
开源搜索引擎Elasticsearch和Solr对比和分析
2018-04-24 12:17魏涛孟方园袁平殷锋
现代计算机 2018年6期
魏涛,孟方园,袁平,殷锋
(1.四川大学计算机学院,成都 610065;2.北京卫星导航中心,北京 100094;3.重庆第二师范学院,重庆 400067;4.西南民族大学校园网络管理中心,成都 610064)
0 引言
在信息化高速发展的今天,大量的智能设备以及人类的活动通过互联网进行计算和通信,从而在互联网上产生了大量的信息,在这些海量的信息中既包含着对我们有用的信息,同时也充斥的大量的无用信息,用传统的工具如关系型数据库对这些信息进行存储,检索和分析显然力不从心[1]。因此,有大量的工具被开发出来,从而为检索和处理海量的数据提供了有效的解决办法[2]。其中,作为同为基于全文搜索框架Apache Lucene的Elasticsearch和Solr,其主要功能相似,但在配置部署,使用及检索性能方面存在一定的区别,本文通过对二者进行对比和分析,为项目成员对这二者搜索引擎的选择提供参考。
1 简介
Elasticsearch是一个分布式、可扩展、实时的搜索与数据分析引擎。Elasticsearch不仅可以全文搜索,同时提供结构化搜索、数据分析、复杂的语言处理、地理位置和对象间关联关系等[3]。通过REST和schemafree的JSON文档提供分布式、多租户全文搜索。并且官方提供 Java,Groovy,PHP,Ruby,Perl,Python,.NET和JavaScript客户端。许多互联网公司使用Elastic⁃search作为其内部搜索引擎,如Wikipedia使用Elastic⁃search提供带有高亮片段的全文搜索。卫报使用Elas⁃ticsearch将网络社交数据结合到访客日志中,实时的给它的编辑们提供公众对于新文章的反馈。Stack Over⁃flow将地理位置查询融入全文检索中去,并且使用more-like-this接口去查找相关的问题与答案。GitHub使用Elasticsearch对1300亿行代码进行查询。
Solr支持许多世界上最大的互联网站点的搜索和导航功能。Solr它是一种开放源码的、基于Lucene Java的搜索服务器,它易于安装和配置,具有高可靠性、可扩展性和容错性,可提供分布式索引,复制和负载平衡查询,自动故障转移和恢复,集中式配置等功能[4]。而且附带了一个基于HTTP的管理界面。Solr提供分布式索引、分片、副本集、负载均衡和自动故障转移和恢复功能。不少知名企业,如AT&T,eBay,Instagram和Netfilx均使用Solr。
2 功能比较
2.1 Elastics earch
Elasticsearch是一个强大的搜索引擎,基于Apache Lucene的全文搜索引擎框架开发,具有近实时、高性能、分布式和零配置的优点。Elasticsearch有以下几个关键的概念:
●节点(Node):节点是一个Elasticsearch的实例,一般一台主机上部署一个节点
●集群(Cluster):集群由若干节点组成,和任意节点的通信等价于和集群的通信
●分片(Shard):一个索引会分成多个分片存储,分片数量在索引建立后不可更改
●副本(Replica):副本是分片的一个拷贝,目的在于提高系统的容错性和搜索的效率
●索引(Index):类似数据库的库
●类型(Type):类似数据库的表
●文档(Document):类似数据库的行,包含一个或多个Field
