
基于快速MFCC计算的说话人识别系统的设计
2018-04-08 02:05:14毕灶荣童东兵陈巧玉
电子科技 2018年4期
毕灶荣,童东兵,陈巧玉
(1.上海工程技术大学 电子电气工程学院,上海201620;2. 上海立信会计金融学院 统计与数学学院,上海 201620)
一般把基于人体固有生理特性和行为特征的识别技术,统称为生物认证识别技术。生物识别的一个重要研究方向是语音识别,和其他生物识别相比,语音识别会有方便、自然、对设备没有较高的要求等优势。语音作为人类沟通交流最常用的媒介,其包含了较多的信息内容,例如:性别、大概的年龄段、以及说话人来自哪里,可以通过分析这些个人信息来推断出说话者的身份,而在很多场景下说话人的身份往往比他要表达的意思更重要。因此,说话人识别是语音识别的一个重要分支,是为了解决说话人是谁的问题。
近年来,说话人识别引起了专家学者的广泛关注。文献[1]研究了深层神经网络框架和转换MFCCs,并为说话者的年龄和性别分类,通过使用转换的MFCC使总体分类精度提高约13%。文献[2] 研究了信号削弱对说话人识别的影响,并提出了一个简单而有效的削波检测方法以及基于深度神经网络(DNN)的信号重建方法。文献[3] 提出了说话人识别的新特征即嘴唇的形状及运动变化,实验结果表明通过训练识别精度达到了99%。文献[6]对几种语音特征参数进行了分析,实验结果表明MFCC与差分MFCC参数结合的识别率最高,线性预测倒谱系数(LPCC)的识别率最低。文献[7]中作者在标准LPCC的基础上通过对分帧语音信号进行小波处理,提出了改进的LPCC参数,在识别的成功率上有了一定的提高。
本文在标准MFCC计算的基础上提出了改进的计算方法,实验结果表明本文所提出的方案在单帧内存访问时间上减少 83.6%,在保证识别准确率不降低的情况下使识别速度大幅提高,降低了说话人识别计算的复杂性。
1 系统总体设计
本文是基于LabVIEW搭建的说话人识别系统。实现对声音的预处理、特征参数的提取、建立参考模板、模板匹配和判决5个功能。系统包括入库阶段和识别阶段。入库阶段完成对说话人的特征参数提取,对每一个测试者建立模板;识别阶段将实时采集到的语音信号的特征参数值与模板中的特征参数值进行匹配,根据动态时间规整(DTW)算法计算出的结果给出判决。图1描述的是说话人识别的系统框图。

图1 说话人识别系统框图
2 系统设计方法
本文设计的说话人确认系统有软、硬件两部分组成。硬件部分是声卡完成对语音信号的采集,并将模拟信号转换成数字信号之后输入给计算机。软件部分是实现对语音数字信号的预处理、特征参数提取、建立模板、匹配模板等功能。
2.1 系统硬件部分
近几年来,随着计算机等相关硬件的快速发展,集成声卡的数据采集能力得到了很大的提升,已经成为一款很出色的音频采集系统。它能够采集频率在20~20 000 Hz范围内的语音信号,可以通过相关软件如MATLAB、LabVIEW来建立语音采集系统,在工程测量领域作为信号采集设备,具有普及的应用远景。本文直接采用声卡作为该系统的硬件部分。
