
深度学习在答案选择句意表示上的应用研究
2018-04-24 07:54张世西丁祝祥
现代计算机 2018年7期
张世西,丁祝祥
(四川大学计算机学院,成都610065)
0 引言
自动问答系统是自然语言处理领域(NLP)一个重要的研究课题,该课题可被形式化地表示为计算机和人通过人类的语言进行交互,并帮助用户完成简单的任务。该课题早在上世纪60年代就被提出,并在80年代因图灵实验[1]而风靡一时,但由于当时实验条件的限制,自动问答一直被限制在特殊领域的专家系统,发展缓慢。随着网络和信息技术的快速发展,用户期待系统可以更快更精准地定位意图,给出高质量的回答,促使自动问答系统再次成为NLP领域的一个研究热点。
近年来,随着大数据时代的到来以及GPU等高速计算设备的发展,深度学习在图像分类、语音识别等任务上取得了突出效果,其在自动学习抽象知识表达上的优异表现使得越来越多的研究人员将其应用在NLP领域的各项任务中,包括自动问答,机器翻译,文章摘要等。本文的研究主要基于自动问答系统中的答案选择子任务,重点集中在问答语句语义表示任务上,探究了主流的深度学习算法,包括卷积神经网络(CNN)、循环神经网络(RNN)等在答案选择中的应用,并通过实验证明结合了两者的混合深度神经网络在问答系统语义表示上取得的效果要好于单一网络。
1 问题描述
答案选择是自动问答系统中的一个关键步骤,该问题可描述为:给定问题q及其对应的候选答案集表示该问题对应的候选答案集的大小,任务目标是从候选答案集中选出最佳答案ak,若ak属于该问题的正确答案集合(一个问题的合理答案可以有多个),则认为该问题被正确回答,否则判定该问题没有被正确回答[2]。该问题的一种解决方案是获取问题和答案的语义表示,通过衡量语义表示的匹配度来选择最佳答案。本文采取上述方案,则所需考虑的两个问题是:一是如何实现问句及答案的语义表示。二是如何实现问题答案间的语义匹配。故而目标任务可分解为两个步骤:第一,利用深度学习算法,如RNN,CNN等将问题序列q以及候选答案集序列转化为向量,分别记为;第二,利用相似度衡量标准衡量中每个向量的相似度,相似度越高,则问题与答案越匹配,该答案排序越靠,反之,问题与答案匹配度越低,该答案排序越靠后。
2 算法描述
2.1 词向量
将深度学习应用于NLP领域的第一步是需要将词语转换为向量,并且向量之间的距离可以表示词语的语义相似度。传统的one-hot词向量不仅无法表示词语的语义相似度,而且会造成维度灾难。近几年,NLP领域多采用分布式稠密实数向量来表示词语的语义特征,如Word2Vec[3],GloVe[4].本文采用的是GloVe算预训练好的模型(Common Crawl,840B tokens),每个单词表示为一个300维的向量[5]。本文实验中直接将词向量初始化后的问题答案向量进行相似性度量,在实验数据集上有一定的效果,网络结构如图1所示。

图1 基于GloVe词向量嵌入的答案选择网络结构
2.2 循环神经网络(RNN)
RNN已被证明在NLP领域的很多任务中表现突出,是当下主流的深度学习模型之一[6]。在NLP领域,一个句子的单词之间是相互关联的,单词因上下文不同而具有不同的含义。然而,传统的神经网络通常假设所有的输入和输出是相互独立的,这对很多NLP领域任务来说是不合理的。RNN的提出正是为了利用句子的这种序列信息。RNN依赖之前的计算结果,并对序列的每个节点执行相同的操作,每个节点的输入除了当前的序列节点还包括之前的计算结果,相当于拥有一个“记忆单元”来记录之前的信息[7]。RNN算法可简单表示为,给定输入,其中xt表示t时刻的序列输入,用ht-1表示t-1时刻的计算结果,则t时刻的计算公式为,其中U,W为参数矩阵,在训练过程中学习;f为非线性激活函数,一般可以用tanh或者ReLU。上述简单RNN在训练过程中容易导致梯度爆炸或者梯度消失,因此研究者们在简单RNN的基础上进行改进,提出了很多变体,常用的包括长短时记忆网络(LSTM)[8]和门限循环单元网络(GRU)[9]。
LSTM针对RNN的处理节点进行了改进,引入了细胞状态值Ct和“门机制”,包括输入门ft,忘记门it以及输出门ot,其单元内部计算公式如下:

