
基于同期线损系统数据挖掘技术的低压台区线损诊断模型
2018-03-12 10:00:32
重庆电力高等专科学校学报 2018年6期
(国网重庆市电力公司 北碚供电分公司,重庆 400700)
线损指的是以热能形式散发的能量损失,是电网电能损耗的简称[1],是电能从发电厂传输到电力用户过程中,在输电、变电、配电和营销各环节中所产生的电能损耗[2],包括有功损耗、无功损耗和电压损失,一般指有功损耗。线损按照性质分为技术线损(理论线损)和管理线损[3-8],技术线损是通过理论计算公式计算出来的线损,管理线损无法通过理论计算得到。随着社会经济的发展,低压台区的线损成为一个突出的问题[9]。目前低压台区线损一般采用理论计算,经典的低压网线损理论计算方法主要有等值电阻法[10-13]、竹节法[10-14]、前推回代法[13]、电压损失率法[13-14]、台区损失率法[14]等。
传统的理论线损计算虽然方法简单,但是需要网络参数,从低压台区中获得所需要的全部参数比较困难,而且理论计算法本身的假设条件与实际情况不符,没有考虑低压网的特征,再加上低压网供电方式多样,所以理论线损计算出的线损值精度不高。另外,在低压台区中三相不平衡供电时[15],线损计算的误差较大,不能反映实际的线损,因此传统理论线损计算虽然在一定条件下具有一定实用性,但是没有代表性,适用范围不广。
现代智能算法的引入,提高了线损计算的准确度,也在一定程度上提高了线损计算的可信度,但是在低压台区线损计算中的应用还不够成熟。此外,智能算法本身也有一定的缺点,需要进一步研究。近年来有许多新方法用于线损计算中:采用粒子群优化支持向量回归机[16]在提高线损计算精度的同时也提高了计算速度,但是该算法依赖于参数对的选取,实用性有待验证;遗传算法和神经网络结合[17-19]用于线损计算,需要建立学习样本不断训练,容易陷入局部最优点,而且训练时间长,计算精度没有较大提高,神经网络算法本身也会产生过拟合的问题,因而通用性不强,在实际运用中也存在困难。
本文将数据挖掘的理念引入到台区线损管理中,以大数据在电力系统中的应用为背景,以用电信息采集系统采集到的用户用电数据为对象,在筛选出稳定台区的前提下,针对稳定台区,采用数据挖掘的方法研究台区线损。首先将稳定台区用户用电信息进行预处理,按照样本分布将样本分区;然后针对分区样本进行主成分分析(PCA),对分析后的各分区稳定台区进行K-means聚类分析,分析传统K-means算法的缺点,并进行改进,同时为了在大数据采集情况下,能够快速给出最佳聚类数,采用并行计算的方法计算轮廓系数;完成聚类分析后,针对每一类样本进行多元线性回归建模,不仅可以得到直观简洁的模型,而且可以分析影响因子对线损率的影响,预测台区线损并给出台区合理线损的范围,定位线损不合理台区,实现台区线损精细化管理的目标。
1 稳定台区
为了减少非主要因素的干扰,提高分析台区线损影响因素及其影响系数的精确度,便于整个研究工作的展开,首先对相关数据进行预处理,建立稳定台区的概念。
