
基于FPGA的多速率LDPC编码器和译码器设计与实现
2018-04-13 08:15张萌
现代导航 2018年1期
张萌
(中国电子科技集团公司第二十研究所, 西安 710068)
0 引言
低密度奇偶校验码(Low-Density Parity-Check Codes,LDPC)因其具有逼近Shannon限的优良性能,目前已经在无线局域网、卫星通信、深空通信和光纤通信等领域得到广泛应用。
为了在时变或有干扰的信道上进行可靠传输,需要一组码率灵活可变的LDPC码,在高信噪比信道条件下,采用高码率以提高传输效率;在低信噪比信道条件下采用低码率,以保障可靠传输。不同的码长需要不同的数据分组方式或者数据帧长度,这极大增加通信系统的整体复杂度。采用码长固定的多码率码,在码长固定的条件下提高或降低码率,可大大降低设计复杂度[1]。
本文设计并实现了码长固定的多速率LDPC码,码长为12960比特,三种码率为2/3,1/3和1/6。与现有码长固定的多速率LDPC设计方法相比[2],本设计直接利用校验矩阵进行系统编码,且在译码过程中采用部分并行译码方式,大大简化了实现难度。
1 多速率LDPC编码器设计与实现
本设计直接利用校验矩阵进行系统编码,不需要把校验矩阵转换成生成矩阵,且有近似于下三角形式的结构,在保证矩阵稀疏性的同时,大大降低编码运算量,便于硬件实现[3]。首先构造一个高码率(2/3)的非规则重复累积码作为母码;然后以该母码为基础,通过同时减少信息位和增加校验位来降低码率。
以码率为2/3的LDPC 码为例作具体说明。其校验矩阵的基矩阵 H16×48如图1所示。扩展因子为270,其中“-1”表示270× 270维的全零矩阵,非负整数表示270×270维的单位矩阵向右循环右移的位数。

图1 码率为2/3的LDPC码的校验矩阵的基矩阵
H16×48可分解为其中HS为16×32的矩阵,行重为8,可表示为
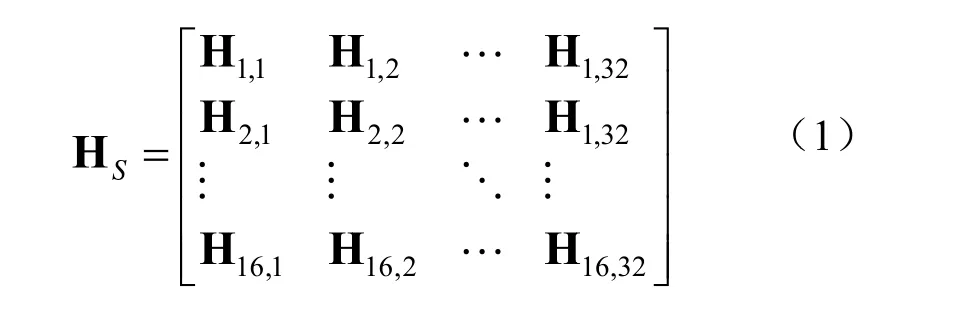
HP为16×16的矩阵,主对角和次对角都是单位矩阵,除了第七行行重为3外,其余行的行重均为2。设码字矢量其中u为信息向量,p为 校验 向 量 , 令其中ui、pj和qj均为270维行向量,1≤i≤32,1≤j≤16。由校验关系分解为:
