
基于Labeled LDA主题模型的医学文献自动分类法
2018-03-21 01:33,,
中华医学图书情报杂志 2018年10期
,,
随着医疗大数据的爆炸性增长,医学文献共享和知识挖掘的需求越来越迫切。如何提高医学文献分类的效率和质量,快速准确地识别这些海量文献的类别信息,从而挖掘出有价值的信息,成为该领域一个十分突出和重要的课题。虽然文本自动分类[1]作为一种成熟、高效的文本分类方法,已经在文本挖掘领域得到了广泛的应用,但分类效果还不够理想。
目前,关于自动分类的研究主要是利用SVM或KNN等分类算法[2-3],而基于主题模型的自动分类方法研究比较少,特别是针对医学领域文本自动分类方法的研究更少。
鉴于主题模型要考虑文本的语义信息可靠性较强,本文提出了一种基于Labeled LDA[4]主题模型的医学文献自动分类方法。它采用医学文本特定的方式构建训练文本,解决数据不平衡问题,调整模型的参数为最佳,选取了10个医学领域的文献进行实验,并用Labeled LDA主题模型与SVM方法进行对比实验,对实验结果进行分析总结,验证本文提出的自动分类方法的可靠性和效果。
1 实验设计
自动分类包括词典构建、语料库构建、算法对比与分析等阶段。
在语料库构建阶段,语料库数量庞大、各类别的覆盖度及类之间的不平衡问题突出,需要设计语料库构建规则,对语料库文档进行筛选,在保证各类完整性的基础上尽量减小语料库规模和计算规模,同时充分考虑类之间的平衡;在词典构建阶段需要对词进行规范,对已有词典文本进行处理,从而提高特征向量的纯度,同时还需要对多种分词算法进行对比分析和测试,选择合适的方法提高分词准确率和未登录词的识别率;在分类算法阶段,针对语料库及需要分类的文本特征选择合适的算法,提高分类效率和准确率。
本文主要是针对医学文本自动分类的问题设计实验,通过对比Labeled LDA和SVM的分类效果,选取好的自动分类方案,提高分类的准确率和效率。
1.1 数据预处理
数据预处理需要解决去除数据中的噪音和数据不均衡性两个关键的问题。
数据下载后,需要进行文本的切词和去停用词处理。由于本文是对医学文本内容进行分类,加之医学词汇有许多特有词和专有词,因此需要构建医学专用词词典,辅助切词过程,提高切词的准确率;需要下载临床医学疾病库中的词汇以及MeSH词汇,经人工筛选、规范同义词,并补充如药物、基因等其他词汇构成切词词典。文本切词后,需要构建停用词词典,将意义不大的词去除。分词工具选用AnsjSeg。
实际分类数据中的数据往往是非平衡的。如何正确分类非平衡数据集成为文本分类的挑战。非平衡数据集是指在同一个数据集中某些类的样本数远大于其他类的样本数,其中样本少的类为少数类,样本多的类为多数类[5]。目前,解决不平衡分类问题的策略分为两大类:一类是从训练集入手,通过改变训练集样本分布降低不平衡程度;另一类是从学习算法入手,根据算法解决不平衡问题中的缺陷,适当地改进算法使之适应不平衡分类问题。本文着眼于使训练样本各类数量基本一致,并从特征选取的角度尽量保留少数类的特征[6]。特征选取的方法为选取各类别中出现频次较高的词保留,结合人工判断保留频次较低但属该类的专有词,并补充漏掉的各类别特征词和专有词。
1.2 Labeled LDA 模型
1.2.1 模型的训练
