
基于遗传算法优化的BP神经网络大肠癌证型分类
2018-03-21 01:31,
中华医学图书情报杂志 2018年3期
,
大肠癌是常见的消化道恶性肿瘤,包括结肠癌和直肠癌。近年来,随着人们生活方式和生活环境的改变,大肠癌在我国的发病率和死亡率呈现快速上升的趋势[1]。大肠癌属本虚标实之证,既有脏腑气血亏虚,又有气滞、血瘀、痰凝、湿毒等标实的情况[2]。目前中医证候诊断标准存在证名不统一、证型的诊断标准没有考虑到疾病的影响,构成证的基本元素模糊不清,标准制定主要依据中医理论、文献及专家咨询带有很大主观成分等诸多问题,而临床上病例往往诸证夹杂,临床医师治疗经验不同,很难统一“标准”,“标准”在临床实践上也难以应用实施[3]。因此,利用计算机技术对中医药信息进行规范化的研究十分必要。
随着人工智能的发展,神经网络技术也不断成熟。由于其分类能力强且具有智能性,人工神经网络在医学诊断、预后、生存分析、临床决策支持、模式识别等领域得到广泛应用[4]。而BP(Back Propagation)算法是基于梯度下降的,自身的缺陷也不可避免。如网络权值和阈值随机设定,当解空间多个局部极小时容易陷入局部极小而无法跳出[5]。此外,网络输出自变量之间多数情况下并非独立而存在冗余信息,会导致网络训练陷入过拟合状态且延长建模时间。本文针对传统BP算法用于分类建模时的缺陷,拟采用遗传算法(Genetic Algorithm,GA)优化后的GABP(Genetic Algorithm Back Propagation)模型构建大肠癌的虚实证型分类器,以期促进对大肠癌虚实证型分类的统一标准研究。通过对优化后的神经网络进行前后对比分析,提升大肠癌分类器的有效识别能力,对制定大肠癌中医临床诊断标准具有指导意义。
1 资料与方法
1.1 数据来源
本文所用数据共338例,其中150例来源于广东省中医院临床病案,其余188例来源于中国知网全文数据库、万方数据知识服务平台及维普全文数据库文献数据。纳入标准为经细胞学或病理学检查诊断为结直肠癌或者已通过肠镜报告检查诊断为大肠癌及经手术切除原发病灶的大肠癌患者,排除病理诊断不明确且具有多原发性肿瘤或既往有恶性肿瘤的患者。综合上述纳入、排除标准,最终筛选出符合条件的218例大肠癌患者数据,其年龄分布于25~80岁,男性患者108例,女性患者110例。
1.2 数据量化
1.2.1 症状量化