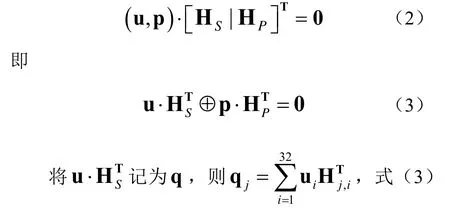
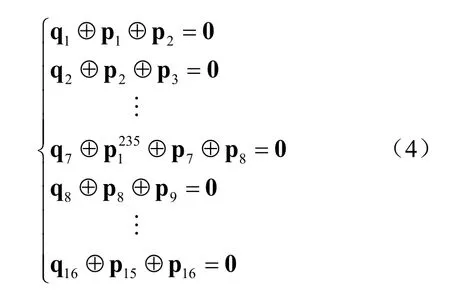
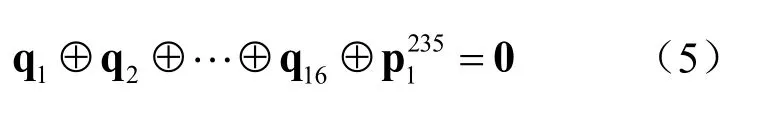
编码过程直接用校验矩阵进行系统编码,并且只需要模2加运算,计算简单,硬件实现方便。
编码器可采用缓存编码结构,可通过接收存储单元来正确处理任意不规律的信息比特流输入,稳定性较强,编码设计结构如图2所示。
根据输入控制信号(码率类型开关、数据有效信号等),控制单元控制接收单元以及内部的移位寄存编码单元有序工作,图2中累加器 AC1~AC3即移位寄存编码累加器,不同码率时,由码率类型开关控制累加器的工作状态和输入比特来源:R=1/6时,AC1、AC2、AC3有效;R=1/3时,AC1、AC2有效;R=2/3时,AC1有效。码率越低,信息长度越短,所需要生成的校验比特越多,对应所需要的AC数量也就越多。
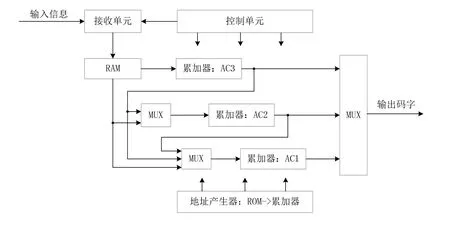
图2 编码器设计结构图
码率R=2/3,将信息序列输入累加器AC1计算校验序列,通过将信息序列与校验序列串行输出实现编码。
码率R=1/3或 1/6时,需要将上一级累加器AC1~AC2的输出序列反馈输入给下一级累加器AC2~AC3,并根据码率选择输出的校验比特序列长度。
多速率编码器的FPGA设计在Xilinx Kintex 7系列的xc7k325t编码器的资源开销如表1所示。

表1 多速率LDPC码编码器资源开销
2 多速率LDPC译码器设计与实现
译码算法是基于和积算法(Sum Product Algorithm,SPA)的简化算法,即归一化最小和算法(Normalized Minimum Sum Algorithm,NMSA),具体步骤为[4]:
(1)接收信道信息,经过量化处理,存储初始的信道似然值。设定初始迭代次数。
(2)校验节点更新。最小和译码算法校验节点更新公式为:
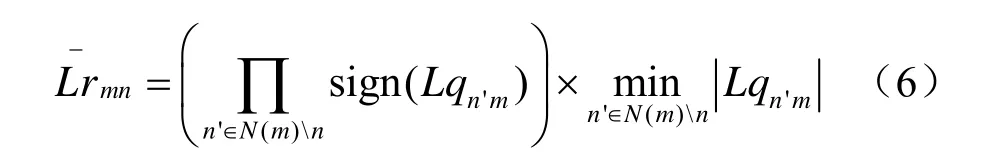
校验节点计算返回值归一化的时候是通过乘以一个小于1的系数α改进性能。此时校验节点的更新公式为:
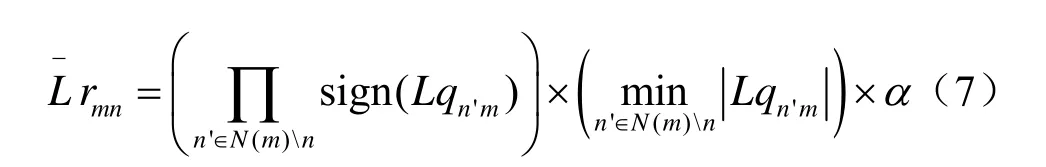
N(m)表示参与第m个校验方程的变量节点的集合,即H矩阵第m行中1的位置;N(m) 表示从集合N(m)中去掉元素n之后的子集。
(3)变量节点更新,迭代次数加1。判断是否达到设定的迭代次数,若未达到迭代次数,转(2)。否则,转(4)。变量节点初始化公式:
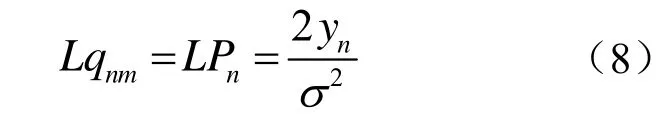
变量节点更新返回值计算公式:
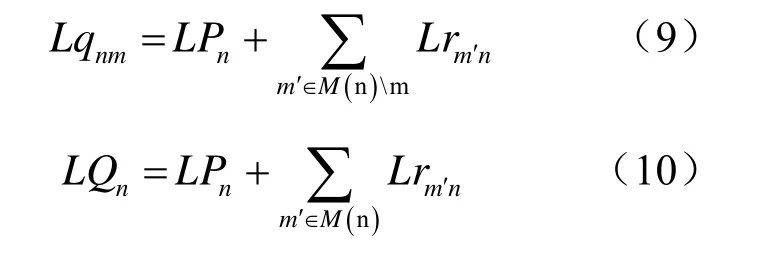
迭代结束,变量节点译码判决:LQn≥0,判决为0,否则判决为1。
M(n)表示与变量节点n相连的校验节点的集合,即H矩阵第n列中1的位置;M(n)m表示从集合M(n)中去掉元素m之后的子集。
(4)计算校验和。若校验和为0,则直接输出结果。否则转(5)。
(5)利用迭代之后的结果以及接收到的新的校验比特,更新原先的初始信道似然值。设定一个新的迭代次数。转(2)。
译码器也采用与编码器设计相似的缓存结构,以处理复杂的输入情况,提升系统的稳定性。主要输入信号包含码率类型开关、数据有效信号和输入软信息等等,由迭代译码控制单元协调各模块的工作,译码器设计结构如图3所示。
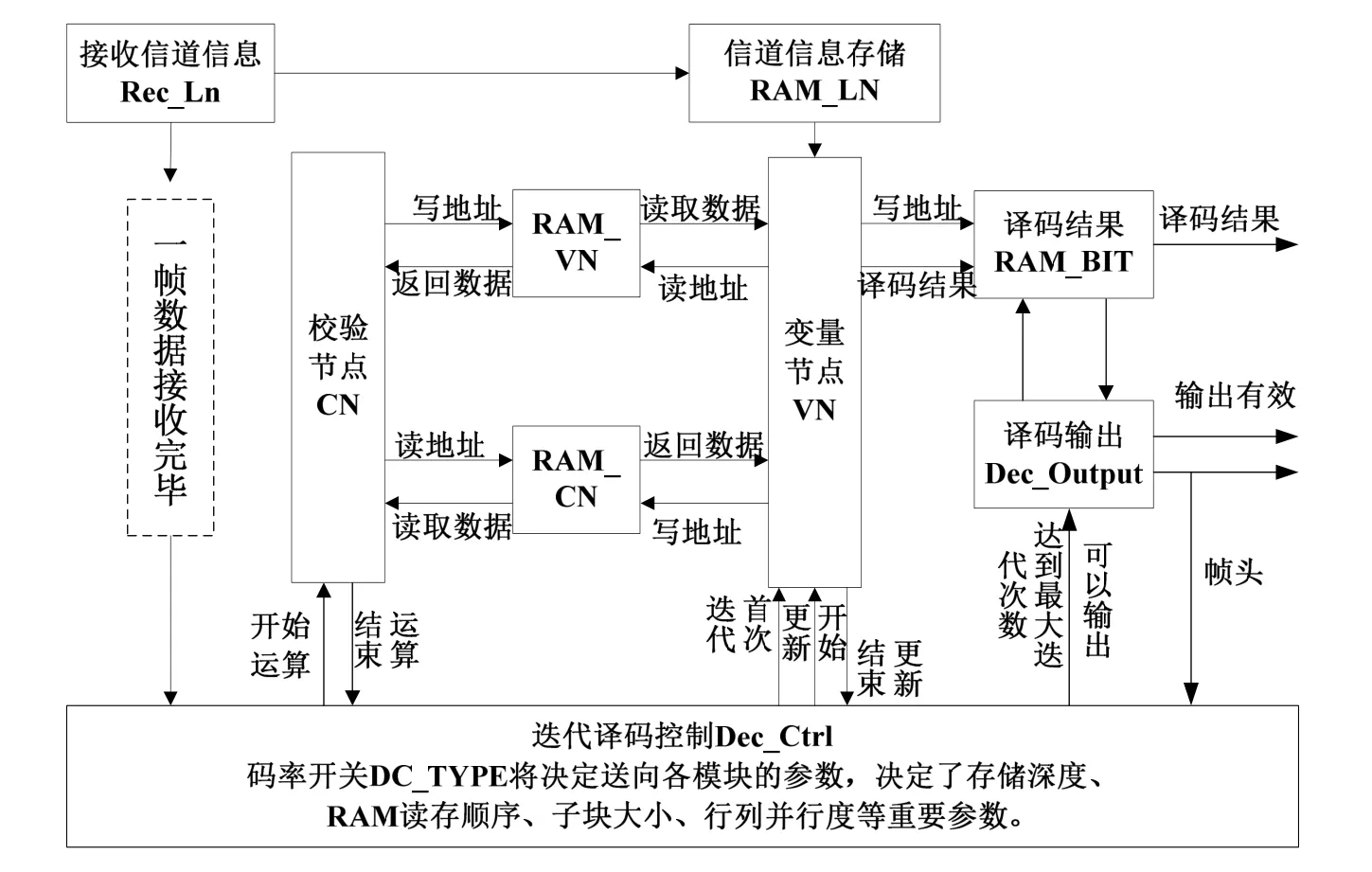
图3 译码设计结构图
硬件译码器是由数据输入缓冲模块、变量节点更新模块、校验节点更新模块、数据输出模块四个模块共同组成。其中,变量节点更新模块与校验节点更新模块属于基本的功能实现模块。数据输入输出模块,以及校验节点、变量节点信息相互传递过程中的存储器模块属于高速译码匹配的存储器模块。译码器采用部分并行译码形式,根据LDPC码的校验矩阵,划分出大小相同的子矩阵,对每一个固定的子矩阵行列组,实现一个变量节点处理单元与一个校验节点处理单元,该译码结构同时兼顾了译码速率与FPGA资源消耗量,是一种首选的译码器的实现结构[5]。
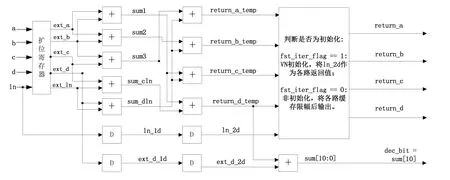
图4 VNU列计算单元设计结构图
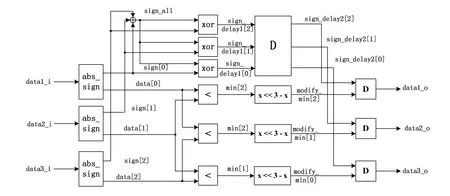