实现Labeled LDA模型在JGibbLDA[7]的基础上进行。当Labeled LDA模型在训练阶段对词进行主题采样的时候,不再计算该词在所属文档上未标记类别的概率,避免了LDA模型中词会在所有主题上进行分配的问题。将词的主题范围限定在所属文档标记的主题之内,很好地利用了人工标记的主题信息,分类效果比LDA模型好。
Labeled LDA模型训练文本的输入格式与JGibbLDA类似,每一行表示一个文档,词与词之间使用空格分隔。Labeled LDA模型需要在每行文本前面使用“[]”的标识,显示每个文档所属的类别。
实验中10个类别的训练文本如图1所示。

图1实验中10个类别的训练文本
图中每1行代表一个医学国标类别,第1行代表消化病学,第2行代表呼吸病学,第3行代表皮肤病学,第4行代表肾脏病学,第5行代表泌尿外科学,第6行代表肿瘤学,第7行代表妇产科学,第8行代表神经病学,第9行代表心血管病学,第10行代表血液病学。这些文本词由相关的医学文本经过分词、筛选并人工分类后得到。
西沙群岛岛屿自身生态环境脆弱,加上岛屿垃圾处理条件有限,保护是开发的前提,西沙的环境保护尤为重要。有效科学的控制游客数量,规范游客行为,推进“一人一袋”环保活动,让每位游客上岛带上环保袋,不得随意丢置垃圾。
Labeled LDA模型使用Gibbs抽样方法对主题词分布进行迭代抽取,其最终的准确度受Gibbs抽样迭代次数的影响。实际使用Labeled LDA模型时,会用某个间隔次数阶梯状地训练Labeled LDA模型,然后需要用人工评估模型的训练结果,找最合适的迭代次数,以保证Gibbs抽样过程已经收敛,也不进行多余的迭代。
1.2.2 模型的预测
预测文本格式与训练文本格式类似,预测时需要设定相关参数而不需要标记类别号。如预测文本的位置,预测类别数目,迭代次数,选择哪种迭代模型进行结果推断。预测完成后结果在输出文件“.theta”中,每行代表预测集中的一个文档,每一行中的值表示该文档属于不同主题的概率,输出最大值和次最大值对应的类别作为最终的分类结果,次最大值数目过多或过少则不保留此分类。
1.3 SVM模型
支持向量机(SVM)已在手写数字的识别、扬声器识别、人脸识别、文本分类等许多领域展示了较好的效果,并在解决小样本、非线性及高维模式识别问题中表现出了特有的优势。它的原始设计是针对两类模式识别的问题及现实世界中的多类问题。
经典的SVM 多类分类算法[8]主要有一对一方法(1-vs-1)、一对多方法(1-vs-all)、有向无环图方法(DAG-SVM)和二叉树法(BT-SVM)等。从分类器的复杂度来看,一对多和二叉树算法对n类分类问题分别需要构造n和n-1个分类面。构造分类面最多的是一对一和DAG算法,对n类问题需要构造n(n-1)/2个分类面。从分类的精度方面分析,一对一和DAG算法比一对多和二叉树算法高。因此在目标分类问题中,分类的精度和分类器的复杂度为一对互相矛盾的指标,因而在解决实际问题中究竟采用哪种分类器,应根据实际的需求而定。当分类精度要求比较高时可以采用一对一和DAG算法,若是需要同时考虑分类精度和分类速度,可以使用一对多和二叉树算法,当然也可以将不同的分类器组合成混合的分类器来协调二者间的需求矛盾[9]。
SVM使用时相对简单,首选需要构建数据的输入格式,然后优化最佳参数并选择核函数,利用训练数据构建模型,最后利用模型对测试数据进行分类预测。数据的输入格式如下:
[label][index1]:[value1][index2]:[value2]…