稳定台区指用电采集系统内日、月线损数据趋于稳定,能真实反映当前实际线损情况的台区。基于营销业务系统的台区档案信息,结合年度的日、月线损数据,按照一定的规则进行筛选。稳定台区的判定步骤如下。
步骤1:以用电信息采集系统采集到的数据为基数,剔除以下台区,如采集未全覆盖;含光伏发电用户、无表计量用户等特殊用户;当月发生业务变更,如考核单元对象发生变化、户变关系调整、用户业务变更(换表除外);月均线损率超出(-1%~10%)范围以及日线损率超出(-1%~10%)范围的天数多于10天。
步骤2:以步骤1中剩余单元为基数,计算每个台区的日线损波动率σ,并且作出σ的分布图,求取70%总台区数时对应的σ值设为φ,其中σ的计算公式为
(1)
式中:N是该台区当月线损的可用天数,即除去日用户计算参与率不为100%的天数,除去日线损率超出(-1%~10%)范围的天数;θ为日线损率。
步骤3:以步骤1中剩余单元为基数,剔除日线损波动率σ大于波动阈值φ的台区,再剔除θ超出月均线损率±φ范围的数据,即为稳定台区数据。
稳定台区分区后共分为14个子区,分区过程如图1所示。
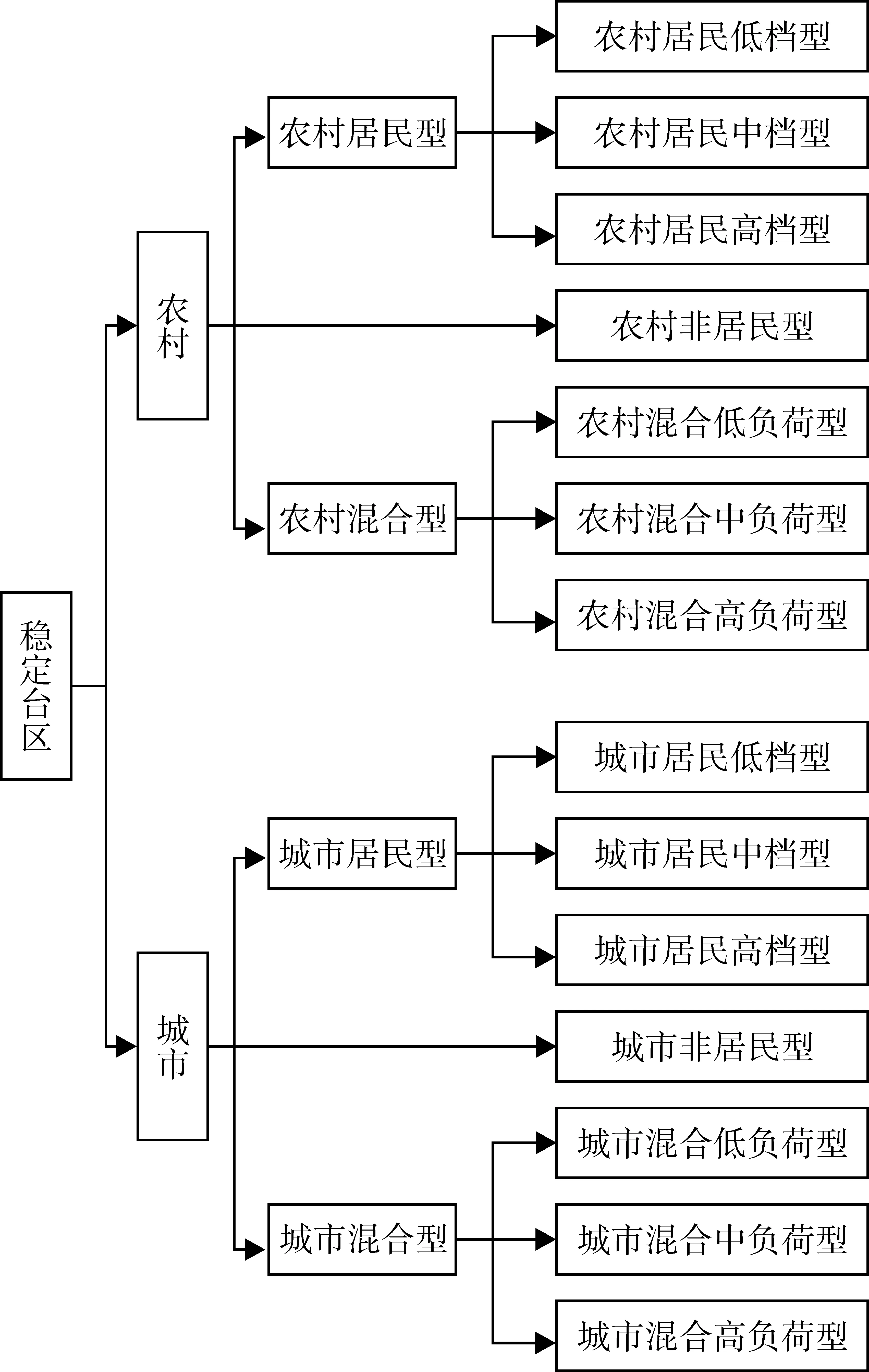
图1稳定台区
综上,稳定台区分为14个分区:城区居民低档型、城区居民中档型、城区居民高档型、城区非居民台区、城区混合低负荷型、城区混合中负荷型、城区混合高负荷型、农网居民低档型、农网居民中档型、农网居民高档型、农网非居民台区、农网混合低负荷型、农网混合中负荷型、农网混合高负荷型。
2 分区数据主成分分析(PCA)
为解决分区数据各维度之间的相关性造成的相互影响和冗余,采用主成分分析(PCA)对分区后的数据进行处理。
PCA的主要步骤如下:
1)样本归一化;
2)计算协方差矩阵的特征根及与特征根对应的正交化的单位特征向量;
3)计算累计贡献率,确定主成分;
4)计算主成分得分。
分区样本完成主成分分析后,得到的各主元相互独立,使得分析问题的维度减少,又能够保持原有数据的绝大部分信息。
3 分区数据聚类分析与线损预测模型
3.1 K-means原理
随着用电信息采集系统的日益完善,可以采集到用户大量的用电数据,因此选择的聚类方法,要求不仅在信息量不大时能够快速准确地聚类,更重要的是能够适应数据量增大的需求,能够及时快速地输出聚类结果。由于K-means算法可以处理大数据集[20],具有很好的可伸缩性和很高的效率,简单快速[21],能够适应数据量增长的实时性处理的需求,广泛地运用在大规模数据聚类中,因此本文选取K-means算法对样本进行聚类。但是K-means算法依赖于初始聚类中心的选取[22],聚类质量受噪声的影响较大,初始聚类中心往往影响聚类结果的好坏;K-means算法是基于梯度下降的算法,具有贪心性;此外,K-means算法需要给定聚类数。这些缺点很大程度上限制了K-means算法的使用,因此,本文针对上述缺点,对K-means算法进行优化,然后运用改进后的算法对主成分分析的结果进行聚类分析。
经典的K-means算法步骤如下。
1)确定聚类数目N和最大迭代次数M。
