
融合CNN和结构相似度计算的排比句识别及应用
2018-04-16 08:40:22穆婉青王素格
中文信息学报 2018年2期
穆婉青,廖 健,王素格,2
(1.山西大学 计算机与信息技术学院,山西 太原 030006;2.山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原 030006)
0 引言
修辞格[1]是通过修饰、调整语句,运用特定的表达形式以提高语言表达作用的方式和方法。在文学类文本中恰当地使用修辞,可使语言表达更加准确、生动,富有感染力。在众多修辞格中,排比作为一种使用频率较高的修辞格,受到了语言学家的广泛关注。典型的排比句[2-3]一般由三至五项组成,排比项[4]之间内容相关[5]、结构相似,词汇之间相互呼应,增强了文章的语篇连贯性,使行文丰满有力[6],广泛地应用在政论、艺术[7]等语体中,在近十年的高考语文鉴赏题中也多有考察,以2016年北京市高考语文卷第24题为例:
问题:文章第四段运用了多种手法,表达了作者对老腔的感受。请结合具体语句加以赏析。
部分参考答案:排比。“这是……”、“抑或是……”、“也像是……”等句子使用了排比的手法,多角度表现老腔不同的腔调,充分表现老腔艺术魅力和我对老腔的沉迷。
若能自动识别文学类文本中的排比句,不仅可求解阅读理解部分的鉴赏类问题,还可以进一步挖掘文本中的隐式情感,为计算机对文本的思想感情、语言风格等方面的自动赏析奠定基础。
排比句具有特征突出、节奏感强[5]、增强文章的表达效果的作用,引起不少语言学家的关注。高婉瑜[8]对对偶和排比两种辞格进行了详细的对比分析,认为二者仅在语法结构和语义上具有相似点,而在平仄相对、字面重复度等特征上不具有一致性。叶定国等人[9]对中文的对偶、排比辞格与英语的Antithesis、Parallelism辞格进行了分析对比,发现中文和英文的辞格并非完全对应,Antithesis和Parallelism有包孕关系,而对偶和排比却相互独立,具有不同的语用功能。吕敬华[10]以《大堰河——我的保姆》为例,分析了排比在其中的艺术特色,认为使用排比使文章更有缠绵的韵味。何佳利[11]以《蜗居》的经典台词为例,研究了排比句在影视作品中的作用,认为使用排比增强了语言气势,更好地表达了人物的思想感情。皮晨曦[7]研究了排比辞格在政论和艺术两种语体中的差异,认为排比在政论语体中常用来举例说明,而在艺术语体中常用来抒发情感。张璐璐[12]分析了排比句在微博中的使用情况,认为使用排比使语言的表达更有感染力,并根据排比项的不同,将排比分为成分排比、分句排比、单句排比。张晓[13]从结构、词语重复度、排比项的数量出发对排比进行了再分类。上述文献仅仅从语言学层面对排比句进行了研究分析,而在自动识别方面的研究较少。梁社会等人[14]对《孟子》《论语》中的排比句进行分析,联系排比句的结构、词语重复等特点设计了相应的排比句自动识别算法。该算法填补了对古汉语排比句自动识别的空白,但由于其只考虑了排比句结构类似和词语重复的表层特点,忽略了语义信息,且对语料本身有较高的依赖性,无法应用到现代汉语的语料中。
