
基于深度学习的渔业领域命名实体识别
2018-04-26 05:32:49孙娟娟于红冯艳红彭松程名卢晓黎董婉婷崔榛
大连海洋大学学报 2018年2期
孙娟娟,于红,冯艳红,彭松,程名,卢晓黎,董婉婷,崔榛
(大连海洋大学信息工程学院,辽宁省海洋信息技术重点实验室,辽宁大连116023)
渔业命名实体识别是对渔业领域文本进行深层次分析的基础,对渔业领域问答系统、舆情分析等研究具有重要意义[1]。早期命名实体的识别主要采用基于规则的方式,周昆[2]使用预先定义的规则来抽取各种类别的实体,程志刚[3]采用基于规则和条件随机场的方法来进行中文命名实体识别研究。基于规则的命名实体识别方法需要富有经验的专家总结规则,模型的稳定性依赖专家的知识结构,不同专家给出的规则之间可能会存在矛盾。为克服基于规则的命名实体识别的不足,Bengio[4]提出了基于机器学习的命名实体识别方法。李丽双等[5]利用信息熵和词频变化对汽车领域的术语进行识别,冯艳红等[6]将领域术语特征和语义特征融入到CRF模型中,完成对渔业领域术语的识别。这些方法在不同领域的语料上均取得了较好效果,但在训练时需要事先设计针对特定领域的特征,使用人工定义的特征作为模型输入,模型的效果严重依赖特征的选择,泛化能力不强。
为避免人工选择特征在命名实体识别方面的不足,基于深度学习的命名实体识别成为研究的热点。深度学习的核心技术是用词向量表达文本中词语的特征[7]。谢逸等[8]利用CNN和LSTM训练词语的分布式特征;毛存礼等[9]利用基于降噪自动编码器获取用于有色金属领域实体识别的最优特征向量组合;候伟涛等[10]使用双向LSTM神经网络学习文本的隐藏特征用于医疗事件识别。这些方法均使用深度学习模型进行特征学习,在相应领域的命名实体识别中均获得了较好效果。但是由于中文缺少明显的空格标记,需要做分词处理,而现有的分词方法对于特定领域的专业术语分词错误率很高。为解决高分词错误率对实体识别任务的影响,Lu等[11]采用word embeddings的向量表示方法,将每个中文字符转换成对应的character embedding向量;Dong等[12]采用基于字符级别的网络结构进行实体识别。但这些方法均是针对通用领域进行的模型选择和参数设置,未考虑渔业领域命名实体的结构特点,直接用于渔业领域命名实体效果不理想。
目前,渔业领域命名实体识别主要存在以下问题:第一,现有的分词工具主要用于通用领域分词,用于渔业领域分词时效果不佳,很多渔业领域专业词会被错分,这将严重影响基于分词的渔业领域命名实体识别的准确性;第二,渔业领域的命名实体一般长度较长,组成命名实体的字之间存在很强的相关关系,单一的网络结构不能很好地刻画这种依赖关系。针对上述问题,在前人研究的基础上,为避免分词不准确对渔业领域命名实体识别带来的影响,本研究中采用训练字向量的方式代替词向量,利用LSTM模型保持较长时间记忆信息,解决传统方法无法捕捉长命名实体前后文隐含信息的缺点。最后,结合CRF可以利用句子级别的标记信息训练实体分类器,旨在提高渔业领域命名实体的识别效果。
1 渔业领域命名实体识别框架
针对渔业领域命名实体的结构特点提出了如图1所示的命名实体识别模型。
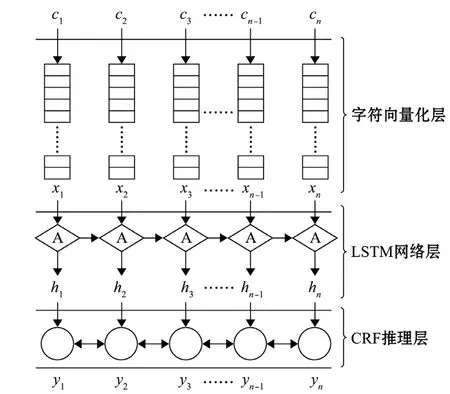
图1 渔业领域命名实体识别模型框架Fig.1 Frame work of fishery domain named entity recognition
