.4,pp.1096-1107,Apr.2016.
[4]Y.T.Liu,K.F.Wang,and F.Y.Wang,“Tracklet association-based visual object tracking:the state of the art and beyond,”Acta Autom.Sinica.,vol.43,no.11,pp.1869-1885,Nov.2017.
[5]A.Geiger,P.Lenz,and R.Urtasun,“Are we ready for autonomous driving?The KITTI vision benchmark suite,”inProc.2012 IEEE Conf.Computer Vision and Pattern Recognition,Providence,RI,USA,2012,pp.3354-3361.
[6]M.Everingham,L.Van Gool,C.K.I.Williams,J.Winn,and A.Zisserman,“The PASCAL visual object classes(VOC)challenge,”Int.J.Comput.Vis.,vol.88,no.2,pp.303-338,Jun.2010.
[7]J.Deng,W.Dong,R.Socher,L.J.Li,K.Li,and F.F.Li,“ImageNet:A large-scale hierarchical image database,”inProc.2009 IEEE Conf.Computer Vision and Pattern Recognition,Miami,FL,USA,2009,pp.248-255.
[8]T.Y.Lin,M.Maire,S.Belongie,J.Hays,P.Perona,D.Ramanan,P.Dolla´r,and C.L.Zitnick,“Microsoft COCO:Common objects in context,”inProc.13th European Conf.Computer Vision,Zurich,Switzerland,2014,pp.740-755.
[9]K.F.Wang,C.Gou,N.N.Zheng,J.M.Rehg,and F.Y.Wang,“Parallel vision for perception and understanding of complex scenes:methods,framework,and perspectives,”Artif.Intell.Rev.,vol.48,no.3,pp.299-329,Oct.2017.
[10]K.F.Wang,C.Gou,and F.Y.Wang,“Parallel vision:an ACP-based approach to intelligent vision computing,”Acta Autom.Sinica,vol.42,no.10,pp.1490-1500,Oct.2016.
[11]K.F.Wang,Y.Lu,Y.T.Wang,Z.W.Xiong,and F.Y.Wang,“Parallel imaging:a new theoretical framework for image generation,”Pattern Recognit.Artif.Intell.,vol.30,no.7,pp.577-587,Jul.2017.
[12]F.Y.Wang,“Parallel system methods for management and control of complex systems,”Control Decis.,vol.19,no.5,pp.485-489,May 2004.
[13]F.Y.Wang,“Parallel control and management for intelligent transportation systems:concepts,architectures,and applications,”IEEE Trans.Intell.Transp.Syst.,vol.11,no.3,pp.630-638,Sep.2010.
[14]F.Y.Wang,“Parallel control:a method for data-driven and computational control,”Acta Autom.Sinica,vol.39,no.4,pp.293-302,Apr.2013.
[15]F.Y.Wang,J.J.Zhang,X.H.Zheng,X.Wang,Y.Yuan,X.X.Dai,J.Zhang,and L.Q.Yang,“Where does AlphaGo go:from Church-Turing thesis to AlphaGo thesis and beyond,”IEEE/CAA J.Autom.Sinica,vol.3,no.2,pp.113-120,Apr.2016.
[16]F.Y.Wang,J.Zhang,Q.L.Wei,X.H.Zheng,and L.Li,“PDP:Parallel dynamic programming,”IEEE/CAA J.Autom.Sinica,vol.4,no.1,pp.1-5,Jan.2017.
[17]F.Y.Wang,X.Wang,L.X.Li,and L.Li,“Steps toward parallel intelligence,”IEEE/CAA J.Autom.Sinica,vol.3,no.4,pp.345-348,Oct.2016.
[18]L.Li,Y.L.Lin,N.N.Zheng,and F.Y.Wang,“Parallel learning:a perspective and a framework,”IEEE/CAA J.Autom.Sinica,vol.4,no.3,pp.389-395,Jul.2017.
[19]K.F.Wang and Y.J.Yao,“Video-based vehicle detection approach with data-driven adaptive neuro-fuzzy networks,”Int.J.Pattern Recogn.Artif.Intell.,vol.29,no.7,pp.1555015,Nov.2015.
[20]P.F.Felzenszwalb,R.B.Girshick,D.McAllester,and D.Ramanan,“Object detection with discriminatively trained part-based models,”IEEE Trans.Pattern Anal.Mach.Intell.,vol.32,no.9,pp.1627-1645,Sep.2010.
[21]S.Q.Ren,K.M.He,R.Girshick,and J.Sun,“Faster R-CNN:towards real-time object detection with region proposal networks,”inProc.29th Ann.Conf.Neural Information Processing Systems,Montreal,Canada,2015,pp.91-99.
[22]R.Girshick,“Fast R-CNN,”inProc.IEEE Int.Conf.Computer Vision,Santiago,Chile,2015,pp.1440-1448.