图5 CNU行比较单元设计结构图
VNU列计算单元的设计结构如图4所示。列计算单元是依据式(8)~式(9)设计的,图4中的结构是针对量化位宽为8比特(含1位符号位)。以列重λc=4为例,其他列重情况下根据输入的数据数目(λc+1)来设计加法器的组合。采用相同加法器结构,可有效精简加法器的数量和较少计算时钟的数量。最后根据初次迭代标志信号fst_iter的电平高低来判断是否为VN节点初始化,并返回变量节点更新数据。图4中右下角的寄存器sum即是4个一列非零点输入的数据和信道似然值ln之和,最高位sum[10]就是本列译码判决结果,赋给dec_bit并输出。
校验节点更新(CNU)行比较单元的设计结构,如图5所示。
行比较单元是依据式(7)设计的,图 5中结构是针对量化位宽为8比特(含1位符号位)。以行重3为例,其他行重情况下需要根据输入的数据数目(λr)来设计加法器的组合,目标是精简比较单元的数量和减少计算时钟的数量。
图5中,“abs_sign”模块实现有符号数的符号位与绝对值分离的功能;“Xor”表示异或操作;“<”表示比较输入数据的最小值并输出;“x<<3-x”则实现了式(7)中α= 7/8的数据修正。本文所对应的速率兼容结构体现在校验矩阵的横向扩展上,因此在Cn单元设计时本着行重最大、向下兼容的原则,即所有Cn处理单元设计时候考虑行重最大的情况,即码率最高的情况;当使用低码率时,将矩阵结构中去掉的部分对应的节点数据置为量化数据的最大值:8'b0111_1111,这样使得行比较单元(计算节点数据最小值)有效避开这些“干扰”,计算所用数据全部来自实际码率所对应矩阵结构部分,即实现码率兼容。
多速率译码器的FPGA设计在Xilinx Kintex 7系列的xc7k325t编码器的资源开销如表2所示。
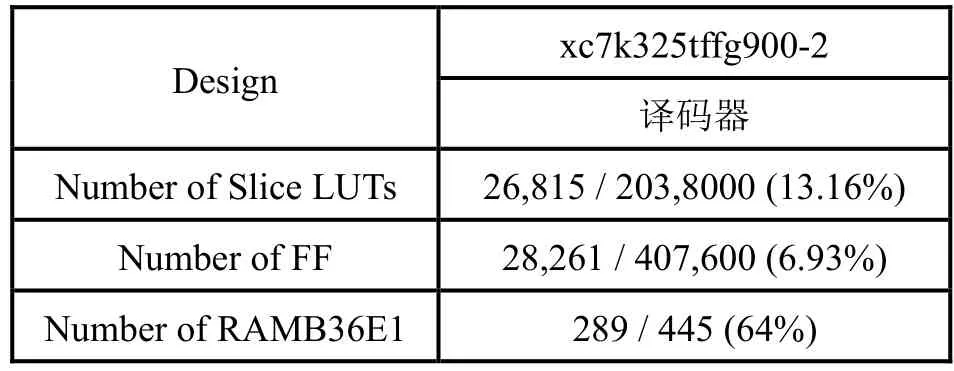
表2 多速率LDPC码译码器资源开销
3 结论
本文设计了一种码长固定,码率灵活可变的多速率LDPC码。在编码过程中采用近似下三角矩阵,直接利用校验矩阵进行系统编码,大大降低编码运算量,便于硬件实现;译码器依据归一化最小和算法设计,采用部分并行译码形式,同时兼顾了译码速率与FPGA资源消耗量。编译码算法都在Xilinx公司的FPGA XC7K325T上成功实现,经在板测试,能够实现设计的所有功能,对工程实践有极大帮助。
