
基于知识图谱的生物学科知识问答系统
2018-03-23 08:23王德军
软件 2018年2期
康 准,王德军
(中南民族大学 计算机学院,湖北 武汉 430074)
0 引言
基于知识图谱[1]提供的语义层面上的支持,问答系统作为下一代搜索引擎,支持用户通过自然语言查询的方式,获得得到所需的答案[2],并通过知识的链接发掘更多知识。
问答系统支持的最重要的一类问题是事实类问题,事实类问题中最为基础的称为基础事实类问题[3],它是针对事物属性或联系的提问,不需要进行复杂的逻辑推理。
国内在这方面也有了一定的研究[4-6],张克亮[5]等人设计并实现的航空领域问答系统,根据航空领域的问题构建大量的本体三元组,并在航空领域数据集上提高了问答算法的准确性和召回率,杜泽宇[6]基于电商领域实体的特殊性并结合依赖缩减算法实现了电商领域的问答系统。目前基础教育方面还缺少一套基于知识图谱的不仅可以解答学生问题,还可以更好连接和发散知识。国家的基础教育,决定民族的兴衰,经济的强弱。然而,我国基础教育存在着某些缺失和偏差现象,造成后续教育的被动和困难,直接影响并制约建设事业的有序进程,这是我们必须面对和思考的问题。主要问题表现在:1. 由于国家教育资源分配的不一致,导致偏远地区的学生缺少教师资源和获取知识的途径;2. 应试教育使得学生对学习新知识产生抗拒心理,教育不应止步于学校,也不应只针对考试。通过构建基础教育学科领域的知识图谱问答,在教师资源匮乏的地区,学生可以可以实时的获取知识。同学可以根据自己的喜好或困惑自主地获取知识,而不再是被动的被灌输知识。本文专注于生物学科基础教育领域,针对生物学科实体特殊性提出一种结合文档迁移距离(Word Mover Distance,WMD)[7]和逻辑回归模型的生物学科领域实体链接算法。在问句理解上,以往问答系统主要分为三种,(1)通过基于模板匹配的方式,该类方式准确率高,但是覆盖率低,需要大量的人工操作;(2)基于句法树的语义提取,对于口语化的问题解析能力不强;(3)基于短文本相似度的语义提取,会丢失语义网本身的链接特征;本文采用基于短文本相似度的语义提取,通过构建标注问答库,将问句语义理解问题简化,并结合深度学习模型进行问句语义匹配。
1 系统架构
1.1 系统结构
生物学科领域知识问答系统(Question Answering System Base on Knowledge Graph In Biology Domain,B-KBQA)是针对中文生物学科基础知识库领域知识的问答系统,重点解决将如何理解中文问句,并转换为Cyhper查询语句从知识图谱中获取相关知识,最终完成问答。系统整体系统框架如图1所示。(1)自然语言输入:输入生物学科基础知识相关问题,例如“肝脏的分泌液是什么?”。
