
基于变异点的选择性变异测试
2018-04-24 07:54刘海陆
现代计算机 2018年7期
刘海陆
(四川大学计算机学院,成都610065)
0 引言
随着计算机与互联网的快速发展,各类软件广泛应用于社会生活的各个领域,其重要性不言而喻。作为保证软件质量的重要手段,软件测试受到了学术界和产业界的高度重视。变异测试是一种基于错误的软件测试方法,自20世纪70年代产生以来,经过近50年的发展,变异测试技术日趋成熟,大量实证研究表明[1-4],相对于路径分析、数据流分析和域分析等测试方法,变异测试能够更为有效地检测软件故障。
变异测试通过向待测程序注入微小的语法错误,得到大量被称为变异体的错误程序,从原程序生成变异体的转换规则被称为变异算子,变异算子主要通过替换、删除和插入三种方式更改程序中的变量或表达式,从而生成变异体,而变异发生的位置被称为变异点。变异测试以测试集甄别原程序与变异体的能力来衡量测试集的有效性,如果一个变异体被测试集甄别出来,则称该变异体被测试集“杀死”,否则称该变异体“存活”。由于变异体数量巨大,在降低测试效率的同时,带来了高昂的测试成本,严重影响了变异测试的广泛应用。大量研究表明,在所有变异体中,存在大量冗余变异体,这些冗余变异体并不能为提高测试集质量做出任何贡献。本文通过分析变异体之间的冗余关系,发现绝大部分非冗余变异体出现在条件和循环等控制语句,因此提出一种基于变异点的选择性变异测试方法,仅对控制语句进行变异,在降低较少测试有效性的前提下,大幅减少测试成本。另外,在现有研究中,多使用变异得分来衡量不同测试方法的有效性,没有考虑冗余变异体和冗余测试用例对变异得分的影响,使变异得分无法准确衡量不同测试方法的有效性,本文提出一种仅考虑非冗余变异体的评估指标MMS(Modified Mutation Score),能够更为有效地评估变异测试的有效性。
1 相关工作
本文提出的方法属于变异体约减技术,现有变异体约减技术主要可分为四类,第一类为变异体采样技术,在生成的全部变异体中,按照一定比例随机选取变异体进行测试,该方法首先由Acree[2]和Budd[3]提出,在Wong和Mathur[5-6]的研究中,选取10%的变异体仅降低16%的测试有效性,DeMillo[7]、King和 Offutt[8]等人的研究也取得了相似的结果;第二类为变异体聚类技术,根据变异体在测试集上的表现对变异体进行聚类,从每一类中选择出典型的变异体进行测试,Hussain[9]采用K-means和层次聚类算法在不降低测试有效性的情况下,较变异体采样技术选出的变异体数量更少;第三类为选择性变异技术,通过对变异算子的约减来减少生成变异体的数量,Mathur[10]首先提出可将变异测试工具Mothra中的ASR和SCR算子省略,Offutt[11]等人进一步将其发展为2-selective、4-selective和6-selective变异测试,其中6-selective变异测试能够在平均保证88.71%测试有效性的情况下,约减60%的变异体;第四类为高阶变异测试技术,首先由Jia和Harman[12]提出,通过将多个一阶变异体组合成一个高阶变异体的方式,在减少变异体的数量的同时,能够更好地模拟实际软件开发过程中的真实错误。
变异体采样技术由于采取随机选择的方法,一方面在较大程度上降低了测试有效性,另一方面在保持同等测试有效性的前提下,不同程序的所使用采样率不尽相同,导致该方法的稳定性较低;变异体聚类技术和高阶变异测试技术均依赖于变异体在测试集上的表现,对初始测试集的依赖度较高;现有选择性变异技术研究中,均以变异算子作为研究对象,而变异点对于一个变异体而言,其重要性并不亚于变异算子,因此本文以变异点作为研究对象,提出一种新的选择性变异方法。
2 变异点选择
变异测试一方面测试有效性较高,另一方面,其测试成本又极其昂贵,其主要矛盾在于生成的大量变异体中,存在一些不必要的变异体,即等价变异体和冗余变异体,下面给它们的定义:
