
基于EKSC算法的网络事件热度预测方法
2018-03-06 11:05张茂元孙树园王奕博孟琼瑶
计算机工程与科学 2018年2期
张茂元,孙树园,王奕博,孟琼瑶,王 琦
(华中师范大学计算机学院,湖北 武汉 430079)
1 引言
随着互联网的快速发展,网络已经成为思想文化信息的集散地和社会舆论的放大器,网络舆情成为映射社会舆情态势的实时晴雨表。由于互联网的虚拟性,如果不能准确把握网络舆情的传播规律并采取有效的引导管理措施,便极有可能影响社会的和谐与稳定,近年来,对网络舆情研究与监管已经得到党和国家的高度重视[1,2]。网络舆情通常是由网络中的各种热点事件刺激而产生的,因此研究如何在热点事件发展的萌芽阶段预测其热度及发展趋势具有重要意义。
现实生活中,人们对网络事件的参与程度(如报道数、评论数、转发数等)是衡量网络事件热度的重要度量,这些度量跟随时间的变化呈现为一个时间序列。不同来源、不同类型的网络事件的热度随着时间的发展呈现一定规律的变化[3 - 5]。如图1所示,其中图1a是关于“天津港爆炸事件”的热度序列图,有数个高峰,衰减速度缓慢;图1b是关于艺人大婚的热度序列图,其波形只有一个高峰,且衰减迅速。由此可见,网络事件的时间序列蕴含着丰富的时态信息,通常情况下,同一类事件的发展趋势有较高的相似性[6]。

Figure 1 Development trend of two different events图1 两个不同事件的热度图
在热度预测方面,现有的方法大多是通过文本处理方法对网络上的信息进行统计,并通过挖掘自身历史数据对未来热度趋势进行预测。这种方法虽然可以达到较高的准确率,但由于新事件产生时,相关的报道数量、评论数、点击率很少,加之网络热点事件通常具有爆发周期短的特点,使得该类算法无法有效地对新出现的事件进行预测,并且在预测的过程中忽视了事件时间序列中蕴含的时态信息。
在现实世界中,事件的发生并不是孤立的,相似事件的受关注程度及发展趋势总是相似的。基于上述思想,本文提出了一种基于EKSC(EEMD-based K_SC)算法的网络事件热度预测模型。该模型使用EKSC算法对每类已知网络舆情事件的时间序列进行聚类,并构建类模型库。当待预测的事件发生时,首先确定事件的类别并获取其已知的热度时间序列,寻找合适的缩放比例并使用最小二乘法选取类模型库中均方误差和最小的模型对该事件进行预测。
2 相关研究
2.1 舆情预测相关研究
在热度发展趋势预测方面,早期的预测方法主要是用于平稳时间序列分析的自回归模型AR(AutoRegressive)、滑动平均模型MA(Moving Average)和自回归滑动平均模型ARMA(AutoRegressive Moving Average)三类。但自然界中绝大部分时间序列都是非平稳的,随着研究的逐渐深入,又出现了一批以现代科学技术方法为主要手段的预测模型。例如:文献[7]采用高斯模型对帖子的发展态势进行拟合,在此基础上对帖子的后续发展进行预测;文献[8]利用小波变换对帖子的点击数或回复数所形成的时间序列进行转换,得到低频和高频小波系数值,通过神经网络对训练集中各个小波系数进行评价,选取贡献度最高的若干系数作为该类别的特征系数;文献[9]利用马尔科夫链对舆情的发展趋势做预测。通过分析舆情事件的点击数、回复数以及转载数得到事件的热度值,并求出热度趋势值,运用马尔科夫链构造状态转移矩阵,最后得到预测结果。