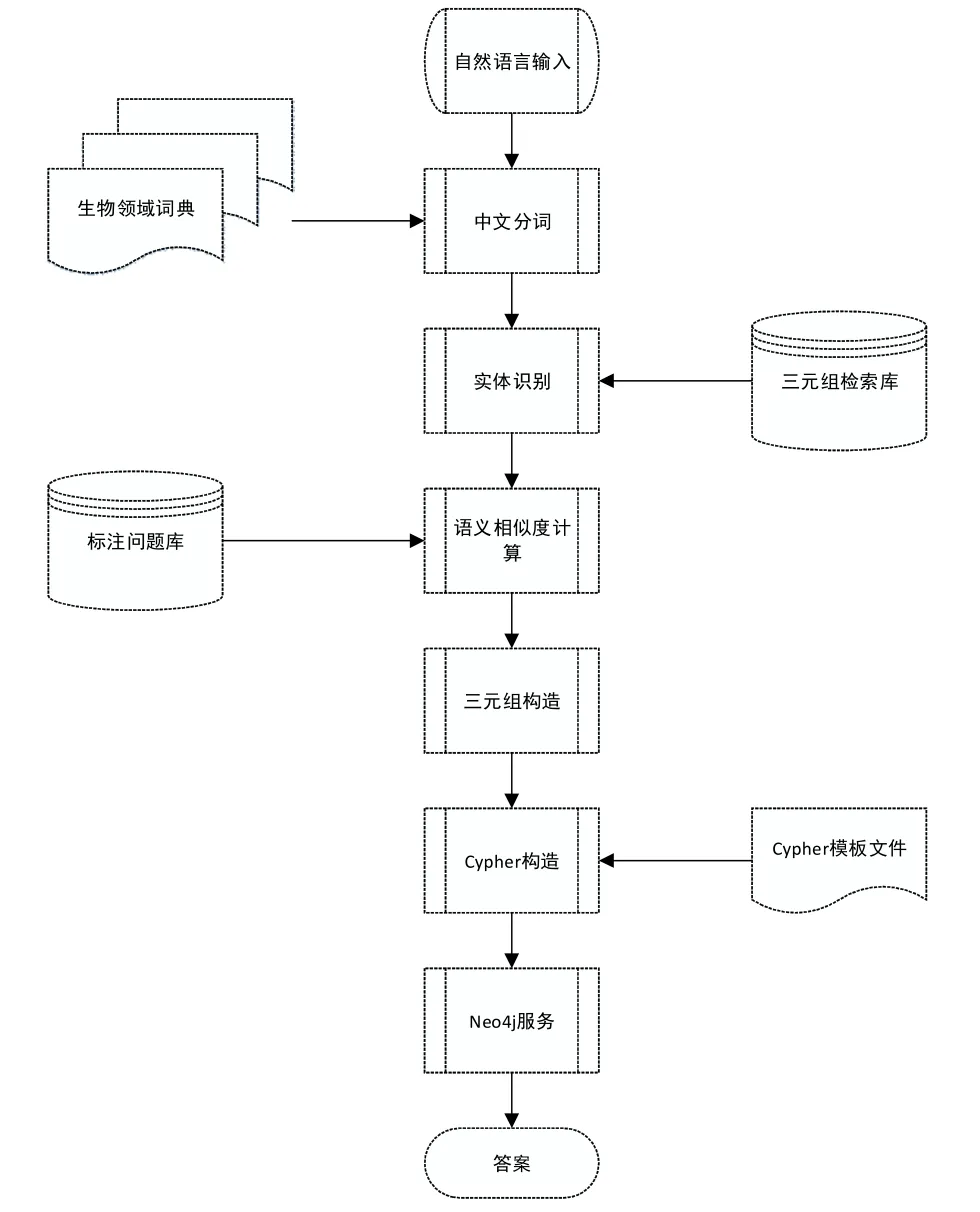
图1 整体系统架构图Fig.1 Overall system architecture diagram
(2)中文分词:使用开源分词工具包 Hanlp,结合生物领域词典进行分词处理。
(3)实体识别:得到分词结果后,首先在三元组检索库中检索得到相关的候选实体,本文借鉴WMD的思想,结合词性标注和依存句法分析[8],抽取文本特征,再通过逻辑回归模型进行候选实体与问题中实体的实体链接。
(4)语义相似度计算:检索标注问题库得到语义相关的候选问句,再通过深度学习模型计算输入问句与候选问句的语义相似度,得到语义匹配的候选问句,获取其标注的意图信息。
(5)三元组构造:三元组是自然语言问句转换为Cypher查询问句的中间状态,表示问句的基本语义,由三部分构成:主语、谓语、宾语。其中主语和宾语是从问句中提取出的实体,谓语是问句语义对应的知识图谱中的关系或者多条关系组成的路径。构造的三元组中主语和宾语其中之一会缺失,缺失元组即需要进行查询获得的结果,例如 Q1“肝脏的分泌液是什么?”和 Q2“胆汁是什么器官的分泌液?”,Q1的三元组表示为(s:肝脏,p:分泌液,o:None),Q2的三元组表示为(s:None,p:分泌液,o:胆汁)。
(6)Cypher构造:主要完成构造 Cypher的工作,通过谓语确定Cypher模板结合抽取的三元组得到最终的Cypher查询语句。
Q1生成的Cypher语句为:
MATCH
(node_a {name:” 肝脏”})
-IOLOGY_SECRETORY_FLUID]->
(node_b)
RETURN node_b.name as name
Q2生成的Cypher语句为:
MATCH
(node_a {name:”%s”})
<-[r:BIOLOGY_SECRETORY_FLUID]-
(node_b)
RETURN node_b.name as name
(7)Neo4j服务:将Cypher语句用于查询,获得最终的结果。
1.2 实体链接与消歧
传统的实体识别包括人名,地名,机构名等命名实体识别,主流的算法是基于条件随机场的命名实体算法或者基于隐马科夫模型的命名实体识别[9]。而生物学科领域的实体不同于传统的命名实体识别,主要以短语出现。例如“伴x染色体的显性遗传病”、“生态系统的信息传递”、“神经细胞”等,没有类似于人名、地名和机构名构成单词的特征,基于条件随机场算法的识别效果差。同时同一实体可能有多种不同的表现形式,如:实体“能量传递效率”可表示为“能量传输的效率”,所以识别算法必须具备一定的鲁棒性。针对生物学科领域实体的上述特点,通过改进文档迁移距离算法抽取文本特征,结合逻辑回归模型进行实体链接。
