
指挥控制智能化问题分解研究
2018-04-09 01:08金欣
指挥与控制学报 2018年1期
金欣
从AlphaGo到AlphaGo Zero,人工智能(Arti fi cial Intelligence,AI)在围棋领域发展到了前所未有的高峰.棋类博弈是对战争博弈的高度抽象简化.AlphaGo系列的成功让人们看到了作战指挥控制智能化的曙光.尤其是AlphaGo Zero不依赖于大量人类样本数据,无需人工参与指导,而且还发现了很多人类未曾探索过的围棋定式,让人们觉得AI具有创造力,能媲美甚至超过人类的指挥艺术.此外,AI在即时战略(Real-Time Strategy,RTS)游戏、战术兵棋游戏的斩获,让人们觉得指挥控制智能化势在必行.
然而,真实战场上的博弈要比棋类、网络视频游戏类博弈复杂得多.AlphaGo的AI方法能否直接照搬到作战指挥控制中?RTS游戏中又为何要拆分出很多具体的问题分别研究?指挥控制智能化问题应当采用哪种方法解决?本文试图围绕这些问题进行探讨,并抛出一些不成熟的观点,供业界争论探讨.
1 相关研究现状
围棋、兵棋、RTS游戏是3种典型博弈系统.围棋规则最为简单,但变化之数却相当大.兵棋和RTS游戏的规则要比围棋复杂一些,变化也更多.目前,3个领域的AI发展都非常迅猛,人类均在不同程度上败给了AI.其中,兵棋与真实战争最为接近.在今年的全国性兵棋大赛上,AI以大比分战胜了人类冠军选手.但由于其技术方面的文献不多,以下主要对比分析AlphaGo系列和RTS游戏中AI的不同实现方法.
1.1 AlphaGo及AlphaGo Zero中的AI
2016年3月,AlphaGo战胜李世石,被认为是AI进入新纪元的里程碑事件.2017年初,化名“Master”的升级版AlphaGo以60局全胜的势头席卷了整个围棋界.2017年5月,计算力和网络深度都大幅增长的AlphaGo以3:0完胜世界排名第一的柯洁,为人类智能在围棋上占据了数千年之久的地位画上了句号.2017年10月,AlphaGo Zero在完全没有人类经验的基础上,通过自我博弈学习的方式,达到了更高的境界,以100:0完胜李世石版AlphaGo,并且发现了很多人类未曾探索过的围棋定式,突破了人类迄今为止对围棋的认知局限,达到了前所未有的高峰.相关事件和评论已经很多了,这里不再赘述.
AlphaGo和AlphaGo Zero使用的方法有许多相关解读[1],限于篇幅这里不再赘述.2016年AlphaGo战胜李世石时,就已经在国内掀起了围绕指挥控制智能化发展的研讨热潮[2−5],同时也引发了一些探索性研究[6−9],但研究者们普遍认为AlphaGo的方法难以复制到指挥控制领域,很大部分原因在于缺少足够的作战对抗样本数据.2017年AlphaGo Zero再一次触动了这根神经,原因是它不再依赖于大量人类棋谱,甚至无需人工参与指导,纯粹依靠“自我博弈”的强化学习方式训练而成.这似乎为缺少样本数据的指挥控制智能化难题另辟蹊径——只要建造一个计算机模拟的战争环境,让机器扮演红蓝双方自我交战,就能训练出智能模型,用到实际作战指挥控制中,像AlphaGo那样战胜人类指挥员.
对此,本文表示持疑态度.强化学习确实有不依赖于大量数据的优点,但也存在延迟回报等问题,一般适用于基本规则简单、评判标准明确、效果立竿见影的问题类型.而这些特点在作战指挥控制中都要打上问号.此外,还有一个很重要的问题是复杂度.AlphaGo系列采用的学习方法可以归纳为一种“从头到尾”的学习.对于策略网,“一头”是落子前的盘面布局,“一尾”是落子的位置,用机器学习训练出一张网络,模拟替代棋手复杂的推理计算过程;对于价值网,“一头”是以落子后的盘面布局,“一尾”是最终胜负结局,也是用机器学习训练出一张网络,模拟替代千万种可能的对弈过程.在Zero版中这两张网合并成一张,但学习模式并没有太大变化.这种学习模式能够胜任围棋的复杂度,而能否适用于作战指挥控制的复杂度?下文将会详细分析.