文献[10]通过将经验模态分解EMD(Empirical Mode Decomposition)和自回归积分滑动平均模型ARIMA(AutoRegressive Integrated Moving Average Model)相结合进行舆情演化分析。这类方法的共同特点是采用模型和方法,不追求严格的数学推导,更重视对时间序列的拟合效果。虽然研究者们在热度预测方面取得了丰硕的成果,但是由于网络舆情是由多种成分共同作用的结果,而现有的方法大多在建模时使用具有一定局限性的单一模型进行建模,忽略了相似的网络事件背后蕴含的发展规律。
2.2 热度定义的相关研究
对网络事件热度定义的问题,当前研究多采用的方法可分为:(1) 直接将事件的报道数或点击数作为热度;(2) 综合考虑时间、关注度、转发数、用户影响力等多种因素定义事件的热度。
方法(1)将多种因素纳入到热度的计算中简单直观,统计方便,如张虹等人[8]在使用小波分解对帖子的热度进行预测时采用帖子的点击数作为热度标准;何炎祥等人[11]将各话题的发帖数量作为话题热度,并以此为基础改进了人口模型,使用遗传优化的神经网络对话题的趋势进行预测。方法(2)综合考虑时间、关注度、转发数、用户影响力等多种因素对热度进行计算。如郑志蕴等人[12]在内容特征、博主特征和传播特征三个方面对热门微博进行特征分解,并使用信息增益算法对微博的热度进行度量;Pal等人[13]在Twitter数据集上将发帖数、回复数、转发数、粉丝数、被引用数引入热度的计算中。
3 基于EKSC算法的网络舆情演化分析
3.1 相关定义
定义1(事件) 事件是在特定的时间和地点,由一系列的原因和条件而产生的,对一定的人群产生影响的事情,其表现形式为与之相关的一系列报道和文档[14]。
定义2(热度) 对一个网络事件,在时间间隔t内被报道和评论的次数称为该网络事件在时间间隔t内的热度。
定义3(热度序列) 在一定时间范围内,对事件的热度进行记录可得到关于该事件热度的时间序列,称为热度序列。根据事件热度序列,可画出热度时间序列图,其反映了该事件的热度是如何随着时间的推移而变化的。
定义4(类模型) 对热度时间序列聚类的结果中,每一个类别中所有成员序列所形成的矩阵中心曲线称为类模型曲线。每一个类别的类模型序列反映了该类成员时间序列的共同模式特征。
3.2 K_SC算法
文献[15]为了刻画两个话题的时间序列之间的内在规律特征提出了K_SC(K_Spectral Centroid Clustering)算法。K_SC算法分为两个步骤:首先,把所有时间序列随机地进行分类,根据矩阵中心公式计算出每个类别矩阵的中心;其次,遍历所有的时间序列,使用差异度计算公式,计算出与每个类别矩阵中心的差异度,并将其归到差异度最小的类中,最后更新该类的矩阵中心。K_SC算法是一个迭代的过程,迭代停止的条件是:每个类别的成员不再发生变化或者达到预定的迭代次数。
下面给出时间序列差异度计算公式和更新矩阵中心公式。
(1)差异度计算公式:
(1)

(2)更新矩阵中心公式:
(2)
化简后得到:
(3)
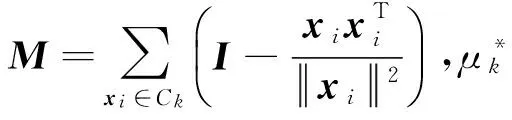
3.3 基于EKSC算法的网络事件热度预测