近年来,文本表示和句子分类方面的研究工作一直开展得如火如荼。相比之前经典的布尔模型和向量空间模型等文本表示模型,Word2Vec[15-17]可以利用上下文语义信息对词语进行分布式表示,基本思想是通过Skip-gram和Continuous Bag of Words(CBOW)模型将每个词映射成n维特征向量,通过词向量之间的距离获取词语之间的语义相似度,将其应用到文本的聚类、分类等自然语言处理领域的研究工作中。卷积神经网络[18-19](convolutional neural network,CNN)是一种前馈神经网络,由输入层、卷积层、池化层、全连接层、输出层组成,由于其良好的自学习能力和泛化能力,在短文本的表示和句子分类上也取得了一系列进展。Kim等人[20]在预训练好的词向量的基础上,构造了一个双通道的CNN模型解决句子级别的分类问题,并取得了较好的效果。Kalchbrenner等人[21]提出了一种使用动态pooling方法的dynamic convolutional neural network(DCNN)模型对句子语义进行建模,该模型在一定程度上保留了词序信息。Hu等人[22]也在CNN的基础上提出了一种解决句子建模的网络结构,主要用于解决句子匹配的问题。
本文依据排比句的定义[2-5],概括了排比句的三个特点:(1)至少由三条相互衔接的排比项组成;(2)各排比项之间具有语义相关性;(3)各排比项之间具有结构相似性。例如,下面的两个排比句:
例1:烛光柔,月光静,电光更静,正如做事迅速的人,来去无声。
例2:一粒种子,可以无声无息地在泥土里腐烂掉,也可以长成参天的大树;一块铀块,可以平庸无奇地在石头里沉睡下去,也可以产生惊天动地的力量;一个人,可以碌碌无为地在世上厮混日子,也可以让生命发出耀眼的光芒。
为了识别具有上述三个特点的排比句,本文结合文本的内容和结构,设计了基于CNN和结构相似度计算融合的排比识别方法,该方法不仅可以用于识别排比修辞,还可以为其他修辞格的自动识别、衡量文本的相似度、解答鉴赏类等问题提供参考。
1 排比句自动识别方法
对于排比句的自动识别,首先对一个句子进行结构化表示,然后对其是否为排比句进行判断。根据排比句中的排比项具有内容相关、结构相似的特点,本文以文本的词性、词语作为基本特征,同时考虑文本内部的语义相关性和结构相似性,设计了基于CNN和结构相似度计算的排比句融合识别方法。设P1、P2分别为利用CNN模型和结构相似度计算得到的该句子为排比句的概率,PY是由P1和P2共同作用决定的排比句的最终概率,模型的框架如图1所示。

图1 融合CNN和结构相似度计算的排比句识别框架图
图1中对文本进行分词等预处理操作后,以词语、词性为特征对文本内容进行分布式[23-25]表示,在此基础上,利用CNN对文本进行分类求得P1,利用LCS算法计算结构相似度求得P2,最终对P1、P2进行加权求和得到PY。基于CNN排比句识别和基于结构相似度计算排比句识别的详细介绍见第1.1节和1.2节。
1.1 基于CNN的排比句识别
(1) 融合词语信息和词性信息的句子表示
由于文档中的句子是非结构化数据,需要将其转换成计算机可识别的结构化数据。Word2Vec是利用词语的上下文信息映射到K维向量空间上的一种方法,它可使词语的语义表示信息更加丰富。本文利用Word2Vec对大规模的数据进行训练获得词的分布式表示,在此基础上,加入句子的词性信息对句子进行表示。
设一个句子S=(word1,word2,…,wordn),由n个词构成,其中第i个词wordi的词性为posi。利用Word2Vec模型对大规模的散文数据进行训练后,wordi可以生成kw维的向量xwi。考虑到排比句具有结构相似的特点,本文视词性信息为浅层结构信息的刻画,将词语信息与词性信息共同作用对句子进行表示。假设现有的词类集为C,对|C|中每一个词类posi(i=1,2,…,|C|)进行编码,随机产生互不相同的维度为kp的向量xpi。对于每个词语与词性对
(1)
这里Xi为句子S中
设句子S表示的向量矩阵为Senkn,融合语义信息和词序信息的句子S可由n个Xi(i=1,2,…,n)进行拼接,其表示形式见式(2)。