一行即为一条数据记录,label是种类,即这一条记录所属的类别,通常为整数;index是有顺序的索引,通常是连续的整数,代表这个类别的特征;value是特征的值,通常是一些实数。
1.4 结果的评估算法
分类器的性能通常采用评估指标衡量,评估指标是指在测试过程中所使用的一些用来评价分类准确度的量化指标[10],包括准确率(Precision)、召回率(Recall)和F1标准等。
2 实验流程与结果分析
2.1 数据预处理
在CBM数据库中,选取2015年发表的部分中文数据作为训练数据和测试数据,根据标题和关键词对文献进行自动分类实验。
下载的数据中包括以R开头的分类号—cn_auo字段(图2)。这是作者给文献的分类号,可将其对应成国标分类号和分类名,作为文献的标准分类结果,并根据需要补充分类名称。
数据需要根据标题和关键词进行分词和去停用词处理,使用AnsiSeg分词包时需要准备医学词表和停用词表,分词的结果只限定于词表中包含的词。分词的词典目前已有30多万词汇,需要用临床医学知识库中的疾病库词汇及MeSH词汇进一步规范和完善词典,然后进行同义词归并,并补充一些较新且属专指的词汇。
对标题和关键词分词后的结果为图2中的“ti_kw”字段和“tw_kw”字段,将这两个字段合并的结果构建训练语料。利用消化病学、肿瘤学、皮肤病学、肾脏病学、泌尿外科学、呼吸病学、妇产科学、神经病学、心血管病学、血液病学等10个类别进行自动分类的测试,每个类别下的词汇需要从标题和关键词的分词结果中遴选,并且辅助人工判断进行补充。选取各个类别中出现频次较高的词保留,并结合人工判断,将频次较低但属该类的专有词保留,并补充漏掉的专有词汇。

图2 CBM数据预处理
2.2 Labeled LDA模型应用
2.2.1 训练文本的构建
应用Labeled LDA模型对文本内容进行分类,首先需要利用训练语料库构建分类模型。分类模型构建的好坏直接影响预测数据分类的准确性,因此模型训练阶段十分关键,其中训练语料库的构建又是模型训练阶段的关键。从语料库的构建入手,选取消化病学、肿瘤学、皮肤病学、肾脏病学、泌尿外科学、呼吸病学、妇产科学、神经病学、心血管病学、血液病学等10个类别、300篇中文数据(共3 000条),构建Labeled LDA模型的输入文本。首先对这10个类别的词汇出现频率进行统计,选取词频大于5的词,并通过人工判断,除去对类别判断没有意义的词,如病毒、注射、复发、早期治疗等,保留频次较低但属该类别的特征词,还需要补充漏掉的专有词汇或特征词。最终选取的特征词汇数量见表1。

表1 特征词统计数量
2.2.2 模型的训练
运用Labeled LDA进行模型训练,设置相关的参数,类目数设为10,每个类别选取前50个最大概率词项,生成的模型文件见图3。
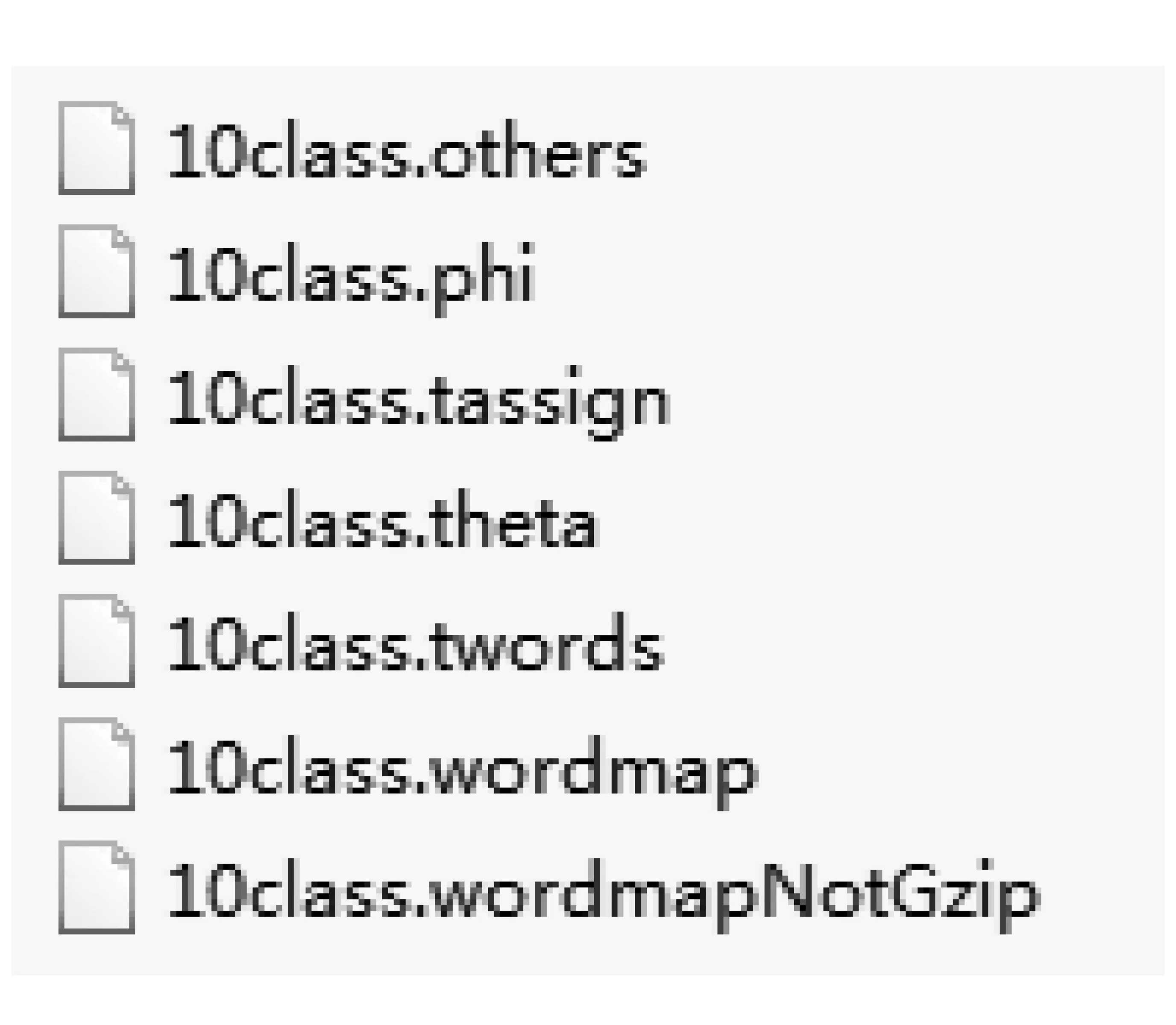
图3 Labeled LDA模型文件
模型训练后得到几个文件,其中“.twords”文件为“词项-主题”预测文件,列出每个主题下的特征词及其概率;“.theta”文件为“文档-主题”预测文件,每行代表训练数据集中的一个文档属于不同主题的概率;“.tassign”文件为“文档-词项-主题”预测文件,文件的每行代表一个文档。如“.twords”文件生成10个主题,每个主题下包含50个词。每个主题的前10个词见表2。

表2 实验中10个主题的前10个主题词