K_SC算法在初始类选择上很敏感,如果初始类的选择不好,则算法收敛的速度十分缓慢;此外,K_SC算法的差异度计算和矩阵中心选择上使用了原始的时间序列进行处理,由于网络事件的时间序列呈现非平稳的变化特点,直接用来作为输入会影响算法的聚类效果。因此,为了减少非平稳性对聚类效果的影响,本文在集合经验模式分解的基础上,提出了改进的K_SC算法,称为EKSC算法。EKSC算法分为两个步骤:(1)对非平稳的时间序列分解为若干近似于平稳的时间序列进行处理;(2)重构并进行聚类。EKSC算法通过集合经验模式分解将非平稳的时间序列处理为不同尺度的时间分量,将不同周期的局部特征从原始序列中分离出来,再利用多变量相空间估计嵌入维数对数据进行重构,把在不同分量上的聚类结果作为迭代的基础,有效地减少了非平稳特性对算法准确性的影响。
非平稳时间序列的分解方法较多,经验模式分解EMD(Empirical Mode Decomposition)[16]是美国航天局Huang等人提出的一种信号处理方法。该方法的本质是对信号进行平稳化处理,通过将信号中不同尺度(频率)的波动逐级抽离出来,产生一系列包含原信号不同时间尺度局部特征信息的本征模函数IMF(Intrinsic Mode Function)和趋势项res。IMF需要满足两个条件:(1)任一局部点上的由序列的极大值和极小值定义的包络均值必须为0;(2)序列过零点的数量和极值点的数量必须相等,或者最多相差一个。EMD的分解过程是根据信号自身的特性将高低频率先后抽离出来,因此EMD分解具有自适应性;而且EMD分解的各个分量在局部与标准的正弦曲线相吻合,因此各个IMF分量在局部近似正交,这使得瞬时频率具有物理意义。
虽然EMD在解决非线性问题上比小波分解更加精确,但是EMD算法仍存在一些问题,即出现不同模态之间的混淆,称为模态混叠。模态混叠是由在信号分解的过程中原始时间信号中含有的噪声而造成的,最终将会导致分解的结果不稳定。为了解决这一缺陷,Wu等人[17]在EMD的基础上提出了EEMD(Ensemble Empirical Model Decomposition)算法。EEMD算法的核心是,在信号处理的过程中加入高斯白噪声,从而改变信号不同频率成分的极值点的分布情况,通过改变加入白噪声的次数和大小可以有效地解决模态混叠的问题。序列y(t)的EEMD分解过程如下:
(1)设定加入高斯白噪声的大小和次数为N,将第i次加入噪声后的序列记为yi(t);
(2)将所有加入噪声后的序列yi(t)进行EMD分解,得到不同尺度的本征模函数IMFij和趋势项resi。其中,IMFij表示序列第i次加入噪声后分解得到的第j个IMF;
(3)将N次分解的结果进行均值处理,得到EEMD分解后最终的IMF,即:
(4)
最终的结果表示为:
(5)
对某一类网络事件的时间序列,我们首先对序列进行平稳化处理,得到具有物理意义的各个IMF分量;然后从低频分量开始聚类,将低频分量的聚类结果作为高频分量聚类的初始矩阵中心。算法迭代过程的结束条件为:
(1)如果低频分量的聚类情况在高频聚类时没有改变,则跳出循环迭代结束;
(2)当算法运行到指定IMF分量层次时,迭代结束。
算法1EKSC算法
输入:N个维度为L的时间序列,k个初始随机类C={C1,C2,…,Ck}。
输出:k个类的矩阵中心。
定义:IMF分量的个数用m表示
1.fori=1 toNdo
2.yi← EEMD Transform(xi);
3.end for
4.forj=mto 0 do
5. fori=1 toNdo
6. (C,μ1,μ2,…,μk)←K_SC(y,C,k);
7. if(finsh(C)) break;
