
面向网络功能虚拟化的高性能负载均衡机制
2018-04-16 11:59王煜炜李鹏飞
计算机研究与发展 2018年4期
王煜炜 刘 敏 马 诚 李鹏飞
1(中国科学院计算技术研究所 北京 100190) 2 (中国科学院大学 北京 100049) (wangyuwei@ict.ac.cn)
在传统的电信业务系统中,丰富多彩的业务由各类专有硬件设备承载.伴随着新技术和新服务的蓬勃发展,设备的生命周期越来越短且运营成本大幅增加,使得传统电信业务应对来自互联网企业OTT(over the top)的服务竞争中逐渐处于不利地位.
针对上述问题,由全球各大运营商牵头,欧洲电信标准化协会(ETSI)在2012年首次提出了网络功能虚拟化(network function vitalization, NFV)的概念,其核心思想在于将网络功能与专用硬件设备解耦,进而将其以软件形式部署于数据中心通用硬件平台,从而为运营商提供强大的业务整合与创新能力[1-2].基于NFV技术框架,通过特定的管理与编排策略,使得虚拟网络功能(network function, NF)以中间件的形式串接形成业务服务链(service function chain, SFC)(简称业务链)来提供服务,NF类型和顺序决定了业务链的功能内容[3].然而,部署电信业务所带来的庞大用户请求和数据流量给NFV业务系统带来了巨大压力,从而引发时延增大和吞吐量下降等严重的性能问题[4],此时单一NF功能处理单元往往不能满足数据高效处理要求,为了保障业务网络性能,需要将数据在不同NF间进行均匀分发以达到高效处理的目的.因此,在NFV系统中部署负载均衡服务至关重要.
ETSI官方发布的标准文稿中定义了4种负载均衡系统模型[5],根据负载均衡服务与网络功能耦合的情况可分为2类:内部负载均衡和外部负载均衡服务系统.前者内嵌于NF产品中,大多由专门厂家定制研发,但部署受限于具体产品架构,缺乏通用性和良好的可移植性;相应地,在外部负载均衡服务系统架构中,负载均衡器可以作为单独的网络功能NF进行部署,由NFV管理系统进行统一业务编排,部署和扩展灵活.因此,本文所提出的负载均衡机制基于外部负载均衡服务系统模型实现.
传统的网络负载均衡系统通常以专用硬件设备的形式部署于网络中,这种方式存在明显的缺陷[6-7]:1)其扩展性受到单点设备容量限制,很难满足用户业务流量快速增长需求.2)不能满足实时业务的高可达性需求.尽管通常采用成对部署的方式来避免单点故障的影响,只能提供简单的1+1冗余备份.3)缺乏业务快速迭代所需要的灵活性和可编程性,硬件系统通常很难升级和修改.4)成本较高,通常只有靠增加新的设备进行部署.相比较而言,面向NFV的负载均衡系统以软件形式部署于商用服务平台之上,因此成本得以大大降低.同时,可以利用横向扩展方式来解决可扩展性问题,此时处理容量可通过灵活增加部署虚拟机的方式来实现,从而提供N+1的冗余备份.同时,服务可达性和可靠性也得到增强,系统部署和升级改造也得以简化.
尽管具有上述优点,设计和部署一个面向NFV的负载均衡软件系统仍然具有非常大的挑战:1)由于NFV承载大量电信业务流量和访问请求,相关负载均衡机制必须能够在虚拟化环境中提供高吞吐量、低延迟的处理性能;2)必须保证业务服务链连接的准确一致,即属于同一个业务连接的数据报文能够转发至后序相同的NF实例,并能够应对后端资源池发生动态变化状况和其他故障;3)业务服务链所处的虚拟化网络环境复杂多变,其网络性能受到多种因素影响而波动情况明显.因此,必须根据网络链路状况以及NF工作负荷情况提供实时、准确的负载均衡调度策略.
基于数据平面开发套件(data plane develop-ment kit, DPDK)等相关技术[8],本文设计实现面向NFV的4层高性能网络负载均衡机制及系统HVLB(high performance virtual load balance system),能够灵活部署并运行于主流虚拟化平台环境,主要贡献包括4点:
1) 设计实现基于控制与转发处理分离的负载均衡处理架构,实现调度策略制订和数据转发的有效分离.同时,提出基于综合能力反馈的NF选择与调度策略,将网络链路和NF计算资源使用状况作为调度依据,有效减小业务数据分发处理过程中的开销.
2) 针对虚拟化网络环境下数据包传输与处理特点,基于网卡分流功能实现队列处理功能硬件卸载,采用多核多队列并发高效处理数据报文,并保证各处理队列间的任务流量均衡,保障数据包的高效处理.
3) 设计基于虚拟NUMA节点资源分配策略,实现从虚拟机到用户空间处理线程之间的数据零拷贝,并保证各处理队列之间数据访问隔离,有效地减少内存申请和释放及线程同步开销.
4) 基于KVM的虚拟化平台部署并实现HVLB原型系统.在虚拟化环境下,HVLB单队列和多队列处理性能均远远优于主流开源软件系统LVS(Linux virtual server)[9].针对UDP小尺寸数据包,在给定计算资源情况下,HVLB在万兆网卡上达到了线速的处理与转发性能.
1 相关工作
目前,负载均衡技术广泛受到产业界和学术界的关注,现有工作主要分为3类:
1) 传统依靠专有硬件设备实现的负载均衡方案[10-14].如引言中所述,这些方案着眼于利用硬件来提升网络数据处理性能;但是成本较高,且可扩展性、灵活性较差,不适合NFV场景中业务动态部署的需求.

