
基于Vivado HLS的求取特征点图像坐标的设计
2018-04-08 02:05:16杨发顺
电子科技 2018年4期
何 凯,梁 蓓,杨发顺
(贵州大学 大数据与信息工程学院,贵州 贵阳 550025)
视觉定位技术是机器视觉研究领域的一个分支,在工业、医疗等领域都有广泛的应用前景,光学定位是其中常见的一种定位技术。本文探讨了一种以被动式光学反射标记物作为特征点的图像坐标求取方法,即以近红外波长反射材料制作靶点,在相机上安装特定的滤光片,以获得特征点明显的灰度图像。此种方案具有鲁棒性强、精度高、使用方便的特点。
特征点图像坐标的获取涉及高斯滤波、二值化、坐标点求取等算法。借助于开源的OpenCV(Open Source Computer Vision)视觉库,在传统串行架构的嵌入式处理器上可以用软件方式轻松实现特征点图像坐标的求取,但该方式存在功耗高、延时长以及数据存储带宽受限等问题。而利用FPGA(Field-Programmable Gate Array)并行求取特征点图像坐标的方式则可以解决上述问题。采用HDL(Hardware Description Language)实现则面临开发难度大、周期长等问题,尤其是算法的时序问题,需要花费大量的时间进行分析、设计、仿真及优化。Xilinx高层次综合工具Vivado HLS(High Level Synthesis)利用有限状态机原理控制算法进程,通过调用与OpenCV视觉库功能对应的HLS视频库,能够快速地将含有OpenCV视觉库的算法程序转化为RTL(Register Transfer Level)硬件。结合Xilinx 高性能和低功耗的Zynq-7000 SoC(System on Chip)处理器平台,通过软硬件协同设计实现对图像处理软件的硬件加速,不仅解决了传统嵌入式处理器处理高清图像时功耗高、延时长、带宽受限等问题,还提高了硬件的开发效率。
1 软件系统设计
Xilinx Vivado HLS利用有限状态机原理控制算法进程,从求取特征点图像坐标的算法程序中提取控制和数据流,通过顶层函数控制流的一些节点,将控制传递到各个子程序中,从而达到并行执行子程序的目的。Vivado HLS本质上是一款软件编译器,通过对算法进行规范以及添加适当的约束指令把相关的OpenCV视觉库算法程序高层次地综合成具有时序和并行性的RTL硬件。
对求取特征点图像坐标进行软件算法设计,首先通过高斯滤波算法对图像进行降噪处理,然后对图像进行二值化处理,以获取该图像的二值图。上述预处理环节均是通过调用OpenCV视觉库中的相关函数来完成的。介于硬件已经对图像背景做了很好的滤除,经过简单的二值化处理,便能获得图像特征点与背景黑白分明的二值图像,最后遍历图像矩阵数据累加大于阈值的像素点的坐标,将累加结果除以像素点数得到对应的特征点图像坐标(x,y)。经过仿真验证后在ARM处理器上实现求取特征点图像坐标的功能。求取特征点图像坐标算法结构图如图1所示。

图1 求取特征点图像坐标算法结构图
