
增强学习基本模型及其分析
2018-04-03 07:11:13北京市延庆区第一中学李子韩
电子世界 2018年5期
北京市延庆区第一中学 李子韩
1.概述
总所周知的,机器学习主要有监督学习、非监督学习、半监督学习以及增强学习四类。一般具有规则性的行为,我们可以通过监督学习和非监督学习,使智能体习得并掌握这些行为。然而对于一些序列决策或者控制问题,就需要用到增强学。增强学习,主要关注的是智能体和环境之间的交互问题,智能体通过增强学习,可以在当前的状态下挑选出一个当前回报最高的决策,通过执行当前挑选的最优决策,达到下一个状态,如此往复,通过执行一系列的决策,从而获得最终最优的累积回报。
例如,为了指导小狗学会一项新技能这一任务,我们不能告诉小狗它应该去做什么,但是我们可以在小狗做出动作后,判读动作是否正确,如果动作正确,则给予奖励;如果动作错误,则给予惩罚。经过一系列类似的训练之后,小狗就可以学习到它做出哪些动作后会得到奖励,做出哪些动作后会得到惩罚。类似地,我们同样可以在控制问题中,使用相同的方法训练智能体学习如何做出决策,获得最大的累积回报,从而达到决策优化的目的。再以曾经风靡全球的游戏《神庙逃亡》为例。我们的目的是让智能体学会这款游戏的玩法,但因为游戏的路线是随机的,所以如果我们直接给其输入某一固定的路线,是达不到令其学会的这一效果的。此时应用到增强学习,训练智能体学习如何作出决策,获得最大的累计回报,即检测到某一的障碍,智能体会作出选择,如果在操作后游戏人物死亡,则否定上一步操作;如果游戏继续,则记录此操作,并于下次检测到同样障碍时作出相同的操作。经过多次否定和记录,最终智能体可以学会这款游戏的玩法。

图1 《神庙逃亡》游戏操作界面
2.增强学习的发展与应用
近些年来,增强学习的研究取得了丰硕的成果,对增强学习的研究主要集中在增强学习的理论、增强学习的算法以及增强学习的应用这三个方面[1]。具体的介绍如下:(1)增强学习理论:时序差分学习的收敛性、表格型强化学习的收敛性、强化学习的泛化方法。研究的主要内容是算法的收敛性等基础理论,比如:时序差分学习的收敛性,表格型增强学习的收敛性等等。(2)增强学习算法:增强学习可以分为非联想增强学习和联想增强学习。比较经典的算法有:折扣型回报指标强化学习算法、Q-学习算法、Sarsa学习算法等等。(3)增强学习应用:增强学习是一种不依赖于环境模型和先验知识的机器学习方法,通过试错和延时回报机制,结合自适应动态规划方法,能够不断优化控制策略,为系统自适应外界环境变化提供了可行方案。通过将系统建模成马氏决策过程,在自动控制领域,增强学习方法已成功地实现了单个机器人的优化控制[2]、多机器人系统并行控制等等[3];如在博弈决策领域,人们利用增强学习方法,已经成功了开发出阿尔法狗——人工智能围棋程序以及星际争霸计算机模拟程序等等,此外增强学习方法在比如自动直升机、手机网络路由、市场决策、工业控制、高效网页索引、优化和调度等领域都取得了巨大的成功。
3.增强学习的数学模型
首先,基于增强学习问题建立如下模型(为了便于问题的简化,我们这里建立的环境和智能体的模型都是具有随机、有限状态性质的模型)。如图2所示。
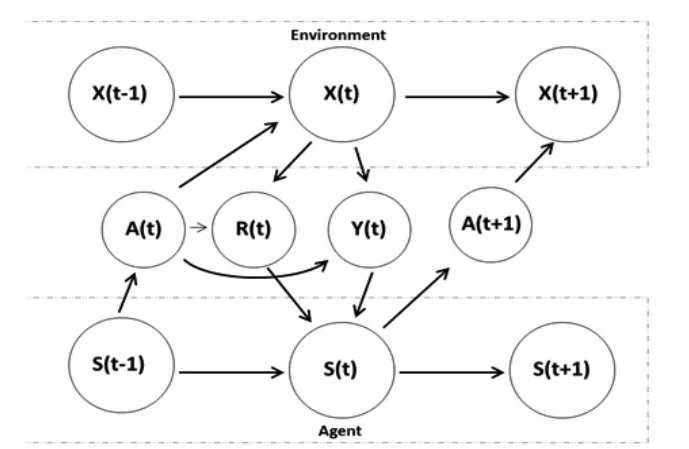
图2 简单的增强学习模型
马尔可夫动态过程可以进一步表示如下:
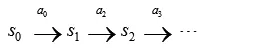
上述流程图表示智能体在状态s0下选择执行某个动作a0,智能体按照概率Ps0a0随机转移到下一个s1状态,然后再执行一个动作a1,智能体按照概率值Ps1a1转移到下一个s2状态,如此往复地进行动作执行和状态转移这两个过程,直达到达最终的终止状态或者到达最大的状态转移步数。
智能体的目标是学习找到一个马尔可夫策略,即一个从状态空间到动作空间的映射关系(,表示在当前状态s下,智能体会根据策略π选择执行动作a),从而最大化折扣回报加权和的期望。在马尔科夫决策过程中,如果智能体的起始状态记为s0,此时智能体根据策略π选择执行下一个动作a0,执行后智能体的状态转移到s1,然后智能体继续根据策略π选择执行下一个动作a1,执行后智能体的状态转移到s2,按照这种方式执行下去,我们可以得到从起始状态s开始,所有过程中回报函数的期望和:
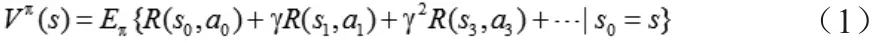
我们把(1)式中定义的期望函数Vπ(s),称为在起始状态s下,在给定的策略π下的价值函数(value function)。与价值函数非常类似的另外一个函数便是Q函数(Q-function),给定策略π,它的Q函数定义为:从一个给定的起始状态s开始,首先采取一个指定的动作a,然后根据策略π采取后续动作得到的所有回报函数的期望和:

