
K-Means优化算法的R语言实现
2018-04-25 11:11郭显娥
山西大同大学学报(自然科学版) 2018年2期
郭显娥
(山西大同大学数学与计算机科学学院,山西大同037009)
我们知道聚类算法很多,如有:K-均值聚类(K-Means),K-中心点聚类,密度聚类,层次聚类与期望最大化聚类。这些算法本身无所谓优劣,在很大程度上取决于数据使用者对于算法的选择是否得当,运用于数据的效果却存在好坏差异[1-4]。
1 K-Means的经典算法
1.1 经典算法与R语言实现
K-Means算法是发展最成熟且原理简单、算法流程清晰,经典算法的步骤描述,分为如下5步完成。
①随机选取K个样本作为n个样本点类中心center_K;
②计算各样本点plot(x[i],y[i])与各类中心cen⁃ter_K的距离;
③将各样本归于最近的类中心点;
④求各类的样本的均值,作为新的类的中心center_K_new;
⑤判定:若类中心不再发生变动或达到迭代次数,算法结束,否则回到第②步。
编写K-Means经典算法的R语言实现(核心代码)见图1所示。
1.2 K-Means的经典算法的弊端
传统的K-means算法由于初始聚类中心选择的随机性,算法结果随着中心点选择的不同而改变,导致结果的不稳定性,可能会造成局部最优值的问题。K-Means算法的时间复杂度为O(nKt),其中:n是数据集中对象的数量,t是算法迭代的次数,K是中心点的预期,当数据量增加时,表现出时间复杂度变大,算法效率低,尤其对噪声和输入数据不太敏感等弊端。

图1 K-Means算法的R语言实现
2 K-Means的优化算法
2.1 基于Map-Reduce的K-means算法
在传统的K-means算法基础上,提出了基于Map-Reduce的K-means算法。该算法的思想是:
假定训练样本为X={x(1),x(2),…,x(m)},其中,x(i)∈Rn(i∈[1,m]),且要将样本聚类成k个数据片,算法分为三步完成,如图2所示.

图2 基于K-means的Map-Reduce算法
K-Means运行过程如图3所示:在图中一共有a至e这5个数据以及2个随机的质心点(灰色点)。图3(a)为算法经过初始化后的状态,图3(b)和图3(d)是两个更新过程,图3(c)和图3(e)是两个更新后的状态。经过2轮更新该算法达到稳定如图3(e)所示。

图3 K-Means 算法过程示例
2.2 优化算法
在上述算法的前提下,引入Hadoop并行化处理方式,将Map-Reduce函数对不规律动态增加的数据进行并行处理,以数据对象不确定性为研究目标进行两个类之间的新距离计算方式对K-means算法进行优化。
该算法的优化是将所采集到的原始数据划分成为n个数据片,将数据片中的每一个数据作为一个类,计算类与类之间的距离,并将距离最小的两个类合并,计算类间距离过程中引入Map函数实现并行化处理,Reduce函数更新类中心点,计算新类的中心点,判断聚类是否收敛,若收敛则输出聚类结果,若不收敛则返回类重新进行距离计算。
2.2.1 优化算法描述
优化算法引入了Map-Reduce函数进行数据的并行化处理,利用Map函数将数据集划分成为若干个数据片,每片的数据分配到不同节点上独立执行K-means算法,而随着K-means算法的迭代,每个数据片中心也将不断变化,Shuffle与Reduce函数进行数据片中心合并汇总,所得结果的键值对重新计算中心点,不断进行K-means算法的迭代,直到收敛为止。其流程如图4所示。
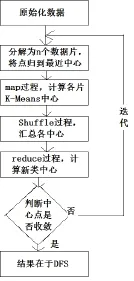
图4 K-means算法优化流程
2.2.2 优化算法中的迭代过程

3 K-Means的优化算法的R语言实现
3.1 大数据挖掘与R语言
大数据挖掘是从海量的数据中发现在趣知识的过程,涉及多个领域的交叉学科,包括统计学、机器学习、模式识别及生物信息学等,大数据挖掘的主要技术包括分类与预测、聚类、关联规则等,还包括一些新的技术,如社交网络和情感分析。在实际应用中,大数据挖掘过程通常分为业务理解、数据清洗、数据预处理、建模、评估和部署6个主要阶段。
R语言是目前在数据分析应用领域广泛使用的数据分析、统计计算及制图的开源软件系统,其提供了大量的专业模块和实用工具。为了在现有大数据平台间使用R语言环境,行业数据分析师在R语言中利用分布式并行计算引擎处理大数据。将R语言与Hadoop结合起来,最早的系统是RHadoop。Hadoop主要用于存储和处理底层的海量数据,R语言则替代Java语言完成Map-Reduce算法的设计实现,使Map-Reduce程序实现到基于R语言的编程接口上,即编程接口用R语言封装。
3.2 优化K-Means算法的R语言实现
优化K-Means算法的R语言实现步骤:
Step1:生成分布式数据样本 3 subsets各120samples模拟拆分出的n个数据片;
Step2:设置聚类参数(聚类数目与新旧中心更新停止阈值;
Step3:可视化原始数据;
Step4:初始化聚类中心函数;
Step5:更新聚类中心函数;
Step6:生成k-means函数;
Step7:随机初始化聚类中心并可视化;
Step8:模拟n片数据的分布式计算。
由于篇幅的限制,下面只给出Step8的源代码,如图5与图6所示。

图5 Map函数实现
3.3 程序测试及应用
针对上述3.2优化算法的R语言实现程序做了相应的测试,所得结果见图7。
图中聚类3类,图7(a)、7(b)、7(c)分别为三个不同的数据片上的聚类,图7(d)是用循环模拟n片数据的分布式计算并验证程序的可行性,其中黑色三角为初始中心,“米”字标记为聚类结果中心,“红”、“绿”、“黑”三种不同颜色表示聚类结果。

图6 Rduce函数实现

图7 R程序测试结果图
程序的应用适合于各种大数据集,如精准营销,广告推荐,互联网金融及行业大数据分析,如:地震大数据、交通大数据、环境大数据与警务大数据等等。
4 结束语
随着数据量呈指数级的增长,大数据、云计算、人工智能时代的到来,数据挖掘、数据聚类的算法研究显得尤为重要。K-Means算法过程简单、易于实现、应用广泛,是人们首选的聚类算法,基于Map-Reduce大数据处理平台的K-Means优化算法是目前研究的热点。今后有望对K-Mean算法在并行处理方面有更深入的研究与成果。
[1]宋杰,孙宗哲,毛克明,等.MapReduce大数据处理平台与算法研究进展[J].软件学报,2017,28(3):514-543.
[2]李晓瑜,俞丽颖,雷航,等.一种K_means改进算法的并行化实现与应用[J].电子科技大学学报,2017,46(1):61-68.
[3]刘继华,强彦.云计算下的一种数据挖掘算法的研究[J].科技通报,2016,32(12):133-137.
[4]刘鹏.大数据[M].北京:电子工业出版社,2017.
猜你喜欢
大众投资指南(2021年35期)2021-02-16
计算机技术与发展(2020年8期)2020-08-12
中国交通信息化(2020年1期)2020-07-27
电脑报(2020年12期)2020-06-30
铁道通信信号(2019年6期)2019-10-08
电脑报(2019年4期)2019-09-10
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
大众摄影(2015年9期)2015-09-06
智能系统学报(2013年1期)2013-01-28