●字段(Field):搜索的最小单元,可通过Mapping定义不同的属性(比如类型,可否被搜索等)
Elasticsearch的部署属于一键式的,只需解压从官网下载的压缩包并运行bin目录下的elasticsearch程序即可(前提是本机已配置好JDK),一旦在多台主机上启动拥有同一个cluster.name的Elasticsearch实例,它们会自动组成一个集群,无需其他操作,自动实现分布式集群。
Elasticsearch通过对JSON格式的文档进行索引,不仅支持并自动识别string、num、bool等常规字段,同时对于特殊字段如地理位置类型([lat,lon])和 ip(192.168.0.1)类型的字段提供特殊支持,只需在索引前手动指定相应字段为geo或者ip字段。在索引方面Elasticsearch提供了批量索引的工具,大大提高了索引及更新效率,在数据检索方面不仅可以提供全文索引,还提供类似关系型数据库的结构化检索(Structured Query DSL)。
Elasticsearch的分布式模式默认情况下分片数量设置为5,并配置有1份复制项,在组成集群的情况下,分片会按照一定的算法存储在集群的各台主机上,以确保其中一台主机意外下线不会影响整个集群的正常工作,如下图所示,由Dremqueen,Fin,Tarot为3个节点组成的Elasticsearch集群,以索引test100w为例,索引分成了5个分片,并且每个分片都有一个冗余分片。
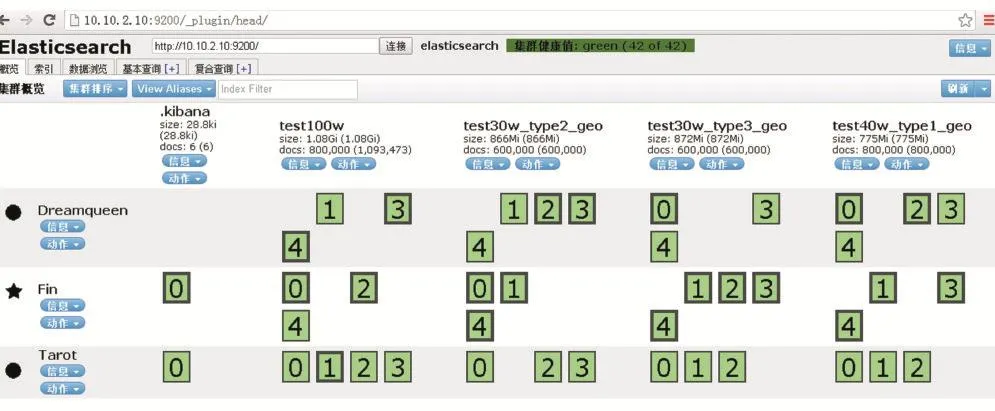
图1 Elasticsearch分片存储情况
2.2 Solr
Solr是一种开放源码的、基于Lucene Java的搜索引擎,易于嵌入到Web应用中。Solr提供了全文搜索、聚类搜索、高亮显示等功能,支持多种输出格式(XML/XSLT和JSON等格式),且自带一个基于HTTP的管理界面。
Solr需使用Tomcat运行,或使用内置的Jetty容器直接运行;使用Solr需新建core(类似实例),core内可直接插入文档,不同的core之间没有任何关系和影响;每个core有单独的存储路径、配置文件;文档有批量导入的和使用HTTP新增的方式,批量导入可直接用post请求将文件发送至Solr,建立索引,HTTP新增可设置若干个文档提交一次;索引文件与Lucene的相同,可使用Luke等工具打开和查看。Solr功能特点如下:
Solr索引的实现是用POST方法向Solr服务器发送一个描述Field及其内容的XML文档,Solr根据XML文档添加、删除、更新索引。因此Solr不支持对基本字段的自动识别,且嵌套结构的JSON文档无法直接在Solr中进行索引,需将JSON文档扁平化(成为只有1级的文档)后才能进行索引操作。Solr搜索只需要发送HTTPGET请求,然后对Solr返回XML、JSON等格式的查询结果进行解析,组织页面布局。Solr不提供构建UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
Solr自带的示例分布式启动命令为“solr start-e cloud-noprompt”,启动后会自动在本机创建2个shard的分布式架构Solr,管理界面如下图:
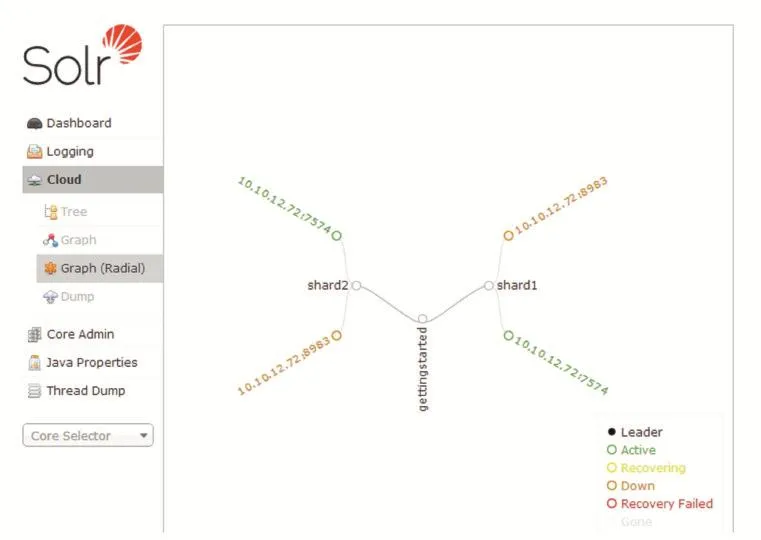
图2 Solr分布式集群管理界面
3 性能测试
3.1 环境及数据准备