GRU在LSTM基础上做了一些简化,将忘记门和输入门合成了一个单一的更新门。同样还混合了细胞状态和隐藏状态,和其他一些改动,其单元内部计算公式如下:

上述式子中σ表示sigmoid激活函数,tanh表示tanh激活函数,*表示矩阵逐点相乘,W,U均为训练过程中学习的参数矩阵。
网络结构图如图2所示。
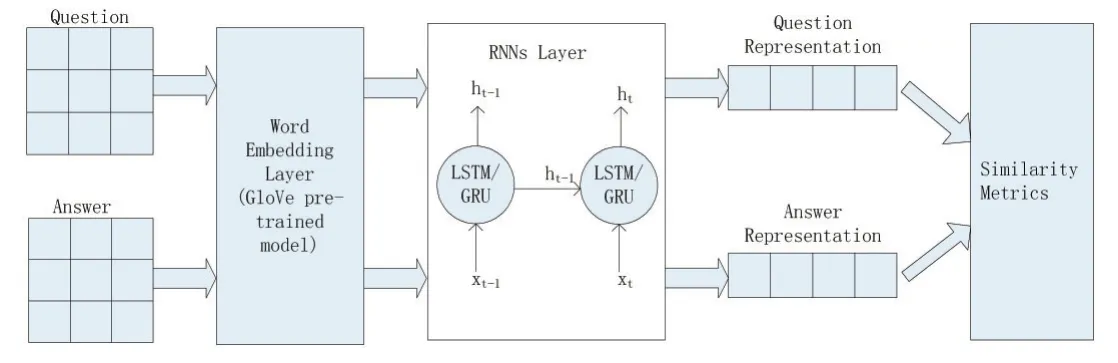
图2 基于RNNs(LSTM/GRU)的答案选择网络结构
2.3 卷积神经网络(CNN)
CNN最早被用在计算机视觉领域,提取图像特征。与传统神经网络相比,卷积神经网络(CNN)包含了一个由卷积层和子采样层构成的特征抽取器。在CNN的卷积层中,一个神经元只与部分邻层神经元连接,CNN的一个卷积层通常包含若干个特征平面,每个特征平面由一些矩形排列的神经元组成,同一特征平面的神经元共享权值,以减少网络各层之间的连接,同时又降低过拟合的风险。近年来,随着Word2Vec,GloVe等词向量技术的发展,很多NLP领域任务的输入也可以看作是词语序列与词向量构成的“像素矩阵”,因而很多研究人员也开始将CNN应用于NLP的任务中[10]。不同于图像处理的卷积,CNN对NLP的卷积核大小有要求,一般来说,卷积核的长度和词向量的维度应该是一致的。例如一个词向量是N维的,卷积核就为X*N维的,X一般可取1,2,3,表示提取1个词、2个词、3个词之间的特征。本文实验中,CNN卷积核数目为1000,CNN窗口大小分别取值为2,3,5,7,并将所得向量做一个拼接,最后经过一层max-pooling得到句子的最终表示,网络结构如图3所示。