2)在样本中任选N个对象,作为初始聚类中心。
3)计算样本到N个对象之间的欧式距离,按照欧式距离的大小,将样本归类。欧式距离定义为
(2)
式中:xik表示第k个样品的第i个变量的观测值;p表示样本数;dij表示样本j与样本i之间的欧式距离。
4)计算各类对象的平均值,更新聚类中心。
5)计算平方误差准则函数,判别是否满足收敛条件,如果收敛,则算法结束;如果不收敛,判断迭代次数是否大于M,如果小于M,则转第三步,否则算法结束。平方误差准则函数为
(3)
式中:E表示所有对象的平方误差和;xq表示聚类样本;Ci表示第i个类;mi是Ci中对象的均值;nCi表示Ci中对象的数目。
6)输出聚类结果。
3.2 聚类质量评价指标
聚类的有效性可以从类间距离和类中距离两个方面来衡量,类中距离意味着同类样本的凝聚度,类间距离意味着不同类之间的分离度,因此一个好的聚类结果,应该满足类间距离大,类中距离小,这样同一类中的相似性越大,不同类中样本的差异性越大。轮廓系数是综合反映类中相似性和类间差异性的指标[23],因此可以用轮廓系数评价聚类质量,确定合理的聚类数。轮廓系数S定义为
(4)
式中:n表示样本总数;si表示样本i的轮廓系数;其定义为
(5)
式中:xi表示类x中第i个样本与类x中其他样本的距离平均值,表征类中凝聚度;计算xi与除类x之外其余所有类中样本距离的平均值,并记yi为该平均值的最小值。
显然si和S值都在[-1,1]之间,值越大,聚类质量越高。本文将利用轮廓系数来衡量聚类质量,根据轮廓系数的值,选取最优的聚类数。
3.3 K-means聚类算法优化
3.3.1 去噪声点
样本点中噪声点的数量远远少于非噪声数据量,但是对于多维数据集,噪声点到聚类中心的距离与误差平方和(SSE)有95%的相关性[24],噪声点远离正常样本点,影响算法迭代过程中的聚类中心,增加K-means算法收敛的迭代次数,聚类结果会偏离实际,影响聚类结果稳定性,因此运用K-means算法前应将噪声点剔除,以提高聚类质量。
为了能够快速简洁地剔除噪声点,基于样本实际特征,采用样本均值欧式距离法剔除噪声点。具体的方法如下,首先计算出样本的均值,然后计算所有样本与均值点的欧式距离,并按欧式距离从小到大对样本点重新编号,显然,编号较大且距离值变化迅速的点就是噪声点。
3.3.2 并行计算

近年来随着计算机技术的发展,多核心CPU的普及为计算的快速性提供可能,利用并行计算[26]技术可以提高计算快速性和响应实时性。并行计算的思想是将待求解的问题分为若干部分,每部分由一个独立CPU核心来处理。
在进行轮廓系数计算时,各个样本个体轮廓系数的计算相互独立,不需要顺序执行,此外计算每一个类样本的个体轮廓系数也是相互独立的。当样本聚为n类时,采用并行计算技术计算每类的个体轮廓系数,最后再计算所有类样本个体轮廓系数均值,得到聚为n类时的聚类轮廓系数。
3.4 线损预测模型