文档迁移距离算法通过计算文档A迁移到文档B的距离衡量文档A与文档B的相似度。算法流程如下:
(1)假定已有词向量矩阵 X ∈ Rd×n,包含n个单词。第 ith单词为 xi∈Rd,表示ith单词在d维向量空间的向量表示。首先将文档D中停用词去除,并表示为词袋模型 D ∈Rm,其中单词i在文档中出现ci次,如(1)式所示:

通过计算两个文档中单词迁移距离,构建文档迁移距离矩阵 C ∈ Rm×n,从文档 Da中选取单词i,从文档 Db中选取单词 j,单词i与单词 j的距离公式。
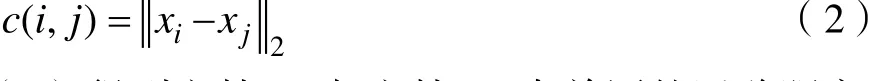
(2)得到文档 Da与文档 Db中单词的迁移距离矩阵和文档 Da与文档 Db的词袋模型,计算 Da与Db的相似度转换为将 Da中所有单词移动到 Db的最小转移费用问题,矩阵 T ∈ Rn×n,其中 Ti,j≥0 ,表示文档 Da中单词i有多少转移到文档 Db中的单词j,得到公式(3):
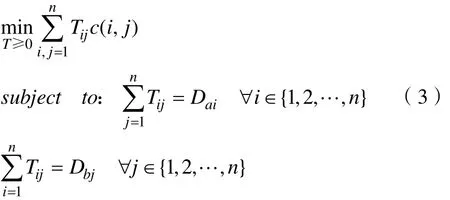
去除限制条件得到缩减文档迁移距离算法(Relaxed Word Mover Distance,R-WMD)[7],得到公式(4):
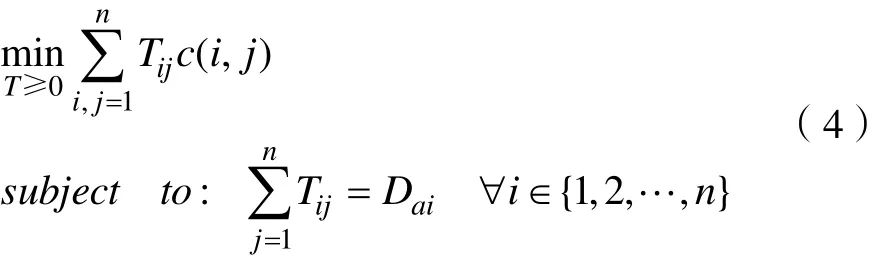
本文对R-WMD算法进行如下改进:
(1)R-WMD算法认为句子中单词对句子语义的贡献是一致的,但实验发现不同词性和不同句法成分的单词对句子语义的贡献不同[8],所以通过对文档D进行词性标注和依存句法分析得到单词的词性和所属句法成分,记 ith单词 Di的句法成分得分为 ri,词性得分为 si,得到公式(5):

(2)R-WMD算法仅考虑了单词i与单词 j的欧式距离,通过增加的单词i与单词 j的余弦距离,向量在方向和位置上描述分别描述实体与问句的语义特征。
1.3 语义识别
传统的语义理解方式包含三类:基于模式的语义理解[12],基于关键字的语义理解[13]和基于同义词的语义理解[14]。基于模式的语义理解需要进行大量的人工标注活动,基于关键字或同义词的缺陷仅通过单词或短语确定问句语义,并未真正理解语义。本文通过构建标注问答库,将问句语义理解问题被转化为问句与标注库中问句相似度计算问题。
问句标注库的数据来源包括三部分,1)爬取百度知道,作业帮,新浪爱问,搜狗问问中生物相关问题,整理得到20100道生物相关问题;2)从历年生物中考和高考试题通过人工整理和改写得到2000道基础事实类问题;3)抽取知识图谱三元组结合设计的模板生成30500道问题,共计52600个。采用人工标注的方式确定问句的意图和涉及的实体,再从中抽取1000道用于验证系统性能,其余题目通过将意图相同的问题进行组合得到正例样本,意图不同问句进行组合得到负例,获得语义相似度模型训练集。