在专家指导下,综合临床与文献两部分数据,选出与大肠癌患者密切相关的28项体征,包括大便脓血、脉沉、舌苔白、纳呆等症状。为突出中医术语的严谨规范性,按照《中医症状鉴别诊断学》(第二版)[6]标准依据,对症状的分类进行初步划分,并将已经规范好的大肠癌常见症状进行赋值量化,有该症状为1,无该症状为0。为防止量化过程中人工录入产生错乱,数据录入采用双边独立录入并进行一致性检验。
1.2.2 证型量化
参照2008年中华中医药学会发布的《中医诊疗指南》中提出的诊断、辨证标准,同时参照1992年全国大肠中医科研协作会议制定的证型划分标准和2004年杨金坤主编的《现代中医肿瘤学》[7],结合本文所收集的实际病例情况,在多位专家进行判定之后,决定将本文筛选出的218例大肠癌患者归为脾失健运、脾虚夹瘀、湿热内蕴、气滞血瘀、瘀毒内阻、气血亏虚、脾肾阳虚、肝脾不调8种证型。考虑到分属于这8种证型的样本数据量较小,可能会对后续建模的分类效果有一定影响,因而将这8种证型进一步分为虚证与实证两种类型,且将虚证赋为1,实证赋为2,同样在赋值后对录入的数据进行一致性检验。
1.3 研究方法
人工神经网络是由大量的功能和形式比较简单的神经元互相连接而构成的复杂网络系统,网络可以看作是从输入到输出的一个非线性映射[8]。BP神经网络具有的非线性映射能力能够保证其成功实现各种简单或复杂分类,它将信息分布式存储于连结权系数中,使网络具有较高的容错性和鲁棒性[9]。遗传算法是模拟自然界优胜劣汰生物进化过程的全局优化搜索算法,采用群体进化的方式对目标函数空间进行并行式搜索,根据个体适应度大小选择个体,保留竞争力强的基因,是一种搜索效率高、鲁棒性强的优化方法[10]。遗传算法广泛应用在机器学习、自适应控制、组合优化等领域,并取得了很好的效果[11]。本文结合遗传算法与BP神经网络的特点,首先利用遗传算法对自变量进行优化筛选,利用遗传算法优化BP神经网络的权值和阈值提高筛选效率,最终通过优化BP神经网络的结构和系数构建大肠癌虚实证型分类器,探讨大肠癌证型分类的有效方法。
2 基于遗传算法优化的过程
利用遗传算法选择特征维必须经过输入变量编码、初始种群产生、适应度计算、交叉变异选择、优化输出等过程[12]。由于BP算法本质上为梯度下降法,所要优化的目标函数非常复杂,容易出现局部最优、收敛速度慢等问题,而遗传算法是多点搜索,能够避免局部最优。此外,利用遗传算法取代一些其他的优化算法,是因为遗传算法的寻优能力可以获取最佳权重。利用遗传算法进行自变量降维与网络初始权值与阈值的优化步骤如下。
2.1 输入变量编码和种群初始化