[23]W.S.Bainbridge,“The scienti fic research potential of virtual worlds,”Science,vol.317,no.5837,pp.472-476,Jul.2007.
[24]H.Prendinger,K.Gajananan,A.B.Zaki,A.Fares,R.Molenaar,D.Urbano,H.van Lint,and W.Gomaa,“Tokyo virtual living lab:designing smart cities based on the 3D internet,”IEEE Internet Comput.,vol.17,no.6,pp.30-38,Nov.-Dec.2013.
[25]J.Mar´ın,D.Va´zquez,D.Gero´nimo,and A.M.Lo´pez,“Learning appearance in virtual scenarios for pedestrian detection,”inProc.2010 IEEE Conf.Computer Vision and Pattern Recognition,San Francisco,CA,USA,2010,pp.137-144.
[26]J.L.Xu,D.Va´zquez,A.M.Lo´pez,J.Mar´ın,and D.Ponsa,“Learning a part-based pedestrian detector in a virtual world,”IEEE Trans.Intell.Transp.Syst.,vol.15,no.5,pp.2121-2131,Oct.2014.
[27]X.C.Peng,B.C.Sun,K.Ali,and K.Saenko,“Learning deep object detectors from 3D models,”inProc.2015 IEEE Int.Conf.Computer Vision,Santiago,Chile,2015,pp.1278-1286.
[28]B.C.Sun and K.Saenko,“From virtual to reality:fast adaptation of virtual object detectors to real domains,”inProc.British Machine Vision Conference,Nottingham,2014,pp.3.
[29]S.R.Richter,V.Vineet,S.Roth,and V.Koltun,“Playing for data:ground truth from computer games,”inProc.14th European Conf.Computer Vision,Amsterdam,The Netherlands,2016,pp.102-118.
[30]G.Ros,L.Sellart,J.Materzynska,D.Vazquez,and A.M.Lopez,“The SYNTHIA dataset:a large collection of synthetic images for semantic segmentation of urban scenes,”inProc.2016 IEEE Conf.Computer Vision and Pattern Recognition,Las Vegas,NV,USA,2016,pp.3234-3243.
[31]A.Gaidon,Q.Wang,Y.Cabon,and E.Vig,“Virtual worlds as proxy for multi-object tracking analysis,”inProc.2016 IEEE Conf.Computer Vision and Pattern Recognition,Las Vegas,NV,USA,2016,pp.4340-4349.
[32]I.J.Goodfellow,J.Pouget-Abadie,M.Mirza,B.Xu,D.Warde-Farley,S.Ozair,A.Courville,and Y.Bengio,“Generative adversarial nets,”Proc.28th Annu.Conf.Neural Information Processing Systems,Montreal,Canada,2014,pp.2672-2680.
[33]K.F.Wang,C.Gou,Y.J.Duan,Y.L.Lin,X.H.Zheng,and F.Y.Wang,“Generative adversarial networks:introduction and outlook,”IEEE/CAA J.Autom.Sinica,vol.4,no.4,pp.588-598,Sep.2017.
[34]K.F.Wang,W.L.Huang,B.Tian,and D.Wen,“Measuring driving behaviors from live video,”IEEE Intell.Syst.,vol.27,no.5,pp.75-80,Sep.-Oct.2012.
[35]K.F.Wang,Y.Q.Liu,C.Gou,and F.Y.Wang,“A multi-view learning
approach to foreground detection for traf fic surveillance applications,”IEEE Trans.Vehicul.Technol.,vol.65,no.6,pp.4144-4158,Jun.2016.
[36]H.Zhang,K.F.Wang,and F.Y.Wang,“Advances and perspectives on applications of deep learning in visual object detection,”Acta Autom.Sinica,vol.43,no.8,pp.1289-1305,Aug.2017.
[37]X.Li,K.F.Wang,Y.L.Tian,L.Yan,and F.Y.Wang,“The ParallelEye dataset:Constructing large-scale artificial scenes for traffic vision research,”inProc.20th Int.Conf.Intel.Trans.Sys.,Yokohama,Japan,2017,to be published.
 IEEE/CAA Journal of Automatica Sinica2018年2期
IEEE/CAA Journal of Automatica Sinica2018年2期
- IEEE/CAA Journal of Automatica Sinica的其它文章
- Decomposition Methods for Manufacturing System Scheduling:A Survey
- Nonlinear Bayesian Estimation:From Kalman Filtering to a Broader Horizon
- Vehicle Dynamic State Estimation:State of the Art Schemes and Perspectives
- Coordinated Control Architecture for Motion Management in ADAS Systems
- An Online Fault Detection Model and Strategies Based on SVM-Grid in Clouds
- An Adaptive RBF Neural Network Control Method for a Class of Nonlinear Systems