本文选用在 Quora[15]数据集上评测结果准确率高于0.87的三个深度学习模型。深度学习模型是一种端到端模型,即模型自动抽取有用的特征,从而减少人为抽取特征造成的繁杂和不完备性。三种模型分别采用不同的特征表示两个问句的相似度特征,BiMPM模型[16],通过BiLSTM抽取句子特征P和Q,然后从PQ→和QP→两个方向的抽取句子匹配特征,再将匹配特征进行拼接表示相似度特征。LSTM with concatenation模型和LSTM with distance and angle模型[17],通过LSTM抽取两个句子特征P和Q,前者将P和Q进行拼接表示相似度特征,后者计算P和Q的欧氏距离和余弦距离表示相似度特征。
2 实验与结论
2.1 数据准备
实验从三个方面验证系统在生物基础知识领域的有效性,利用准确率(P)、召回率(R)、F值(F)作为衡量指标:
(1)命名实体识别;
Pe_num是准确识别的实体数目, E ntry_Num是系统识别的实体数目,AucNum是验证集的问题数目。

(2)问句匹配;
Pq_num是准确匹配的问题,Q uery_Num是系统匹配到的问题数目,AucNum是验证集的问题数目。

(3)系统评测:
Ps_num是准确答案的数目,ResNum是系统给出的答案数目,AucNum是验证集的问题数目。

实验使用的生物学科基础知识库共 324194个三元组。测试集1000道,且通过人工标注确定了问题意图和涉及的实体。
2.2 实验分析
实验对比R-WMD和改进的R-WMD抽取文本特征结合逻辑回归模型进行命名实体识别。后者比前者在准确率、召回率和F值上都有所提升,如表1所示。
在生物学科知识领域,由于实体的特殊性,问答系统需要解决最重要的问题及领域内的实体识别和实体链接问题,从表1中可以发现改进的R-WMD算法抽取的文本特征比R-WMD算法抽取的特征更适合该领域的命名实体识别工作。由此说明,根据问句中单词词性和句法成分确定单词重要性的方式比使用单词词频设置单词重要性更能反映句子的语义。
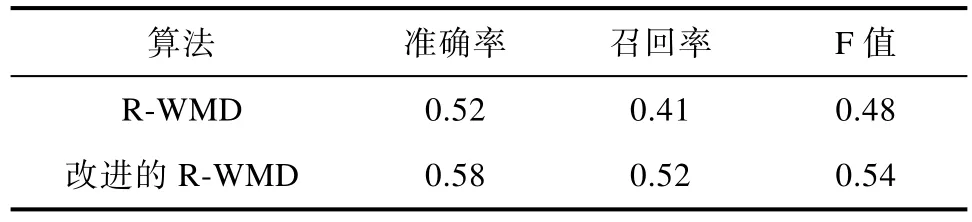
表1 命名实体识别实验结果Tab.1 Named entity recognition experimental results
问句匹配实验结果如表2所示,三种模型的准确率均在0.63以上,召回率均在0.44以上,F值均在0.52以上。
通过不断的扩充训练数据集,问句匹配的各项评价指标还有很大的提升空间,B-KBQA系统对生物基础知识领域的问题已经初步具备了语义理解能力。BiMPM模型在准确率、召回率和F值上优于其他两个模型,说明 BiMPM 更适合该问题的求解,后续工作中会通过尝试新模型和优化 BiMPM 模型进一步提升模型效果。