为了规划算法在Zynq SoC架构上的实现,文中对ARM软件实现方式进行测试。当系统工作在666.6 MHz频率时,处理像素为1 280×1 024的图像。取20帧求平均时间,记录主要处理步骤的执行时间,记录结果如表1所示。

表1 ARM软件实现主要处理步骤执行时间
由表1数据可以看出,在ARM平台软件实现中,高斯滤波、二值化处理、求取坐标等过程共消耗337.2 ms,占据了系统大量的处理时间,导致整个系统的处理速率降低。本文提出的设计将对计算量较大的处理环节进行硬件加速,从而达到提高系统的处理速率的目的。
在Vivado HLS上对求取特征点图像坐标的算法程序进行硬件加速,需对程序进行算法规范。为了与HLS视频库处理机制相匹配,将原程序改写成基于视频数据流链的算法程序。在预处理环节中,OpenCV视觉库函数中的高斯滤波和二值化程序包含了Vivado HLS 在编译时不能综合的动态内存分配、浮点运算等,因此需要用功能相同的HLS视频库函数进行替换。由于HLS视频库中的高斯滤波、二值化处理等函数与OpenCV视觉库中相应功能的函数具有相似的接口与算法,为适应FPGA的并行架构,对HLS视频库函数进行了浮点运算转化成定点运算、片上行缓存、窗口缓存等优化。预处理后的图像交由求取特征点图像坐标环节进行加速处理。需要注意的是,与ARM软件实现代码不同,编写可加速代码的过程中不能包含任何运行时动态存储器分配,必须在代码中明确描述算法使用的所有存储器阵列,并通过手工添加约束优化系统结构,使算法模块符合AXI(Advanced eXtensible Interface)协议标准。在该设计中,定义了3个大小为1 280×1 024,HLS_8UC1的图像内存,将算法处理过程中的图像映射到存储单元,并将(x,y)坐标及return的接口设置Saxi_AXILiteS模式,输入图像的接口设置为axis模式。坐标求取环节主要实现遍历累加大于阈值的像素点的坐标,并将累加结果除以像素点数以求取对应的特征点图像坐标(x,y)的功能。将此环节放置于HLS视频库函数链之后,预处理后的图像数据由求取坐标环节消耗,并输出特征点图像坐标(x,y)。求取特征点图像坐标算法硬件加速设计流程图如图2所示。

图2 求取特征点图像坐标算法硬件加速设计流程图
该设计通过dataflow指令对硬件加速模块进行优化,主要指示Vivado HLS通过并行方式安排执行该函数的所有子函数,从而达到缩短延时、提高吞吐率的效果。利用编译器对软件进行RTL实现,在RTL/C++协同仿真验证阶段,取20帧图像并求取特征点图像坐标的结果进行对比分析,图像坐标(x,y)的值精确到小数点后3位。试验验证表明,两种实现方式的仿真结果相同。验证后编译器以AXI兼容的方式对IP核进行封装,封装过程中编译器自动生成IP核的软件驱动,从而完成整个求取特征点图像坐标模块(Coordinates)的IP核设计。整体求取特征点图像坐标算法硬件加速设计流程如图3所示。
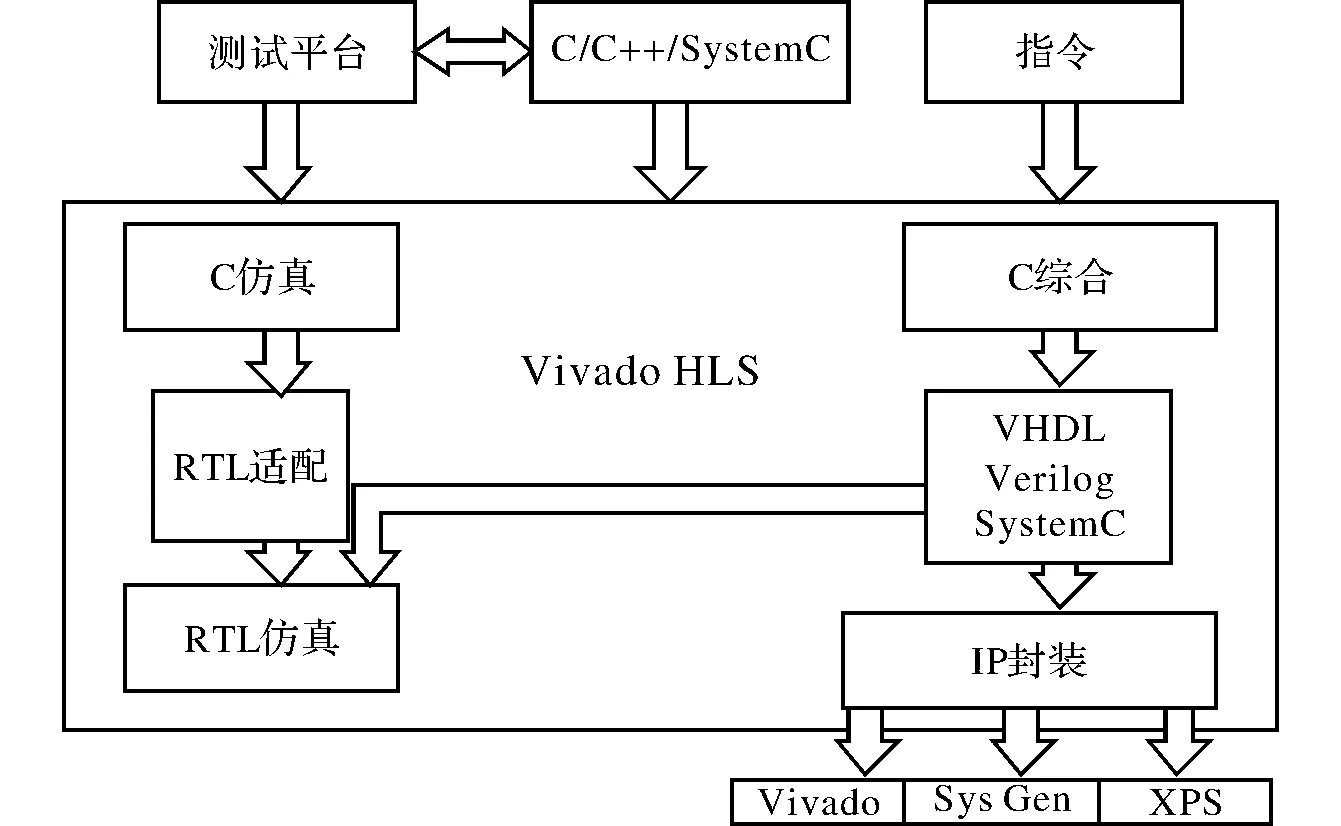
图3 整体求取特征点图像坐标硬件加速设计流程图
求取特征点图像坐标算法经Vivado HLS综合后,统计了其在XC7Z020-2CLG400I 器件FPGA部分的资源占用率,如表2所示。