从递推的角度来看,我们可以进一步把上述(1)式子写成:
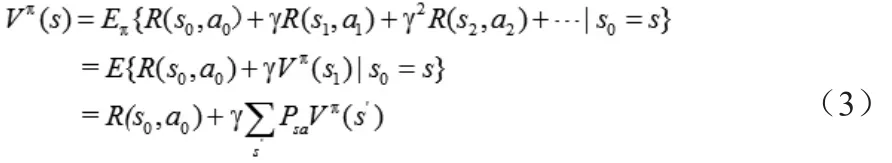
因此,上述找最优马尔可夫策略π的问题可以形式化为求解下述问题——求解最大化V*(s):

同样地,我们可以把Q函数写成上面的表达形式:
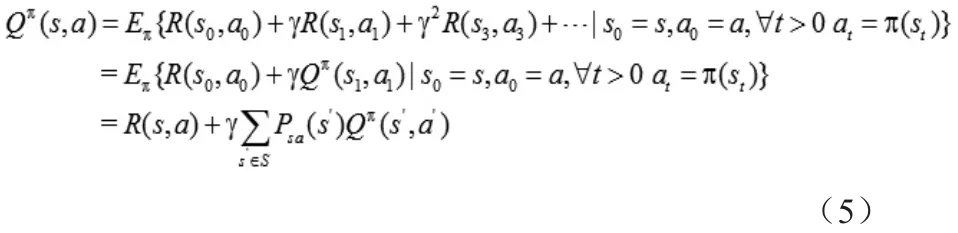
同样,我们定义最优的Q函数如下:

通过求解上述式子(6),我们可以得到最优的决策策略π*和最大的累积回报值。
4.全文总结
通过本文的介绍,我们大致了解了增强学习的基本概念、增强学习适用于解决哪些问题,增强学习的研究领域及主要的应用领域,最后我们通过建立并且简单地推导增强学习中最简单的数学模型——隐马尔科夫模型,加深了对增强学习模型的理解,即增强学习是通过不断地试错,学习到一组最优的决策策略,从而获得最终最大的累积回报的学习过程。
增强学习在许多应用领域都取得了巨大的进展,我们有理由相信,增强学习在今后的发展中,将会进一步推动人工智能领域的发展,给我们的生产生活带来极大的便利。
[1]陈学松,杨宜民. 强化学习研究综述[J].计算机应用研究,2010,27(8):2834-2838.
[2]吴军,徐昕,王健等.面向多机器人系统的增强学习研究进展综述[J].控制与决策,2011,26(11):1601-1610.
[3]秦志斌,钱徽,朱淼良.自主移动机器人混合式体系结构的一种Multi-agent实现方法[J].机器人,2006,28(5):478-482.
猜你喜欢
纺织科学研究(2021年9期)2021-10-14 08:52:10
数学物理学报(2020年3期)2020-07-27 01:19:48
小学生作文(低年级适用)(2019年5期)2019-07-26 00:45:10
中学生数理化·七年级数学人教版(2019年6期)2019-06-25 01:01:34
读友·少年文学(清雅版)(2018年12期)2018-04-04 05:16:40
Acta Mathematica Scientia(English Series)(2018年6期)2018-03-01 03:13:42
家庭百事通(2016年3期)2016-03-14 08:07:17
山东青年(2016年3期)2016-02-28 14:25:52
数学年刊A辑(中文版)(2015年4期)2015-10-30 01:49:12
应用数学与计算数学学报(2015年1期)2015-07-20 11:39:06