(2)
(2) 基于多个卷积核的CNN的排比句识别
CNN是一种前馈式神经网络,它利用反向传播算法对网络结构进行优化,对网络中的未知参数进行估计,常用于处理图像和时间序列等二维网格结构数据,容错能力强,运行速度快,具有较强的自适应能力,近期在句子表示和句子分类方面也获得不错的结果。本文利用大小不同的卷积窗口进行卷积操作,对获取的特征集合利用最大池化方法进行池化,为了防止训练样本过少造成的过拟合问题,在全连接层部分使用了Dropout技术,即以一定的概率暂时丢弃网络中的部分参数,将池化后获得的向量经过全连接层后,连接到Softmax层,最终获得该句子为排比句的概率。
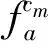
基于CNN排比句识别算法:
输入:句子S的表示Senkn;

Step2利用t(1≤t≤n)个卷积核分别对Senkn进行卷积操作,可获得t个特征集合Fc1,Fc2,…,Fct。
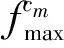
Step5将FW最终连接到Softmax分类器,输出S为排比句的概率P1;
Step6当P1>Φ1时,则句子S为排比句。
1.2 基于结构相似度计算的排比句识别
最长公共子序列(longest common subsequence,LCS)[26]算法可计算出两个或多个序列中最长的公共子序列,该子序列中的元素在原序列中不一定是连续的,但是前后顺序不发生改变,广泛地用于计算图形、文字之间的相似度。本文依据LCS算法的特性,在句子词性串的基础上,利用该算法对句子的结构相似度进行度量。
由于排比句各排比项之间具有结构相似性的特点,本文以逗号和分号作为分隔符对句子进行分句,以连续的三个分句为一个分句单元,对各分句分词后生成词性串。在此基础上,利用LCS算法计算出两两分句之间的最长公共子序列;再利用相似度计算公式计算分句单元内的两两分句间结构相似度,并对其求平均值。最终将所有分句单元中句子间相似度平均值最高的认为是排比句。
设一个句子S=(s1,s2,…,st)由t(t>2)个分句组成,第i(i∈{1,…,t})个分句si的词性串序列为pi,len(pi)为pi的词性串长度,分句si和分句sj(j∈{1,…,t})的公共词性串为pij、结构相似度值为ssij,sim(si,sj)为相似度函数。假设连续的三个分句为一个分句单元,则第k(k∈{1,…,t-2})个分句单元SCK内为ak,所有分句单元中句子间相似度平均值最大为amax、SCK={sk,sk+1,sk+2}。
基于结构相似度计算的排比句识别算法(SSC):
输入:句子S中的分句单元SC1,SC2,…,SCt-2;
Step1对每一个单元SCK,执行Step1.1-Step1.3
Step1.1计算两分句si、sj之间共同的词性串pij=h(si,sj)=lcs(pi,pj);
Step1.2计算分句si、sj结构相似度值[26]
ssij=sim(si,sj)=(2×len(pij))/(len(pi)+len(pj));


Step3当amax>Φ2时,则句子S为排比句。
1.3 基于CNN和结构相似度计算的融合
排比句具有语义相关性、结构相似性的特点。由于CNN考虑了文本的语义信息,而SSC算法考虑了文本的结构信息,因此,将两者的结果进行融合,用于判别一个句子是否为排比句。为了融合结构信息,将第1.2节中获得的分句单元中最大平均相似度值amax视作该句子为排比句的概率P2=amax。设α为权重,利用1.1节求得的概率P1,判断句子S是否为排比句的最终概率为PY=αP1+(1-α)P2,这里的α是依据排比句的标签信息确定的最优值,当PY>Φ3时,则句子S为排比句。