Fig. 1 The architecture and working flow of HVLB图1 HVLB架构及处理流程
2) 基于软件的网络负载均衡方案.部分方案以通用软件包的形式,按照扁平的结构进行部署,目前已经在Web搜索或其他并行计算系统中得到广泛应用,如LVS,Nginx[15],HAProxy[16]等.这部分方案可在虚拟化环境下进行灵活、快速地部署.但数据传输与处理基于内核,存在网卡中断、数据包拷贝等固有开销,网络性能较差;且需依靠多层次部署才能实现容量扩展,无法满足NFV业务的需求.
3) 随着用户业务需求进一步扩大,出现了第3类层次化负载均衡解决方案,其实质是一个可扩展的负载均衡集群系统.相关机制依托ECMP协议进行业务分流.将数据平面功能划分为若干层次,在路由器、负载均衡器和终端服务器之间建立多层负载处理,具有良好的可扩展性和处理能力.比较典型的有微软公司的Ananta[7],Duet[17],普林斯顿大学的Niagara[18]和谷歌公司的Maglev[6]等.Ananta是一个分布式的软件负载均衡器,它采用ECMP协议进行系统扩展和管理控制,并使用业务流表保持连接的一致性.尽管提供了快速路径转发机制,其单机数据包的处理性能受限于操作系统内核,在虚拟化环境中存在处理瓶颈.Duet和Niagara是基于硬件和软件混合设计的负载均衡器,旨在解决Ananta机制存在的单机转发性能问题,其使用数据中心现有的交换机来构造高性能负载均衡系统,处理与转发需要大量依靠硬件交换机,使得无法在NFV虚拟化环境中进行灵活部署和扩展.Maglev是谷歌公司为其云平台研发的网络负载均衡系统,统一部署并运行于商用物理服务器中,处理容量可以通过添加移除服务器的形式进行调整.在性能优化方面,Maglev采用网卡和进程共享内存资源的方式实现内核跨越,转发性能可以达到线速.同时引入特有的一致性Hash与连接追溯算法,提供均匀、准确的后端服务器选择和调整机制.Maglev系统适用于较大规模云平台且性能优异,但无法直接部署并应用于NFV虚拟化环境中;同时,其采用的服务集群选择策略未考虑链路状况及计算负载变化对其处理能力的影响,因而不能提供最佳的目标NF选择策略.
综上所述,现有研究工作无法直接应用于NFV虚拟化应用场景,且未充分考虑虚拟化环境下的网络链路和业务链负载变化状况对业务处理性能的影响,进而无法为业务系统提供高性能负载均衡服务.
2 概 述
2.1 架构与处理流程
HVLB采用控制与转发分离的架构设计,如图1所示,主要包括控制器(controller, CR)和转发器(forwarder, FR)两部分.其中CR主要完成虚拟服务配置、调度策略制订以及对转发器工作状况、NF计算资源占用以及网络链路状况监测.此外,CR还提供与NFV管理系统的接口,以实施资源动态配置与调整.在实际部署中,CR既可作为NFV管理系统的一部分,也可以单独部署.相应地,FR则专注于数据包的接收、调度策略执行及转发处理.在实际的数据中心环境部署中,可根据虚拟网络配置情况部署多个CR,每个CR负责管控不同的FR,从而提升管理效率,保障性能.
HVLB主要工作流程包括:由NFV管理系统根据业务处理和传输状况向HVLB发起负载均衡请求(步骤①),同时将需要进行负载均衡的NF及业务链的信息发送给CR,其中包含虚拟服务、待服务的前序NF信息等;收到请求后,CR给出确认回复(步骤②),同时挑选工作能力较强的FR进行处理,并向该FR下发虚拟服务配置指令(步骤③);如果未能找到合适的FR则通知NFV管理系统建立新的FR实例.FR接收到CR配置指令后,进行确认回复,并及时更新其虚拟服务列表(virtual service list, VSL)(步骤④).NFV管理系统下发路由更新策略(步骤⑤),引导待服务NF业务流转发至步骤③中选定或新生成的FR(步骤⑥),由该FR完成业务数据转发和响应接收(步骤⑦),并更新其业务连接表(connection table, CFT).CR开始根据备选目标NF计算资源占用及网络链路状况为FR制订业务调度转发策略,并更新下发至FR(步骤⑧).FR根据CR策略将数据包转发至备选NF集群中的多个NF处理,然后根据NFV管理系统路由信息将数据包转发至该业务链中的后续NF.
2.2 虚拟服务配置与管理
HVLB旨在为NFV业务提供业务负载分担,尽可能减少网络传输和处理瓶颈.作为特殊的网络功能中间件,HVLB可为多个NF或多条业务链同时提供服务.因此,首先需要对其提供的服务进行标识和管理.
虚拟服务(virtual service,vs)是HVLB对外进行服务宣称的虚拟实例,用五元组信息(关键字,协议,地址,端口,真实服务)标识,即vsi=〈keyi,protocoli,vipi,vporti,rsi〉.其中,protocol为传输协议,vip为虚拟服务IP地址,vport为对应端口号,关键字key为此虚拟服务的唯一标识,由协议、地址和端口所对应的值进行Hash计算得到.真实服务(real service,rs)实质是为该虚拟服务提供处理的目标NF集合,用rsi=〈keyk,protocolk,dipk,dportk,healthk,reservedk〉标识,其中前4项含义与关键字计算方法和虚拟服务一致,不同之处在于虚拟服务中的IP地址并不需要配置在具体网络接口上,而真实服务中的IP地址和端口信息为各NF所在虚拟机中的真实配置信息.health为每个NF的工作状态,初始化设置为1.在系统处理过程中,若CR通过NFV管理系统获悉某个NF故障或网络不可达,即将该NF健康状态置为0.此时暂时将该rs从对应vs中真实服务列表中剔除.reserved为调度转发策略保留信息字段,主要用来存放对应某vs中的各目标NF的转发比例.当需要进行虚拟服务添加时,首先完成2.1节中的虚拟服务信息配置,由CR统一管理并维护虚拟服务集合VS={vsi}(i=1,2,…,N),同时下发至各个FR,由FR维护各自虚拟服务列表.相关虚拟服务配置结构如图2所示:

Fig. 2 The configuration of virtual service and management in HVLB图2 HVLB虚拟服务配置与管理
3 转发器
3.1 概 述
HVLB设计实现了高性能负载均衡转发器数据处理框架,作为独立的应用程序,转发器FR部署并运行于虚拟机的用户空间,实现对Linux操作系统内核协议栈的完全跨越.整体处理流程如下:转发器基于轮询模式批量接收来自网卡的数据请求和响应,接收到的数据包将会按照其五元组信息被分发至不同的队列进行并行处理.首先进行业务分类操作,该过程通过查找和匹配虚拟服务关键字进行,只有匹配命中的数据包才会进入后续处理流程.完成业务分类后,仍然以数据包五元组Hash值为关键字,在业务连接表中进行连接状态查询.若命中,则证明该业务连接已存在,此时重用表中已选择的NF作为目标NF;若未命中,则证明该业务连接为新连接,需要从控制器CR更新的调度和转发策略中选择目标NF.由于CR已经为各NF确定了数据转发比例,FR只需运行一个简单的0~1的随机数计算程序,然后将计算结果和4.2.3节中各NF转发比例范围进行比对即可完成调度操作.同时,在业务连接转发表中插入新的表项并维护业务连接状态.业务连接表格式如表1所示:

Table 1 The Structure of the Connection Table表1 业务连接表结构
HVLB同时支持TCP和UDP传输协议,对于无连接的UDP协议,FR对相同五元组的数据分发视同一次“连接”,通过维护其超时状态来进行管理,超时时间默认为300 s,若超时之后仍然没有后续相同五元组的数据包到来,则将相关表项删除.
完成调度策略选择后,转发器对数据包的路由和MAC信息进行修改,根据NF目的地址查找路由表匹配出下一跳IP地址和端口,查找ARP表匹配出下一跳MAC地址,路由表和ARP表内容通过控制器配置虚拟服务时进行统一添加,并在处理过程中进行定期更新维护.最后将数据包地址和信息写入发送队列缓冲区描述符,请求网卡完成数据包转发.完成上述处理的同时,转发器FR还需实时对各队列数据处理情况进行监测;另一方面,实时接收并处理来自控制器CR的虚拟服务配置和调度策略更新消息.
3.2 高速数据包处理
为了满足NFV承载的业务服务质量需求,我们希望HVLB的处理和转发速度能够达到线速,因此需要尽可能减少处理与转发过程中的各种开销.分析负载均衡的处理过程,主要的开销包括IO传输和数据处理2部分.前者主要指的是操作系统及网络协议栈处理过程中引入的中断、系统调用以及数据包拷贝等开销;后者主要来源于计算资源调度竞争、线程上下文切换、数据访问竞争等[19-20].
HVLB转发器实质上是一个位于虚拟机用户态的高性能网络处理协议栈.整体架构如图3所示,核心操作由处理与转发线程(processing and for-warding thread, PFT)和统计与交互线程(statistics and interaction thread, SIT)两类完成.从网卡接收到的请求和响应被分发至多个队列进行处理,每个队列对应一个PFT线程,单独完成负载均衡处理与转发操作;相应地,由SIT线程完成虚拟服务配置、各PFT对应队列的工作状态信息监测,并负责完成与控制器CR的消息交互操作.