8.end for
9.returnC,μ1,μ2,…,μk。
将原始序列使用EKSC算法进行聚类后可得到聚类结果C={C1,C2,…,Ck} ,对于每一类Ci,使用最小二乘法求出与该类包含的所有时间序列均方误差和最小的类模型。具体做法如下:设类别Ci所包含的时间序列集合为{y1,y2,…,yn},n为类别Ci中所包含的时间序列的个数。每个时间序列表示为yj={tj1,tj2,…,tjl},l为时间序列的维度,1≤j≤n。则类别Ci的类模型可以表示为:
(6)

(7)
将式(6)代入式(7),式(7)可以看做关于a0,a1,…,ak的多元函数,根据多元函数求极值法,分别对a0,a1,…,ak求一阶偏导,并令等式的右边为零,得到如下的非齐次线性方程组:
(8)
解上述非齐次线性方程组,求出所有的驻点a0,a1,…,ak,并找到边界值上的最小值,最小值对应的驻点即为该类类模型中的各个系数,从而可获得该类的类模型。采取同样的方法,可以建立每一类的类模型。
3.4 热度预测
当新的网络事件发生时,首先确定事件所属的类别,并按一定的时间间隔采集该事件的热度,获得该事件的时间序列;将该事件的时间序列进行自适应的缩放变换,并逐一与其所属的事件类别中的所有类模型进行匹配,选取与已知时间序列均方差和最小的类模型作为该事件的预测模型,具体流程如图2所示。
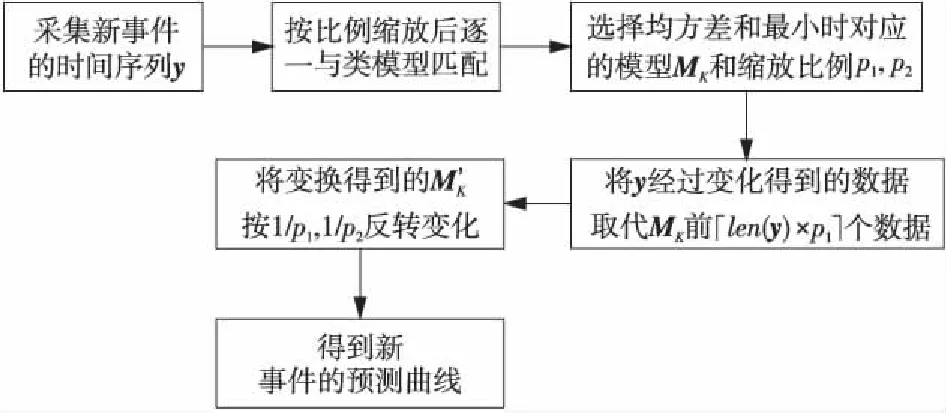
Figure 2 Process of predicting development trend图2 热度预测流程
图2中,新事件的热度预测方法主要分为三个步骤:
(1)按一定的时间间隔采集新事件的热度形成时间序列y,长度为len(y),对时间序列的横坐标和纵坐标按照比例p1、p2进行平移和缩放。经过缩放变换后的横坐标ti和纵坐标yi分别为:
ti=(tθ+tr-tθ)(xi-θ))p2
(9)



4 实验与分析
4.1 实验数据
实验共使用三个数据集,分别来自Stanford大学(http://snap.stanford.edu/data/volumeseries.html)的MemePhr数据集、Twhtag数据集和从“新浪新闻”爬取的社会安全类新闻报道数据。MemePhr数据集选取1 000个博客和网站上的热门帖子和新闻,以评论数作为热度,按小时进行划分,维度为128;Twhtag选自Twitter上的1 000个热门帖子,以帖子被提及的次数作为热度,按小时划分,维度为128;第三个数据集来自“新浪”新闻中在2015年4月~2015年10月期间关于社会安全类的新闻报道,以新闻报道的评论数为热度,按小时进行划分,维度为120。实验分为两个部分,实验第一部分分别在MemePhr数据集、Twhtag数据集和从“新浪新闻”爬取的社会安全类新闻报道数据上对EKSC算法与K_SC算法的聚类效果进行评估;实验第二部分在从“新浪新闻”爬取的社会安全类新闻报道数据上对“天津港爆炸”事件的发展趋势进行预测。
4.2 评价指标
(1)EKSC算法和K_SC算法聚类效果评价指标。
作为聚类算法,主要考虑算法的聚类结果是否合理,为此,分别从类内和类间进行评价:
①F-Value(F值)。F值反映了每个类内部成员的紧凑程度,F值越小,表明类内的元素越紧凑。其计算方法如下:
②D-Value(D值)。
其中,μi、μj分别代表了类i和类j的中心。D值的大小反映了类间的差异性,因此,D值越大表明聚类的效果越好。