2.2 系统软件部分
本系统是基于LabVIEW编程软件搭建的,众所周知LabVIEW的优势就在于控制,但对于大量数据的计算,LabVIEW就会显得有些力不从心,语音信号的MFCC特征参数提取需要用到大量的数学计算,而Matlab恰好在数值计算上具有较大的优势。所以本系统是在LabVIEW和Matlab结合下完成的。LabVIEW采用的版本为LabVIEW 2013,Mtalab采用的版本为Matlab 7.0。
仿真实现的内容包括语音信号的预处理、入库以及识别3个模块。在仿真的界面中会展示实时采集的信号波形图、当前声音强弱的特征图、MFCC特征参数曲线图、DTW识别主界面和DTW识别结果。系统的前面板如图2所示。
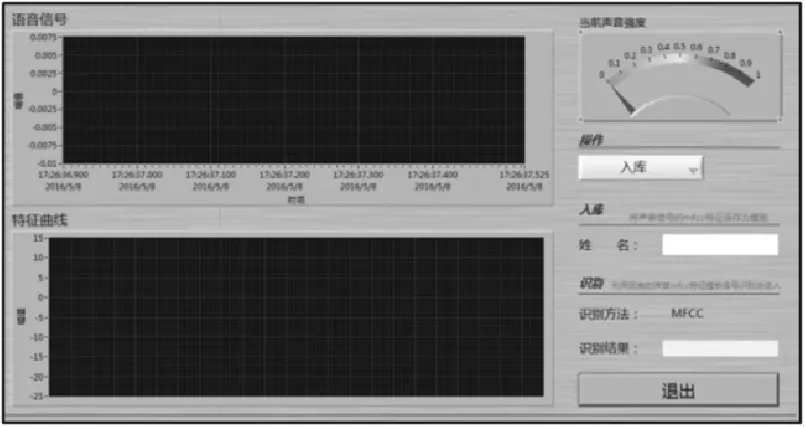
图2 系统前面板
实时采集过程如下:当对着麦克风发出一段语音,语音通过麦克风,传送到声卡形成一段经过采样、保持、转换的数字信号,然后以wav文件格式储存于计算机内存中。
实时语音采集信号采集过程中,可根据实际需要更改采集的语音信号格式,如采样频率、通道数以及每采样比特位数等,还可设置设备ID及采样模式等。语音信号具有的“短时平稳”状态特性,在研究分析语音信号时,经常需要基于“短时平稳”特性来开展。一般情况下,通过采集设备获取的语音信号需要先经过预处理,以便减小计算量,从而提取更有效的说话人的特征参数。预处理过程通常包括:预加重、分帧、加窗、端点检测。
说话人识别的一个重要的步骤就是语音信号的特征参数提取,其对系统识别结果的真实性和有效性起到了重要的作用。语音特征参数提取的基本思想就是让预处理过的语音信号通过设定好的函数,经过变换将冗余去除,提取出特征参数。
目前常见的语音特征参数有:MFCC、LPCC、谱熵、基因周期等。MFCC是模拟人的感知听觉特性,而LPCC则是模拟人的声道特征。
(1)标准MFCC。图3描述的是标准MFCC求解过程。首先将预处理的语音信号进行快速傅里叶变换,然后将求得离散功率谱通过Mel滤波器组并对其求对数得出系数,最后将系数进行离散余弦变换得出标准MFCC倒谱系数。图4为标准MFCC特征曲线图。

图3 标准MFCC倒谱系数求解过程
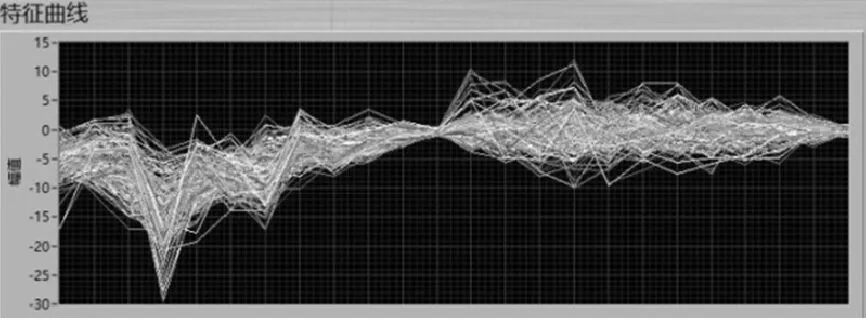
图4 标准MFCC特征曲线
(2)差分MFCC。在一定程度上,差分倒谱系数能够描述人耳感知特性的动态连续特性,其在用于语音处理中取得了较好的效果,差分MFCC的计算采用下式
(1)
其中,k为确定常数且k取2;d(n)表示一帧语音的差分Mel倒谱系数。
(3)改进MFCC。Mel滤波器为三角形结构,其中一个滤波器峰值频率的位置位于上一个滤波器端点频率处,即Mel滤波器的峰值频率为两块峰值频率中任意一块,滤波器左半部分与前一个滤波器右半部分一致,类似的右半部分与后一个滤波器的半部分一致。单一能量谱E(i)与两个滤波器相关,通过乘法器可以得到一个滤波器的能量,其他的能量可以通过减法器得到,所以滤波器模型只需一个乘法器和一个减法器即可。标准MFCC滤波器仿真如图5所示。