Fig. 3 The processing architecture of the FR图3 转发器处理架构
每个PFT周期性进行接收请求和响应轮询,轮询操作通过一个高速环形队列Rece_Ring进行,该队列存在2个指针,分别指向当前环形队列中的未处理数据请求和已处理请求,请求中包含了相关数据包的地址指针信息.PFT读取对应地址信息,并随即进入后续操作处理.PFT和SIT之间的通信通过DPDK提供的无锁环形队列实现,每个PFT和SIT之间维护一个环形通信结构Control_Ring,以独立的生产者和消费者方式与其他PFT和SIT之间实现访问隔离,减少由线程竞争引发的开销.为保障处理性能,转发器采取了一系列高效数据处理策略,下面进行详细介绍.
3.2.1 数据高效直通和零拷贝
数据高效传输是负载均衡相关业务高性能处理的前提,在虚拟化传输环境中,传输开销主要包括中断开销、内核空间和用户空间的上下文切换以及数据拷贝开销等.基于单根IO虚拟化(single root IO virtualization, SR-IOV)技术[21],HVLB为转发器所在虚拟机分配了特定的HVLB-VF(virtual function),在网卡和虚拟化管理单元Hypervisor之间建立数据直通通道,实现对Hypervisor以及操作系统操作的跨越;另一方面,由于HVLB转发器部署于虚拟机用户空间,通过轮询的方式实现数据批量的接收与发送,实现对虚拟机操作系统的跨越.通过上述2次跨越操作,转发器在虚拟机用户空间和网卡之间建立了高效直通通道.同时,基于用户空间IO技术,转发器在网卡和接收处理队列之间建立共享数据包存储区域,从网卡接收的数据包被直接存入共享数据包存储区域,接收队列轮询到数据请求的同时将数据地址指针信息通知PFT进行处理,整个过程无需进行数据拷贝操作,有效减少了数据传输开销.
3.2.2 队列处理功能硬件卸载
3.2节已述及,PFT线程要负责处理负载均衡过程中的多项操作,因而会产生较大的处理开销.如图4所示,利用主流智能网卡支持的RSS[22](receive side scaling)和FD[23](flow director)技术,在不改动网卡硬件的前提下,转发器进一步将硬件队列分配以及部分Hash计算操作卸载至网卡进行,从而有效减少处理开销,同时降低计算资源消耗,相关FD和RSS规则设置代码参见图5.

Fig. 4 Hardware function offload of queue processing图4 队列处理功能硬件卸载

队列处理功能硬件卸载过程主要包含2部分操作:
1) 硬件队列分配及CPU绑定
系统初始化时给转发器所在虚拟机分配N个vCPU,分别绑定N个物理CPU核,将其中N-1个vCPU与相同数量的PFT线程绑定,称为处理与转发核(process and forward core, PFC);将剩余1个vCPU与统计与交互线程SIT绑定,称为统计与交互核(statistics and interaction core, SIC).同时,计算每个数据包的五元组Hash值,根据接收与处理核的数量,依托网卡建立相同数目的硬件接收与转发队列.
在数据接收方向上,基于控制信令接收端口号,通过FD规则匹配将所有接收到的来自控制器的控制消息数据报文发送至SIT线程上进行处理,从而将控制报文和数据报文区分.进一步基于RSS将余下相同五元组数据通过接收队列均匀且独立分发至多个PFT处理,由于各个PFT预先绑定了独立的CPU资源,因而可以避免由于CPU上下文切换产生的开销.完成相关处理后,依靠3.2.1节中直通通道从发送队列中进行转发.相应的vCPU和物理CPU数量可根据业务流量进行预设和调整.
2) 基于元数据的数据信息预处理
由3.1节分析可知,为了完成业务连接查询匹配,需要计算每个数据包的五元组Hash值.随着数据传输速率增加,上述计算开销也会随之增大,进而会给处理性能带来影响.基于DPDK提供的RSS功能接口,我们直接将操作1中用于硬件队列分配所计算的五元组Hash值存入相关数据包的元数据信息中,业务连接状态查询时直接通过DPDK提供的pktmbuf.hash.rss接口访问,有效地避免重复Hash计算操作带来的处理开销.
3.2.3 虚拟NUMA节点资源分配优化策略
目前主流多处理器系统大多基于非统一内存架构(non uniform memory access architecture, NUMA)设计,不同的NUMA节点的CPU插槽(socket)中对应不同的物理CPU核和本地内存资源.在HVLB的实际部署过程中要求为虚拟机分配多个vCPU,每一个vCPU绑定一个物理CPU核.若当前虚拟机所需CPU数量Cvm大于Socket含有的CPU核总数Csocket时,则需要从不同的Socket中分配CPU资源.此时,存储访问开销将取决于处理器和不同存储区域之间的相对位置.原则上应该尽量避免不同的Sockets中CPU核交叉访问各自的本地内存资源,因为这会导致大量的上下文切换及竞争开销,使得数据包处理性能大幅下降[24-25].
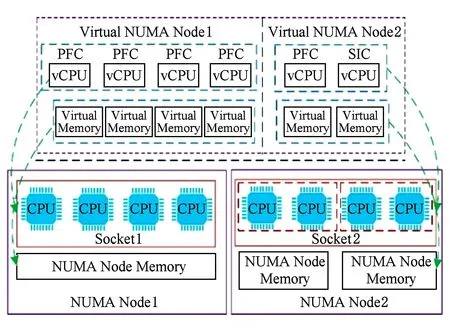
Fig. 6 The resource assignment and management of the virtual NUMA图6 虚拟NUMA的资源分配与管理
为了解决上述问题,FR初始化时即进行基于NUMA节点的资源分配策略优化操作,如图6所示.首先根据业务处理需求对转发器所需的Cvm的数量上限进行预估,然后利用KVM的libvirt接口从已有NUMA节点的Socket中划分出相同数量的CPU核.同时以大页(hugepage)形式为上述CPU分配本地内存,形成为转发器服务的物理NUMA资源池,其中包含若干独立的NUMA节点资源.完成上述操作后,便可以在虚拟机侧感知底层基于NUMA的资源分配情况.进而基于DPDK功能接口将转发器所在虚拟机vCPU及虚拟内存和底层物理NUMA资源池中的CPU和本地内存进行绑定映射,从而形成和物理NUMA资源池相对应的虚拟NUMA资源池,包含相同数量的虚拟NUMA节点.
当需要为转发器分配计算资源时,首先根据实际Cvm值确定所需的vCPU(也即物理CPU核)数量,从虚拟NUMA资源池中选择若干vCPU和各PFT进行绑定,并进一步为每个PFT均匀分配独立的数据缓存区,用于单独存储业务队列数据及业务连接转发表等信息.在处理过程中数据包始终存储在预设内存缓冲区内;相应地,转发器也为SIT设置了独立缓存区,用于存储控制器之间的交互信息.应用上述资源分配和管理机制的好处在于:1)可以直接通过数据包地址指针高效访问对应数据包缓冲区,对数据包进行修改的过程无需任何拷贝操作,有效提升了数据包处理效率;2)确保不同线程所属的处理数据相互隔离,避免了线程访问共享数据的竞争开销.
3.2.4 基于队列负载状况感知的QoS保障
转发器实现数据的多队列并行高效处理,依托RSS等技术使得到达所有队列的业务流分布均匀.然而,由于每条业务流的数据发送速率不同,造成各队列间的数据处理负载有所差异.随着业务量不断增大,可能造成某个队列处理首先过载,后续发送至该队列中的数据将会由于处理不及时而发生丢包.针对上述情况,转发器进一步采取了基于队列负载状况感知的QoS保障策略RSS-A,表2为主要变量及符号释义对照表.

Table 2 Key Notations in the FR表2 转发器器处理过程主要符号释义

(1)
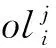
(2)

(3)

(4)
为了防止迁移过程对目标队列的过载影响,采取逐条逐项迁移操作的方式,并实时比较迁移前后目标队列过载频率值的变化情况,确保目标队列不出现过载情况.此外,由于目标队列上PFT的业务连接表中没有迁移业务流的相关信息.因此,完成迁移操作的同时需要将业务表中的连接状态信息更新至目标队列上PFT的业务连接表中,上述策略可有效避免队列过载,保障转发器的处理性能,相关策略如算法1所示.
算法1. 基于负载感知的队列任务调整策略.
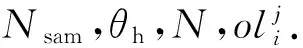
① fori=1→N
② forj=1→Nsamdo