1.2 RTS游戏中的AI
RTS游戏是一类与战争博弈较为接近的游戏.如红色警戒、星际争霸、魔兽世界、帝国时代等,都是以战争博弈为主题.RTS游戏中的AI研究已经系统地开展了许多年[10−15],积累了较大规模的博弈对抗样本数据,形成了用于探索、研究、测试AI模型算法的标准平台和开源的测试软件,有频繁举行的竞赛活动,形成了良好的生态.该领域中的AI已达到了较高的技术水平.阿里多智能体协作网络BiCNet已经学会了避碰协调移动、打跑结合、掩护进攻、集火攻击、跨兵种协同打击等人类常用的协同战术[12],加上计算机精细的微操作控制,目前已达到人类玩家中等水平,未来在人机对战中获胜指日可待.
如果参照AlphaGo“从头到尾”的学习模式,则策略网的“一头”是上一时刻的视频画面,“一尾”是下一时刻采取的行动,价值网的“一头”是下一时刻的视频画面,“一尾”是最终胜负结局.然而,RTS游戏中的很多AI并没有这样设计,而更多的是采用“分而治之”的办法,分解出一些更加细小、专业性更强的决策问题,针对性地设计AI算法[10].这些问题包括战术和战略两级.对于单元战斗行为规划、机动路径规划、协同配合战术规划等战术级决策问题,常用的AI算法包括博弈树搜索、蒙特卡洛树搜索、强化学习等.对于基地和工事建造、战场环境侦察、兵力部署和投送等战略级决策问题,常用的AI算法包括基于案例的推理、分层任务网络、目标驱动的自主性、状态空间规划、进化计算、空间推理等.
2 指挥控制AI问题复杂度分析
AlphaGo系列“从头到尾”的学习模式,和RTS游戏“分而治之”的办法,哪种更适合作战指挥控制呢?这取决于学习对象有多复杂.众所周知,深度学习对样本数据规模的要求是非常高的,而且学习对象越复杂,样本规模要求越大.
围棋的复杂度是10170,这一点早已被探究过.深度学习之所以能够成功,是依赖于规模庞大的样本数据.16万人类棋局规模已经很庞大了,仍然不满足深度学习的“胃口”,因而又采用“自我博弈”方法产生出数千万级别的棋局样本,才得到战胜柯洁的网络模型.AlphaGo Zero用了490万棋局样本,虽然有所减少,可依然是一个庞大的数字.
与围棋相比,RTS游戏的复杂度又提升了许多.文献[11]中对星际争霸游戏的复杂度进行了分析.如果只考虑每个作战单元每时每刻的位置(128×128可选),400个单元的复杂度就达到了101685.如果考虑作战资源、打击点、能源、科技研发等因素,复杂度还要更高.这也是为什么RTS游戏中大部分AI选择“分而治之”的办法.
与RTS游戏相比,真实作战指挥复杂度又要高出数不清的数量级.1)层次更多.RTS游戏只有战略、战术2个层级;而真实战争分战略、战役、战术、平台、火力5个层次.2)作战单元种类和数量更多.星际争霸游戏中,每个种族的兵种大约在20种左右,单元数量上限为200个;而真实战争中,装备种类何止数百,单元数量何止数千.3)单元行为控制更复杂.RTS游戏中向作战单元下达一个行动指令只需要鼠标点击几下;而真实作战指挥中的行动控制指令通过都需要设定大量控制参数.4)战场环境更复杂.RTS游戏中通常只有陆、海、空3种环境,而且环境变化通常只有有限的几种状态;而真实战场上,地形、大气、海况更加复杂,此外还有太空、电磁、网络等更多复杂环境.5)作用机理复杂.RTS游戏中裁决一个打击行动的效果,通常是简单地基于攻防指标计算得到数值;而真实战场上,每个实体行为都有一套复杂的作用机理,涉及到各种各样的装备参数和物理模型.6)评价标准复杂.RTS游戏的评价标准就是输赢;而真实战争中,衡量作战结果有一套复杂的评估指标体系.