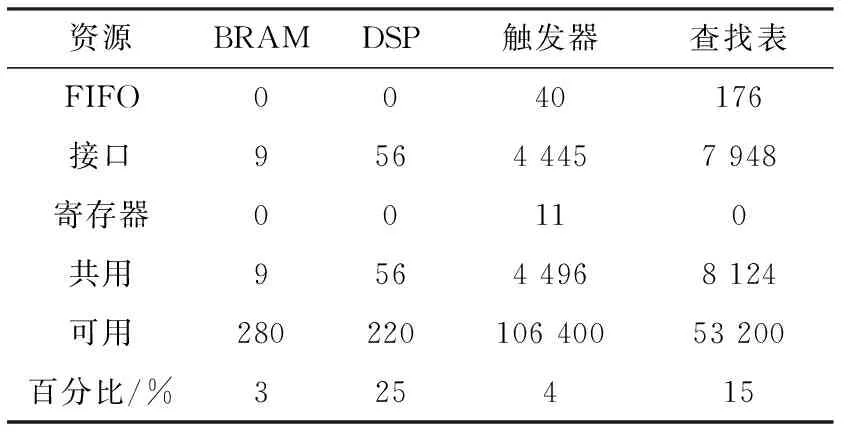
表2 PL部分的资源占用统计表
2 硬件系统设计
Zynq SoC融合了通用嵌入式单元(Processing System,PS)和可编程逻辑单元(Programmable Logic,PL)两种架构。PS包含双核ARM Cortex A9处理器及一些关键外设;而PL实际上是Xilinx 7系列的FPGA,可作为PS外设的一部分,用于扩展处理平台。Zynq SoC启动流程与FPGA不同,但与传统ARM处理器类似,支持JTAG、NAND、parallel NOR、Serial NOR(Quad-SPI)以及SD卡等启动方式。该设计采用Basler GigE相机,需要Linux系统作为装载驱动的平台,因此Zynq SoC采用SD卡启动方式:(1)将SD卡分为卷标rootfs的EXT3格式与卷标BOOT的FAT32格式的两区并格式化,将Linaro Ubuntu文件系统放进SD卡的rootfs分区;(2)根据系统需求添加PS的SD卡千兆以太网等外设并完成系统的模块设计(Block Design),将仿真综合后生成的二进制比特流文件(systerm.bit)导入Vivado SDK(Software Development Kit)与第一阶段引导文件(fsbl.elf)、Linux系统的启动文件(u-boot.elf)合成加载启动任务的文件(Uboot.bin);(3)根据配置修改内核文件并编译生成二进制的Linux内核镜像文件(uImage),依据内核配置裁减设备树文件生成二进制设备树文件(devicetree.dtb);(4)将Uboot.bin、uImage、devicetree.dtb3个文件放入BOOT分区,构建基于Zynq SoC的板载系统。在系统规划中,PS主要负责抓取图像与控制系统进程;计算密集型数据则由PL加速处理。利用Zynq SoC完成求取特征点图像坐标系统的搭建,具体过程如图4所示。
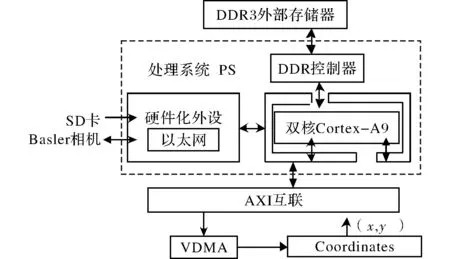
图4 特征点图像坐标求取系统
2.1 PS部分实现的功能
PS处理系统抓取图像与控制系统进程功能主要分为5个流程实现,具体流程如下:
(1)运行Linaro Ubuntu板载系统,为上层应用提供Linux操作系统支持;
(2)在PS中安装Basler Pylon驱动程序软件包,从Basler相机中抓取图像并存储到PS和PL共用的DDR3存储芯片中;
(3)通过调用Vivado HLS 自带的VDMA(Video Direct Memory Access)视频存储器直接访问IP核驱动程序实现对读写过程中的通道控制;
(4)装载OpenCV视觉库,运行OpenCV软件算法程序;
(5)运行软件控制整个系统的进程。
图像采集使用的是Basler GigE千兆网工业相机,该相机配有e2v EV76C661 CMOS 感光芯片,帧率可达 60 fps,130万像素。该相机具有较低的延迟和抖动时间,GigE每秒数据量超过100 MB,能够快速传输高清图片无需担心带宽问题。实际操作中,将相机与PS端的以太网口相连,在板载系统中安装相机驱动程序软件包;设置板载系统的IP地址与相机IP在同一个网段,编写并调试软件抓取图像,并将抓取的图像存储在PL、PS共享的DDR3内存中。