④ end for
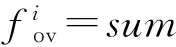
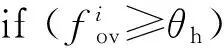
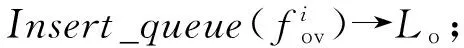
⑧ else
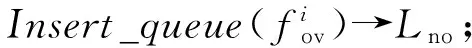
⑩flow_sort(Lo,Lno);
4 控制器
控制器是HVLB系统的管理核心,负责虚拟服务配置、NF选择与调度策略制订等.此外,控制器还负责各类信息监测与分析.
4.1 信息监测与统计分析
1) 转发器工作状况监测.HVLB系统需要并发处理大量业务数据,在实际处理过程中,CR需要实时掌握各FR的工作状况,包括各处理队列上的负载情况等.CR通过与FR的SIT之间的消息接口进行信息交互并对相关信息进行分析,进而按照负载状况及处理情况对各FR进行排序.当NFV管理系统发起负载均衡服务请求时,CR将参考上述列表内容,从中选择理处理能力相对较强的FR进行服务.当某个FR处于严重过载或者网络不可达时,CR会及时将流量转移至其他FR或通知NFV管理系统启动新的FR实例.限于篇幅,相关内容本文不作详述.
2) 网络链路状况监测.业务链中的各NF通过虚拟化网络建立数据传输连接,虚拟化环境的传输特性决定了相关链路状况变化的不确定性,通过与NFV管理系统的接口,CR对各FR至不同NF间的网络链路状况进行监测,以制订准确的调度策略.
3) NF计算资源使用状况监测.目标NF可能为多条业务链所共用,因此其计算资源的使用情况也在不断变化中,而计算资源使用状况对NF网络性能有着重要影响,需要实时监测NF计算资源状况.
4) 业务连接信息维护.CR统一管理和维护所有FR数据处理信息.并将同一虚拟服务的业务连接表进行聚合,然后重新分发至各FR上.因此每个FR可以实时维护其他FR上同一虚拟服务的业务连接信息.当FR发生故障时,可以将业务流实时调整至其他FR进行处理,保障业务数据的传输.
4.2 基于综合能力反馈的NF选择与调度
完成虚拟服务配置后,CR为FR上每一个虚拟服务制订调度和转发策略,进而将业务数据分发至不同的目标NF处理.在NFV典型应用场景中,NF选择首先要保障不会引入新的性能处理瓶颈,主要考虑2方面的因素:1)虚拟化传输过程中引入的固有开销以及数据中心网络中的流量干扰,使得各NF与转发器之间的网络链路状况变化明显,直接影响数据的转发性能[19-20];2)各NF可能同时被不同业务链复用而导致计算资源的竞争,进而影响其网络性能[26-28].基于上述分析,控制器采用基于综合能力反馈的NF选择与调度策略,包括网络传输能力和计算能力2部分.表3为相关变量及符号释义对照表.

Table 3 Key Notations in the CR表3 控制器处理过程主要符号释义
4.2.1 网络传输能力计算与筛选
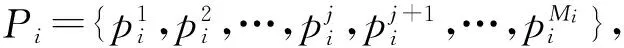
(5)

4.2.2 NF计算处理能力计算与筛选
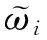
(6)
i=1,2,…,N-k,
4.2.3 调度及分发策略制订
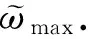
(7)
对计算出的偏移率φi和ηi进行加权处理,即:
ai=γ×φi+(1-γ)×ηi,
(8)
i=1,2,…,N-k-r,
其中,γ为常数,默认值γ=0.5.按照不同nfi对应ai值的大小,进一步分别为各nfi计算业务转发比例λi,用以指导数据转发,即有
(9)
完成上述过程后,控制器将该虚拟服务对应的各nfi业务转发比例值进行汇总,进一步计算nfi在选择比例范围tri如下:随即更新各转发器的虚拟服务配置信息中的reserved字段数值.FR在进行调度处理时,只需按照随机数计算结果进行匹配即可(参考2.2节).
(10)
上述调度策略参见算法2.
算法2. 基于综合能力的目标NF选择策略.
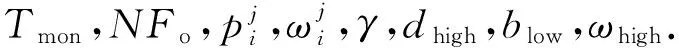
①Pc=∅,A=∅,k=0,ηi=0,num=N;
② fori=1→N
③ forj=1→Mido

⑤ end for
⑥ end for
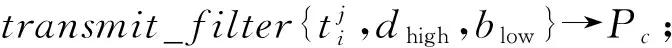
⑧ fori=1→N-k
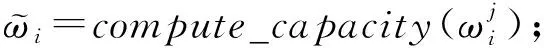
⑩ end for
5 部署与性能分析
HVLB核心作用在于为NFV提供高效的负载均衡数据分发,其处理性能可能受到多种因素的影响,包括处理队列及分配的CPU数量、NUMA节点资源分配情况以及处理的数据包类型等.本节对HVLB的处理性能进行全面评估.为了便于比较,我们搭建了原型系统实验平台,包括8台物理服务器S1~S6,C1和C2,在S1上建立4个虚拟机V1,V2,V3,V4,其中V1运行HVLB转发器,V2运行性能对比系统,V3运行HVLB控制器,V4作为控制器备份.在S2~S6上建立多个虚拟机,用来模拟备选NF集群.在C1和C2上部署和安装测试工具PktGen-DPDK[29]和Thrulay[30].实验过程中由C1和C2单独或同时发送请求至HVLB转发器.令转发器和NF处于同一虚拟子网,并设置FR为NF网关,实验配置参数如表4所示:
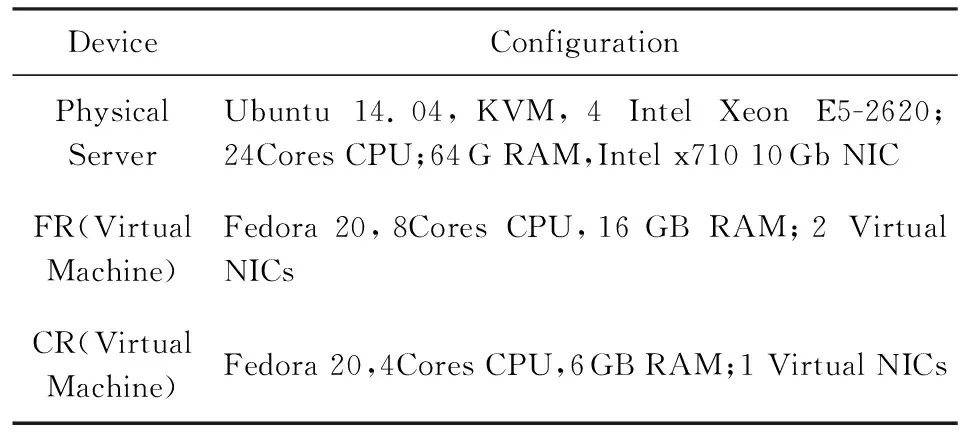
Table 4 Configuration of the Experiment Platform表4 实验平台配置
5.1 HVLB单机处理性能
首先来看转发器的单机处理性能,我们在V2上部署业界广泛采用的LVS[9]进行性能对比.LVS系统可以灵活地部署于虚拟化环境中,但其数据转发处理依赖Linux内核进行.为公平起见,我们同时为V1和V2分别配置基于SR-IOV的虚拟功能VF1和VF2,保证实验过程中2个系统的数据收发均能跨越Hypervisor而直接到达各自虚拟网卡,并同时保证CPU和内存资源处于相同NUMA节点.进而对比HVLB和LVS处理不同类型、不同大小的数据包时的网络性能.
5.1.1 单处理队列性能
首先来看单处理队列的情况,此时HVLB转发器工作在最低配置情况:一个PFT通过虚拟机vCPU绑定1个物理CPU核,SIT绑定1个CPU核,实验中为LVS系统配置相同数量的CPU核.用PktGen均匀发送2种类型的UDP数据包并逐渐增大到线速,大小从64~1 518 B变化.第1种为Constant 5-tuple类型,简称UDP-C,此时发包工具均匀产生1条业务流,所有的数据包具有相同的五元组;第2种为Independent 5-tuple类型,简称UDP-I,发送数据包时不断改变源IP地址和发送端口,因此各数据包对应不同的五元组值.