本文在利用遗传算法进行自变量筛选的过程中,染色体编码采用二进制法,即将个体编码为一个二进制串。根据研究中的28项体征,此处染色体编码长度为28,染色体的每一位对应一个输入特征维,若染色体某一位值为1,说明该位置上相对应的输入自变量参与建模,若为0则不参与。而在利用遗传算法进行BP网络权值和阈值的优化过程中,我们对初始种群采取实数编码,每个个体由一组实数串组成。当BP网络结构确定时,个体编码长度也随权值和阈值个数确定。本文将种群大小初始化为20,最大进化代数设置为100,遗传算法以这20个个体作为初始点进行迭代。
2.2 适应度函数计算
BP神经网络的误差绝对值越小越好,而在遗传算法中,适应度值越大越好[13],因此采用以BP神经网络目标函数的倒数作为适应度函数。本文选取测试集数据误差平方和的倒数作为适应度函数,以便使遗传算法朝向适应度函数增大的方向进化。
2.3 选择交叉变异
选择交叉变异是遗传算法的核心。本文选择操作采用轮盘赌法,首先产生0与1之间的随机数确定种群中个体被选中次数,然后根据上述适应度函数计算,选择适应度大的进入下一代种群。对于交叉操作,降维过程选择单点交叉算子,变异点位置是随机产生的,且该位置上的基因值由0变成1或1变为0。在权值和阈值优化过程中,交叉操作采用交叉算子,利用一对个体根据给定的概率重组产生新的种群后代。
2.4 优化结果输出
按照遗传算法进行层层迭代之后,当迭代次数达到最大进化代数时,进化终止,最终输出的此种群中适应度最好的个体对应输入变量的基因编号为1、4、5、9、13、14、18、20、22、27,分别对应于大肠癌的腹泻、里急后重、大便秘结、脉沉、脉细、脉滑、舌紫、舌胖、舌苔白、纳差等10项体征,筛选出来参与建模的自变量不到原来总输入的一半,即收集统计的28项体征输入自变量之间并非独立,存在冗余信息,经遗传算法降维是非常必要的。遗传算法优化降维的过程如图1所示。由图1可知,最优个体是在种群进化到第35代后得到的。由于遗传算法存在一些随机因素,故种群的平均适应度函数均值在稳定中出现微小波动。
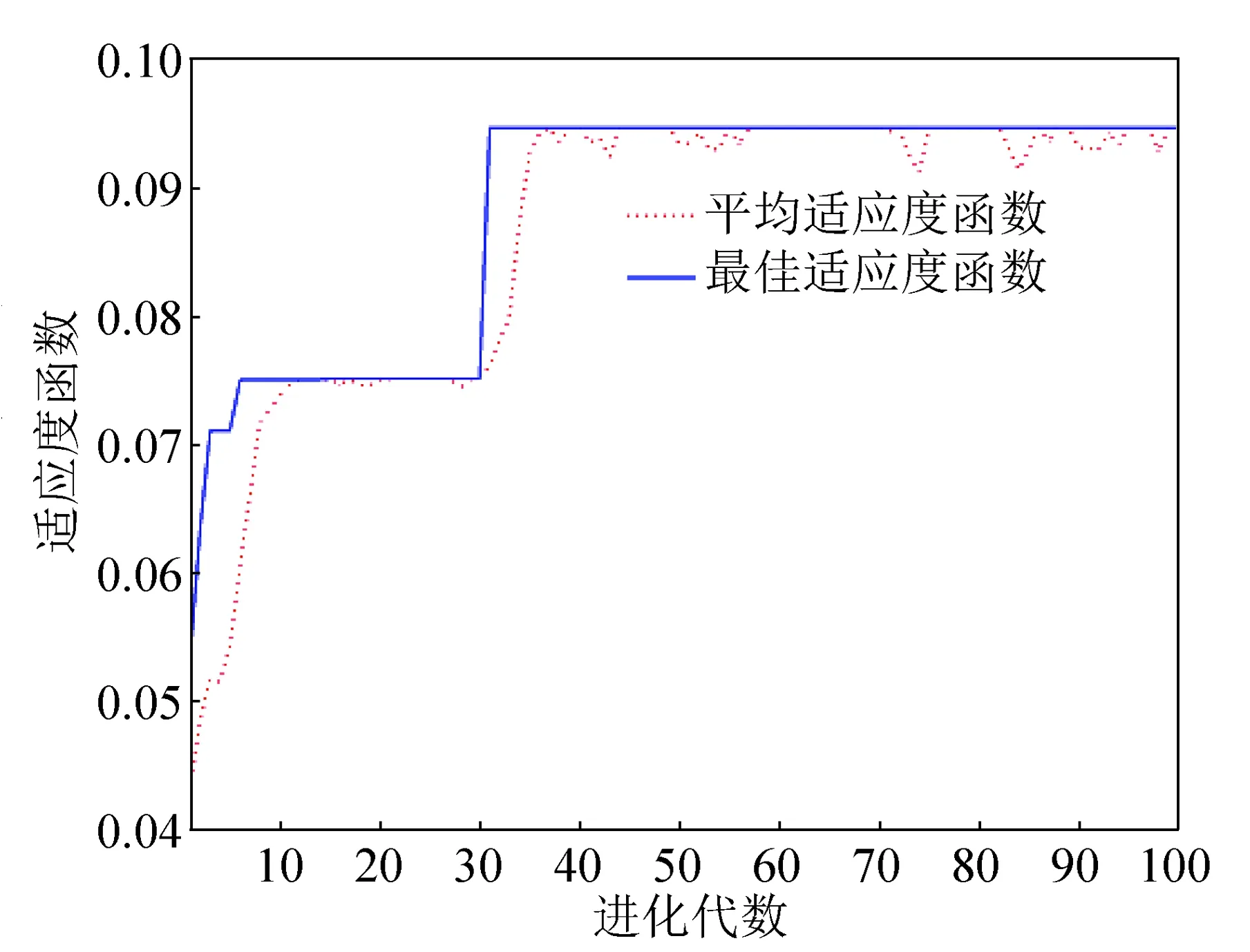
图1 种群适应度函数进化曲线
3 建立基于遗传算法优化的BP神经网络
3.1 遗传算法优化BP神经网络流程
BP神经网络对网络初始权值和阈值的依赖性比较强,以往大多随机选取易陷入局部最优。遗传算法是一种全局优化的自适应概率搜索算法,可以得到全局最优[14]。本文利用遗传算法对神经网络的初始权值和阈值进行优化寻优,基本流程如图2所示。
3.2 BP神经网络结构及隐层设置