复杂度如此之高,相应的是否有更多样本数据呢?答案是否定的.真实战争的代价是任何一个国家都难以承受的.实兵演练的成本很高,且多以科目训练为主,真正的对抗演练数量较少,联合层面的演练就更少.那么有没有可能像AlphaGo Zero那样,打造一个贴近真实战争的模拟博弈环境,通过机器自我交战的方式产生大量样本数据呢?笔者认为这可能是一个方向,但有很大的难度.一方面在于打造模拟真实战场环境的本身是一个挑战,另一方面在于即便打造出来,要做到像围棋那样的快速自我博弈也是困难的.因为围棋推一步对于计算机而言成本几乎为零,而模拟战场上的每一个单元行动造成的结果都是综合大量因素计算出来的,模拟的逼真度越高,需要综合的因素就越多,计算量也就越大,耗时也就越多.总体而言,短期内可用的作战指挥控制样本数量,远远少于围棋和RTS游戏.
综上所述,考虑极高的复杂度和极少的可用样本,认为指挥控制AI不能直接照搬AlphaGo的方法,“从头到尾”的学习模式实现起来难度太大.相比之下,RTS游戏“分而治之”的办法可能更加适合指挥控制.将指挥控制AI分解成更为具体的小问题,并尝试用不同AI方法解决不同具体问题,也许是短期内较好的解决办法.
3 现有AI方法及对应指挥思维模式
纵观现有的各种AI方法,大体可以分成基于知识和基于学习两大类,分别对应于指挥员的理性和感性思维模式.
3.1 基于知识—理性思维模式
包括数理计算、逻辑推理、概率推理等方法.基本原理是将客观事实及相互间作用关系、作用规律定义为知识,并基于数学公式、逻辑或概率的形式符号化,从而运用计算、推理等方法进行预测或求解.基于知识的方法对应于指挥人员的理性思维模式,运用掌握的知识理性地推断和严谨地求证.其代表性应用如计算模型、专家系统.运用这种理性思维和掌握的知识,既可以分析推断敌方的关系、意图和行动,也可以按条令条规推断决策、规划行动、调度资源.其问题在于获取知识较难,需要用机器能够理解的语言“教”会机器.且知识之间多存在冲突,当冲突太多时会影响求解精度,效率也会大幅下降.
3.2 基于学习—感性思维模式
包括基于实例的学习、深度学习、强化学习、迁移学习等学习方法.基本原理是从大规模样本数据中,学习隐含的模型或模式,反过来用于实际问题中进行预测或求解.基于学习的方法对应于指挥人员的感性思维模式,从大量的实践(样本数据)中获得经验直觉.其代表性应用如图像识别、语音识别、自然语言处理等.运用这种感性思维,既可以根据经验直觉判断敌方可能的行为、形势是否有利等,也可以按经验直觉做出快速决策.其问题在于遇到不按套路出牌的情况容易出错,而这在战争中并不少见.另一个问题是机器学习对样本数据的规模和质量要求较高,而真实战争的样本数据往往不容易获得.
传统基于知识的方法在实际应用中遇到了知识难以获取、难以转化应用等瓶颈问题.而另一方面,眼下基于学习的方法在很多领域获得了成功,开始大行其道.然而,“天下没有免费的午餐”,任何一种方法都不能适用于所有问题.RTS游戏中的AI综合运用了多种基于知识和基于学习的方法.指挥控制领域也是如此,采用哪种方法需要具体问题具体分析.
4 指挥控制AI问题分解及方法分析
按“分而治之”的理念,对指挥控制AI问题进行了分解,如图1所示.指挥控制横向覆盖OODA过程,纵向跨认知域、信息域、物理域3个功能域.图1中的曲线表明指挥控制是从信息域出发,经过认知域加工,再回到信息域,进而经过物理域实践,最终又回到信息域的一个周而复始的循环过程.这个循环既包含战前筹划战中实施战后总结的大循环,也包含战中发现情况采取措施执行评估的小循环.
指挥控制AI问题贯穿在这个循环中.首先按OO、D、A切分成3部分,再按照涉及认知域和物理域的深浅,进一步切分成6个子问题.
1)融合处理.接收各路情报信息,同已掌握的信息之间相互进行关联、印证,识别各类战场实体及其行动,生成一幅共用态势图,形成对战场情况一致的掌握理解.AI除了可用于图像、音视频识别理解外,更多是通过构建知识图谱,对人类已掌握的各类目标特征、军事概念、关联关系等知识进行建模,并运用关联搜索、知识推理等方法实现信息内容的自动提取、语义分析、关联匹配,从而将情报参谋人员从海量、多源、异构的信息中解放出来,大幅提升融合处理工作的效率.