Fig. 7 The network performance under single queue图7 单处理队列网络性能
吞吐量性能实验结果如图7(a)所示,横轴为数据包尺寸大小,左边纵轴为吞吐量(单位Gbps),右边纵轴为平均处理延迟.对于UDP-C类型数据包,HVLB的吞吐量性能远超LVS,以64 B小包为例,HVLB的最大吞吐量约为1.7 Gbps,约为LVS的3.8倍,其单核处理1 024 B数据包吞吐量性能已达到网卡饱和处理值10 Gbps.相应地,LVS处理各个尺寸大小的数据包均无法达到或者接近10 Gbps.对于UDP-I类型数据包,HVLB的处理64 B数据包吞吐量约为1.48 Gbps,为LVS的5.9倍,但是略低于处理UDP-C类型数据的性能,这是因为UDP-I类型每个数据包的五元组信息各不相同,每个数据包处理都要进行业务连接表查询以及新表项建立操作,引入额外的处理开销.对于UDP-C类型数据而言,业务连接表中已存储相关信息,只需进行查询操作.
平均延迟性能实验结果如图7(b)所示,对于UDP-C和UDP-I类型数据包,在单核大尺寸数据包(512~1 518 B)场景下,HVLB和LVS的延迟性能差距并不明显,随着数据包大小的减少,二者的差别越来越明显,处理64 B小包时,对于UDP-C类型数据,LVS平均处理延迟约为HVLB的3倍;对于UDP-I类型的数据包,LVS平均处理延迟约为HVLB的2.4倍.从实验结果分析可知,LVS基于Linux内核处理数据,引入大量中断、拷贝开销,最终影响网络性能.
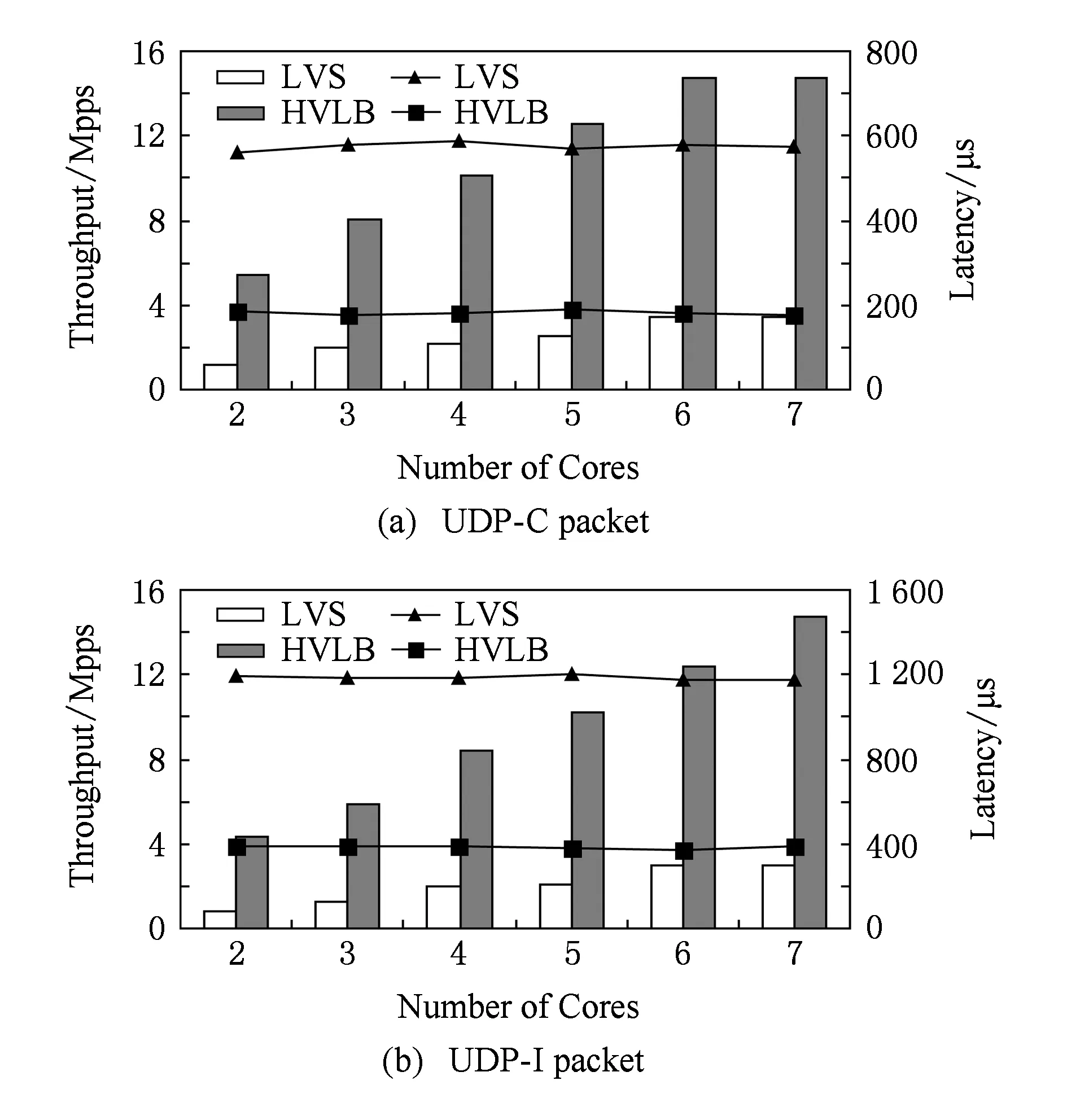
Fig. 8 The network performance under multi-queues图8 多处理队列网络性能
5.1.2 多处理队列性能
分析多处理队列下系统处理性能,实验中为HVLB和LVS系统配置相同的计算资源和处理队列,同时发送UDP-C和UDP-I两种类型,大小为64 B的数据包,并保证为每个接收与处理队列发送相同数量的业务流.结果如图8(a)和图8(b)所示,横轴为处理与转发核数量,左边纵轴为数据转发吞吐量(单位为Mpps),右边纵轴为平均处理延迟.对于UDP-C类型的数据包而言,队列和相应计算资源的增加增强了LVS系统的处理能力,在6和7个处理核时达到最大吞吐量性能约为3.4 Mpps,其队列平均处理延迟约为574.5 μs;相应地,HVLB系统在6个处理核(处理线程)时已达到线速14.88 Mpps;比LVS提升近4.4倍,队列平均处理延迟为181.7 μs;对于UDP-I类型数据包而言,LVS和HVLB处理性能均低于前者.HVLB需要7个CPU才达到线速,平均延迟为386 μs;相比之下,LVS在7个处理核情况下达到的最大吞吐量性能仅为3 Mpps,平均延迟为1 187.5 μs,说明在大量业务数据并发的场景下,LVS的处理瓶颈仍然来源于内核数据收发过程中的固有开销.
5.2 NUMA分配策略对处理性能影响
在前面的实验中,我们对转发器的单机处理性能进行了分析,本节将进一步采用3.2.3节中的虚拟NUMA节点资源分配策略前后对系统性能的影响.实验中令2~7个队列上的PFT绑定不同NUMA节点资源.为简单起见,当队列数量为偶数时,平均分配PFT至2个不同的NUMA节点的计算资源;当队列数量为奇数时,在平均分配基础上随机分配剩余PFT给某个NUMA节点,测试内容和5.1.2节相同.