(2)趋势预测评价指标。
趋势预测的目的在于对网络事件发展过程中所形成的时间序列进行预测,其准确性可通过预测值与真实值的对比进行衡量。因此,选择均方误差MSE(Mean Square Error)和趋势预测准确率(PRE)两个指标对结果进行评价。
①均方误差MSE。MSE反映了事件热度的预测值与真实值之间的差距,计算方式如下:
(10)

②趋势预测准确率PRE。趋势预测准确率反映了对事件发展趋势预测的准确性,PRE值越大,表明预测的结果越准确。对待预测事件所形成的时间序列Y和预测得到的时间序列Y′,其第i个时刻到第i+1个时刻的趋势预测是否正确记为Ri,Ri的定义如下:
(11)
则趋势预测准确率PRE的计算公式如下:
(12)
4.3 实验结果与分析
4.3.1 EKSC算法与K_SC算法聚类效果比较
表1给出了K_SC算法和EKSC算法在三个数据集上的F值和D值。从表1中可以看出,EKSC算法在F值和D值上都要优于K_SC算法,说明无论在类内成员的紧凑程度上还是类间的差异度上,EKSC算法都要好于K_SC算法。其原因在于,EEMD能根据信号的自身特性自适应地分解若干表征局部特征的IMF分量,不同尺度的IMF分量物理含义明显。在网络事件的时间序列分解上,各个分量所代表的物理含义可以看作事件演化过程的特征成分、瞬时成分、周期成分和趋势成分。因此,在初始矩阵中心的选择上,EKSC算法所选择的矩阵中心更能反映各个类别的发展特性。

Table 1 F-Value and D-value of two algorithms under different data sets
4.3.2 趋势预测结果与分析
对“天津港爆炸事件”的预测需要对其所属的事件类型构建类模型库,为了构建类模型库,首先使用EKSC算法对其所属的社会安全类数据集进行聚类,并通过最小二乘法得到每一小类的模型。对社会安全类事件的聚类,其模型曲线如图3所示。图3表示将该类事件划分为4个小类的模型曲线。构建得到每一小类的模型后,将“天津港爆炸事件”前60小时的数据作为训练数据,后60小时的数据作为测试数据,设定横纵坐标的缩放比例,当p1=2,p2=1.5时,模型库中的第3类模型与缩放后的“天津港爆炸事件”数据的均方误差和最小。因此,选定模型3作为天津港事件的预测模型。对模型3的横纵坐标按照1/p1,1/p2的比例进行反变化,并将模型中前60小时的数据替换为天津港事件前60小时的数据,从而得到天津港事件的预测曲线。
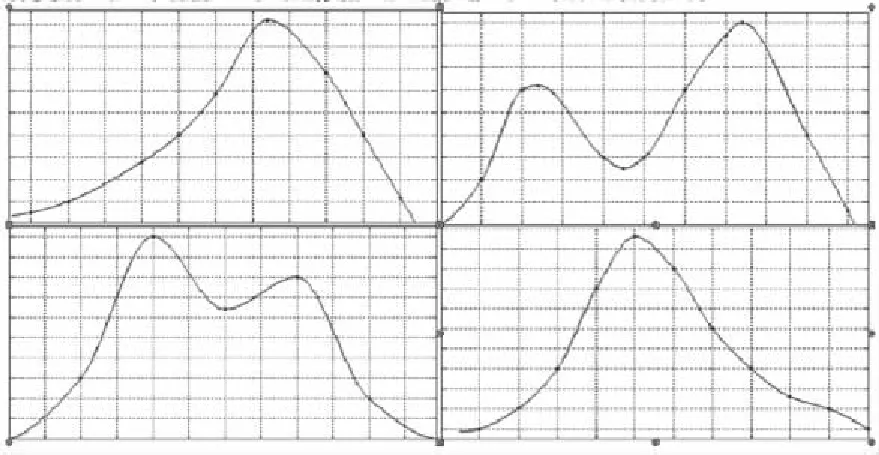
Figure 3 Class model library of the development trend图3 类模型曲线图
为了验证本文方法的有效性,将本文提出的方法与其他两种算法进行比较。
算法1参照文献[10]中提出的“基于数据挖掘的网络论坛话题热度趋势预报”方法,选取N=4阶消失矩的db4小波,采用3层BP(Back Propagation)神经网络模型对“天津港爆炸事件”进行热度预测,其中隐含层和输出层的传递函数设置为logsig,训练函数为trainlm。在BP神经网络中,学习速率Ir的大小对收敛的速度和训练结果影响很大,一般设定在0.01~0.1,本文设定Ir为0.1。
算法2参照文献[18]中提出的“基于K近邻的新话题热度预测算法” 对“天津港爆炸事件”进行热度预测。在文献[18]中,当K=1时,实验效果最好,因此本文将K的值取为1。
