
基于SVM的恶意PDF检测研究
2018-04-24 07:58:56李涛
现代计算机 2018年8期
李涛
(四川大学计算机学院,成都610065)
0 引言
近年来,PDF文档格式作为一种电子文件的格式,由于它的方便性、高效性、稳定性,已经在市场上广泛的应用。PDF文档的格式是标准化的,并且是公开的,这就有不同的厂商实现自己的PDF阅读器。但是它的广泛流行,在安全性上受到了极大的挑战。
PDF文档的攻击方法主要通过3种形式达到目标。第一种是通过PDF阅读器的API漏洞,通过API漏洞实现攻击,第二种是编写有害的JavaScript植入PDF文档中,达到攻击目的,第三种是通过PDF标准提供的间接引用、加密等形式来隐藏攻击向量。攻击者可以通过3种攻击形式的有效结合,更大程度的实现攻击成功率。目前研究PDF检测方面,重点是研究恶意文档中JavaScript的检测,其中大部分嵌入的Ja⁃vaScript代码在一定程度上进行了混淆编码,不但增加了分析的复杂度,同时杀毒软件很难检测出来。
本文通过N-gram算法提取PFD中JavaScript的特征,组成特征向量,通过机器学习算法的学习,最后得到PDF的静态检测模型。在其中引入反混淆的处理机制,从而能够建立更为完善的机器学习模型。
1 PDF文档检测模型
本文PDF文档检测模型是基于机器学习的模型静态检测模型,模型主要解决的问题是,PDF文档中Ja⁃vaScript的准确的提取,再利用N-gram算法提取恶意特征,最后使用机器学习算法建立模型。
故此,模型划分为3个模块,其一,提取PDF中Ja⁃vaScript代码;其二,分析JavaScript特征向量;其三,通过机器学习建立模型。

图1 PDF文档检测模型流程图
1.1 PDF 文档结构
一个基本的PDF文档都是由以下4部分组成:文件头(header),文件内容(body),交叉引用表(cross-ref⁃erence table)和文件尾(trailer)。文件内容是由一些对象(Objects)组成的,这些对象可以直接和间接引用,对象有8种不同的类型,如表1。
1.2 PDF文档中JavaScript代码及其提取
JavaScript一种直译式脚本语言,是一种动态类型、弱类型、基于原型的语言,内置支持类型。在PDF中也广泛应用。在JavaScript的帮助下,PDF提供了一些除展示图片和文字以外的其他功能。对PDF的文档批处理,还用出来PDF中的表格,以及控制多媒体事件等。

表1 PDF中的8种不同类型
在PDF文档中,JavaScript的代码数据可以通过直接引用,和间接引用两种方式去处理,一般在恶意PDF中,JavaScript都是通过间接引用,来简单的绕过检测工具的检测。通过使用开源的JavaScript提取工具,可以提取是直接显式的嵌入/JS中的,也可找出通过查询/JS关键字,找出应用的JavaScript代码。
1.3 PDF中JavaScript的特征分析
从PDF文档中提取JavaScript代码后,通过N-gram方法来处理,N-gram是基于马尔科夫链的文本处理方法,提取出恶意的JavaScript特征作为多维向量的数据,建立模型。为了增加提取特征的有效性,反混淆,提出如下措施:
(1)恶意PDF为了躲避杀毒软件对它的查杀,它会隐藏JavaScript代码,它不会直接使用/JavaScript和/JS这种对象,这些对象会暴露它们的JavaScript代码。取而代之的是如下对象名:

在特征对象中添加这类特征,可直接判断它为恶意代码。
(2)在恶意的JavaScript中会出现较多的特殊函数。eval()函数可计算某个字符串,并执行其中的JavaScript代码;escape()对字符串加密和 unescape()函数对字符串解密。
(3)在恶意 PDF 中出现 for,while,if,else等关键字的个数一般都是有一定规律的,把它们的个数加入到恶意PDF的特征向量中;在利用漏洞,使用堆喷射技术会需要大量的填充无意义的NOP语句,其中含有%u9090特征字符出现。
1.4 机器学习算法
本文使用的PDF文档静态检测模型是单一类别支持向量机(OCSVM),其优点是当分类问题中最典型的的二分类问题,遇到样本中有一种分类中的样本数量非常稀少,不能形成二分类的模型,就要考虑单一类别支持向量机。在恶意PDF文档的检测中,含有JavaS⁃cript的PDF文档要远远大于含有JavaScript的正常文档。所以只需要获取恶意PDF文档特征,建立单一类别支持向量机模型,进行PDF检测。
这种单一类别支持向量机模型对数据的分类方法过程为:通过学习大量的恶意PDF样本,建立模型M,对于需要检测的PDF样本,计算它提取出的特征向量和模型M中原点两者之间的欧氏距离,设置合适的R值,当此距离在R之内时,认为此PDF属于类别M中的,归类为恶意PDF文档,否则文档是非恶意的。
2 实验
对检测系统的评估使用的数据时来自恶意数据收集网站contagio,提供的数据其中包括10982个恶意PDF文档,和9000个正常的PDF文档。下载的文档通过抽样检测,通过virustotal网站的检测,得到数据的正确性,可对本文提出的检测系统进行检测。为了测试需要,把恶意样本分成训练集样本,和测试集样本两部分,其中训练集样本个数为10509个,测试集样本为473个,因为使用的模型是单一向量机,所以正常PDF文档就全部为测试集。
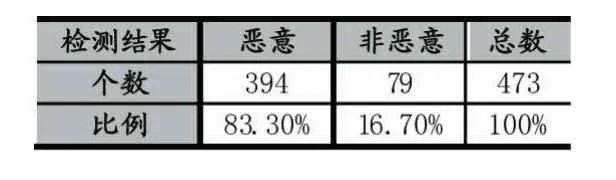
表2 本检测系统对473个恶意文档的检测结果
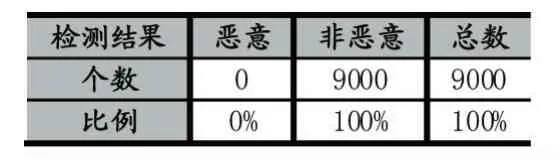
表3 本检测系统对9000个正常文档的检测结果
经过查看未检出的恶意PDF文档,可以看出大部分是不含JavaScript的文档,即便是包含JavaScript的文档,脚本本身也没有攻击性,这给我们以启示,在以后的工作,我们还要收集除JavaScript外的其他的特征。对于正常的PDF文档而言,由于收集到的文档中绝大多数都不含有JavaScript代码,含有JavaScript代码的正常PDF样本也多为表格,对PDF文档集合进行批处理,控制多媒体事件等,例如使用的是判断表格中填写的是否为日期是否为合适的数字等简单的Java-Script代码,所以被误报的可能就非常小。
在表4,使用了ClamAV与NOD32与本系统进行比较,ClamAV是用于检测木马,病毒,恶意软件和其他恶意威胁的一个开源杀毒引擎,NOD32是ESET公司旗下的一款防病毒软件。从对恶意PDF的检出率情况,可以看出本文系统检出率高于ClamAV和NOD32,说明了实验的有效性,实验结果达到了预期效果。
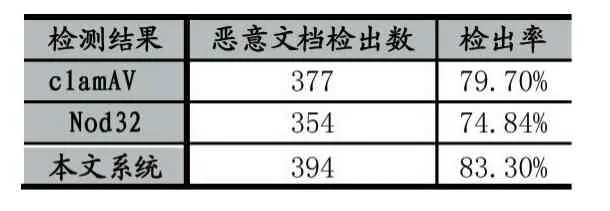
表4 和近年其他检测工具比较
3 结语
本文介绍了PDF中包含JavaScript的基本知识,通过提取PDF中JavaScript特征,形成特征向量,再通过基于的支持向量机的机器学习算法学习训练,提出了一种PDF的静态检测模型。在处理JavaScript时候,增加了反混淆的简单机制,使特征分析更为精确,并建立更为完善的机器学习模型。在接下来的研究中,重点放在静态与动态模型相结合的思路上,增加恶意PDF的检出率。
参考文献:
[1]孙本阳,王轶骏,薛质.一种改进的恶意PDF文档静态检测方案[J].计算机应用与软件,2016,33(3):308-313.
[2]周可政,施勇,薛质.基于恶意PDF文档的APT检测[J].信息安全与通信保密,2016(1):131-136.
[3]李玲晓,伍淳华.基于结构特征的恶意PDF文档检测[C].中国通信学会学术年会,2014.
[4]林杨东,杜学绘,孙奕.恶意PDF文档检测技术研究进展[J/OL].计算机应用研究,2018(08):1-7[2018-01-17].
[5]文伟平,王永剑,孟正.PDF文件漏洞检测[J].清华大学学报(自然科学版),2017(1):33-38.
[6]胡江,周安民.针对JavaScript攻击的恶意PDF文档检测技术研究[J].现代计算机,2016(1):36-40.
[7]Laskov P.Static Detection of Malicious JavaScript-bearing PDF Documents[C]Twenty-Seventh Computer Security Applications Conference,ACSAC 2011,Orlando,Fl,USA,5-9 December.DBLP,2011:373-382.
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
保定学院学报(2022年2期)2022-04-07 02:26:50
中国新闻周刊(2021年26期)2021-07-27 04:02:12
动漫星空(2018年11期)2018-10-26 02:24:02
动漫星空(2018年2期)2018-10-26 02:11:00
动漫星空(2018年9期)2018-10-26 01:16:48
动漫星空(2018年5期)2018-10-26 01:15:02
许昌学院学报(2018年4期)2018-05-02 12:27:37
中华建设(2017年1期)2017-06-07 02:56:14
信息安全研究(2016年4期)2016-12-01 06:06:54