Fig. 9 The network throughput performance under different NUMA resource allocation strategies图9 不同NUMA资源分配策略下吞吐量对比
实验结果如图9和图10所示.在图9的吞吐量性能对比中,对于UDP-C类型的数据包而言,对于没有经过优化的跨NUMA节点(crossing NUMA nodes, CNN)情况下,吞吐量性能出现明显下降,在6个处理队列条件下,未经过策略优化和优化后(crossing NUMA nodes optimization, CNNO)情况下分别为12.95 Mpps和14.47 Mpps,提升约11.7%,后者仍然略低于5.1.2节中单NUMA节点(single NUMA node, SNN)情况下的处理性能;对于UDP-I类型数据包而言,未经过策略优化和优化后分别为10.55 Mpps和12.05 Mpps,提升约14.2%,同样略低于单NUMA节点下的处理性能.
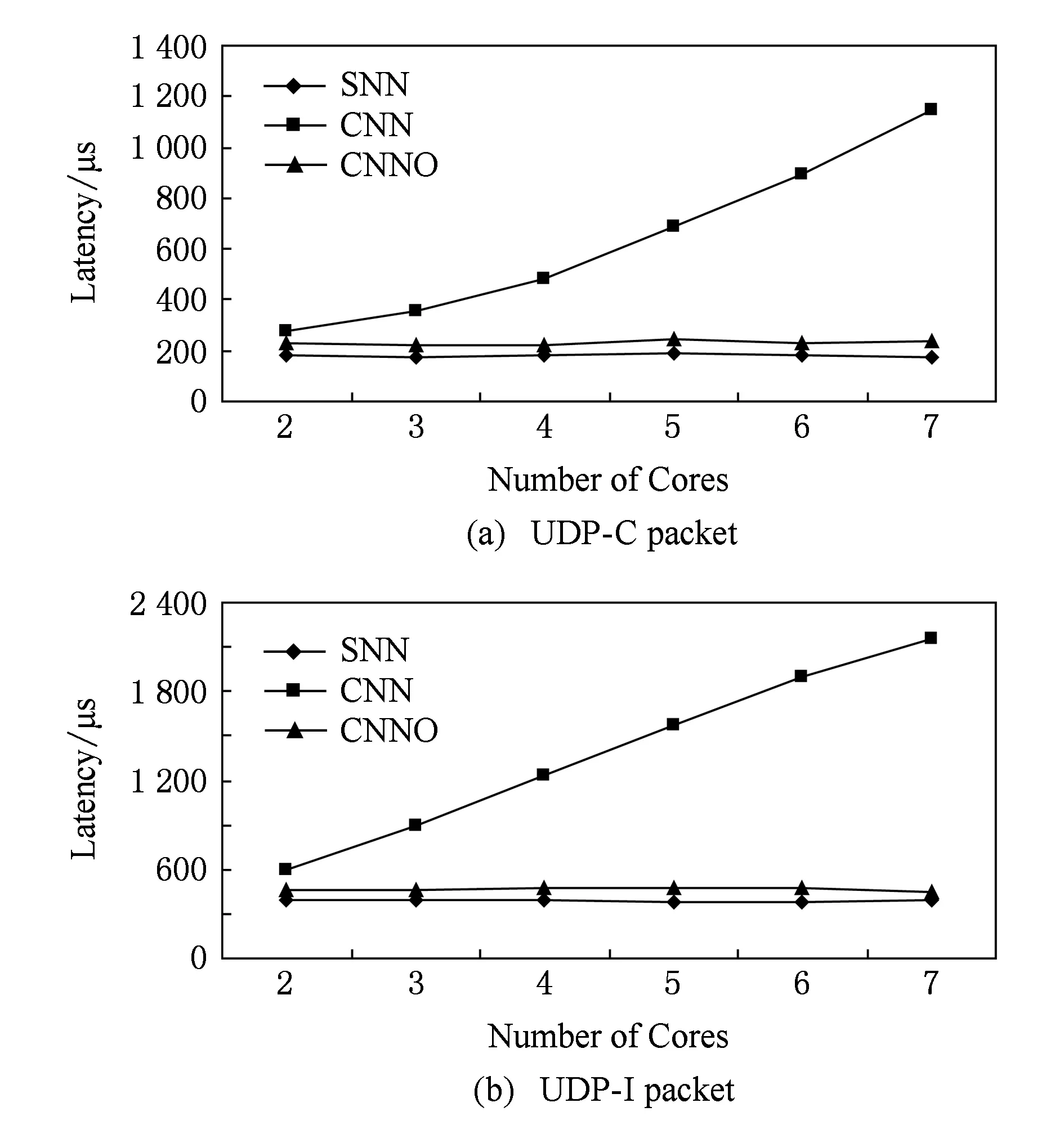
Fig. 10 The latency performance under different NUMA resource allocation strategies图10 不同NUMA资源分配策略下延迟性能对比
从图10中可以看出,相比吞吐量性能而言,跨NUMA节点分配(CNN)对延迟处理性能影响更为明显,并且随着处理队列(处理与转发核)的数量的增加而增大,在7个处理队列时2种类型数据包的平均处理延迟分别达到了1 150 μs和2 149 μs.经过NUMA策略优化(CNNO)后,对应2种数据包类型的平均处理延迟分别为239 μs和442 μs,略高于单NUMA节点情况(SNN)下的177 μs和391 μs.由上述结果可知,采用虚拟NUMA节点资源分配策略后,系统吞吐量和延迟性能均得到提升,但相对单NUMA节点情况仍有下降,原因是HVLB采用一个SIT,PFT和SIT间存在跨NUMA节点访问开销.
5.3 基于负载状况感知的队列QoS性能
在5.1~5.2节实验中发送的测试数据在各队列分布均匀,如果某些业务数据发送速率较高会造成部分队列处理过载而引发性能下降.本文提出RSS-A策略来实现队列间的处理均衡,本节将通过实验验证应用该策略前后对系统性能的影响.我们使用C1和C2同时发送UDP-C类型64 B数据包至转发器.转发器配置为6个处理队列(绑定6个处理与转发核).通过改变源端口,在C1上构造并为每个队列生成10条业务流,并为每个队列的业务流设置不同的增长速率,分别为0.02 Mpps,0.03 Mpps,0.04 Mpps,0.05 Mpps,0.06 Mpps和0.1 Mpps,显然,队列6负载最重;同时,由C2生成并均匀发送每个队列10条业务流,增速为0.01 Mpps,令C1和C2逐渐增大发送速率.过载判决阈值因子ε=0.95,策略处理周期为1 s,测试周期为5 min,取样次数为20,θh=0.5.
图11(a)为各队列达到稳态时吞吐量性能情况,可以看出,在业务传输速率分布不均匀情况下(RSS without uniformity, RSS-WOU),队列6很快处于过载状况,吞吐量性能受到较大影响,仅为10.89 Mpps;相应地,应用RSS-A策略情况后(RSS-A without uniformity, RSS-A)达到13.83 Mpps,且各队列处理情况均匀,与图8中分布均匀情况下(RSS with uniformity, RSS-U)的结果相比仍相差6.5%左右.其原因在于业务迁移过程中业务连接表更新等操作造成一定开销.图11(b)为各队列吞吐量实时变化情况,可看出由于出现过载情况,队列6接连出现2次业务迁移操作,使得队列1和队列2出现速率瞬时增加情况,最终达到处理饱和状态.
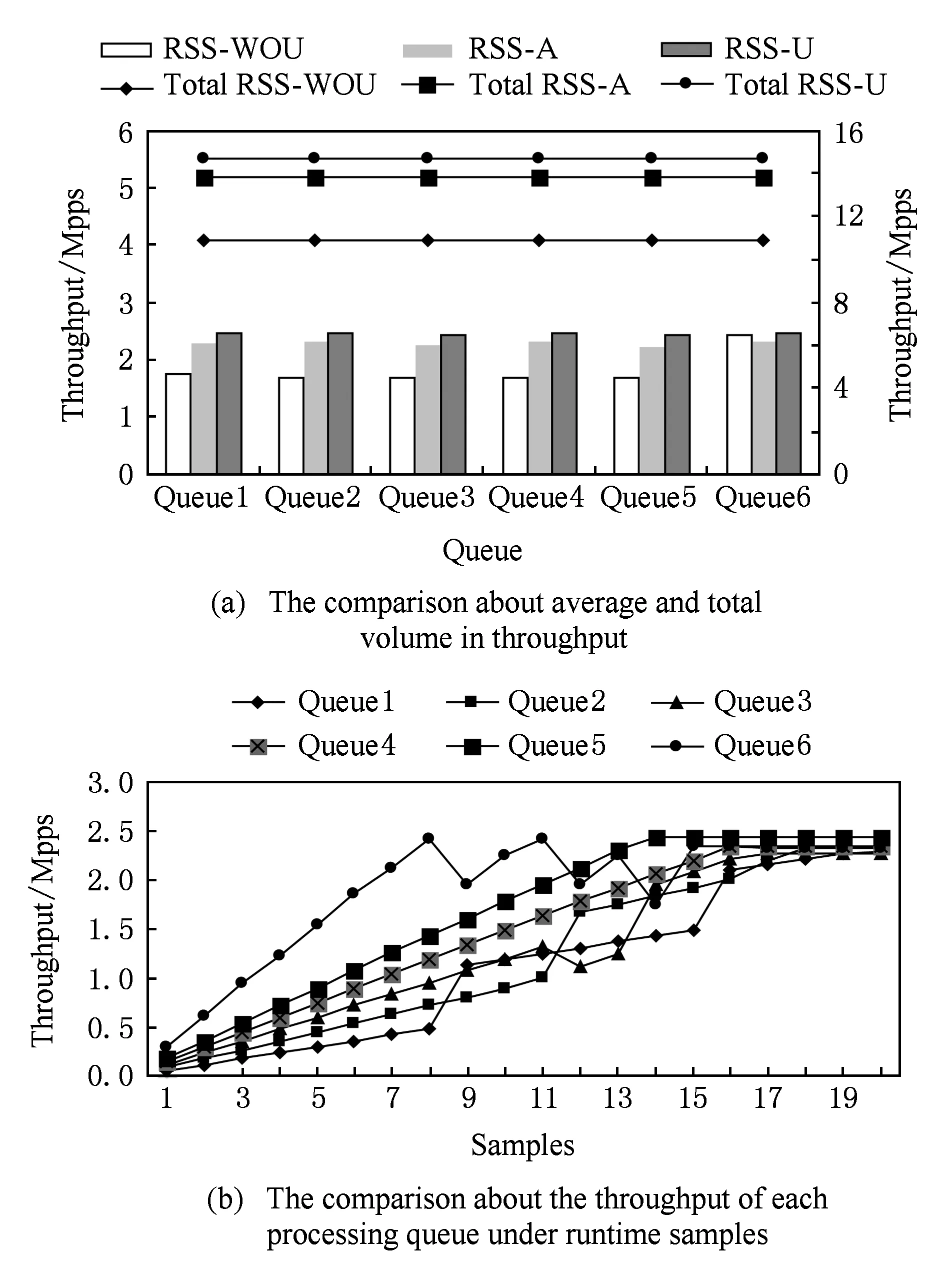
Fig. 11 The network throughput performance with or without the HVLB RSS-A mechanism图11 应用HVLB RSS-A策略前后吞吐量性能对比
5.4 NF选择及调度策略性能分析
本节将对调度策略对网络性能的影响进行评估,实验中选择轮询策略(RR)、Maglev-Hash策略[6]来和HVLB策略进行对比,比较吞吐量及平均往返时延(RTT)变化情况.实验采用Thrulay[30]工具产生60条TCP业务流,经过HVLB处理后分发至S2~S6上的10个NF,转发器和NFs间存在5条链路,链路固有RTT为2.2 ms,每条链路最大带宽为600 Mbps,转发器配置6个处理队列,参考5.1.2节的结果,转发器处理上述业务数据不会产生性能瓶颈,引入处理延迟约为0.2 ms.实验在2种情况下进行:1)稳态情况,HVLB和NF之间链路无其他流量干扰,同时NFs上不运行其他程序;2)动态变化情况,用限流工具对S2,S4和HVLB间链路增加5 ms延迟,在S3,S5中NF所属虚拟机上通过Sysbench[31]工具增加负载,使CPU占用率维持在75%~80%.