BP神经网络是信号沿着前项传播,误差沿着反方向传播,不断调整权值与阈值使网络趋于收敛构建的过程。由于由输入层、隐藏层、输出层构成的3层BP神经网络可以逼近任意函数,故本文选取BP的3层拓扑结构进行大肠癌虚实分类器的构建。输入层由经遗传算法降维优化的10项体征设定,输出层由虚实两种证型作为输出。由于BP神经网络隐藏层节点通常由经验公式及误差对比调整得出,本文考虑到样本量偏少,为充分利用数据集,利用MATLAB(matrix&laboratory)中的crossvalind函数采用五折交叉验证确定GABP神经网络建模过程中的最佳隐含层神经元个数,程序根据数据集实际情况设定最佳神经元个数在10-28之间循环寻找。结果显示当隐含层神经元个数为15时,网络的分类效果最好,故GABP神经网络模型的隐层个数确定为15个。因此本文中BP神经网络的基本模型确定为10-15-2,且隐含层和输出层的传递函数都取s函数。
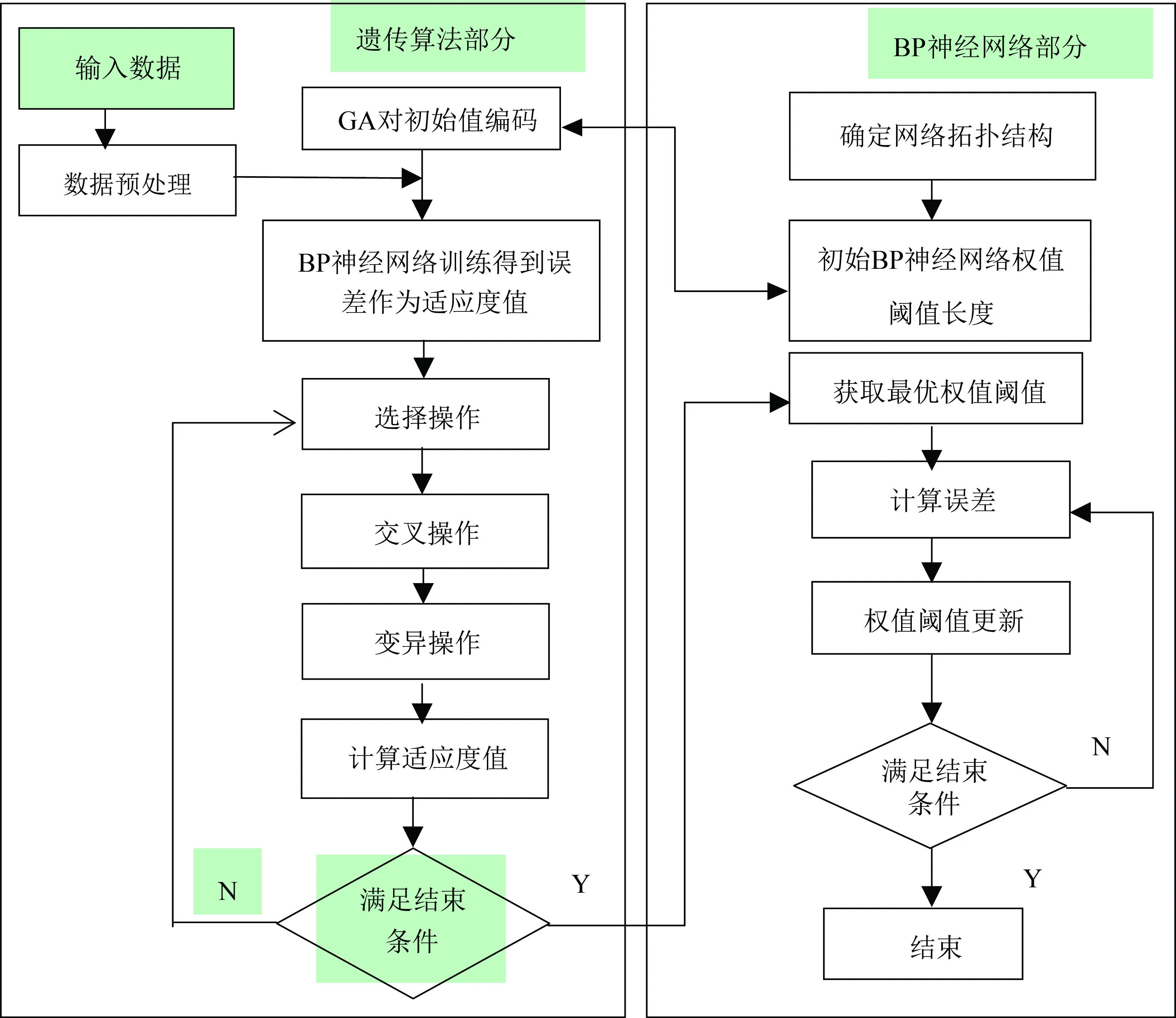
图2遗传算法优化神经网络流程
3.3 BP神经网络输出方式
在进行网络训练之前,将虚实证型分别标记为“1”“2”。由于经BP神经网络输出的为非二值结果,即网络的期望输出只能取1或2作为已标记的大肠癌虚实证型分类,故在程序中进行四舍五入的设定,即当网络预测输出值介于0.5~1.5之间时视为虚证,若该值介于1.5~2.5之间时则视为实证,统计预测结果并输出正判率。
3.4 BP神经网络训练及测试
将经遗传算法优化计算后筛选的输入自变量对应的数据提取出来建立新的BP神经网络。为了使训练的网络不失一般性,随机选取165例数据作为训练集,剩余的53例作为测试集,设定最大迭代次数为1000,允许误差界值设为0.001。当2次迭代结果的误差小于该值时,系统结束迭代计算,输出结果,并统计正判率。三次仿真结果的虚实两证型的正判率及建模时间如表1所示。

表1 传统BP与GABP的3次仿真分类结果
4 基于传统BP与经遗传算法优化的GABP神经网络分类模型的结果对比
经传统BP神经网络模型和遗传算法优化改进的BP神经网络模型(GABP)实现的的大肠癌虚实证型分类器结果平均值见表2。两种模型样本总量均为218例,其中训练样本选取总样本的75%(本文中选取165例),测试样本占总样本的25%(本研究中选取53例)。从表2可以看出,经遗传算法优化改进后的BP神经网络分类效果明显优于传统BP神经网络,这是因为经遗传算法优化改进后,不仅克服了传统BP网络存在的缺陷,而且利用遗传降维有效提取了输入维度的信息,从而实现了高效的分类。此外,在利用两种模型构建分类器时,实证正判率明显低于虚证正判率,这是因为在218例总样本中,虚证有143例,而实证仅有75例,且在测试构建好的网络模型时,随机选取的测试集虚实证型的不均匀分布也会影响分类的最终效果。如果可以克服样本证型数量分布不平衡,实验分类效果可能更佳。