表2给出了三种方法得到的预测值与实际值之间的均方误差和趋势预测准确率,图4给出了天津港事件的真实热度曲线和预测曲线。从表2中可以看到,基于EKSC算法的热度预测方法在预测热度值的准确性和事件发展趋势的预测上都要优于其他两种方法,因此,本文提出的预测方法是有效的。

Table 2 Predicted results of different methods

Figure 4 Comparison of predicted trend and actual trend图4 “天津港爆炸事件”热度预测对比图
5 结束语
近年来随着我国进入关键的转型阶段,社会的复杂程度进一步提高,合理科学地监管和引导网络舆情对确保社会的稳定和谐具有重要意义。如何准确把握网络舆情的传播规律是一个关键问题,本文就此提出了基于ESKC算法的网络事件热度预测模型。该模型使用EKSC算法对每类的已知网络舆情事件的时间序列进行聚类,并构建类模型库。当待预测的事件发生时,首先确定事件的类别并获取其已知的热度时间序列,寻找合适的缩放比例并使用最小二乘法选取类模型库中均方误差和最小的模型对该事件进行预测。实验表明本文提出的方法比传统的预测方法预测结果更准确,可以更好地帮助监管部门对网络舆情事件发展态势的把控,提高网络舆情监管功效。
[1] Dai Yuan,Yao Fei.Research on information mining and evaluation index system based on network public opinion security [J].Information Studies:Theory & Application,2008,31(6):873-876.(in Chinese)
[2] Zeng Run-xi,Xu Xiao-lin.A study on early warning mechanism and index for network opinion [J].Journal of Intelligence,2009,28(11):52-54.(in Chinese)
[3] Szabo G,Huberman B A.Predicting the popularity of online content [J].Communications of the ACM,2010,53(8):80-88.
[4] Mei Q,Liu C,Su H et al.A probabilistic approach to spatiotemporal theme pattern mining on weblogs [C]∥Proc of the 15th International Conference on World Wide Web, 2006:533-542.
[5] Crane R, Sornette D.Robust dynamic classes revealed by measuring the response function of a social system [J].Proceedings of the National Academy of Sciences of the United States of America,2008,105(41):15649-15653.