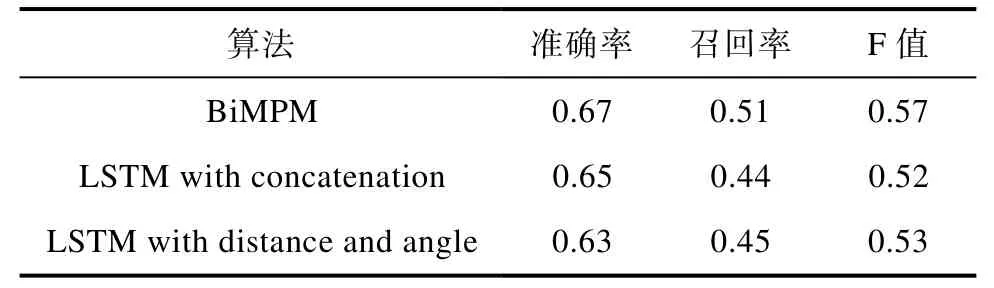
表2 问句匹配实验结果Tab. 2 Experimental results of question matching
系统评测对比了由DBpedia团队设计的开源问答系统TBSL[13],同时在B-KBQA框架基础上,实现了基于关键字的生物学科领域知识问答系统(Question Answering System Base on Knowledge Database In Biology Domain With Keywords,B-KBQA-keywords)和基于同义词的生物学科领域知识问答系统(Question Answering System Base on Knowledge Database In Biology Domain With Synonym,B-KBQA-synonym)。与B-KBQA的区别在于问句解析的方式不同,B-KBQA-keywords采用基于问句特征关键字的方式确定问句语义,B-KBQA-synonym在B-KBQA-keywords基础上,通过同义词扩展问句特征关键字,实验结果如表3所示。
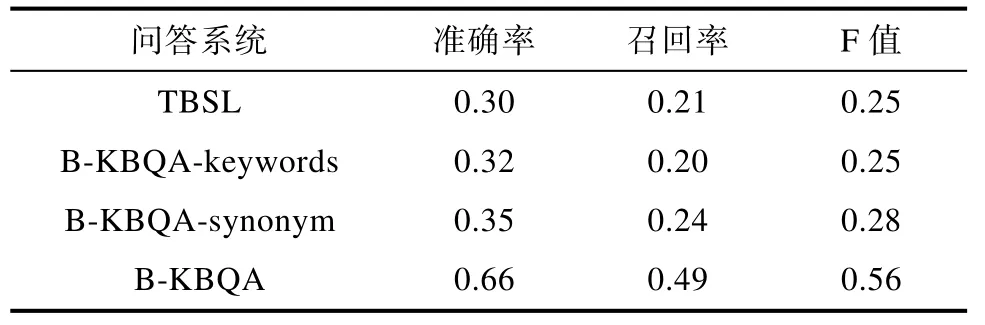
表3 系统评测实验结果Tab 3 Experimental results of system evaluation
对比其他三个问答系统B-KBQA在准确率、召回率和F值上均得到最高分,说明基于标注问题库和短文本相似度计算的系统框架对于生物学科知识领域的问答不仅可以回答更多问题,而且更为准确。现有实验说明B-KBQA的整套框架可以在生物学科知识领域知识图谱上提供面向基础事实类问题的问答服务,且各模块间相互独立,有利于进一步优化系统整体性能。
3 结论
本文结合改进R-WMD和逻辑回归模型进行生物学科的实体识别和实体链接,并通过对比R-WMD算法,结果将单词词性及句法特征应用于 R-WMD可以有效提升实体识别及实体链接的准确率。最后对通过对比TBSL,B-KBQA-keywords和B-KBQA-synonym三个问答系统,实验结果表明B-KBQA系统在问答准确率,召回率及F值上均优于其他系统,B-KBQA在生物学科知识问答领域具有一定的应用价值。然而本文也存在着不足,实体识别及实体链接的准确率直接影响最终问答的准确率,目前使用的方法在此方面还有很大的提升空间,未来工作中需要进一步研究。
[1] 刘峤, 李杨, 段宏, 刘瑶, 秦志光. 知识图谱构建技术综述[J]. 计算机研究与发展, 2016, 53(3): 582-600.