模型由3部分组成:字符向量化层、LSTM网络层、CRF推理层。字符向量化层用于把组成文本序列的字符ci转化为用于模型训练的字符向量xi;针对渔业领域命名实体一般长度较长的特点,使用LSTM网络层获取更多的语义信息,提取渔业领域命名实体包含上下文的特征向量hi;CRF推理层能够通过动态规划的最优路径推理计算,把提取到的特征向量变换为字符对应的标签yi。针对渔业领域命名实体识别任务采用BIESO标记方案[13],即B用来表示渔业领域命名实体的第一个字符,I用来表示渔业领域命名实体的内部字符,E表示渔业领域命名实体的结尾字符,S表示单个字符独立组成渔业领域命名实体,O表示不是渔业领域命名实体中的字符。
1.1 字符向量层
要将文本交由计算机处理,首先要将文本向量化。文本向量化有两种表示方法:one-hot表示和分布式表示[14]。one-hot表示没有考虑文本之间的相互关系,且容易遭受维数灾难的影响;分布式表示是以低维度的向量来表示字,让相关的字在语义上更接近。为获取渔业领域命名实体内部字符之间的语义结构特征,并回避领域分词对实体识别结果的影响,本研究中采用分布式表示方法来进行字符向量化表示。分布式表示包括CBOW模型[15-16]和Skip-gram模型。CBOW在训练效率上高于Skipgram,故本研究中采用CBOW模型来训练字的分布式特征。
本研究中训练字向量的数据来自 《水产辞典》和海洋领域标准文档。经过预处理后得到约92万字符,以7∶3的比例分成训练集和测试集。CBOW模型的框架如图2所示。
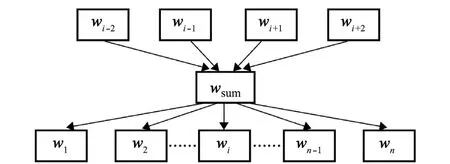
图2 CBOW模型结构Fig.2 CBOW model structure
以文本序列 “水产养殖学”为例,模型的任务是通过字符 “养”的上下文 “水产殖学”,来预测所有字符出现的概率,目标是使中心字符 “养”出现的概率最大。模型的输入是 w(i-c),w(i-c+1), …,w(i+c-1), w(i+c), 表示字符 ci上下文对应的字向量,c为窗口大小,表示在字符ci的前后各取c个字;映射层将2c个字向量求和得到wsum,输出层神经单元的个数为训练集字典大小n,每个神经元的值代表字典中每个词出现的概率,中心字符向量wi出现的概率越大模型效果越好。
目标函数为
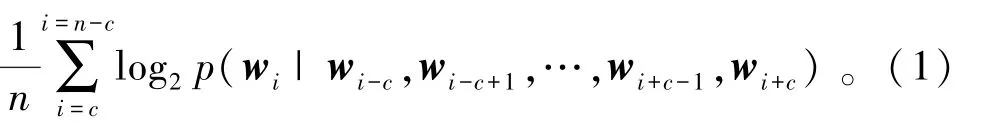
其中:p(wi|wi-c, wi-c+1, …, wi+c-1, wi+c) 是给定上下文 wi-c, wi-c+1, …, wi+c-1, wi+c条件下 wi出现的概率。通过对目标函数的训练,每个字都获取到了一个对应的m维字向量xi,一般来说维度越高,模型的效果越好,但是训练成本也会越高,此处根据经验选定m为100维。
1.2 LSTM网络
通过对大量渔业领域的命名实体进行分析,发现渔业领域的命名实体一般长度较长,组成命名实体的相邻字符间存在着很强的相关关系。图3为《水产辞典》[17]中5194条专业术语字符组成个数的统计情况。
由图3可以看出,组成渔业领域命名实体的字符个数集中在3~7之间,这些字符的特征向量很大程度上依赖上文信息。RNN模型[18]具有保持之前信息的能力,其最大特点是神经元的某些输出可作为其输入再次传入到神经元中,其链式结构很适合处理渔业领域命名实体识别任务的长序列问题。但是在训练中存在梯度爆炸和消失问题,难以保持较长时间的记忆。