现代人工智能算法已在许多方面得到了广泛运用,例如神经网络、遗传算法、粒子群算法、蚁群算法等成功运用在许多领域,并取得很好的效果。虽然这些算法建立的模型预测精度高,但是泛化能力不强,而且模型的可解释性也不强。为了能够直观得出线损与影响因子之间的关系,最简单有效的方法是采用线性回归,这样能够得出直接的回归方程,确定线损与影响因子之间的关系,从而能够为降低线损提供思路,简单实用。
多元线性回归是多元统计分析中的一个重要方法,被广泛应用于社会、经济、技术以及众多自然科学领域的研究中[27],其数学模型为
y=β1x1+β2x2+…+βkxk+β0+ε
(6)
式中:β0为常数项;β1,β2,…,βk为回归系数;ε为随机误差,且服从N(0,σ2)。最小二乘法在误差平方和为
(7)
最小的情况下,求回归系数的估计量,代入式(6)得回归方程

(8)
3.5 算法基本流程
根据特征类似的台区拥有较为接近的线损率的原则,本文算法模型实际包含K-means聚类与线性回归2个部分。通过K-means聚类按照与台区线损率相关的基本特征属性分为K类,然后将每一类数据分别建立各自的线性回归模型,通过回归模型代入对应台区特征数据,得到预测的台区线损率,定义为合理线损率。合理线损与实际线损之差即为预测误差。算法的基本流程如图2所示。

图2 基于K-means值聚类的流程图
4 结论
为提高线损预测模型的预测准确性和实用性,剔除不确定因素,筛选出稳定台区,将稳定台区细分为14个分区:城区低档居民型、城区中档居民型、城区高档居民型、城区非居民台区、城区低负荷混合型、城区中负荷混合型、城区高负荷混合型、农网低档居民型、农网中档居民型、农网高档居民型、农网非居民台区、农网低负荷混合型、农网中负荷混合型、农网高负荷混合型。
在稳定台区划分的基础上,针对各分区采用主元分析,降低稳定台区用电信息样本维度并剔除冗余信息;各分区得到主元后,考虑计算的实时性,采用K-means算法对各分区主元信息聚类进行分析。考虑到K-means算法聚类质量受噪声点影响较大,初始聚类中心的选取影响聚类结果,最佳聚类数无法确定,同时为满足在大数据集情况下计算的实时性的要求,对K-means算法进行了优化。利用优化后的K-means算法对各分区样本进行聚类分析,然后利用多元线性回归方法建立各分区的线损预测模型,在得到线损直观表达式的同时,也可以为降低线损提供思路。
猜你喜欢
水利学报(2022年3期)2022-06-07 05:26:02
今日农业(2020年14期)2020-12-14 19:47:34
电子制作(2017年2期)2017-05-17 03:55:22
电子制作(2017年2期)2017-05-17 03:55:17
电子制作(2016年11期)2016-11-07 08:43:38
电子制作(2016年1期)2016-11-07 08:42:53
电子制作(2016年23期)2016-05-17 03:53:59
电测与仪表(2014年16期)2014-04-22 05:19:40
电测与仪表(2014年13期)2014-04-04 12:04:20
电力需求侧管理(2014年6期)2014-03-20 13:36:07