冗余变异体:对于一个变异体m,如果存在另一个变异体m',使得在测试集T上,如果m'被杀死,则m必然被杀死,就称m为m'的一个关于测试集T的冗余变异体。
等价变异体:如果一个变异体与原程序虽然在语法上不同,但在语义上相同,则称该变异体为原程序的等价变异体,等价变异体无法被任何测试集杀死。
本文从以往研究的基准程序中,选择了9个程序作为研究对象,之所以选择这些程序,一是由于它们都具有明确且容易理解的功能,人工识别等价变异体的准确率更高;二是由于它们涵盖了Java程序中分支、循环和迭代等主要的控制结构,同时在数据结构方面,涵盖了数组等相对复杂的数据结构;三是本文主要针对方法级的变异测试,因此未选择更大规模的程序,在减少实验工作量的同时,保证了实验结果的准确性。
本文使用变异测试工具MuJava进行变异测试,获得了完备的测试集,根据测试结果对变异体进行了分类,分类结果如表1所示。由表中可以看出,在生成的2217个变异体中,等价变异体平均占8.80%,冗余变异体平均占88.14%,而能够提升测试集质量的非冗余变异体平均只占3.07%。
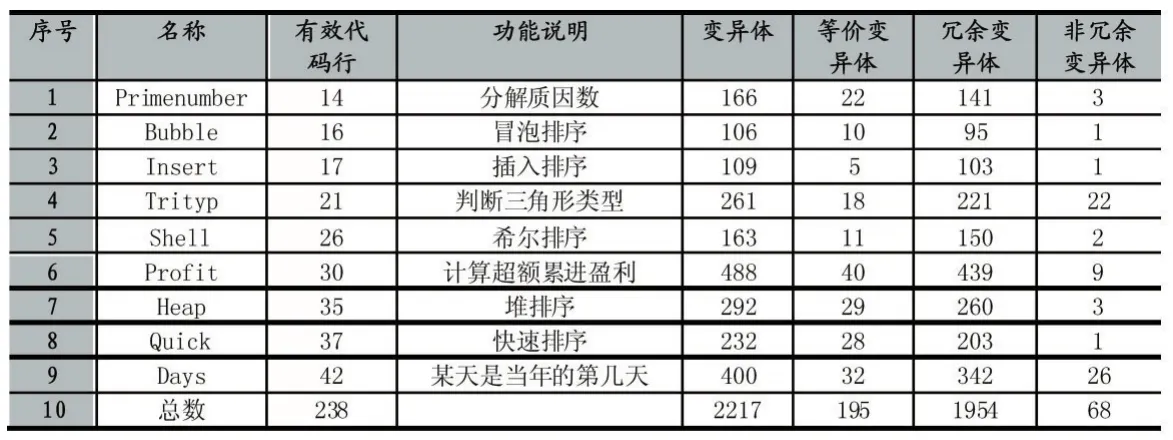
表1 分类结果
为进一步分析非冗余变异体与变异点的关系,对非冗余变异体的变异点根据语句类型进行统计,统计结果如表2所示。从统计结果可以看出,非冗余变异体多出现在条件语句和循环语句,而在Profit和Days两个程序中,虽然部分非冗余变异体出现在赋值语句中,但仍然与条件语句具有很强的联系,在Profit程序中非冗余变异体均出现在同一If语句的不同分支中,在Days程序中非冗余变异体所在语句均在SwitchCase语句中。因此,本文仅选取条件语句和循环语句进行变异。
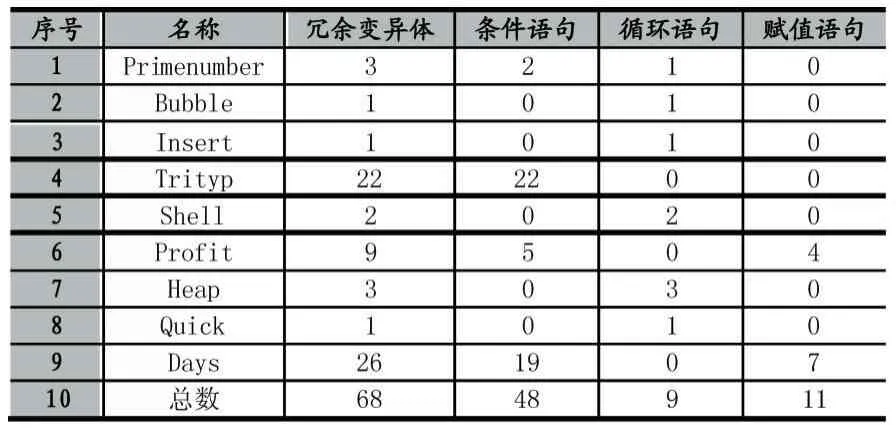
表2 非冗余变异体变异点
3 测试有效性评估
变异测试使用变异得分衡量测试用例集的有效性,其计算公式为Ms=Mk/(Mt-Me),其中Mk表示被测试集杀死的变异体数量,Mt表示全部变异体的数量,Me表示等价变异体的数量。
直观上,在给定变异体集合M的情况下,对于不同的测试用例集,其变异得分越高,说明其杀死变异体的能力越强,有效性越高。但由于冗余变异体的存在,使变异得分不能够准确的描述测试集的质量。例如假设M中共有10个变异体其中mi(i=1,2,3,4,5)不为冗余变异体,mi(i=6,7,8,9,10)为m5的冗余变异体,T1和T2为两个测试集,使用K(T,M)表示M中能够被测试集T 杀死的变异体集合,其中 K(T1,M)={mi|i=1,2,3,4},MS(T1,M)=0.4,K(T2,M)={mi|i=5,6,7,8,9,10},MS(T2,M)=0.6。显然T1可以侦测以m1、m2、m3和m4代表的四类错误,而T2只能侦测以m5代表的一类错误,T1的测试有效性明显高于T2,但由于冗余变异体的存在,变异得分给出的结果却恰恰相反。
在给定参考测试集的情况下,对于不同的变异体集合,其变异得分越高,说明其越容易被测试集杀死,所包含的变异体表示的错误种类越少,质量越低,但同样由于冗余变异体的存在,变异得分同样无法准确描述变异体集合的质量。例如将上例中的M拆分成M1和M2两个集合,其中M1={m1,m2,m3},M2={mi|i!=3},给定参考测试集 T,K(T,M)={mi|i!=2},则 Ms(T,M1)=0.67,Ms(T,M2)=0.78。M1代表了 m1、m2和m3三类错误,而M2代表了m1、m2、m4和m5四种错误,因此M2的质量高于M1,但由于冗余变异体的存在,变异得分同样给出了相反的结果。