图3 基于CNN的答案选择网络结构
2.4 混合神经网络(Con vLSTM)
RNN的模型设计可以很好地为序列建模,尤其是LSTM和GRU模型可以很好地保留远距离依赖的信息,但容易忽略局部的最近几个词之间的关系,同时,若序列过长,LSTM和GRU训练的时间代价将难以忍受。而CNN中的卷积核大小远小于输入大小,强调的是局部最近几个词之间的关系,同时其训练时间代价也小于LSTM。因而将两种模型结合起来使用,对解决NLP领域任务更有帮助。本文实验的模型结构如图4。
3 实验部分
3.1 实验数据
本实验基于开放数据集Ubuntu Dialog Corpus(UDC,Paper[11],GitHub[12]),该数据集是目前已公开的最大的对话数据集之一,它抽取互联网中继聊天Internet Relay Chat(IRC)中的 Ubuntu 聊天室记录,文献[11]中详细介绍了该数据集的产生过程。该数据集被划分为训练集,验证集以及测试集,训练集包含1000000个样例,验证集包含195600个样例,而测试集包含189200个样例。训练集的每一个样例包含一个问题,一个回答和一个标签,其中500000为正例(标签为1),500000为负例(标签为0)。正例表明该答案与问题匹配,负例表示不匹配,数据样例如图5。验证集和测试集的格式与训练集不同,验证集和测试集的每一个样例包括一个问题,1个正确答案(ground truth utterance)和9个干扰项,即错误答案(错误答案来自于验证和测试集中其他问题的答案),数据样例如图6。值得注意的是数据集的产生脚本中已经对数据做了一些预处理,包括分词、取词根、英文单词变形归类等。此外,例如人名、地名、组织名、URL链接、系统路径等专有名词也做了替代。表1给出了训练集问题答案长度统计信息。

图4 基于混合模型Conv-RNN的答案选择网络结构

图5 UDC训练集示例

图6 UDC验证集/测试集示例

表1 UDC训练数据集问题(context)和响应(utterance)长度统计
3.2 数据预处理
本文数据预处理主要包括两个部分,一是文本序列化以及序列填充;二是重构验证集和测试集,保证验证集和测试集数据格式与训练集相同,便于验证和测试。在第一步中,首先建立词表(将词语和某个整数一一对应),并将句子转换为整数序列;本文通过对训练集问题和回答的长度统计分析,综合考虑长度统计信息以及模型训练时长,最终选择最大序列长度为160,若句子序列长度大于160,则将超过的部分截断;若不足160,则在句子后面以0填充。在第二步中,本文扩充了验证集和测试集中的问题数目,使得每个正确的回答和干扰项都对应一个问题,并为正确回答打上标签1,干扰项打上标签0。
3.3 实验设置
本文实验中问题和回答的相似度计算公式为:

式(10)中,Vq表示经过深度神经网络学习后的上下文向量,Va表示经过深度神经网络学习后的响应向量,*表示逐点相乘,Vq*Va表示Vq和Va的相似度向量,经sigmoid函数转换成值为(0,1)的一个相似度概率,此概率越接近于1表明相似度越大,上下文于答案越匹配;越接近于0表明相似度越小,上下文与响应越不匹配。
本文实验中模型的目标函数选择的是对数损失函数(binary cross-entropy loss),计算公式如下:

其中y'表示预测标签,y表示真实标签,训练目的为最小化该损失函数。
模型其他参数设置如下:词向量维度为300维;LSTM隐藏层大小设置为300;CNN卷积核数目为1000,混合模型中CNN卷积核数目取500,CNN窗口大小取值为2,3,5,7;batch_size为256,模型优化器为Adam优化器[13]。
3.4 实验结果及分析
本文采用的评价标准为recall@k in n,其中n表示候选答案集的大小,k表示正确答案在top_k中,如re⁃call@2 in 10表示给定的候选答案集大小为10,从其中选择得分最高的前两个答案,正确答案出现在前两个答案中,则认为回答正确,计算回答正确的样例占数据集总样例的比例。
实验结果如表2所示,文献[11]中给出的基准实验结果如表3所示。通过实验表2和表3的对比发现,LSTM和GRU在答案选择任务上的表现突出,且效果不相上下,CNN在该任务上的表现不如前两者,而将LSTM与RNN组合使用的混合模型Conv-LSTM在该任务该数据集上的表现要好于单独使用LSTM或者CNN,由表2表3可以看出,Conv-LSTM比CNN在Re⁃call@1 in 10上提升了9.2%,比LSTM提升了2.3%,比文献[11]中提供的LSTM基准提升了3.2%。