[6] Gao Hui,Wang Sha-sha,Fu Yan.Prediction model for long-term development trend of web sentiment [J].Journal of University of Electronic Science and Technology of China,2011,40(3):440-445.(in Chinese)
[7] Lu Jun-jia,Zhang Hong-li,Zhang Yue.Research on the technology of hot topics foundation and trend forecast in BBS [J].Intelligent Computer and Applications,2012,2(2):1.(in Chinese)
[8] Zhang Hong,Zhong Hua,Zhao Bing.Hot trend prediction of network forum topic based on data mining [J].Computer Engineering and Applications,2007,43(31):159-161.(in Chinese)
[9] Liu Kan,Li Jing,Liu Ping.Trend analysis of public opinion based on Markov chain [J].Computer Engineering and Applications,2011,47(36):170-173.(in Chinese)
[10] Zhou Yao-ming, Wang Bo, Zhang Hui-cheng.Evolution analysis and modeling method of internet public opinions based on EMD [J].Computer Engineering,2012,38(21):5-9.(in Chinese)
[11] He Yan-xiang, Liu Jian-bo, Liu Nan.Based on improved Malthusian model microblogging topic trend forecast [J].Journal on Communications,2015,36(4):5-12.(in Chinese)
[12] Zheng Zhi-yun, Jiang Guo-lin,Zhang Hang-jin.Researh on the prediction algorithm for Sina popular micro blog based on multi-features [J].Journal of Chinese Computer System,2017,38(3):494-498.(in Chinese)
[13] Pal A,Counts S.Identifying topical authorities in microblogs [C]∥Proc of the 4th ACM International Conference on Web Search and Data Mining,2011:45-54.
[14] Chen Xue-chang,Han Jia-zhen,Wei Gui-ying.Topic detection and tracking pilot study [J].China Management Informationization,2011,14(9):56-58.
[15] Yang J,Leskovec J.Patterns of temporal variation in online media [C]∥Proc of the 4th ACM International Conference on Web Search and Data Mining,2011:177-186.
[16] Huang N E, Shen Zheng,Long S R,et al.The empirical mode decomposition and the hilbert spectrum for nonlinear and non-stationary time series analysis[J].Proceedings of the Royal Society,1998,454(1971):903-995.
[17] Wu Zhao-hua, Norden E H.Ensemble empirical mode decomposition:A noise-assisted data analysis method[J].Advances in Adaptive Data Analysis,2009,1(1):1-41.
[18] Nie En-lun,Chen Li,Wang Ya-qiang.Algorithm for prediction of new topic’s hotness using theK-nearest neighbors [J].Computer Science,2012,39(S1):257-260.(in Chinese)
附中文参考文献:
[1] 戴媛,姚飞.基于网络舆情安全的信息挖掘及评估指标体系研究[J].情报理论与实践,2008,6(31):873-876.
[2] 曾润喜,徐晓林.网络舆情突发事件预警系统、指标与机制[J].情报杂志,2009,28(11):52-54.
[6] 高辉,王沙沙,傅彦.Web舆情的长期趋势预测方法[J].电子科技大学学报,2011,40(3):440-445.
[7] 卢珺珈,张宏莉,张玥.基于BBS的热点话题发现与态势预测技术的研究[J].智能计算机与应用,2012,2(2):1.
[8] 张虹,钟华,赵兵.基于数据挖掘的网络论坛话题热度趋势预报[J].计算机工程与应用,2007,43(31):159-161.
[9] 刘勘,李晶,刘萍.基于马尔可夫链的舆情热度趋势分析[J].计算机工程与应用,2011,47(36):170-173.
[10] 周耀明,王波,张慧成.基于EMD的网络舆情演化分析与建模方法[J].计算机工程,2012,38(21):5-9.
[11] 何炎祥,刘健博,刘楠.基于改进人口模型的微博话题趋势预测[J].通信学报,2015,36(4):5-12.
[12] 郑志蕴,江国林,张行进,等.基于多特征的热门微博预测算法研究[J].小型微型计算机系统,2017,38(3):494-498.
[18] 聂恩伦,陈黎,王亚强,等.基于K近邻的新话题热度预测算法[J].计算机科学,2012,39(S1):257-260.
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
铁道通信信号(2019年6期)2019-10-08
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
雷达学报(2017年6期)2017-03-26
消费电子(2016年12期)2017-01-19
中国民政(2016年16期)2016-09-19
中国民政(2016年10期)2016-06-05
互联网天地(2016年1期)2016-05-04
