
基于多标签机器学习的环境适老化改造应用研究
2018-04-26 08:34鲁卫华
无线互联科技 2018年7期
崔 震,鲁卫华,李 鹏,韩 涵,陈 文
(中国电子工程设计院有限公司 健康与养老研究所,北京 100142)
1 研究现状
近年来,老龄化问题日趋严峻,现有的住宅环境并未系统地考虑老年人日常起居的各种适老性需求,老年人生活中存在诸多不便,甚至存在不同程度的安全隐患,从而影响到老年人的生活品质和健康质量。针对此类问题,王羽等搭建了国内首个适老建筑参数实验室,在老年人卧室设计、轮椅回转半径、老年人起居室照度、适老住宅开关插座高度、厨房卫生间空间适老性等方面进行了大量实验,并初步提出了各项适老化改造规范[1-5]。但尚未从老年人实际个人需求出发,制定各改造项的改造规则。
本文拟从老年人实际个人状况出发,利用多标签机器学习算法研究老年人能力与适老改造项之间的关联性,并给出个性化推荐方案。
2 多标签排序算法原理
本文主要针对居家环境的适老化改造,利用电子问卷的方式对居家老人完成数据采集,内容包括21项老人能力项及15项适老改造项。用D表示数据集,D={(Xi,Yi)|i=1,2,…,m},其中:Xi是第i个老人样本的能力特征向量;Yi表示第i个样本的适老改造项有序相关标签集合。有序多标签数据集的样例,如表1所示。

表1 有序多标签数据集样例
为了学习适老改造项标签的顺序,本文在校准标签排序算法的基础上引入了ML-kNN算法,在学习过程中将标签排序问题转换成多标签分类问题,Dtrain和Dtest分别表示训练集和测试集。
2.1 校准标签排序
传统的成对比较排序法是利用One VS One策略将标签排序问题转换成标签分类问题,将两两标签对的排序进行比较,如式1所示。
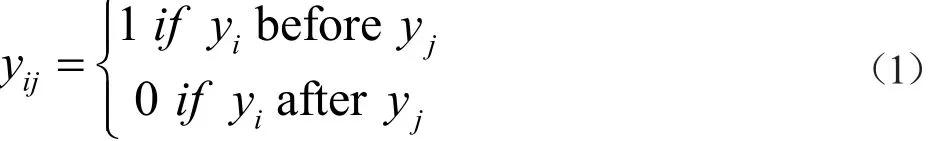
根据One VS One策略,需遍历n*(n-1)/2次即可完整表述所有标签对之间的关系,n为标签总个数,对每个标签对构建分类器,给定一个未知样本,对每个分类器的预测值进行投票,通过阈值法将排序后的投票结果划分为该样本的相关标签和不相关标签,然后根据投票结果对相关标签进行排序[6]。该方法的主要难点在于:如何确定阈值来尽可能正确地估计样本所属的类别标签集合。因此校准标签排序算法引入了校准标签yv,将其作为每个样本的相关标签和不相关标签的一个自然划分点;在每个标签相互成对比较的同时,也要将每个标记与校准标签进行成对比较。对于给定的未知样本,将所有分类器的预测结果进行投票,将投票次数大于校准标签yv的类别标记看成该样本的相关标签,并根据投票结果进行排序[7-8]。问题转换过程如图1所示。
校准标签排序问题转换过程:

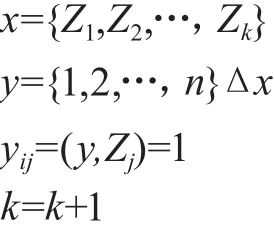
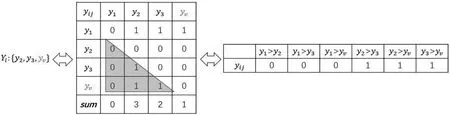
图1 校准标签排序问题转换
2.2 多标签k近邻
通过校准标签排序问题转换后,将问题转换为无相关的多标签分类问题,其特点是标签维度多,分布杂乱且有交叉,因此本文引入了多标签k近邻(Multi-label K Nearest Neighbors,ML-kNN)算法。ML-kNN算法是在kNN框架下处理多标签分类问题的算法,具有效率高,且对标签域有交叉重叠的分类效果较好等特点[8]。ML-kNN算法在输入测试数据后,用kNN算法根据老人能力项确定相应的邻域标签信息,如式2所示。利用先验概率与后验概率通过最大后验概率准则和贝叶斯准则计算得到预测样本的标签对关系集合,如式3所示。
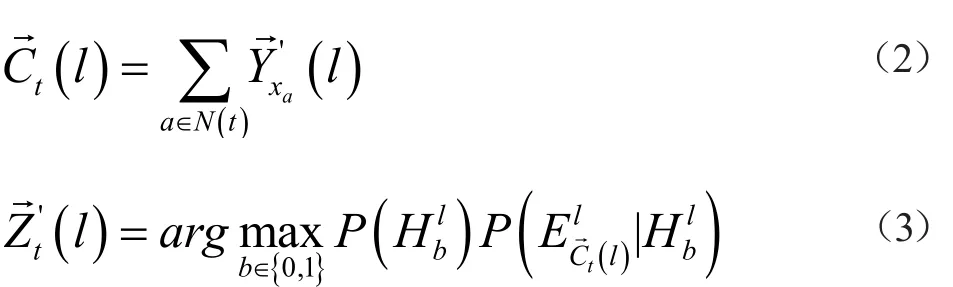