2 实验及分析
2.1 数据集及评价指标
实验数据来源于高中语文课文、全国历年语文高考题的散文文本、查字典网(https://www.chazidian.com/)和散文吧网站(https://www.sanwen8.cn/),经过人工标注的排比句2 000条,非排比句2 000条,共计4 000条,其中非排比句来源于排比句的上下文。为了训练Word2Vec模型,采用1946—2006年近3.5GB的《人民日报》语料、散文吧网站上获取的散文71 460篇、全国历年语文高考题的散文文本184篇。所有的实验数据均经过去噪、去重、分词等预处理操作。
实验结果采用的评价指标为精确率(precision)、召回率(recall)、F1值和正确率(accuracy)。
2.2 参数设置
使用第1.1节CNN模型对排比句识别时,训练过程中参数的更新采用随机梯度下降方法。通过多次实验,选取性能最优参数如下:kw=200,kp=200,t=3,C1、C2、C3的卷积窗口大小分别为300×3、300×4、300×5,学习率为0.01,dropout的概率为0.5,Φ1=0.5,Φ2=0.65,Φ3=0.6,α=0.3。
实验结果均采用五折交叉验证,即每次取全部数据的80%为训练集,其余20%为测试集,各评价指标均重复五次实验取平均值。
2.3 实验结果及分析
实验1不同权重α下融合CNN和SSC的排比句识别结果
为了分析权重α对第1.3节提出的融合CNN和SSC方法判别排比句的影响,本实验选取α∈{0.1,0.2,…,0.8,0.9},进行了九组对比实验,实验结果如图2所示,其中,横坐标为权重α的取值,纵坐标为实验结果。
由图2可看出:随着α的变化,各评价指标均有所波动,说明内容和结构对于排比句识别均有一定的影响。当α值为0.3时,F1值和accuracy取得了最优结果,说明结构相似度(SSC方法)在排比句识别中起着重要的作用。在后续实验中均选取α=0.3。
实验2不同特征、分类方法进行排比句识别比较
为了验证本文提出方法的有效性,我们设置了如下对比实验:
SVM[w]:以wordi为特征的基于SVM分类器的排比句识别;
SVM[pos]:以posi为特征的基于SVM分类器的排比句识别;
SVM[w+pos]:以wordi和posi为特征的基于SVM分类器的排比句识别;
CNN[w]:仅以wordi为输入特征,利用1.1节提出的基于CNN的排比句识别方法;
CNN[pos]:仅以posi为输入特征,利用1.1节提出的基于CNN的排比句识别方法;
CNN[w+pos]:利用1.1节提出的基于CNN的排比句识别方法;
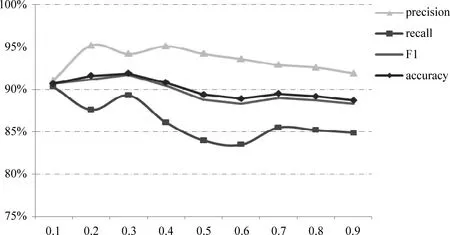
图2 不同权重α下融合CNN和SSC的排比句识别结果
SSC[w]:利用1.2节基于SSC的排比句识别方法,仅以wordi为输入特征,且令sim(si,sj)为cosine相似度simcos(si,sj),计算内容相似度;
SSC [pos]:利用1.2节基于结构相似度计算的排比句识别方法;
SSC [w+pos]:利用1.2节基于结构相似度计算的排比句识别方法,以wordi和posi为输入特征,且令sim(si,sj)=βsimlcs(si,sj)+(1-β)simcos(si,sj),计算内容相似度和结构相似度,其中β取最优值为0.6。
CNN[w+pos]+ SSC [pos]:利用本文第1.3节提出的排比句识别方法。
各分类方法的实验结果如表1所示。