图5 标准MFCC滤波器仿真图
设计Mel滤波器需了解滤波器块的滤波系数。Mel滤波器在Mel域是等距,当被映射到线性频域,通过图5可知Mel滤波器为三角形结构,但并不等距。假定滤波器系数的增量是恒定的,每一个滤波器块可以通过存储以下3个值来描述,从而减少内存访问的时间。
第一个系数:每个块的第一个系数的值。
增量:滤波器系数值的平均增量。
系数个数:块中系数的总数。
通过第一个系数的值和增量可以计算出其他所有系数,在每个滤波器结束处需要标记其所需要的系数的个数。这种配置需要3个存储器,由于需要同时访问这3个值,所以为3个存储器赋予相同的地址。系数的个数反馈送到递减计数器,递减计数器在每个计算周期后递减,并且当其等于零时,指示块的结束。通过每次增加增量来计算滤波器块的权重,然后将其乘以能量谱样本E(j)。为了计算在相同块中的相邻滤波器中的能量,可以通过E(j)减去该值。该系统的具体实施如图6所示,以及改进MFCC特征曲线如图7所示。
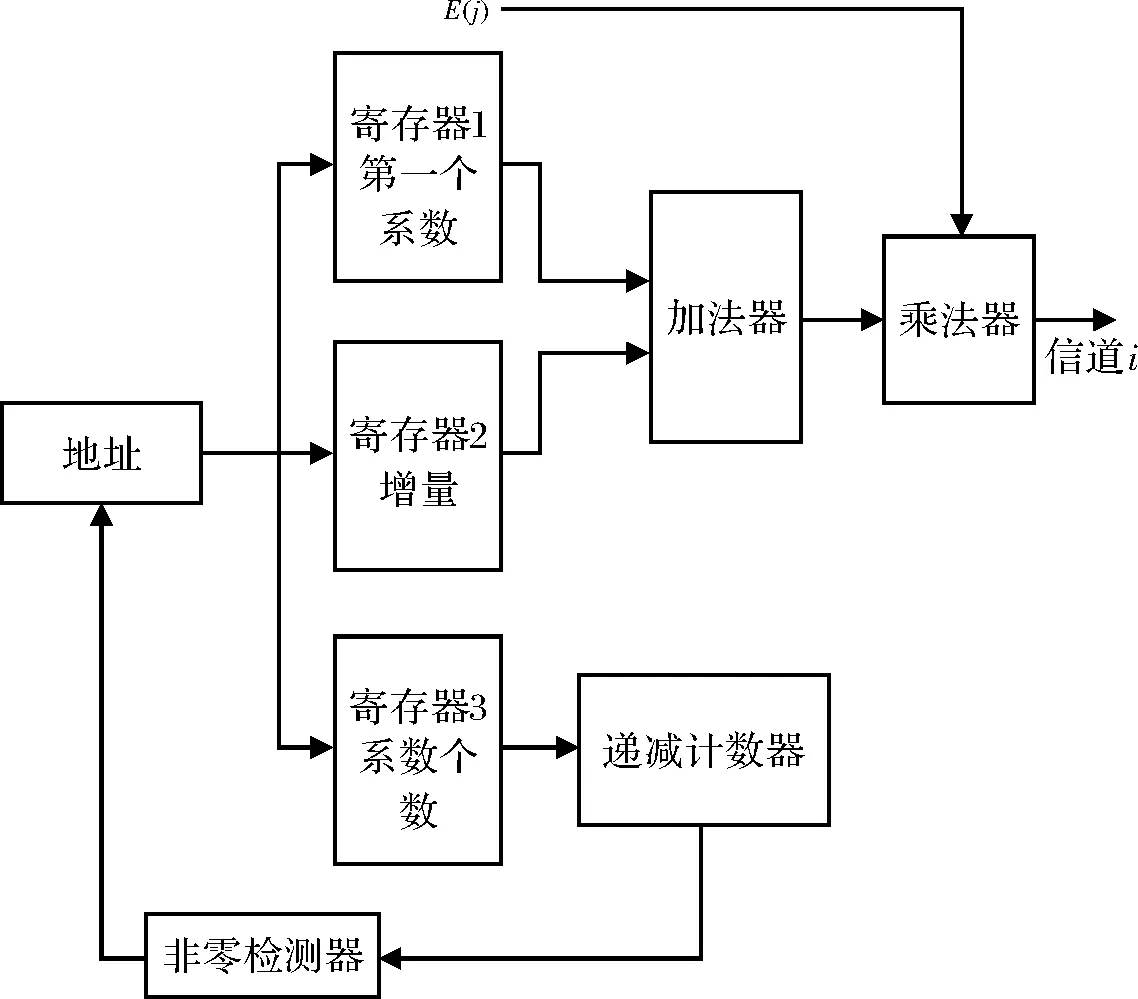
图6 改进Mel滤波器的设计
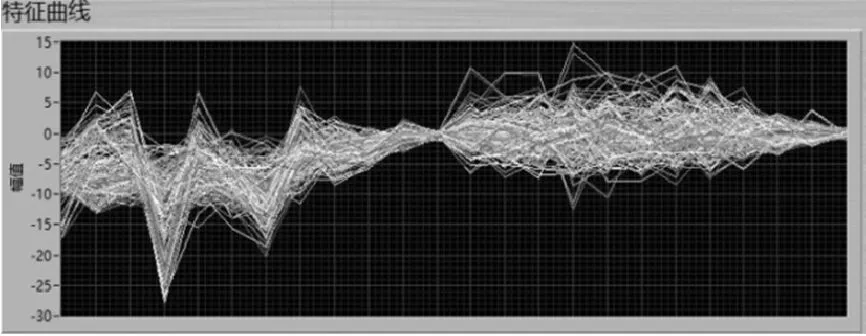
图7 改进MFCC特征曲线
动态时间规整思想是将未知量伸长或缩短(压扩),直到与参考模板的长度一致。假设设定好的模板的特征矢量为x1,x2,…,xi,待测的特征矢量为y1,y2,…,yi,其中,i和j不相等。通过DTW算法找到最佳路径j=w(i),将测试矢量的时间轴i非线性的映射到参考模板时间轴上,使得总失真到达最小,记距离测度为D,其表达式为
(2)
实现过程可以分成两个步骤进行:(1)通过计算两个模板之间各个特征矢量间的距离来构成一个距离矩阵;(2)运用DTW思想在距离矩阵中找出最佳的路径,使得累加距离最小。
3 结果分析
在基于资源要求的性能比较实验中,本文提出的方案与文献[4]中实施的标准MFCC方案和文献[5]中提出的改进方案的性能比较总结在表1中。
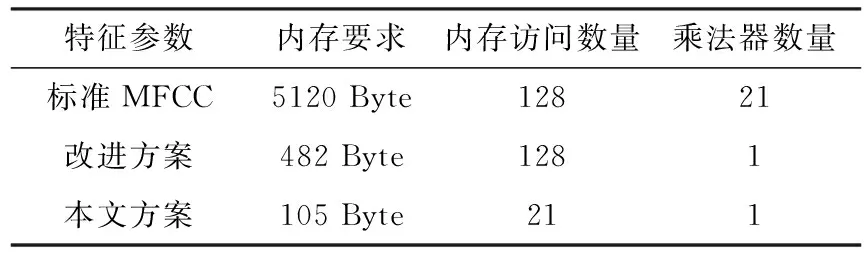
表1 基于资源要求的性能比较
标准MFCC算法中,对于F(帧的大小)为 256和M(滤波器通道数) 为 20的帧,该算法将需要20个存储器和20个乘法器并且存储器具有128 Byte。对于较大的帧大小,如F为1 024,则需要20 kB的内存。因此,在单帧计算中,处理存储器的总时间将等于存储器访问时间的F/2倍,存储器延迟将导致的计算速度降低。