图3 《水产辞典《渔业领域命名实体字符组成个数统计图Fig.3 Statistical graph of the number of characters in“Fishery Lexicon”
LSTM模型就是为了解决RNN模型存在的问题而设计的,它可以实现记住长期信息的能力[19]。相较于RNN模型单一的重复链式模块,LSTM模型拥有不同的结构,LSTM细胞状态的更新过程如图4所示。

图4 LSTM模型结构Fig.4 LSTM model structure
LSTM模型通过特有的Gates结构来保持和更新细胞状态,以达到长期记忆功能。
(1)遗忘门。从当前细胞状态中忘记无用信息,输入由当前层输入xt+1和上层输出ht组成:

其中:wf为对各部分信息的记忆权重;bf为渔业领域的先验知识;at+1为0~1之间的实数,控制不同部分信息传递的比例。
(2)输入门。控制哪部分信息应该被记住,输入包括 xt+1和ht两部分:
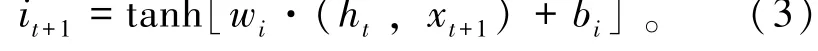
其中:wi、bi与wf、bf表示的含义相同,但有不同的值,通过值的不同控制哪些信息应该被记住,哪些信息应该忘记,旧的细胞状态和新的候选信息一起组成新的细胞状态。

(3)输出门。决定最后的输出信息,先使用sigmoid函数决定要输出细胞状态的部分信息,然后用tanh处理细胞状态,两部分信息的乘积得到输出值,即

通过LSTM网络处理,渔业数据集得到了最优的向量化表示hi,为之后的标签推理做准备。
1.3 CRF模型
在LSTM网络层之后接入一个线性层,将特征向量映射到k维,k是标注集的标签数,记作矩阵p =(p1, p2, …, pn) ∈Rn×k, n 是训练集中字符长度。把pi∈Rk的每一维pij视为将字xi分类到第j个标签的打分值。为了描述标签间的依赖,引入CRF层[20]进行句子级别的序列标注。CRF层的参数是一个k×k的转移得分矩阵A,其中Aij表示从第i个标签转移到第j个标签的得分,这样在为一个位置进行标注的时候可以利用之前已经标注过的标签。对于句子长度为n的标签序列y= (y1,y2,…,yn),模型对于句子x的标签y的打分为
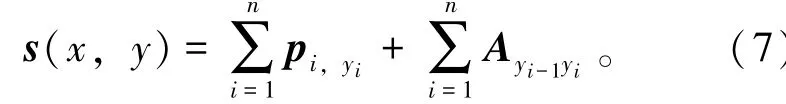
可以看出,整个序列的打分等于各个位置的打分之和,而各个位置的打分由得分矩阵和转移矩阵组成。模型训练时通过最大化得分函数,即可求得文本的最佳得分序列。
2 结果与分析
2.1 试验环境、数据和评价指标
本研究中的试验环境为intell(R)Core i3-4150 CPU 3.5GHz处理器,4.00 GB内存,操作系统为Ubuntu 14.04 64 bit。字符向量化由实现了CBOW模型的开源Word2VEC[21]训练得到,LSTM网络层由Keras 0.33实现。
本研究中试验数据来源于课题组已收集的渔业领域文档,分别为 《水产辞典》和海洋渔业领域的国家和地方标准文档。《水产辞典》分为渔业资源、水产捕捞、水产养殖等10个类别,去掉文中特殊符号和插图,得到约55万字的文本;标准文档包括海水养殖类文档和水产品类文档,选取167篇,经过预处理后得到约37万字的文本。所以渔业领域语料共有约92万字的文本。
实体识别评价指标采用准确率(P)、召回率(R)、综合指标(F值), 其计算公式为