为准确检验本文方法的测试有效性,消除冗余变异体对结果的影响,定义 MMS(Modified Mutation Score)用于衡量变异体集合的测试有效性。对于变异体集合M1、M2和参考测试集T,首先排除M1和M2中的冗余变异体,得到M1’和M2’,同时分别去除T中关于M1和M2的冗余测试用例,得到T1和T2,计算MS(T1,M1’∪M2‘)和 MS(T2,M1’∪M2‘),记为 MMS(T,M1)和 MMS(T,M2)。
如图1所示,其中m1至m5表示变异体,每个椭圆形表示能够杀死该变异体的测试用例集合,每个小三角形表示一个测试用例。设变异体集合M1={m1,m2},M2={m2,m3,m4},参考测试集 T={t1,t2,t3,t4,t5},则 M1’={m1,m2},M2’={m3,m4},T1={t2},T2={t5},MMS(T,M1)=0.5,MMS(T,M2)=0.75,说明 M2 的测试有效性高于M1,其物理意义为根据M2生成的最小测试用例集在全部变异体上的变异得分为0.75,而M1仅为 0.5。而 MS(T,M1)=MS(T,M2)=1,无法体现 M1与M2在测试有效性方面的差异。
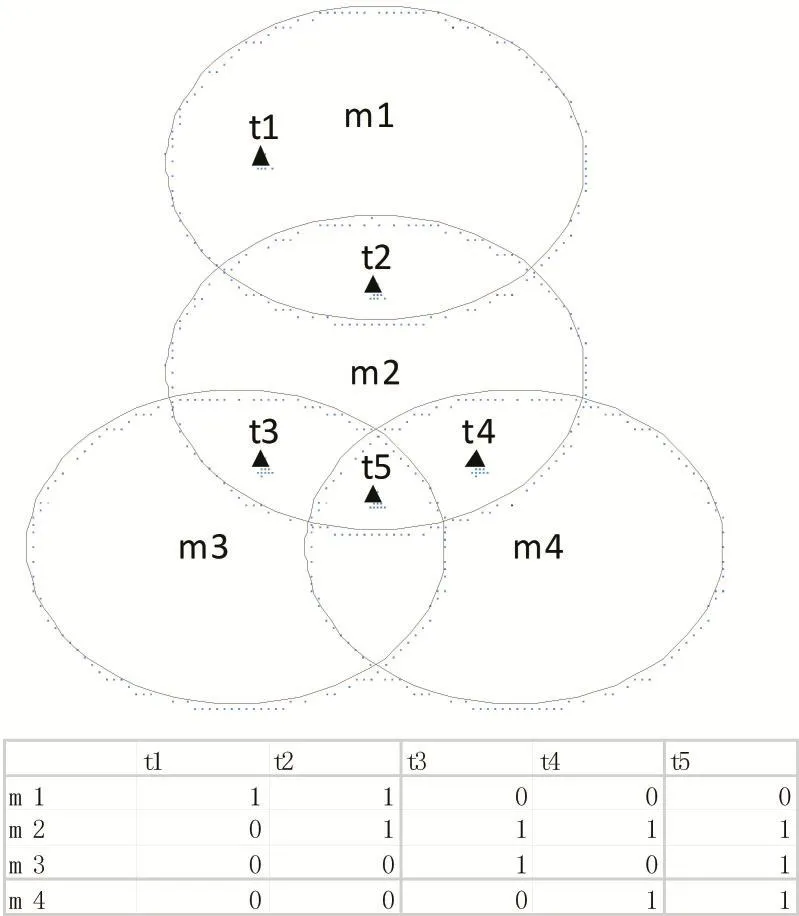
图1 MMS计算示例
4 实验结果
表3给出了本文提出的选择性变异方法的实验结果,采用本文提出的选择性变异方法,能够约减45.02%的冗余变异体,由于使用的是完备测试集,因此约减前和约减后的变异得分Ms均为1,使用本文提出的MMS衡量测试有效性,约减后的测试有效性降低了7.93%。由于Profit和Days两个程序中不存在循环语句,而本文提出的方法仅对条件和循环语句进行变异,因此这两个程序的测试有效性下降最为明显,这也是本文提出方法的有效性威胁之一。

表3 实验结果
5 结论及未来工作
实验结果表明本文提出的基于变异点的选择性变异测试方法,能够在降低较少测试有效性的情况下,大幅降低变异测试的成本。但一方面由于在实际软件测试过程中,存在大量不包含或包含极少条件和循环语句的程序,限制了本文方法的实用性;另一方面,在实验过程中观察到,即使仅对条件和循环语句进行变异,同样会生成大量的冗余变异体,不同类型语句的非冗余变异体与变异算子的类型存在紧密的联系,如对条件语句进行ROR(关系运算符替换)和COR(条件运算符替换)变异,生成非冗余变异体的可能性较高,而对表达式语句进行AORB(二元运算符替换)变异,生成非冗余变异体的可能性较高。因此,将沿着两个研究方向开展后续研究,一是利用程序依赖图等图形化方式表示待测程序,将程序中的每条语句表示成图中的一个节点,利用PageRank[13]和HITS[14]等算法计算各节点的重要程度,仅对重要程度较高的节点进行变异;二是借鉴现有的选择性变异测试方法,进一步研究不同语句和不同变异算子的对应关系,对于不同类型的重要节点选择与其相适应的变异算子。
参考文献:
[1]WongW E,Mathur A P.Fault Detection Effectiveness of Mutation and Data Flow Testing[J].Software Quality Journal,1995,4(1):69.
[2]Acree A T.On Mutation[M].Georgia Institute of Technology,1980.
[3]Budd TA.Mutation Analysis of Program Test Data[M].Yale University,1980.
[4]Walsh PJ.AMeasure of Test Case Completeness(Software,Engineering)[J],1985.
[5]Mathur AP,WongW E.An Empirical Comparison of Mutation and Data Flow Based Test Adequacy Criteria[J],1993,4(1):9–31.