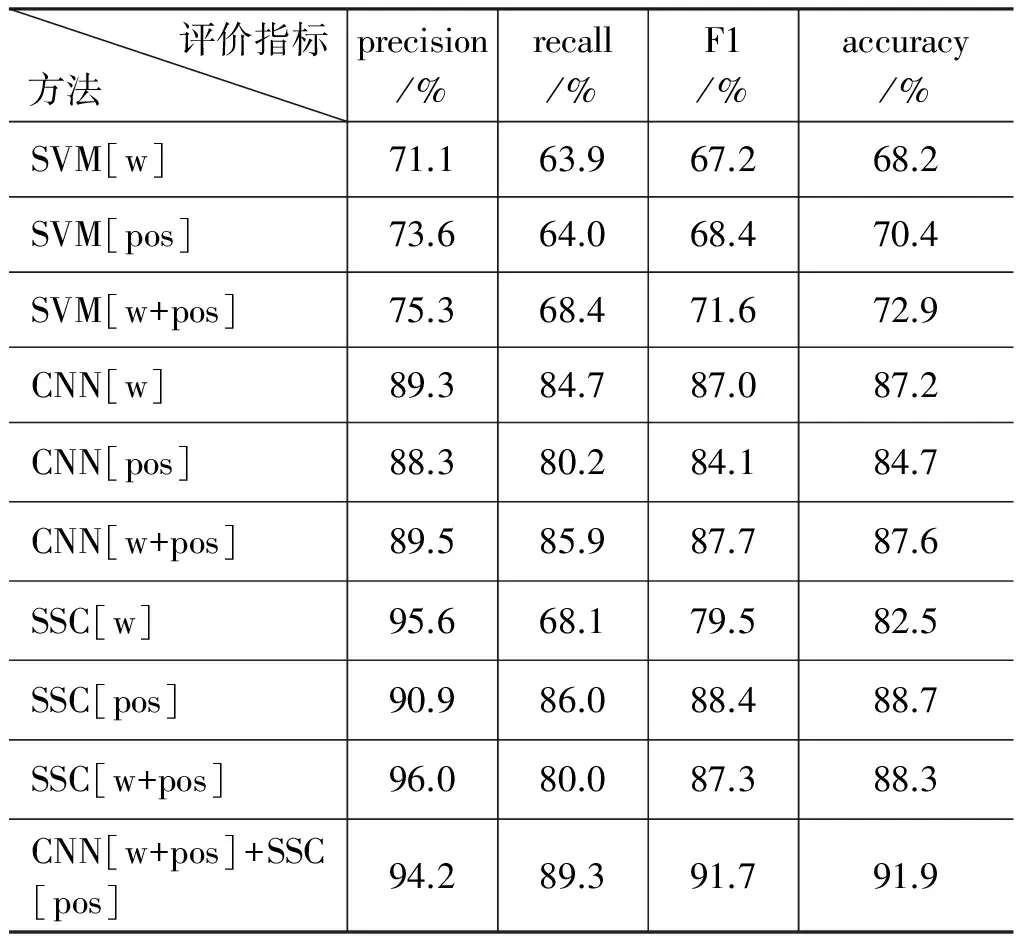
表1 各类排比句识别方法的实验结果比较
由表1可以看出:
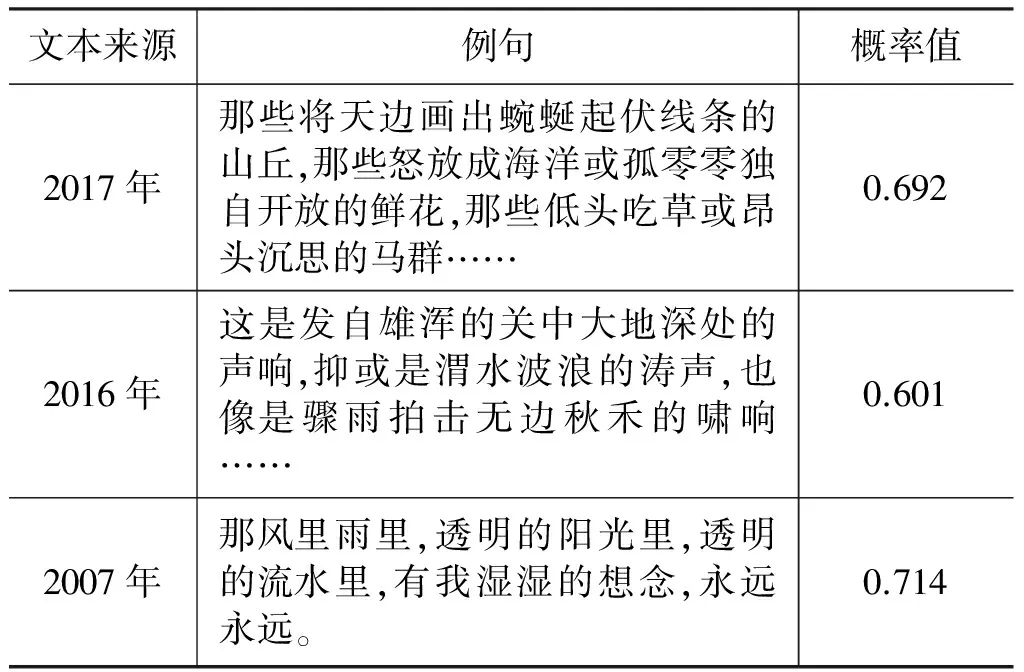
(1) 从分类器的角度,在三种不同的特征表示下,三种分类方法识别排比句的结果分别为SVM[w] (2) 对于CNN算法,在precision、F1和accuracy 三种评价指标下,CNN[pos] (3) 对于SSC算法,在precision、recall、F1和accuracy四种评价指标下,SSC[w] (4) 从综合词语与词性作为特征的角度,SVM[w+pos] (5) 从方法融合的角度,CNN[w+pos]+SSC[pos]在所有方法中识别排比句的效果最好,说明融合后的方法充分地考虑了句子的内容相关性和结构相似信息。 对于引言中例1和例2,CNN[w+pos]、SSC[pos]、CNN[w+pos]+SSC[pos]的概率如表2所示。 表2 方法融合前后的概率值对比 由表2可知,例1中使用SSC[pos] 得到排比句的概率值为0.53,判断为非排比句。例2中使用CNN[w+pos]得到的概率值为0.34,也判断为非排比句。然而,两个例子若使用融合后的方法,其概率值分别为0.63和0.69,均可正确地判断为排比句。由此,对于排比句来说,有些句子侧重结构上的相似,有些句子侧重语义上的相关,将两个方法融合是必要的。 实验3CNN[w+pos]+SSC[pos]在高考鉴赏题中的应用实验 将本文所提的方法应用在高考题解答中,选取2017、2016和2007年北京高考题中文学类阅读材料进行排比句识别,获得排比句识别的概率如表3所示。 表3 文学类文本中排比句识别的概率值 由表3可看出,三个例句的概率值均大于Φ3,说明对排比句识别均正确,由此可知本文提出的方法可以有效地对排比句进行识别,进而为高考阅读理解部分的鉴赏题解答和文本的自动赏析服务。 本文针对文学类文本中的排比句,依据其内容相关、结构相似的特点,设计了融合CNN和结构相似度计算的排比句识别方法,并与其他方法做了比较实验。针对高考题内的文学类阅读理解的问题,将本文所提方法应用到阅读材料中的排比句识别中,取得了不错的效果,从而进一步证明了本文所提出的方法和特征选择的有效性。但本文仍有不足,例如数据量较小,没有在政论、新闻等其他语体上进行对比实验。今后的工作可以考虑如何更好地将文本的结构相似性信息嵌入到CNN的输入层中,并将其应用到更为广泛的语体语料之中。 备注:为了便于更多的研究者开展排比句识别方面的研究,我们将本文所用的数据共享到山西大学文本情感分析技术资源开放与服务平台(http://115.24.12.5/)。 [1]张宗正.修辞格位、修辞格变体和修辞格作品——关于修辞格本质即同一性的再思考[J].修辞学习,2003,(2):24-25. [2]李胜梅.排比的篇章特点[J].南昌大学学报(人文社会科学版),2005,36(5):127-133. [3]陈永敬.排比的构成特征及排比项数限制的心理机制[D].武汉:华中师范大学,2008. [4]夏丽芳.排比的语篇衔接功能[J].牡丹江教育学院学报,2008(1):51-52,85. [5]范俊.排比的语用修辞研究[D].重庆:四川外国语大学,2013. [6]聂仁海.排比辞格:语言本质的典型体现[J].现代企业教育,2006(9):160-161. [7]皮晨曦.政论语体与艺术语体排比差异研究[D].广州:暨南大学,2011. [8]高婉瑜.谈对偶与排比[J].修辞学习,2008(5):58-60. [9]叶定国.Parallelism与对偶、排比[J].