2.2 PL实现的功能
PL加速处理密集型数据功能主要分为以下3个流程完成:
(1)将生成的Coordinates IP核加入PL中,并与其他模块相连接;
(2)通过软件调用VDMA从PL、PS共享DDR3存储芯片中读取图像并传输至Coordinates IP核中进行加速处理;
(3)加速处理完成以后计算出特征点的图像坐标,将坐标(x,y)的输出设定为S_axi_AXILiteS模式,与PS端的AXI互联总线连接,则可用MMAP函数将设备映射到内存,然后直接操作虚拟地址从Coordinates IP核的寄存器读取(x,y)的像素值。
在Zynq SOC内部,PS和PL共享DDR3控制器。PS访问DDR3内存较为简单,只要操作DDR3内存映射的虚拟地址即可。对于PL而言,要接入DDR3,必须通过遵循AXI协议AXI_HP端口。该设计采用Xilinx官方提供的VDMA IP核,VDMA是一种遵循AXI协议的软核IP,可以实现双缓冲和多缓冲机制,并且能够直接与AXI_HP端口相连。VDMA数据接口可以分为读、写通道,使用时可以通过写通道将AXI-Stream类型的数据流写入DDR3,通过读通道可以从DDR3读取数据,并以AXI-Stream类型的格式输出。VDMA本质上是一个数据搬运IP,为数据进出DDR3提供了一种便捷的方案。
3 计算性能对比
RTL/C++联合仿真验证表明,经算法规范加速后,两种实现方式的仿真结果完全一致。为了直观体现硬件加速的效果,文中对比两种实现方法的执行时间。系统中Basler 相机分辨率为1 280×1 024,帧率达到60 fps。取五帧图像进行对比,ARM 工作时钟设置为666.6 MHz,FPGA工作时钟设置为100 MHz,不同实现方式执行时间如表3所示。

表3 不同实现方式所需时间对比
由表2可知,若将相机获取图片以及硬件加速时传输图像的时间都计算在内,Zynq SOC硬件处理系统每帧的平均时间为33.1 ms,而ARM软件处理系统每帧的平均时间为353.3 ms。整个系统用Zynq SOC硬件实现求取特征点图像坐标算法比ARM软件实现要快9倍。若仅从算法的处理时间上看,包括高斯滤波、二值化、图像坐标求取步骤,硬件处理算法仅耗时10.2 ms,比软件处理算法的335.8 ms要快33倍。
4 结束语
本文提出了一种基于Vivado HLS开发工具来对软件程序进行硬件加速的解决方案。借助于Xilinx的Vivado HLS 开发工具设计了求取特征点图像坐标的硬件加速单元,并在Zynq SOC上完成整个系统的设计。通过对比不同系统下软硬件实现的执行时间,可以看出硬件加速方案显著提高了系统的计算性能,而通过采用软硬协同设计的方法大大降低了系统硬件的开发时间。该方案对计算密集型软件算法的优化具有一定参考价值。