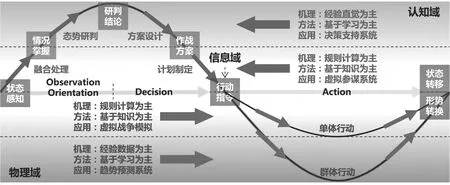
图1 指挥控制AI问题分解
2)态势研判.根据融合处理后掌握的战场情况,理解战场上发生的活动及相互关系、各方势力强弱、重心分布,估计对方作战意图和下一步行动,预测未来战局走势,评估战场态势对己方构成的威胁和机遇,形成态势研判结论,为制定作战决策提供依据.这个层次的研判工作具有较强的主观性,需要辨别欺骗和识别计谋,需要靠直觉判断战场形势利弊,与指挥员的思维习惯和偏好有很大关系.知识很难提炼,很多判断也无法量化,更多地是凭借经验直觉.因此,建议采用基于学习的方法构造AI,类似AlphaGo的价值网,在红蓝对抗中以红方看到的态势为输入,以指挥员的研判结论或蓝方实际的意图为输出,让机器去学习训练构建经验直觉判断模型.
3)方案设计.根据态势研判结论,依据我方控制范围内的可用兵力及环境条件,决定是否采取行动及预期达到的终态,并开展任务分解、目标选定、兵力分配、行动设计、协同组织、保障调配等设计工作,形成若干套候选方案,通过推演分析评估优选,最终定下作战决心.这个层次的设计工作具有较强的艺术性.尤其是“打不打”、“怎么打”之类的问题,是指挥决策艺术的集中体现,掺杂着较多情感因素和指挥风格,并且大量运用创新.因此,建议采用基于学习的方法构造AI,类似AlphaGo的策略网,以战场态势要素作为输入,以指挥员制定的方案要素作为输出,或者根据模拟推演结果建立赏罚函数,让机器去学习训练,逐步优化自己的策略模型.
4)计划制定.根据作战决心,细化分解打击目标、作战行动、兵力编成编组、行动时序路线、协同要求、保障资源分配调度等,制定可实施的行动计划,最终形成可操作的指挥命令序列.这个层次的决策工作主要是将确定的策略落实为可实施的行动计划,以量化的计算为主.例如出动兵力指派是根据各个部队的兵力就绪状态,参考上级制定的兵力使用建议计算得出.再如兵力投送路线规划、交战过程设计、保障物资规划等都是以各种计算、规则、流程为主.因此,这个层次的AI大量采用基于知识的方法,实现大量计算工作自动化,提升计划制定效率.
5)个体行动.每个作战单元执行指挥命令,实施探测、打击、机动、干扰、保障等具体行动,产生物理输出,导致战场状态发生转换.AI主要用于模拟个体行动过程和产生的结果,从而构建一个仿真环境,支撑作战方案推演、战法战术试验和指挥人员训练.各类武器装备在出厂和使用期间都会做大量的实验测试,作战部队也要经过各种训练和演习.个体行动过程通常都有规范的流程和规则约束,行动输出的能力也有大量的实验训练数据可查,可以转换成计算公式,建模相对较为容易.因此这个层面的AI主要是将这些已有的规则、计算、数据建立模型,建议采用基于知识的方法构造AI.
6)群体行动.如编队协同突击、防御,以及联合突击、防御等群体性行为,多个作战单元同时行动、相互作用,形成综合输出,导致战场形势发生转移.AI主要用于模拟综合行动的阶段变化和产生的形势转移效果,用于构建更高层次的战争模拟系统,支撑作战效果的预估和战局走势的预测.群体行为建模比较困难,行动过程和作用效果会受到多方面因素的影响,在不同场合表现也不同.而且大量的影响因子叠加起来形成的规律是非线性的,难以用简单的规则、计算来表达.因此,建议采用基于学习的方法,利用平时演习训练和模拟推演积累的大量数据,学习训练建立复杂群体行动效果的统计概率模型.