外语与外语教学,1999(2):53-55. [10]吕敬华.排比和反复的妙用[J].长沙电力学院学报(社会科学版),2000,15(2):96-98. [11]何佳利.《蜗居》比喻和排比辞格探析[J].大众文艺,2011(4):125-126. [12]张璐璐.浅析微博语言中的排比修辞格[J].青春岁月,2012(24):120-121. [13]张晓.排比的再探讨[J].昭乌达蒙族师专学报(汉文哲学社会科学版),2004,25(8):17-18,11. [14]梁社会,陈小荷,刘浏.先秦汉语排比句自动识别研究:以《孟子》《论语》中的排比句自动识别为例[J].计算机工程与应用,2013,49(19):222-226. [15]Mikolov T,Sutskever I,Chen K,et al.Distributed representations of words and phrases and their compositionality[C]// Proceedings of the International Conference on Neural Information Processing Systems.USA:Curran Associates Inc,2013:3111-3119. [16]Mikolov T,Chen K,Corrado G,et al.Efficient estimation of word representations in vector space[J].arXiv preprint arXiv:1301.3781,2014. [17]Le Q V,Mikolov T.Distributed representations of sentences and documents[J].arXiv preprint arXiv:1405.4053,2014. [18]周飞燕,金林鹏,董军.卷积神经网络研究综述[J].计算机学报,2017,6(40):1-23. [19]李彦冬,郝宗波,雷航.卷积神经网络研究综述[J].计算机应用,2016,39(09):2508-2515,2565. [20]Kim Y.Convolutional neural networks for sentence classification[J].arXiv preprint arXiv:1408.5882,2014. [21]Kalchbrenner N,Grefenstette E,Blunsom P.A convolutional neural network for modelling sentences[J].arXiv preprint arXiv:1404.2188,2014. [22]Hu B,Lu Z,Li H,et al.Convolutional neural network architectures for matching natural language sentences[C]// Proceedings of Advances in Neural Information Processing Systems.USA:MIT Press,2014:2042-2050. [23]Bengio Y,Schwenk H,Senécal J,et al.Neural probabilistic language models[J].Journal of Machine Learning Research,2003,3(6):1137-1155. [24]Collobert