[1]张展,崔晋伟,陆炯.基于Xilinx Vivado HLS的小型无人机平衡仪设计[J].电子科技,2015,28(7):151-154.
[2]周体民,佐风玲,吴宜轩,等. 基于Zedboard的便携式频谱仪的设计与实现[J].电子科技,2017,30(7):139-145.
[3]彭习武,张涛. 基于Vivado HLS的边缘检测硬件加速应用[J].电子应用技术,2017,43(5):70-73.
[4]丁帅帅,柴志雷.基于HLS的SURF特征提取硬件加速单元设计与实现[J].微电子学与计算机,2015,32(9):133-143.
[5]郭丰收.Xilinx FPGA/Zynq设计中使用HLS实现OpenCV的开发流程[J].电子产品世界,2014(2-3):50-52.
[6]李振宇.基于PL-PS架构的图像处理系统的实现与算法应用[D].济南:山东大学,2016.
[7]何宾.Xilinx FPGA设计权威指南[M].北京:清华大学出版社,2014.
[8]党宏社,王黎,王晓倩.基于Vivado HLS的FPGA开发与应用研究[J].陕西科技大学学报,2015,33(1):155-159.
[9]张俊涛,王园伟,庞多.一种硬件加速OpenCV的图像处理方法研究[J].微型机与应用,2015,34(22):41-43.
[10] 张艳辉,郭洺宇,何宾. Vivado HLS嵌入式实时图像处理系统的构建与实现[J].电子技术应用,2015,34(22):115-121.
[11] 焦再强.基于Zynq-7000的嵌入式数字图像处理系统设计与实现[D].太原:太原理工大学,2015.
[12] 陆佳华,江舟.嵌入式系统软硬件协同设计实战指南[M].北京:机械工业出版社,2013.
[13] 陆启帅,陆彦婷,王地.Xilinx Zynq SoC与Linux嵌入式设计实战指南[M].北京:清华大学出版社,2014.
[14] 郭晖,陈光.基于OpenCV的视频图像处理应用研究[J].微机型与应用,2010,29(21):14-20.
[15] 姬生毅.基于Zynq的嵌入式数字图像传输系统的设计与实现[D].西安:西安电子科技大学,2014.
[16] 杨晓安,罗杰,苏豪,等.基于Zynq-7000高速图像采集与实时处理系统[J].电子科技,2014,27(7):151-154.
猜你喜欢
英语文摘(2021年10期)2021-11-22 08:02:26
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
摄影之友(影像视觉)(2019年3期)2019-03-30 01:36:58
铁道通信信号(2018年2期)2018-04-18 12:18:23
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
电镀与环保(2016年3期)2017-01-20 08:15:32
精品(2015年9期)2015-01-23 01:36:01
单片机与嵌入式系统应用(2014年9期)2014-03-11 15:35:13
自动化博览(2014年4期)2014-02-28 22:31:15