[6]W.E.Wong,On Mutation and Data Flow[D],Purdue University,West Lafayette,Indiana,1993.
[7]Demillo R A,GuindiDS,MccrackenW M,etal.An Extended Overview of the Mothra Software Testing Environment[C].Software Testing,Verification,and Analysis,1988.Proceedings of the Second Workshop on.IEEE,1988:142-151.
[8]King KN,OffuttA J.A Fortran Language System for Mutation-Based Software Testing[J].Software Practice&Experience,2010,21(7):685-718.
[9]S.Hussain,Mutation Clustering[D],King's College London,UK,2008.
[10]Mathur A P.Performance,Effectiveness,and Reliability Issues in Software Testing[C].Computer Software and Applications Conference,1991.COMPSAC'91.Proceedings of the Fifteenth International.IEEE,1991:604-605.
[11]OffuttA J,RothermelG,ZapfC.An Experimental Evaluation of Selective Mutation[C].International Conference on Software Engineering,1993.Proceedings.IEEE,1993:100-107.
[12]Jia Y,Harman M.Constructing Subtle Faults Using Higher Order Mutation Testing[C].Eighth IEEE International Working Conference on Source Code Analysis and Manipulation.IEEE,2008:249-258.
[13]PAGE,L.The PageRank Citation Ranking:Bringing Order to the Web[J].Stanford Digital Libraries Working Paper,1998,9(1):1-14.
[14]Gibson D,Kleinberg J,Raghavan P.Inferring Web Communities from Link Topology[C].ACM Conference on Hypertext and Hypermedia:Links,Objects,Time and Space-Structure in Hypermedia Systems.ACM,1998:225-234.
猜你喜欢
计算机系统应用(2022年2期)2022-05-10
云南大学学报(自然科学版)(2022年1期)2022-02-21
汽车工程师(2021年11期)2021-12-21
电子技术与软件工程(2021年18期)2021-11-21
建材发展导向(2021年6期)2021-06-09
校园英语·上旬(2020年1期)2020-05-09
电子制作(2019年16期)2019-09-27
电子制作(2019年15期)2019-08-27
卷宗(2017年16期)2017-08-30
计算机工程与设计(2014年4期)2014-02-09