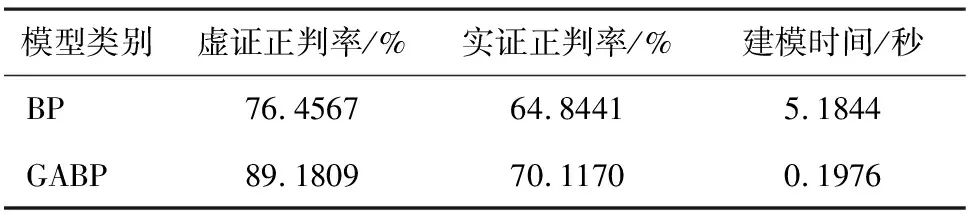
表2 分类模型结果对比
5 结语
实验结果表明,BP神经网络分类器可在一定程度上克服中医症状与证型之间的不确定性与模糊性,能获得较高的分类正判率。引入遗传算法后对证型分类的效果有进一步的提高,说明人工神经网络与遗传算法相结合能有效将大肠癌表面体征与内在证候特征有机结合起来对大肠癌证型进行预测分类,具有较强的研究价值与应用意义,对大肠癌中医的临床诊断有一定的借鉴意义。不足之处在于,本文是通过遗传算法将自变量降维和优化BP神经网络的初始权值和阈值来提高网络性能的,也可利用遗传算法过程中不同编码方式达到优化效果。此外,为验证经遗传算法优化改进后的BP神经网络的分类效果,我们也构建了LVQ(Learning Vector Quantization)神经网络用来进行对比。利用LVQ神经网络无需对数据进行归一化,而只需通过计算输入向量与隐含层神经元间的距离,便可完成模式识别构建大肠癌分类器。实验结果显示,LVQ神经网络得到的虚证正判率达到81.5118%,实证正判率达到67.4537%,略优于传统BP的分类效果,但依旧低于经遗传算法优化的BP神经网络分类效果。对比实验很好地表明了虽然LVQ神经网络也是一种很好的分类算法,但GABP模型用于大肠癌虚实证型的分类拥有更高的分析速度与准确度。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
世界科学技术-中医药现代化(2021年8期)2021-12-21
世界科学技术-中医药现代化(2021年12期)2021-04-19
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
计算机测量与控制(2018年3期)2018-03-27
自动化学报(2017年7期)2017-04-18
中国继续医学教育(2015年5期)2016-01-07
中国继续医学教育(2015年4期)2016-01-07
中外医疗(2015年18期)2016-01-04
中国中医眼科杂志(2015年1期)2015-12-28