Fig. 12 Effect on network throughput under different scheduling strategies图12 不同调度策略下吞吐量性能对比
实验结果如图12和13所示,图12(a)和12(b)中,横轴为时间,纵轴为测试业务流的总吞吐量;图13(a)和13(b)中,横轴为RTT值,纵轴为测试业务流RTT均值概率分布.可以看出,在稳态情况下,3种调度策略下总吞吐量和RTT均值变化平稳,总量维持在2 820 Mbps左右,RTT均值维持在2.5 ms左右;动态变化情况下,RR策略对应总吞吐量值为1 901.9 Mbps,且抖动剧烈;平均RTT延迟为14.9 ms;Maglev-Hash策略对应总吞吐量值为2 044.5 Mbps,抖动较之RR策略更为剧烈,RTT延迟约为11.9 ms.分析其原因在于RR策略固定地选择链路状况不佳或计算资源竞争严重的NF,其网络性能受到影响较大;Maglev-Hash采取均匀选择目标NF方式,性能受到影响较小.采用HVLB策略后吞吐量为2 648.7 Mbps,相比RR和Maglev-Hash策略分别提升39.3%和29.6%,且波动平缓;RTT均值为6.8 ms,比另2种策略分别降低54.4%和42.9%.上述结果表明,HVLB的调度策略综合考虑NF传输和计算能力,在保障网络性能的前提下制订准确的NF选择策略和分发比例.
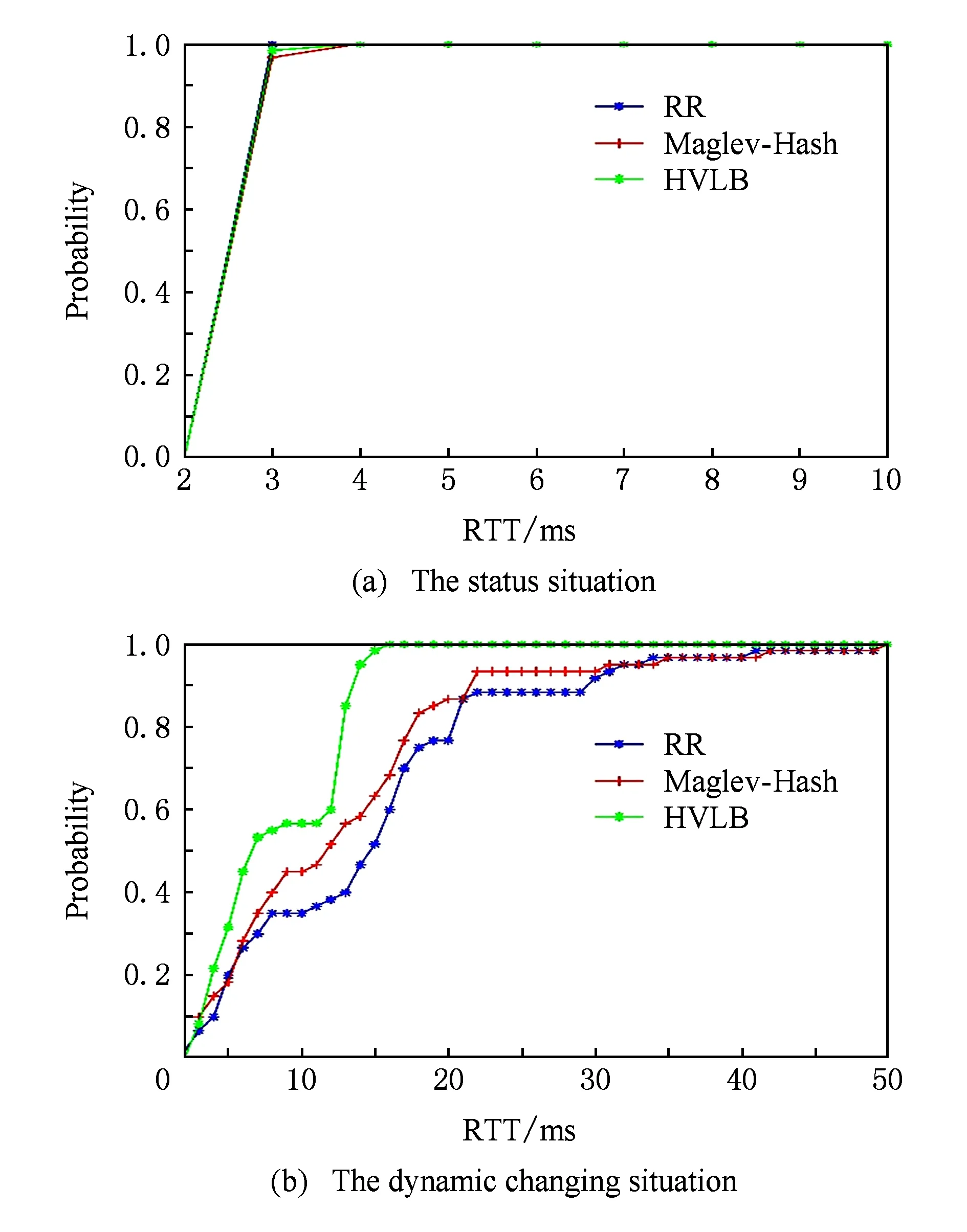
Fig. 13 CDF for latency under different scheduling strategies图13 不同调度策略下延迟性能对比
6 结 论
NFV为电信运营商提供了低成本、灵活高效的业务实施方式.作为其重要功能组件,负载均衡系统可实现准确的业务分发处理,从而提供有力的服务质量保障.本文设计实现了面向NFV的高性能负载均衡机制及系统HVLB,实现调度策略制订和数据转发的有效分离,在转发端基于用户空间实现多核多队列高效数据处理架构,保证各处理队列之间的数据访问隔离和任务处理均衡;在控制端将网络链路和计算相结合的综合能力作为目标NF选择和调度策略制订依据,在业务准确分发的基础上保障了网络性能.下一步研究工作将着眼于系统的容量扩展管理、容错处理方面的改进,并进一步在大规模数据中心环境下进行部署与试商用.
[1]ETSI-GS-NFV-002. 2014. Network functions virtualization (NFV): Architectural framework[OL].[2017-10-28]. http:www.etsi.orgdeliveretsi_gsnfv001_09900201.01.01_60gs_nfv002v010101p.pdf
[2]ETSI-GS-NFV-003. 2014. Network functions virtualisation: Terminology for main concepts in NFV[OL].[2017-07-12]. https:www.etsi.orgdeliveretsi_gsNFV001_09900301.02.01_60gs_NFV003v010201p.pdf
[3]Quinn P, Nadeau T. Service function chaining problem statement[OL]. Internet-Draft: IETF Secretariat, 2014 [2017-08-20]. https:www.ietf.orgarchiveiddraft-ietf-sfc-problem-statement-10.txt
[4]Mijumbi R, Serrat J, Gorricho J, et al. Network function virtualization: State-of-the-art and research challenges[J]. IEEE Communications Surveys and Tutorials, 2016, 18(1): 236-262
[5]ETSI-GS-NFV-SWA-001. 2014. Network functions virtualisation(NFV):Virtual network functions architecture[OL].[2017-01-08]. https:www.etsi.orgdeliveretsi_gsNFV-SWA001_09900101.01.01_60gs_nfv-swa001v010101p.pdf
[6]Eisenbud D E, Yi C, Contavalli C, et al. Maglev: A fast and reliable software network load balancer[C]Proc of ACM NSDI. New York: ACM, 2016: 523-535
[7]Patel P, Bansal D, Yuan L, et al. Ananta: Cloud scale load balancing[C]Proc of ACM SIGCOMM 2013. New York: ACM, 2013: 207-218
[8]Intel. DPDK: Intel data plane development kit[OL].[2016-12-27]. http:www.dpdk.org
[9]LVS. Linux Virtual Server[OL]. [2016-12-27]. http:www.linuxvirtualserver.org
[10]A10 Network. AX Series[OL].[2017-02-11]. http:www.a10networks.com
[11]Array Networks. Array networks[OL].[2017-02-12]. http:www.arraynetworks.com
[12]F5. BIG-IP[OL].[2017-02-17]. http:www.f5.com
[13]Barracuda. Load balancer application delivery controller[OL].[2017-02-23]. http:www.barracuda.com
[14]Load balancer. org Virtual Applicance[OL].[2017-02-23]. http:www.loadbalancer.org
[15]Haproxy. Haproxy Load Balancer[OL].[2017-02-27]. http:www.haproxy.org
[16]Nginx. Nginx[OL].[2017-04-25]. http:www.nginx.org
[17]Gandhi R, Liu Hongqiang, Charlie H, et al. Duet: Cloud scale load balancing with hardware and software[C]Proc of ACM SIGCOMM 2014. New York: ACM, 2014: 27-38
[18]Kang N, Ghobadi M, Reumann J, et al. Efficient traffic splitting on commodity switches[C]Proc of ACM CoNEXT. New York: ACM, 2015: 58-70