表2 实验结果
4 结语
本文针对深度学习在问答系统中的句意表示子任务上进行了研究,通过实验对比发现LSTM和GRU等RNN模型相比于CNN在该任务上的表现更为突出,而将LSTM与CNN结合后的混合模型Conv-LSTM效果更好。目前针对问答系统依据答案来源分为两种解决方案,一种是如本文所述的检索式模型,即给定了答案集合,从中检索出正确的答案;另一种是生成式模型,即不依赖于预先定义的回答集,模型自动生成回答的句子,如深度学习中的sequence to sequence架构[14]便可用于这种生成式任务。另外,在检索式或生成式模型中引入注意力机制[15]也是最近的研究热点;本文所述研究集中在单轮对话任务上,而用户所期待的对话系统往往需要处理多轮对话任务,这可作为未来的一个研究方向。
参考文献:
[1]https://en.wikipedia.org/wiki/Turing_test.
[2]MinweiFeng,Bing Xiang,MichaelR.Glass,LidanWang,Bowen Zhou.Applying Deep Learning To Answer Selection:AStudy And An Open Task.arXiv:1508.01585v2[cs.CL]2Oct2015.
[3]Mikolov,Tomas,Chen,Kai,Corrado,Greg,Dean,Jeffrey.Efficient Estimation of Word Representations in Vector Space.arXiv:1301.3781v3.
[4]Jeffrey Pennington,Richard Socher,Christopher D.Manning.GloVe:Global Vectors forWord Representation.In EMNLP,2014
[5]https://nlp.stanford.edu/projects/glove/.
[6]https://karpathy.github.io/2015/05/21/rnn-effectiveness/
[7]L.R.Medskerand L.C.Jain.Recurrent neural networks.Design and Applications,2001.
[8]Alex Graves.Supervised Sequence Labelling with Recurrent Neural Networks.Textbook,Studies in Computational Intelligence,Springer,2012.
[9]K.Cho,B.V.Merrienboer,C.Gulcehre,D.Bahdanau,F.Bourgares,H.Schwenk,and Y.Bengio.2014.Learning Phrase Representations Using Rnn Encoder-Decoder for Statistical Machine Translation.In arXiv preprintarXiv:1406.1078.
[10]Yoon Kim.ConvolutionalNeuralNetworks for Sentence Classification.arXiv:1408.5882v2[cs.CL].
[11]Ryan Lowe*,Nissan Pow*,Iulian V.Serbany,Joelle Pineau*.The Ubuntu Dialogue Corpus:A Large Dataset for Research in Unstructured Multi-Turn Dialogue Systems.arXiv:1506.08909v3[cs.CL]4 Feb 2016.
[12]https://github.com/rkadlec/ubuntu-ranking-dataset-creator
[13]KINGMAD,BA J.Adam:AMethod for Stochastic Optimization[J].arXiv preprintarXiv:1412.6980,2014.
[14]Ilya Sutskever,Oriol Vinyals,Quoc V.Le.Sequence to Sequence Learning with Neural Networks.arXiv:1409.3215v3.
[15]C.Santos,M.Tan,B.Xiang,and B.Zhou.2016.Attentive Pooling Networks.In arXiv:1602.03609.
猜你喜欢
现代电力(2022年2期)2022-05-23
新高考·高一数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电子制作(2019年19期)2019-11-23
电子制作(2019年11期)2019-07-04
电子制作(2019年24期)2019-02-23
北京航空航天大学学报(2018年1期)2018-04-20
北京航空航天大学学报(2017年12期)2017-04-23