2.2.3 分类的预测
从实验的10个类别中选取3 000条中文文本数据进行分类的测试工作,预测数据的文本格式与训练文本格式类似,只是不需要标记预测数据的类别号。
运用Labeled LDA进行分类预测,设置相关参数,类目数设为10,每个类别选取前50个最大概率词项,生成的结果文件见图4。

图4 Labeled LDA结果文件
读取.theta文件,选取其中的最大值分类和次最大值分类作为最终分类。如果次最大值个数大于2或是次最大值小于0.02,则只保留最大值分类。
2.3 SVM模型应用
选取以上处理过的消化病学、肿瘤学、皮肤病学、肾脏病学、泌尿外科学、呼吸病学、妇产科学、神经病学、心血管病学、血液病学等10个类别的3 000篇文献数据构建训练文本,每行表示一条中文文献记录,每列代表一个属性词。若是该词在文献中出现则属性值为1,没有出现则属性值为0,属性值为0时可以不用列出。部分文本见图5。
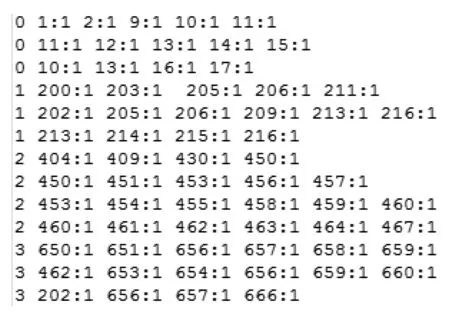
图5 SVM训练文本
选用的SVM训练文本为libsvm-3.20,应用其中的Windows版本执行命令python easy.py svmtrainsvmtest进行参数寻优,使用核函数RBF寻得最优的参数c为0.03125,g为0.0001220703125。
预测得到的最终结果保存到svmtest.predict文件中,预测得到的总准确率为79.9333%。
2.4 结果的对比
Labeled LDA模型与SVM模型的分类结果如表3所示。利用Labeled LDA模型分类结果的平均准确率为87.00%、平均召回率为87.00%、平均F1值为86.97%,利用SVM模型分类结果的平均准确率为79.93%、平均召回率为79.95%、平均F1值为79.94%。由此可见,利用Labeled LDA模型分类的3个测评指标均高于利用SVM模型的分类结果,特别是对肾脏病学的分类结果差别更加明显,其Labeled LDA模型的F1值高出SVM模型的F1值8.59%。实验表明,通过训练文档集的改善及参数的调整,主题模型的分类效果要优于SVM模型,显示出更好的分类效果。

表3 Labeled LDA模型与SVM模型的分类结果对比
3 结论
本文提出了一种基于Labeled LDA主题模型的医学文献自动分类法,通过构建医学领域文本的特定训练集,解决数据的不平衡问题,然后进行模型的训练与测试,并与SVM模型进行了对比实验。结果显示,基于Labeled LDA主题模型自动分类方法的准确率和召回率均优于SVM模型的准确率和召回率,表明此方法在医学领域文本分类方面具有一定的可靠性。但是,本文训练文档集的设定受人为主观因素的干扰较多,下一步工作需要加强研究训练文档集的自动构建方案,进一步提高分类的效率。
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
文化创新比较研究(2020年13期)2021-01-14
少儿画王(3-6岁)(2020年4期)2020-09-13
天津外国语大学学报(2020年1期)2020-03-25
电脑爱好者(2017年7期)2017-05-06
西夏学(2016年2期)2016-10-26
浙江大学学报(工学版)(2015年1期)2015-03-01
外语教学理论与实践(2014年4期)2014-06-13