其中:P、R、F的值介于0和1之间;P和R的值越接近1,准确率或召回率越高;F为P和R的均衡平均数,表达了实体识别的综合效果。
2.2 试验设计及结果
为验证本研究中提出的模型对渔业领域实体识别的效果,分别设置了如下3组试验。
试验1:不同模型对渔业领域实体识别结果的比较。表 1分别给出了 LSTM模型、Character+LSTM+Softmax模型及Character+LSTM+CRF模型的识别效果。

表1 不同模型对渔业领域命名实体识别效果比较Tab.1 Comparison of different models for identification effect in fishery domain %
从表1可以看出:LSTM模型识别效果较差,Character+LSTM+Softmax模型的识别效果较LSTM模型高出1.26%;Character+LSTM+CRF的识别效果较LSTM有1.93%提升,这表明本研究中提出的基于深度学习的模型较LSTM模型在渔业领域命名实体识别任务上有较好的效果。
试验2:分别以字和词构造的Embedding向量对模型识别效果进行比较。为了证明基于字向量的深度学习模型能有效避免分词不准确对渔业领域命名实体识别带来的影响,试验分别测试了以中文字符构造的Character Embeddings向量和以中文词语构造的Word Embeddings向量作为深度学习模型的输入进行渔业领域命名实体识别试验。表2说明了以字特征来构造embeddings向量比以词特征来构造的Embeddings向量能有效提升模型的识别效果。

表2 Word Embeddings和Character Embeddings识别效果比较Tab.2 Comparison of Word Embeddings and Character Embeddings for identification effect in fishery domain %
试验3:对比不同时间步长对深度学习模型实体识别效果的影响。通过试验1和试验2,可以得出结论:采用字向量构造的文本向量层结合LSTM和CRF模型可以有效提升渔业领域命名实体识别的效果。本试验在保证其他条件保持相同的情况下,设置了3组参照试验来对比不同时间步长(3、5、7)对结果的影响。