用来进行测试的主机配置如下:
CPU:Intel Xeon E7-4807,1.87GHz
MEM:8GB
DISK:HDD 40GB
测试工具与数据如下:
LoadRunner,使用两台Windows7台式机作为运行Vuser虚拟用户的压力测试机;
共有100W条文档,其中包含3种格式,数量分别为40W、30W、30W。文档的数字、时间部分为随机生成,文本部分为从大量电子书中随机选取,标签部分为从数百个词语中随机选取;
例如,在教学《有理数》(北师大版数学七年级上册)这一课时,教师就可以制作一节相关的微课,详细讲解如何通过有理数去探究勾股定理,不仅让学生对有理数的各种知识有着充分的了解,还可以学习到未来需要学习的知识。通过这样的方式进行教学,可以使课堂教学内容有效扩展,为学生未来的学习打下坚实的基础,切实提升数学教学质量,提升学生的学习效率。
关键词词库,包含50W词语,其中中文词语约40W个、数字10W个、英文单词约1.5W个;
地理搜索条件、时间段范围、数值范围各30个,其中地理搜索包括20个圆形(按距离搜索)和10个多边形。
测试项如表1所示:

表1
3.2 性能对比
(1)索引建立和更新速度对比
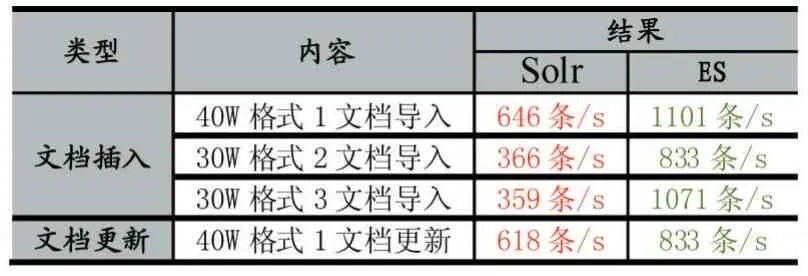
表2
由上表可以看出Elasticsearch的索引建立和更新速度要优于Solr。
(2)检索速度对比
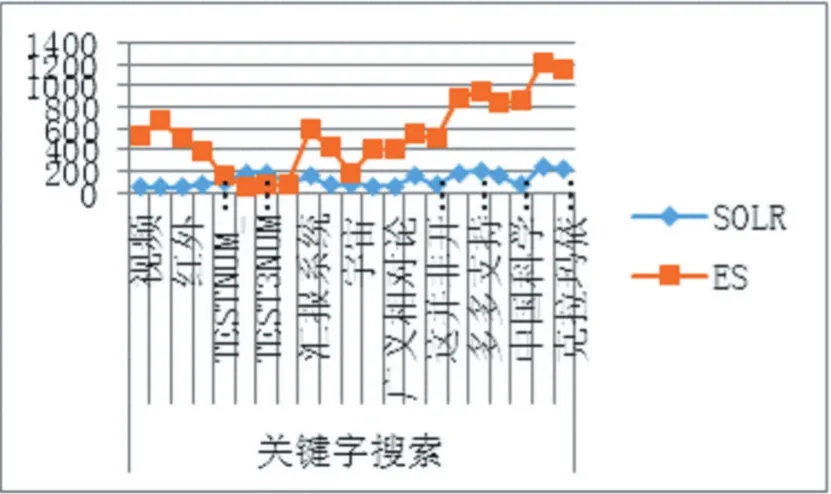
图3 关键字搜索响应速度对比
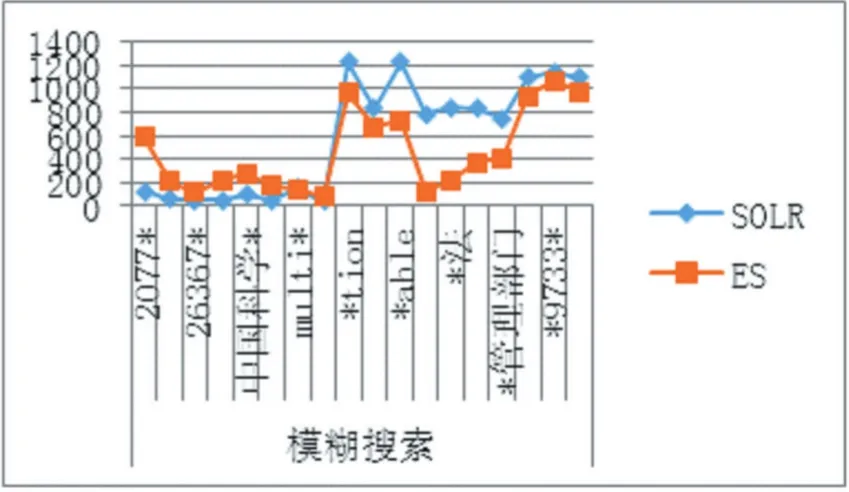
图4 模糊搜索响应速度对比
4 结语
本文通过简要介绍开源搜索引擎Elasticsearch和Solr,对二者所支持的索引和检索方法进行了阐述,并通过对其索引和检索性能进行多方面比较,为项目开发人员依据自身项目的需要选择合适的搜索引擎提供了依据。
参考文献:
[1]F.Ohhorst.Turning Big Data Into BigMoney.Big Data Analytics,,New Jersey,AB.D.,2013.
[2]S.Ramamorthy,S.Rajalakshmi.Optimize d Data Analysis in Cloud using BigData Analytics Techniques.4th ICCCNT Conferense,Tiruchengode,India,2013.
[3]https://www.elastic.co/guide/en/elasticsearch/reference/current/_basic_concepts.html
[4]http://lucene.apache.org/solr/guide/7_1/solr-tutorial.html.
猜你喜欢
词学(2022年1期)2022-10-27
计算机系统应用(2022年5期)2022-06-27
电子科技大学学报(2022年3期)2022-05-28
计算机与网络(2022年2期)2022-03-17
电脑爱好者(2021年23期)2021-12-08
疯狂英语·新阅版(2020年11期)2020-12-21
办公室业务(2019年13期)2019-08-01
火控雷达技术(2018年4期)2019-01-15
新世纪图书馆(2014年7期)2014-09-19
新世纪图书馆(2014年7期)2014-09-19