参考文献:
[1]Vila Casa do, A.I, Wen-Yen Weng, Wesel, R.D. Multiple rate low-density pari ty-check codeswith con stant blockleng th [A]. Confer ence Record o f the Thirty-Eighth Asilomar Conference on Signals, Syste ms and Computers[C]. Vol.2, pp: 2010 - 2014, 2004.
[2]Xueqin J iang; Yier Yan; Moon Ho Lee. Construction of multiple-rate quasi-cycli c LDPC codes via the hyper plane decomposing [J]. IEEE Communications and Networks,Vol. 13, pp: 205 - 210, 2011.
[3]茅迪.伪随机 LDPC码的编译码器设计及 FPGA实现[D].西安电子科技大学硕士学位论文, 2013.
[4]王育民,李晖,梁传甲.信息论与编码理论[M].北京:高等教育出版社, 2005.
[5]袁瑞佳. LDP C码的高效编译码实现技术研究[D].西安电子科技大学博士学位论文, 2012.
猜你喜欢
电子测试(2022年4期)2022-03-17
沈阳工业大学学报(2021年6期)2021-11-29
现代电子技术(2021年7期)2021-04-08
现代计算机(2021年36期)2021-03-14
科学技术创新(2021年2期)2021-01-21
计算机应用(2018年7期)2018-08-27
科技视界(2018年27期)2018-01-16
时代英语·高一(2017年5期)2017-11-14
科教导刊·电子版(2016年36期)2017-04-22
遥测遥控(2015年2期)2015-04-23