表3 不同时间步长识别效果比较Tab.3 Comparison of different timesteps for identification effect in fishery domain %
从表3可以看出,在保持深度学习模型其他条件相同的情况下,时间步长设为5能达到最好的识别效果,这与 《水产辞典》中实体的字符组成个数结果相吻合。通过对文献[22]渔业数据的分析,证明了一个字与它最临近的5个字在句法语义上具有非常强的相关关系,也由此说明了本研究中试验结果的合理性。
3 结论
针对渔业领域命名实体识别面临的问题,提出了一种基于深度学习模型的渔业领域命名实体识别方法。该方法利用训练字向量的方法代替训练词向量,有效避免了采用传统分词工具分词不准确对渔业领域命名实体识别结果的影响;选择可以记住上文信息的LSTM模型作为隐藏层,解决了渔业领域命名实体结构较长的问题;最后使用CRF作为标签推理层解决文本序列标签依赖问题。在已有的渔业数据上进行试验,试验结果证明了本文提出Character+LSTM+CRF模型的有效性。基于深度学习的渔业领域命名实体识别模型Character+LSTM+CRF也可推广到与渔业领域有相似特点的领域,具有一定的通用性。
参考文献:
[1] 阎笑彤,徐翔,郭显久,等.基于WEB的水产养殖病害诊断专家系统[J].大连海洋大学学报,2016,31(2):225-230.
[2] 周昆.基于规则的命名实体识别研究[D].合肥:合肥工业大学,2010.
[3] 程志刚.基于规则和条件随机场的中文命名实体识别方法研究[D].武汉:华中师范大学,2015.
[4] Bengio Y.Learning deep architectures for AI[J].Foundations and Trends in Machine Learning,2009,2(1):1-27.
[5] 李丽双,王意文,黄德根.基于信息熵和词频分布变化的术语抽取研究[J].中文信息学报,2015,29(1):82-87.
[6] 冯艳红,于红,孙庚,等.基于词向量和条件随机场的领域术语识别方法[J].计算机应用,2016,36(11):3146-3151.
[7] Mnih A,Hinton G.A scalable hierarchical distributed language model[C]//Proceedings of the 21st International Conference on Neural Information Processing Systems.British:Curran Associates Inc,2008:1081-1088.
[8] 谢逸,饶文碧,段鹏飞,等.基于CNN和LSTM混合模型的中文词性标注[J].武汉大学学报:理学版,2017,63(3):246-250.
[9] 毛存礼,余正涛,沈韬,等.基于深度神经网络的有色金属领域实体识别[J].计算机研究与发展,2015,52(11):2451-2459.
[10] 候伟涛,姬东鸿.基于Bi-LSTM的医疗事件识别研究[J].计算机应用研究,2018,35(7),http://www.arocmag.com/article/02-2018-07-019.html.(优先出版)
[11] Lu J,Ye M,Tang Z,et al.A novel method for Chinese named entity recognition based on Character vector[M]//Guo S,Liao X,Liu F.Collaborative Computing:Networking,Applications,and Worksharing.Cham:Springer,2016.
[12] Dong C H,Zhang J J,Zong C Q,et al.Character-based LSTMCRF with radical-level features for Chinese named entity recognition[M]//Lin C Y,Xue N,Zhao D.Natural Language Understanding and Intelligent Applications.Cham:Springer,2016.
[13] Collobert R,Weston J,Bottou L,et al.Natural language processing(almost)from scratch[J].Journal of Machine Learning Research,2011,12:2461-2505.
[14] 温潇.分布式表示与组合模型在中文自然语言处理中的应用[D].南京:东南大学,2016.
[15] Mikolov T,Chen K,Corrado G,et al.Efficient estimation of word representations in vector space[J].arXiv:1301.3781,2013.
[16] Mikolov T,Sutskever I,Chen K,et al.Distributed representations of words and phrases and their compositionality[C]//Proceedings of the 26th International Conference on Neural Information Processing Systems.Lake Tahoe,Nevada:Curran Associates Inc,2013:3111-3119.
[17] 水产辞典编辑委员会.水产词典[M].上海:上海辞书出版社.
[18] Mikolov T,Karafiát M,Burget L,et al.Recurrent neural network based language model[C]//INTERSPEECH 2010,Conference of the International Speech Communication Association.Makuhari,Chiba,Japan:DBLP,2010:1045-1048.
[19] Sak H,Senior A,Beaufays F.Long short-term memory recurrent neural network architectures for large scale acoustic modeling[C]//15th Annual Conference of the International Speech Communication Association.Singapore:ISCA Archive,2014:338-342.
[20] He H F,Sun X.F-score driven max margin neural network for named entity recognition in Chinese social media[J].arXiv:1611.04234,2017.
[21] Word2VEC[EB/OL].[2015-09-08].https://github.com/NLPchina/Word2VEC_java.
[22] 王兰.基于维基百科的渔业知识库构建研究[D].上海:上海海洋大学,2014.
猜你喜欢
电脑爱好者(2022年15期)2022-05-30 01:29:23
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19 08:52:46
小学生学习指导(低年级)(2019年12期)2019-12-04 03:39:42
电子制作(2019年19期)2019-11-23 08:41:50
智富时代(2019年6期)2019-07-24 10:33:16
少儿美术(快乐历史地理)(2018年7期)2018-11-16 05:31:14
东方女性(2018年3期)2018-04-16 15:30:02
散文诗(2017年17期)2018-01-31 02:34:08
高中生·天天向上(2016年9期)2016-11-22 09:10:34
青苹果·教育研究版(2013年2期)2013-04-29 00:44:03