R,Weston J,Bottou L,et al.Natural language processing(almost)from scratch[J].Journal of Machine Learning Research,2011,12(1):2493-2537. [25]Kiros R,Zhu Y,Salakhutdinov R,et al.Skip-thought vectors[C]// Proceedings of International Conference on Neural Information Processing Systems.USA:MIT Press,2015:3294-3302. [26]Lin C Y,Och F J.Automatic evaluation of machine translation quality using longest common subsequence and skip-bigram statistics[C]// Proceedings of the 42nd Annual Meeting on Association for Computational Linguistics,USA:Stroudsburg ,2004. 穆婉青(1993—),硕士研究生,主要研究领域为自然语言处理。E-mail:948611255@qq.com 廖健(1990—),博士研究生,主要研究领域为文本情感分析。E-mail:liaojian_iter@163.com 王素格(1964—),通信作者,博士,教授,主要研究领域为自然语言处理,文本情感分析。E-mail:wsg@sxu.edu.cn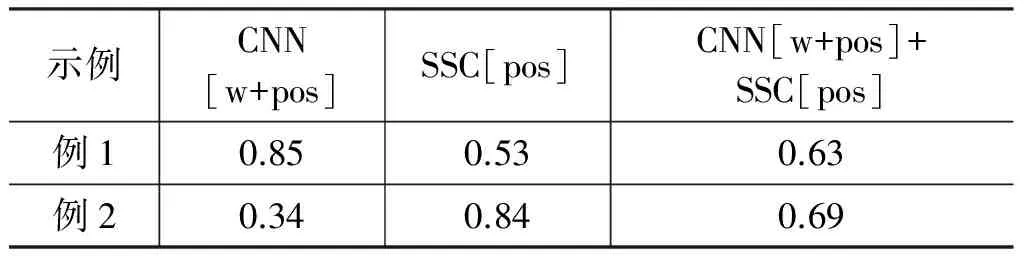
3 总结


 猜你喜欢
国际医药卫生导报(2022年18期)2022-09-29 01:29:00中等数学(2022年2期)2022-06-05 07:10:50小天使·一年级语数英综合(2020年4期)2020-12-16 02:56:32小学生学习指导(低年级)(2020年6期)2020-07-25 02:31:36作文周刊·小学四年级版(2020年24期)2020-07-17 02:48:39快乐语文(2020年18期)2020-07-17 01:20:36小学生学习指导(低年级)(2018年9期)2018-09-26 05:59:44疯狂英语·新读写(2018年2期)2018-09-07 09:32:10作文评点报·低幼版(2016年42期)2017-01-23 11:45:27现代语文(2016年21期)2016-05-25 13:13:46
猜你喜欢
国际医药卫生导报(2022年18期)2022-09-29 01:29:00中等数学(2022年2期)2022-06-05 07:10:50小天使·一年级语数英综合(2020年4期)2020-12-16 02:56:32小学生学习指导(低年级)(2020年6期)2020-07-25 02:31:36作文周刊·小学四年级版(2020年24期)2020-07-17 02:48:39快乐语文(2020年18期)2020-07-17 01:20:36小学生学习指导(低年级)(2018年9期)2018-09-26 05:59:44疯狂英语·新读写(2018年2期)2018-09-07 09:32:10作文评点报·低幼版(2016年42期)2017-01-23 11:45:27现代语文(2016年21期)2016-05-25 13:13:46