文献[5]提出的改进方案中强调存储滤波器系数中非零值,即需要482 Byte大小的存储器存储241个值。对于本文所提出的方案,第一系数值和增量可以是2 Byte大小,所需的存储器大小为105 Byte。这是标准MFCC计算中所需的存储器的2.05%也是改进MFCC计算中所需的存储器的21.78%,同时帧的大小保持1 024恒定。在单帧内存访个数上仅为21,这将使访问时间减少83.6%。
说话人识别实验在实验室环境下进行。录制30个人的声音,每人录制一句:“上海工程大。”分别采用标准MFCC特征参数,以及本文提出的改进MFCC计算对30个语音信号的特征参数进行提取并入库如图9所示。识别阶段采用同样30个人录制声音,让30个语音信号依次通过识别系统,判断准确率并记录系统识别所需时间,如图10所示。
图9 说话人识别系统入库环节仿真图

图10 说话人识别系统识别环节仿真图
实验结果表明,对于两种算法系统都能够较好的完成说话人识别,但在识别的速度上还是有较大的差距。
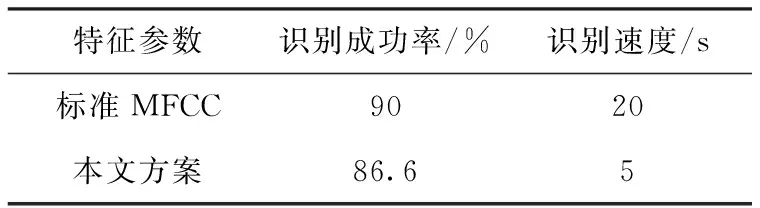
表2 基于说话人识别成功率与速度的比较
经过30个样本测试,采用标准MFCC特征参数的识别成功率为90%,而采用本文改进MFCC识别的成功率为86.6%,降低了3.4%,但是在识别速度上带来了75%的提升。
4 结束语
本文所提出的MFCC计算方案具有较高的计算效率。为MFCC语音识别系统的设计者提供了参考,在牺牲最小精度的条件下,更快地产生了结果,并降低了硬件要求和成本。
[1]Qawaqneh Z, Mallouh A A, Barkana B D.Deep neural network framework and transformed MFCCs for speaker’s age and gender classification[J]. Knowledge-Based Systems, 2017,115(3):5-14.
[2]Bie F, Wang D, Wang J, et al. Detection and reconstruction of clipped speech for speaker recognition[J]. Speech Communication, 2015, 72(2):218-231.
[3]Lai J Y, Wang S L, Liew W C, et al. Visual speaker identification and authentication by joint spatiotemporal sparse coding and hierarchical pooling[J]. Information Sciences, 2016, 373(1):219-232.
[4]Bahoura M, Ezzaidi H. Hardware implementation of MFCC feature extraction for respiratory sounds analysis[C].Zeralda:International Workshop on Systems, Signal Processing and Their Applications,IEEE, 2013.