ML-kNN算法流程:
(2)确定数据邻域N(xi),i∈{1,…,n*(n+1)/2}。
(3)forlfrom 1 toq//q为类标个数即n*(n+1)/2。
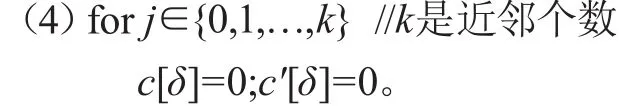
(5)fori∈{0,1,…,n}。
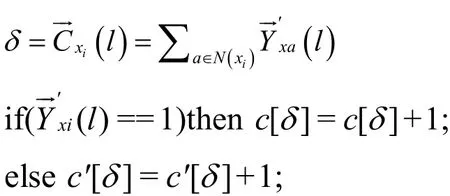
(6)forj∈{0,1,…,k}。
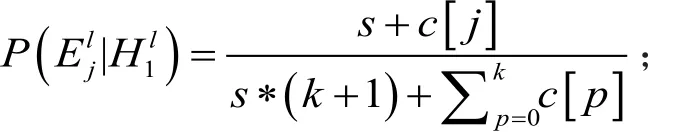
(7)确定测试数据的邻域N(t)。
(8)forlfrom 1 toq。
(9)将分类问题反变换回到排序问题,得到测试数据标签排序Zt。
根据矩阵对称的特点,重构标签对关系矩阵,并进行投票统计,将投票次数大于校准标签yv的类别标记看成该样本的相关标签,并对相关标签按照投票结果排序,如图1所示。
3 实验效果分析
3.1 预处理
本文在前期进行了大量的数据采集工作,采集方式主要为电子问卷的方式,数据内容包括两部分:能力项和适老改造项,其中能力项包括进食能力、梳洗能力、如厕能力、排便能力、自由移动能力、自主洗浴能力、记忆力衰退、抑郁症、跌倒、噎食、高血压、糖尿病、帕金森、老年痴呆、通风、肢体骨折、眼疾、失聪等,每个能力项根据严重程度分为4个等级(0分、3分、5分、10分),分值越高,能力越差;适老改造项包括选用照度高的灯具、清除房间地面高差、选用防滑地面、降低开关位置、炉灶自动断火、水温调节、操作台添加轮椅空间、安全扶手、洗手盆下方留空、洗浴区助浴椅、玄关鞋柜及穿鞋凳、发光门铃、马桶扶手及安装紧急呼叫器等。每位老人根据个人实际状况勾选能力项并根据个人意愿对适老改造项进行筛选并按照需求进行排序。
由于采集对象为老年人,消费观念和身体重视程度差异较大,因此需要进行数据清洗,删除个人能力项和改造项为空集的样本,并对相邻重复的样本进行了适当的删减,最终获得的老人样本数为257个。为了提高学习器的准确性,对数据进行了归一化处理并对数据的能力项特征进行主成分分析(Principal Component Analysis,PCA)处理,删除冗余的能力项信息,最终保留了15项作为能力项的属性特征。对样本集做随机抽样,选取205个样本作为训练集Dtrain,52个样本作为测试集Dtest。
3.2 评测指标
本文采用3个评测指标对算法性能进行评价。对于一个样本Xi,用Zi表示学习器给出的Xi所属的标签集,Yi表示老人自选改造项集,ri(y)表示标签y在预测出来标签中的排序位置,y'表示预测出来的标签。
汉明损失Hamming Loss:该指标度量的是预测标签与真实标签集之间的差异性,及相关的标签不包含在真实结果中或不相关标签包含在真实结果中。该指标值越小说明与真实标签集越吻合。
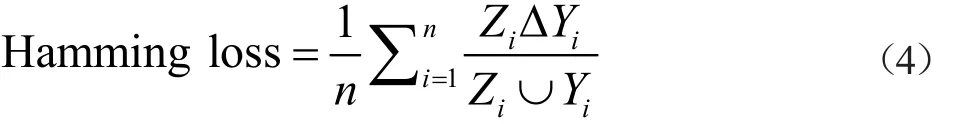
其中ZiΔYi表示对称差集长度;Zi∪Yi表示并集长度。
(2)1-错误率One-Error:该指标度量的是学习器对每个样本的预测标签集合中,排序最靠前的标签不属于该样本实际标签集合的情况。该指标值越小说明预测效果越好。
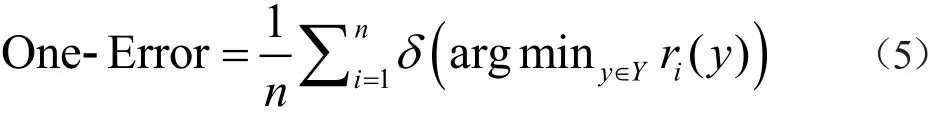
其中arg miny∈Yri(y)表示预测排位最靠前的标签,当arg miny∈Yri(y)∈Yi时,δ(y)=0;否则δ(y)=1。
平均精度AvgPrec:该指标反映了所有样本的预测标签排序中,标签排序值比真实结果集中的某一个标签大的标签个数,该值越大表明预测结果越好。
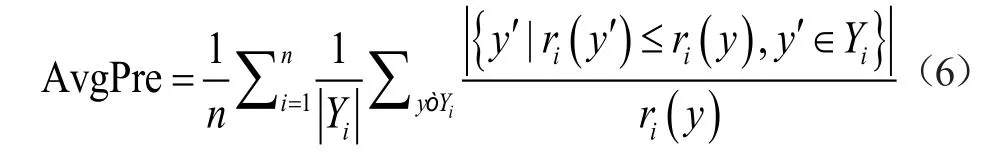
3.3 适老改造预测效果