[19]Xu Fei, Liu Fangming, Jin Hai, et al. Prolog to managing performance overhead of virtual machines in cloud computing: A survey state of the art, and future directions[J]. Proceedings of the IEEE, 2014, 102(1): 11-31
[20]Li J, Sharma N K, Ports D R, et al. Tales of the tail: Hardware, OS, and application-level sources of tail latency[C]Proc of ACM SoCC 2014. New York: ACM, 2014: 1-14
[21]Dong Yaozu, Yang Xiaowei, Li Xiaoyong, et al. High performance network virtualization with SR-IOV[C]Proc of the 16th Int Symp on High Performance Computer Architecture (HPCA). Piscataway, NJ: IEEE, 2010: 1471-1480
[22]Makineni S, Iyer R, Sarangam P, et al. Receive side coalescing for accelerating TCPIP processing[C]Proc of the 13th Int Conf on High Performance Computing. Berlin: Springer, 2006: 289-300
[23]Intel. Ethernet Flow Director[OL]. [2017-02-17]. https:www.intel.comcontentwwwusenethernet-productsethernet-flow-director-video.html
[24]Han Sangjin, Jang Keon, Park KyoungSoo, et al. Packetshader: A GPU-accelerated software router[C]Proc of the ACM SIGCOMM Conf. New York: ACM, 2010: 195-206
[25]Hwang J, Ramakrishnan K K, Wood T, et al. NetVM: High performance and flexible networking using virtualization on commodity platforms[C]Proc of Networked Systems Design and Implementation. New York: ACM, 2014: 445-458
[26]Wang G,Ng T. The impact of virtualization on network performanceof Amazon ec2 data center[C]Proc of the 29th IEEE Int Conf on Computer Communications. Piscataway, NJ: IEEE, 2010: 1-9
[27]Shea R, Wang Feng, Wang Haiyang, et al. A deep investigation into network performance in virtual machine based cloud environments[C]Proc of the 33rd IEEE Int Conf on Computer Communications. Piscataway, NJ: IEEE, 2014: 1285-1293
[28]Xu Yunjing, Musgrave Z, Noble B D, et al. Bobtail: Avoiding long tails in the cloud[C]Proc of Networked Systems Design and Implementation. New York: ACM, 2013: 329-341
[29]GitHub. Traffic generator powered by DPDK[OL]. [2017-09-20]. https:github.comPktgenPktgen-DPDK
[30]Sourceforge. Thrulay-ng[OL]. [2017-10-12]. http:thrulay-ng.sourceforge.net
[31]Sourceforge. Sysbench[OL]. [2017-10-22]. http:sysbench.sourceforge.net

WangYuwei, born in 1980. PhD candidate. Senior engineer in the Institute of Computing Technology, Chinese Academy of Sciences. His main research interests include future network, virtualization technology and cloud computing.

LiuMin, born in 1976. Professor in the Institute of Computing Technology, Chinese Academy of Sciences. Her main research interests include mobile management, network measurement and mobile computing.

MaCheng, born in 1989. Master candidate in the Institute of Computing Technology, Chinese Academy of Sciences. His main research interests include cloud computing, next generation network and mobile computing.

LiPengfei, born in 1992. Master candidate in the Institute of Computing Technology, Chinese Academy of Sciences. His main research interests include cloud computing, next generation network and mobile computing.
猜你喜欢
计算机与数字工程(2022年3期)2022-04-07
民用飞机设计与研究(2020年4期)2021-01-21
科学导报·学术(2020年26期)2020-10-21
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
军营文化天地(2018年2期)2018-12-15
物联网技术(2018年8期)2018-12-06
世纪之星·交流版(2017年6期)2017-10-09
世纪之星·交流版(2017年3期)2017-07-03
山东工业技术(2016年16期)2016-08-22