[5]贺玲玲,周元. 基于改进MFCC的异常声音识别算法[J]. 重庆工商大学学报:自然科学版, 2012,29(2):52-57.
[6]刘雅琴,智爱娟. 几种语音识别特征参数的研究[J]. 计算机技术与发展,2009,19(12):67-70.
[7]王彪.一种改进的LPCC参数提取方法研究[J]. 电子设计工程,2012,20(6):29-30.
[8]李泽,崔宣,马雨廷,等. MFCC和LPCC特征参数在说话人识别中的研究[J].河南工程学院学报:自然科学版, 2010, 22(2):51-55.
[9]朱少雄. 声纹识别系统与模式匹配算法研究[D].大连:大连理工大学, 2005.
[10] 范长青.小词汇量非特定人连续语音识别系统的研究[D]. 沈阳:沈阳理工大学, 2008.
[11] 张伟伟,杨鼎才.用于说话人识别的MFCC的改进算法[J].电子测量技术,2009,32(8):118-121.
[12] Xie C, Cao X, He L. Algorithm of abnormal audio recognition based on improved MFCC[J]. Procedia Engineering, 2012, 29(4):731-737.
[13] Chia Ai O, Hariharan M, Yaacob S, et al. Classification of speech dysfluencies with MFCC and LPCC features[J]. Expert Systems with Applications, 2012, 39(2):2157-2165.
[14] 郭春霞,裘雪红. 基于MFCC的说话人识别系统[J].电子科技, 2005(11):53-56.
[15] 吴佳龙,李坤,刘中.孤立词语音识别算法研究与设计[J].电子科技, 2015, 28(2):22-25.
猜你喜欢
计算技术与自动化(2024年3期)2024-10-10 00:00:00
中国特种设备安全(2021年5期)2021-11-06 05:09:00
装备制造技术(2021年4期)2021-08-05 07:39:54
北京航空航天大学学报(2021年6期)2021-07-20 07:24:00
电子制作(2019年11期)2019-07-04 00:34:38
电子制作(2018年16期)2018-09-26 03:26:50
制造技术与机床(2017年11期)2017-12-18 06:46:39
火控雷达技术(2016年2期)2016-02-06 02:29:00
电测与仪表(2015年7期)2015-04-09 11:40:04
环球时报(2014-06-18)2014-06-18 16:40:11