总体而言,指挥控制AI适合采用基于知识还是基于学习的方法主要取决于AI层次深度.图1中越靠近信息域的AI层次越浅,越偏向规则、计算等传统的知识形式,因此越适合采用基于知识的方法构造AI.反之,越靠近认知域和物理域的AI层次越深,越偏向经验数据的知识形式,因此越适合采用基于学习的方法构造AI.
5 结论
AI技术的迅猛发展颠覆了很多传统的行业,以机器学习为代表的新方法、新技术让许多过去解决不了的问题有了突破的可能.深度学习、强化学习方法在AlphaGo中的成功应用,让人们看到了指挥控制智能化的曙光.然而考虑战争的高度复杂性,认为AlphaGo采用的技术方法不能够直接照搬到指挥控制领域.分解是将复杂问题简单化的一种有效途径,包括RTS游戏AI领域也是采取将问题分解分而治之的思路.参照这个思路对指挥控制AI进行分解,分出6类指挥控制AI,并分别给出了基于知识和基于学习两类方法的适用性分析建议,作为一种观点,供业界争论探讨.
然而,目前这6类指挥控制AI问题仍然过于粗线条,适用AI方法的建议有些也过于绝对化.到工程实现上还需进一步分解,并结合具体问题具体分析适用的AI方法.本文主要是表达一种理念,供业界去争论探讨.
1 SILVER D,HUANG A,MADDISON C J,et al.Mastering the game of Go with deep neural networks and tree search[J].Nature,2016,529(7587):484−489.
2 王飞跃.复杂性与智能化:从Church-Turing Thesis到AlphaGo Thesis及其展望(1)[J].指挥与控制学报,2016,2(1):1−4.
3 王飞跃.复杂性与智能化:从Church-Turing Thesis到AlphaGo Thesis及其展望(2)[J].指挥与控制学报,2016,2(2):89−92.
4胡晓峰,郭圣明,贺筱媛.指挥信息系统的智能化挑战——“深绿”计划及AlphaGo带来的启示与思考[J].指挥信息系统与技术,2016,7(3):1−7.
5陶九阳,吴琳,胡晓峰.AlphaGo技术原理分析及人工智能军事应用展望[J].指挥与控制学报,2016,2(2):114−120.
6郑书奎,吴琳,贺筱媛.基于深度学习的兵棋演习数据特征提取方法研究[J].指挥与控制学报,2016,2(3):194−201.
7朱丰,胡晓峰.基于深度学习的战场态势评估综述与研究展望[J].军事运筹与系统工程,2016,30(3):22−27.
8蒋晓原,邓克波.面向未来信息化作战的指挥信息系统需求[J].指挥信息系统与技术,2016,7(4):1−5.
9 金欣.“深绿”及AlphaGo对指挥与控制智能化的启示[J].指挥与控制学报,2016,2(3):202−207.
10 ROBERTSON G,WATSON I.A Review of real-time strategy game AI[J].AI Magazine,2014,35(4):75−104.
11 ONTANON S,SYNNAEVE G,URIARTE A,et al.A survey of real-time strategy game AI research and competition in starcraft[J].IEEE Transactions on Computational Intelligence and AI in Games,2013,5(4):1−19.
12 PENGP,YUANQ,WENY,etal.Multiagent bidirectionally-coordinated nets for learning to play starcraftcombatgames[EB/OL].(2017-09-14)[2017-09-16].https://arxiv.org/abs/1703.10069.
13 ADIL K,JIANG F,LIU S,et al.State-of-the-art and open challenges in RTS game-AI and starcraft[J].International Journal of Advanced Computer Science&Applications,2017,8(12):16-24.
14 BURO M,FURTAK T.RTS games as test-bed for real-time AI research[J].Journal of Minimally Invasive Gynecology,2008,21(6):S144-S144.
15 BURO M,FURTAK T M.RTS games and real-time AI research[C]//Behavior Representation in Modeling and Simulation Conference,2004.
猜你喜欢
密码学报(2021年4期)2021-09-14
中学生数理化·高一版(2021年2期)2021-03-19
成都信息工程大学学报(2021年6期)2021-02-12
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
领导决策信息(2018年16期)2018-09-27
数学学习与研究(2017年3期)2017-03-09
初中生学习·低(2016年10期)2016-11-25
作文大王·笑话大王(2016年8期)2016-08-08
小学科学(2015年7期)2015-07-29