[2] 常超. 基于网络问答社区的专家排名算法分析[J]. 软件,2015, 36(11): 120-122.
[3] 刘家玮, 刘波, 沈岳. 知识图谱在农业信息服务中的应用进展[J]. 软件, 2015, 36(3): 26-30.
[4] 黎航宇. 命名实体识别中适应性特征的跨领域与跨风格特性研究[J]. 软件, 2014, 35(10): 100-106.
[5] 张克亮, 李伟刚, 王慧兰. 基于本体的航空领域问答系统[J]. 中文信息学报, 2015.
[6] 杜泽宇. 基于中文知识图谱的电商领域问答算法设计与系统实现[D]. 华东师范大学, 2016.
[7] KUSNER M J, SUN Y, KOLKIN N I, et al. From word embeddings to document distances[J]. 2015: 957-966.
[8] CUI W, WANG H, WANG H, et al. KBQA: learning question answering over QA corpora and knowledge bases[J].Proceedings of the Vldb Endowment, 2017, 10(5): 565-576.
[9] OU S, ORASAN C, MEKHALDI D, et al. Automatic Question Pattern Generation for Ontology-based Question Answering[C]// International Florida Artificial Intelligence Research Society Conference, May 15-17, 2008, Coconut Grove,Florida, Usa. DBLP, 2008: 183-188.
[10] JIANG L, CHANG S, NIKHIL D. Semantic Question Matching with Deep Learning[EB/OL]. (2017-02-13) [2017-02-13]. https://engineering.quora.com/Semantic-Question-Matching-with-Deep-Learning.
[11] UNGER C, CIMIANO P. Pythia: Compositional Meaning Construction for Ontology-Based Question Answering on the Semantic Web[C]// International Conference on Natural Language Processing and Information Systems. Springer-Verlag, 2011: 153-160.
[12] UNGER C, BUHMANN L, LEHMANN J, et al. Templatebased question answering over RDF data[C] //Proceedings of the 21st International Conference on World Wide Web.Lyon, France: ACM, 2012: 639-648.
[13] UNGER C, LEHMANN J, NGONO A C N, et al. Templatebased question answering over RDF data[C]// International Conference on World Wide Web. 2012: 639-648.
[14] BOWMAN S R, ANGELI G, POTTS C, et al. A large annotated corpus for learning natural language inference[J].Computer Science, 2015.
[15] AHAEBRAHIMIAN A. Quora Question Answer Dataset[C]//International Conference on Text, Speech, and Dialogue.Springer, Cham, 2017: 66-73.
[16] WANG Z, WAEL H and RADU F. Bilateral Multi-Perspective Matching for Natural Language Sentences [EB/OL].(2017-02-13) [2017-02-14]. https://arxiv.org/pdf/1702.03814.pdf.
[17] KENTER T, BORISOV A, RIJKE M D. Siamese CBOW: Optimizing Word Embeddings for Sentence Representations[J]. 2016.
猜你喜欢
客联(2022年3期)2022-05-31
理科爱好者(教育教学版)(2022年1期)2022-04-14
乳业科学与技术(2021年3期)2021-08-09
中国新闻周刊(2021年26期)2021-07-27
中学生数理化(高中版.高考理化)(2020年2期)2020-04-21
中国外汇(2019年18期)2019-11-25
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
信息安全研究(2016年4期)2016-12-01