本文选择传统的成对比较排序法(Ranking by Pairwise Comparison,RPC)与校准标签排序算法(Calibrated Label Ranking,CLR)作为对比方法进行试验,两种算法都属于问题转换方法且均采用支持向量机(Support Vector Machine,SVM)作为基分类器。实验结果如表2所示,可以直观地看出CLR+ML-kNN算法的汉明损失更低,准确率更高,因为SVM在处理分布不均的类标集时容易陷入过拟合。从1-错误率与平均精度来看CLR+SVM和CLR+ML-kNN效果更佳,这是因为校准标签的引入,过滤了部分非相关标签,使得排序精度更高,效果更好。
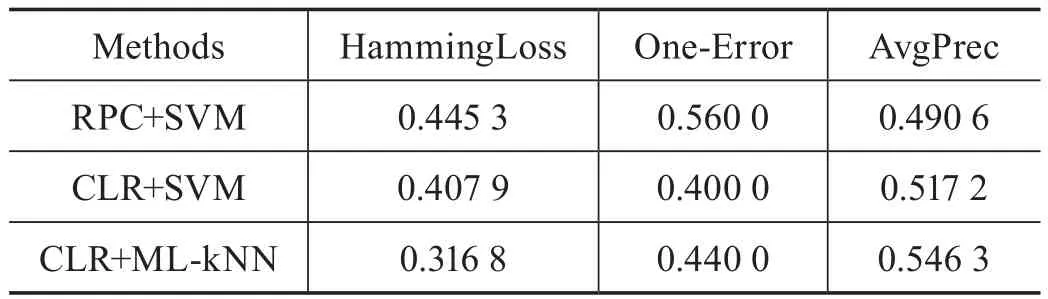
表2 3种算法在各评测指标上的结果
4 结语
随着社会老龄化日趋严重,居家养老的适老化改造逐渐成为社会的热点研究问题。然而大多数都是趋于某个改造项的参数研究,缺少将改造项整合的个性化方案研究。本文根据老年人改造需求的排序,提出了基于多标签机器学习的环境适老化改造算法,引入CLR与ML-kNN,经测试表明,相比传统的RPC与CLR效果更佳,适合进行环境适老化改造个性化的方案推荐。
[参考文献]
[1]王羽,王朝霞,王辛,等.适老建筑实验室[J].住区,2015(1):103-109,102.
[2]贵晨,王羽,王辛,等.适老卧室实验[J].住区,2015(2):115-125,114.
[3]王朝霞,王羽,王辛,等.老年人居住建筑设计规范系列论证(一)—老年人轮椅回转空间基础实验[J].住区,2015(1):145-151.
[4]邓超,王羽,郝俊红.适老住宅开关插座高度实验[J].住区,2015(5):82-88.
[5]HÜLLERMEIER E,FÜRNKRANZ J,CHENG WW,et al.Label ranking by learning pairwise preferences[J].Artificial Intelligence,2008(16):1897-1916.
[6]FÜRNKRANZ J,HÜLLERMEIER E,MENCÍA EL,et al.Multilabel classification via calibrated label ranking[J].Machine Learning,2008(2):133-153.
[7]WANG M,LIU M,FENG S,et al.A novel calibrated label ranking based method for multiple emotions detection in Chinese microblogs[J].Communications in Computer & Information Science,2014(496):238-250.
[8]ZHANG M L,ZHOU Z H.ML-KNN:a lazy learning approach to multi-label learning[J].Pattern Recognition,2007(7):2038-2048.
猜你喜欢
中学生数理化·七年级数学人教版(2022年11期)2022-02-14
科普童话·学霸日记(2020年1期)2020-05-08
车迷(2018年11期)2018-08-30
知识经济·中国直销(2018年8期)2018-08-23
海峡姐妹(2018年3期)2018-05-09
公民与法治(2016年10期)2016-05-17
中国老区建设(2016年1期)2016-02-28
计算机工程(2015年8期)2015-07-03
